搭建一个高并发的Web商品推荐系统,如何涉及软件架构
在搭建一个高并发的Web商品推荐系统时:
微服务架构:
为了支持高并发,我们可以采用微服务架构,将系统拆分成小型、独立的服务,每个服务专注于特定的功能,如商品推荐算法、用户数据处理等。这有助于水平扩展,并降低单点故障影响。
分布式缓存:
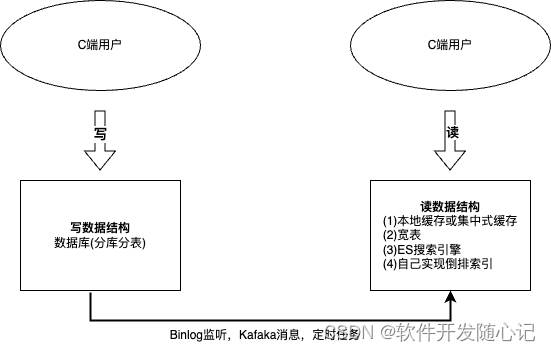
利用Redis或Memcached等缓存机制,缓存热门商品推荐结果,减少数据库查询压力,提高响应速度。
负载均衡:
通过负载均衡器(如Nginx或HAProxy)将流量分散到多个服务器,确保请求能被均匀处理。
数据库优化:
选择适合的数据库技术(例如MySQL分库分表、NoSQL数据库),并利用索引、分区等策略提高数据访问性能。
API Gateway:
设置API网关可以统一管理和控制对各服务的访问,同时处理认证、限流等问题。
事件驱动设计:
使用消息队列(如RabbitMQ或Kafka)来解耦前端请求与后台处理,允许异步处理推荐算法和更新。
容器化和云部署:
使用Docker和Kubernetes等工具,便于快速部署和弹性扩展资源。
监控和日志管理:
实施实时监控(如Prometheus和Grafana)以便及时发现性能瓶颈,使用ELK Stack(Elasticsearch, Logstash, Kibana)进行日志聚合和分析。
高并发场景下,如何保证推荐算法的实时性和准确性?
在高并发的Web商品推荐系统中,保证推荐算法的实时性和准确性需要考虑以下几点:
缓存一致性:
结合缓存和数据库,使用惰性计算或启发式算法在热点数据上做预计算,一旦有更新就迅速同步至缓存,保证推荐的即时性。
异步处理:
对于复杂的推荐算法,可以将其分解为小任务,放到消息队列中异步执行,避免阻塞主线程,提升实时响应。
分布式计算:
如果推荐算法计算量大,可以考虑使用分布式计算框架(如Hadoop或Spark),在多台机器上并行处理,缩短整体计算时间。
增量学习:
实时学习算法如在线协同过滤或深度学习模型,能够根据新的用户行为数据不断调整推荐结果,保持准确性。
实时数据处理:
使用流处理技术(如Apache Flink或Kafka Streams)处理用户的实时交互数据,及时更新推荐结果。
批处理优化:
定期进行大规模的数据处理和模型训练,比如每天晚上进行一次全量的商品推荐更新。
降维和特征选择:
对推荐特征进行优化,只保留最重要的变量,减少计算复杂度。
评估和调整:
持续跟踪推荐效果,使用A/B测试或其他指标(如准确率、召回率)来验证改进,并实时调整推荐策略。