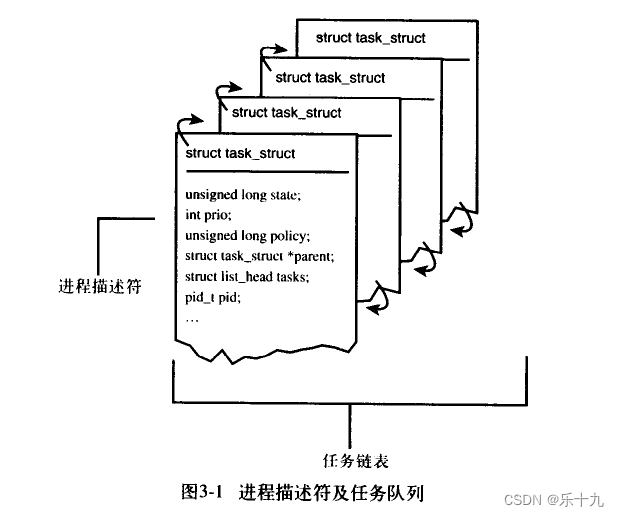
进程有两种特殊的形式:
没有用户虚拟地址空间的进程叫内核线程,共享用户虚拟地址空间的进程叫用户线程。
共享同一个用户虚拟地址空间的所有用户线程叫线程组。
进程原理及调用
进程:是指计算机中已运行的程序。进程本身不是基本的运行单位,而是线程的容器程序本身只是指令、数据及其组织形式的描述,进程才是程序(那些指令和数据)的真正运行实例。
Linux通过:ps 命令用于输出当前系统的进程状态。显示瞬间进程的状态,并不是动态连续。如果我们想对进程进行实时监控就 top 命令。

USER:该进程是由哪个用户产生的;
PID:进程的ID号;
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty1-tty7代表本地控制台终端,tty1-tty6是本地的字符界面终端,tty7是图形终端。pts/0-255代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台;
START:该进程的启动时间;
TIME:该进程占用CPU的运算时间,注意不是系统时间;
COMMAND:产生此进程的命令名;
进程生命周期
Linux 操作系统属于多任务操作系统,系统中的每个进程能够分时复用CPU时间片,通过有效的进程调度策略实现多任务并行执行。而进程在被 CPU 调度运行,等待 CPU 资源分配以及等待外部事件时会属于不同的状态。进程状态如下:
1.创建状态:创建新进程;
2.就绪状态:进程获取可以运作所有资源及准备相关条件;
3.执行状态:进程正在CPU中执行操作;
4.阻塞状态:进程因等待某些资源而被跳出CPU;
5.终止状态:进程消亡。
进行状态关系

task_struct 数据结构
Linux内核涉及进程和程序的所有算法都围绕一个名为 task_struct 的数据结构建立,该结构定义在 include/linux/sched.h 中。
进程优先级
并非所有进程都具有相同的重要性。除了大多数我们所熟悉的进程优先级之外,进程还有不同的关键度类别,以满足不同需求。首先进行比较粗糙的划分,进程可以分为 实时进程 和 非实时进程 (普通进程)。
限期进程的优先级是-1,实时进程优先级(0-99)都比普通进程的优先级(100-139)高。当系统中有实时进程运行时,普通进程几乎无法分到时间片(只能分到5%的CPU时间)。


系统调用
(1) fork 是重量级调用,因为它建立了父进程的一个完整副本,然后作为子进程执行。为减少与该调用相关的工作量,Linux 使用了写时复制(copy-on-write)技术。【防止在fork执行时将父进程的所有数据复制到子进程。在调用fork时,内核通常对父进程的每个内存页,都为子进程创建一个相同的副本】
(2) vfork 类似于 fork,但并不创建父进程数据的副本。相反,父子进程之间共享数据。这节省了大量CPU时间(如果一个进程操纵共享数据,则另一个会自动注意到)。
(3) clone产生线程,可以对父子进程之间的共享、复制进行精确控制。
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
#endif
struct kernel_clone_args args = {
.flags = (lower_32_bits(clone_flags) & ~CSIGNAL), // 创建进程的标志位集合
.pidfd = parent_tidptr,
.child_tid = child_tidptr,
.parent_tid = parent_tidptr, // 指向用户空间中地址的指针,分配指向父子进程的PID
.exit_signal = (lower_32_bits(clone_flags) & CSIGNAL),
.stack = newsp,
.tls = tls,
};
pid_t kernel_clone(struct kernel_clone_args *args)
{
u64 clone_flags = args->flags; // 创建进程的标志位集合
struct completion vfork;
struct pid *pid;
struct task_struct *p;
int trace = 0;
pid_t nr;
/*
* For legacy clone() calls, CLONE_PIDFD uses the parent_tid argument
* to return the pidfd. Hence, CLONE_PIDFD and CLONE_PARENT_SETTID are
* mutually exclusive. With clone3() CLONE_PIDFD has grown a separate
* field in struct clone_args and it still doesn't make sense to have
* them both point at the same memory location. Performing this check
* here has the advantage that we don't need to have a separate helper
* to check for legacy clone().
*/
if ((args->flags & CLONE_PIDFD) &&
(args->flags & CLONE_PARENT_SETTID) &&
(args->pidfd == args->parent_tid))
