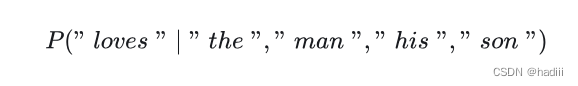鱼弦:公众号【红尘灯塔】,CSDN博客专家、内容合伙人、新星导师、全栈领域优质创作者 、51CTO(Top红人+专家博主) 、github开源爱好者(go-zero源码二次开发、游戏后端架构 https://github.com/Peakchen)
Keras深度学习实战——使用skip-gram和CBOW模型构建单词向量
简介
词向量是将单词表示为向量的一种技术,它可以捕获单词之间的语义关系。词向量在自然语言处理 (NLP) 中有着广泛的应用,例如机器翻译、文本分类和情感分析。
Keras 框架提供了便捷的工具,可以用于构建 skip-gram 和 CBOW 模型来学习词向量。
原理详解
- Skip-gram 模型:
Skip-gram 模型的目标是预测一个目标单词的上下文单词。具体来说,给定一个目标单词及其上下文,模型会学习到上下文单词与目标单词之间的语义关系。
- CBOW 模型:
CBOW 模型的目标是预测一个上下文单词的中心词。具体来说,给定一个上下文,模型会学习到中心词与上下文单词之间的语义关系。
应用场景解释
词向量具有广泛的应用场景,例如:
- 机器翻译: 词向量可以用于机器翻译,以提高翻译的质量。
- 文本分类: 词向量可以用于文本分类,例如垃圾邮件过滤和情感分析。
- 信息检索: 词向量可以用于信息检索,以提高