return -EINVAL;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if (args->exit_signal != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(NULL, trace, NUMA_NO_NODE, args);
add_latent_entropy();
if (IS_ERR(p))
return PTR_ERR(p);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, args->parent_tid);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
return nr;
}
内核线程
内核线程是直接由内核本身启动的进程。内核线程实际上是将内核函数委托给独立的进程,与系统中其他进程“并行”执行(实际上,也并行于内核自身的执行)。
内核线程经常称之为(内核)守护进程。它们用于执行下列任务:
1.周期性地将修改的内存页与页来源块设备同步(例如,使用mmap的文件映射);
2.如果内存页很少使用,则写入交换区;
3.管理延时动作(deferred action);
4.实现文件系统的事务日志;
与普通用户进程区别在于内核线程没有独立的进程地址空间
/*
* Create a kernel thread.
*/
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags)
{
struct kernel_clone_args args = {
.flags = ((lower_32_bits(flags) | CLONE_VM |
CLONE_UNTRACED) & ~CSIGNAL),
.exit_signal = (lower_32_bits(flags) & CSIGNAL),
.stack = (unsigned long)fn,
.stack_size = (unsigned long)arg,
};
return kernel_clone(&args);
}
退出进程
退出进程有两种方式:一种是调用exit()系统调用或从某个程序主函数返回;另一个方式为被接收到杀死信号或者异常时被终止。
进程主动终止:从main()函数返回,链接程序会自动添加到exit()系统调用;主动调用exit()系统函数。
进程被动终止:进程收到一个自己不能处理的信号;进程收到 SIGKILL 等终止信息。
程必须用 exit 系统调用终止。这使得内核有机会将该进程使用的资源释放回系统。见 kernel/exit.c------>do_exit。简而言之,该函数的实现就是将各个引用计数器减 1,如果引用计数器归 0 而没有进程再使用对应的结构,那么将相应的内存区域返还给内存管理模块。
调度器及 CFS 调度器
进程调度目的:最大限度利用CPU时间。
内核中用来安排进程执行的模块称为调度器(scheduler),它可以切换进程状态(process state)。例如执行、可中断睡眠、不可中断睡眠、退出、暂停等。

调度器是CPU中央处理器的管理员,主要负责完成做两件事情:
一、选择某些就绪进程来执行;
二是打断某些执行的进程让它们变为就绪状态。
调度器分配 CPU 时间的基本依据就是进程的优先级。
上下文切换(context switch):将进程在CPU中切换执行的过程,内核承担此任务,负责重建和存储被切换掉之前的 CPU 状态。
如果调度器支持就绪状态切换到执行状态,同时支持执行状态切换到就绪状,称该调度器为抢占式调度器。
调度类 sched_class 结构体与调度类
// 调度类 sched_class 结构体如下:
struct sched_class {
#ifdef CONFIG_UCLAMP_TASK
int uclamp_enabled;
#endif
/* 操作系统当中有多个调度类,按照调度优先级排成一个链表 */
/* 将进程加入到执行队列当中,即将调度实体(进程)存放到红黑树当中,并对 nr_running 变量自动加 1 */
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
/* 从执行队列当中删除进程,并对 nr_running 变量自动减 1 */
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
/* 放弃 CPU 执行权限,实际上此函数执行先出队后入队,在这种情况它直接将调度实体存放在红黑树的最右端 */
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p);
/* 专门用于检查当前进程是否可被新进程抢占 */
void (*check_preempt_curr)(struct rq *rq, struct task_struct *p, int flags);
/* 选择下一个要运行的进程 */
struct task_struct *(*pick_next_task)(struct rq *rq);
/* 将进程施加到运行队列当中 */
void (*put_prev_task)(struct rq *rq, struct task_struct *p);
void (*set_next_task)(struct rq *rq, struct task_struct *p, bool first);
#ifdef CONFIG_SMP
int (*balance)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
/* 为进程选择一个适合的CPU */
int (*select_task_rq)(struct task_struct *p, int task_cpu, int flags);
struct task_struct * (*pick_task)(struct rq *rq);
/* 迁移任务到另一个CPU */
void (*migrate_task_rq)(struct task_struct *p, int new_cpu);
/* 专门用于唤醒进程 */
void (*task_woken)(struct rq *this_rq, struct task_struct *task);
/* 修改进程在CPU的亲和力 */
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask,
u32 flags);
/* 启动/禁止运行队列 */
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
struct rq *(*find_lock_rq)(struct task_struct *p, struct rq *rq);
#endif
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*task_fork)(struct task_struct *p);
void (*task_dead)(struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serialized by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switched_from)(struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval)(struct rq *rq,
struct task_struct *task);
void (*update_curr)(struct rq *rq);
#define TASK_SET_GROUP 0
#define TASK_MOVE_GROUP 1
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_change_group)(struct task_struct *p, int type);
#endif
};
Linux 调度类可分为:stop_sched_class、dl_sched_class 、rt_sched_class 、fair_sched_class 及idle_sched_class 。
extern const struct sched_class stop_sched_class; // 停机调度类
extern const struct sched_class dl_sched_class; // 限期调度类
extern const struct sched_class rt_sched_class; //实时调度类
extern const struct sched_class fair_sched_class; // 公开调度类
extern const struct sched_class idle_sched_class; // 空闲调度类
这 5 种调度类的优先级从高到低依次为:停机调度类、限期调度类、实时调度类、公开调度类、空闲调度类。
- 停机调度类:优先级是最高的调度类,停机进程是优先级最高的进程,可以抢占所有其它进程,其他进程不可能抢占停机进程。
- 限期调度类:最早使用优先算法,使用红黑树把进程按照绝对截止期限从小到大排序,每次调度时选择绝对截止期限最小的进程。
- 实时调度类:为每个调度优先级维护一个队列。
- 公平调度类:使用完全公平调度算法。完全公平调度算法引入虚拟运行时间的相关概念:
虚拟运行时间 = 实际运行时间 * nice0对应的权重/进程的权重。 - 空闲调度类:每个CPU上有一个空闲线程,即0号线程。空闲调度类优先级别最低,仅当没有其他进程可以调度的时候,才会调度空闲线程。
进程优先级
task_struct 结构体中采用三个成员表示进程的优先级:prio 和 normal_prio 表示动态优先级,static_prio 表示进程的静态优先级。
内核将任务优先级划分,实时优先级范围是 0 到 MAX_RT_PRIO-1(即99),而普通进程的静态优先级范围是从 MAX_RT_PRIO 到 MAX_PRIO-1(即100到139)。
/* Linux 内核优先级如下 */
#define MAX_RT_PRIO 100
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH) // NICE_WIDTH 40 NICE_WIDTH 值得范围宽度, 即[-20, 19]共40个数字的宽度
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
实时进程(Real-Time Process):优先级高、需要立即被执行的进程。
普通进程(Normal Process):优先级低、更长执行时间的进程。
进程的优先级是一个 0--139 的整数直接来表示。数字越小,优先级越高,其中优先级0-99留给实时进程100-139留给普通进程。

内核调度策略
linux内核调度策略源码:/include/uapi/linux/sched.h
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
SCHED NORMAL:普通进程调度策略,使 task 通过 CFS 调度器实现;
SCHED FIFO:先进先出调度算法(实时调度策略),相同优先级任务先到先服务,高优先级的任务可以抢占低优先级的任务。
SCHED RR:轮流调度算法(实时调度策略)。
SCHED BATCH:普通进程调度策略,相当于 SCHED NORMAL 分化版本,采用分时策略,根据动态优先级,分配CPU运行需要资源,使 task 通过 CFS 调度器实现;
SCHED IDLE:普通进程调度策略,优先级最低,使task以最低优先级选择CFS调度器来调度运行;
SCHED DEADLINE:限期进程调度策略,使 task 选择 Deadline 调度器来调度运行;
其中 stop 调度器和 DLE-task 调度器,仅使用于内核,用户没有办法进行选择。
CFS 调度器
完全公平调度(Completely Fair Scheduling):完全公平调度算法体现在对待每个进程都是公平的,让每个进程都运行一段相同的时间片,这就是基于时间片轮询调度算法。
CFS定义一种新调度模型,它给 cfs_rq(cfs 的 run queue)中的每一个进程都设置一个虚拟时钟-virtual runtime(vruntime)。如果一个进程得以执行,随着执行时间的不断增长,其 vruntime 也将不断增大,没有得到执行的进程 vruntime 将保持不变。
在实际当中必须会有进程优先级高或者进程优先及低,CFS调度器引入权重,使用权重代表进程的优先级,各个进程按照权重比例分配CPU时间。
1.实际运行时间:
实际运行时间 = 调度周期 * 进程权重 / 所有进程权重之和
调度周期:指所有进程运行一遍所需要的时间;
进程权重:根据进程的重要性,分配给每个进程不同的权重;
2.虚拟运行时间:
虚拟运行时间 = 实际运行时间 * NICE_0_LOAD/ 进程权重 = (调度周期*进程权重 / 所有进程权利之和 ) * NICE_0_LOAD / 进程权重 = 调度周期 * NICE_0_LOAD / 所有进程总权重
在一个调度周期里面,所有进程的虚拟运行时间是相同的,所以在进程调度时,只需要找到虚拟运行时间最小的进程调度运行即可。
调度器结构
主调度器:通过调用 schedule() 函数来完成进程的选择和切换;
周期调度器:根据频率自动调用 scheduler_tick 函数,作用根据进程运行时间触发调度。
上下文切换:主要做两件事情(切换地址空间、切换寄存器和栈空间)。

CFS 调度器类
CFS完全公平调度器的调度器类叫 fair_sched_class。Linux内核源码目录: kernel/sched/fair.c,struct sched_class 调度器类类型
const struct sched_class fair_sched_class;
DEFINE_SCHED_CLASS(fair) = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = __pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_next_task = set_next_task_fair,
#ifdef CONFIG_SMP
.balance = balance_fair,
.pick_task = pick_task_fair,
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_common,
#endif
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
enqueue_task_fair:当任务进入可运行状态时,用此函数将调度实体存放到红黑树,完成入队操作;
dequeue_task_fair:用此函数将调度实体从红黑树中移除,完成出队操作。
完全公平调度器CFS就绪队列
CFS 的顶级调度就队列 struct cfs_rq,Linux内核源码目录:kernel/sched/sched.h。
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load; // CFS运行队列中所有进程总负载
unsigned int nr_running; // rq 中调度实体数量
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;
u64 min_vruntime;
#ifdef CONFIG_SCHED_CORE
unsigned int forceidle_seq;
u64 min_vruntime_fi;
#endif
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root_cached tasks_timeline;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
// sched_entity 可被内核调用的实体
struct sched_entity *curr;
struct sched_entity *next;
struct sched_entity *last;
struct sched_entity *skip;
#ifdef CONFIG_SCHED_DEBUG
unsigned int nr_spread_over;
#endif
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
#ifndef CONFIG_64BIT
u64 load_last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
/* Locally cached copy of our task_group's idle value */
int idle;
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_clock;
u64 throttled_clock_pelt;
u64 throttled_clock_pelt_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护按照虚拟时间排序的红黑树。
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
tasks_timeline -> rb_root 是红黑树的根,tasks_timeline -> rb_leftmost 指向红黑树中最左边的调度实体,即虚拟运行时间最小的调度实体。
实时调度类及SMP和NUMA
Linux 进程可分为两大类:实时进程和普通进程。
实时进程与普通进程根本不同之处,如果系统中有一个实时进程且执行,那么调度器总是会选择它,除非另有一个优先级更高实时进程。
SCHED FIFO:没有时间片,在被调度器选择之后,可以运行任意长的时间;
SCHED RR:有时间片,其值在进程运行时会减少。
实时调度
实时调度实体 sched_rt_entity数据结构
表示实时调度实体,包含整个实时调度数据信息。linux 内核源码目录:include/linux/sched.h。
// 表示实时调度实体
struct sched_rt_entity {
struct list_head run_list; // 专门用于加入到优先级队列当中
unsigned long timeout; // 设置的时间超时
unsigned long watchdog_stamp; // 用于记录 jiffies 值:从电脑开机到现在总共的时钟中断次数
unsigned int time_slice; // 时间片
unsigned short on_rq;
unsigned short on_list;
struct sched_rt_entity *back; // 临时用于从上往下连接 RT 调度实体使用
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent; // 指向父 RT 调度实体
/* rq on which this entity is (to be) queued: */
// 实时类
struct rt_rq *rt_rq; // RT 调度实体所属的实时运行队列,被调度
/* rq "owned" by this entity/group: */
struct rt_rq *my_q; // RT 调度实体所拥有的实时运行队列,用于管理子任务或子组任务
#endif
} __randomize_layout;
实时调度类rt_sched_class 数据结构
linux 内核源码目录:/kernel/sched/rt.c。
/* Real-Time classes' related field in a runqueue: */
struct rt_rq {
struct rt_prio_array active; // 优先级队列
unsigned int rt_nr_running; // 在 RT 队列中所有活动的任务数
unsigned int rr_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* 当前 RT 任务的最高优先级 */
#ifdef CONFIG_SMP
int next; /* 下一个要运行的RT任务的优先级,如果两个任务都有最高优先级,curr==next */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned int rt_nr_migratory;
unsigned int rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif /* CONFIG_SMP */
int rt_queued;
int rt_throttled;
u64 rt_time;
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned int rt_nr_boosted;
struct rq *rq;
struct task_group *tg;
#endif
};
DEFINE_SCHED_CLASS(rt) = {
.enqueue_task = enqueue_task_rt, // 将一个task存放到就绪队列或者尾部
.dequeue_task = dequeue_task_rt, // 将一个task从就绪队列末尾
.yield_task = yield_task_rt, // 主动放弃执行
.check_preempt_curr = check_preempt_curr_rt,
// 核心调度器选择就绪队列当中的那个任务将要被调度,prev 是将要被调度出的任务,返回值是将要被调度的任务
.pick_next_task = pick_next_task_rt,
.put_prev_task = put_prev_task_rt, // 当一个任务将要被调度出时执行
.set_next_task = set_next_task_rt,
#ifdef CONFIG_SMP
.balance = balance_rt,
.pick_task = pick_task_rt,
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
.find_lock_rq = find_lock_lowest_rq,
#endif
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
实时调度操作核心
1.进程插入
// 更新调度信息,将调度实体插入到相应优先级队列的末尾
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
if (flags & ENQUEUE_WAKEUP)
rt_se->timeout = 0;
enqueue_rt_entity(rt_se, flags);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_task(rq, p);
}
2.进程选择:实时调度会选择最高优先级的实时进程来运行。 linux内核源码目录:/kernel/sched/rt.c
static struct sched_rt_entity *pick_next_rt_entity(struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
// 第一个找到一个可用的实体
idx = sched_find_first_bit(array->bitmap);
BUG_ON(idx >= MAX_RT_PRIO);
// 从链表组中找到对应的链表
queue = array->queue + idx;
if (SCHED_WARN_ON(list_empty(queue)))
return NULL;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
return next; // 返回找到运行实体
}
3.进程删除:从优先级队列中删除实时进程并更新调度信息,然后把这个进程添加到队尾。
static void dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
// 更新调度信息等等
update_curr_rt(rq);
// 将rt_se从运行队列当中删除,然后添加到队列尾部
dequeue_rt_entity(rt_se, flags);
// 从hash表当中进行删除
dequeue_pushable_task(rq, p);
}
SMP
处理器系统的工作方式分为 非对称多处理(asym-metrical mulit-processing) 和对称多处理 (symmetrical mulit-processing,SMP) 两种。
在对称多处理器系统中,所有处理器的地位都是相同的,所有的资源,特别是存储器、中断及I/O空间,都具有相同的可访问性,消除结构上的障碍。
多处理器系统上,内核必须考虑几个额外的问题,以确保良好的调度:
- CPU负荷必须尽可能公平地在所有的处理器上共享;
- 进程与系统中某些处理器的亲合性(affinity)必须是可设置的;
- 内核必须能够将进程从一个CPU迁移到另一个。
Linux SMP 调度就是将进程安排/迁移到合适的 CPU 中去,保持各 CPU 负载均衡的过程。
优势:当前使用的OLTP(在线事务处理)程序当中,用户访问一个中断数据库,如果采用SMP系统构架,它的效率要比MPP架构要快。
NUMA(非一致内存访问结构)
NUMA 为是多处理器计算机,系统各个 CPU 都有本地内存,可以支持超快的访问能力,各个处理器之间通过总线连接起来,支持对其他 CPU 的本地内存访问(但比访问自己的内存要慢点)
优势:一台物理服务器内部集成多个CPU,使系统具有较高事务处理能力。
CPU 域初始化
内核对CPU的管理是通过bitmap来管理,并且定义 possible、present、online、active 这4种状态。linux内核源码目录:/kernel/cpu.c
// 表示系统中有多少个可以执行的CPU核心
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
// 表示系统当中有多少个正在处于运行状态的CPU核心
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
// 表示系统当中有多个具备online条件的CPU核心 ,它们不一定都处于online,有的CPU核心可能被热插拔
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
// 表示系统当中有多个少活跃的CPU核心
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)
#define cpu_dying_mask ((const struct cpumask *)&__cpu_dying_mask)
进程优先级与调度策略
Linux内核的三种调度策略:
SCHED OTHER 分时调度策略;
SCHED FIFO 实时调度策略,先到先服务;
SCHED RR 实时调度策略 时间片轮转。
如果有相同优先级的实时进程(根据优先级计算的调度权值是一样的)已经准备好,
FIFO 必须等待该进程主动放弃之后才可以运行这个优先级相同的任务;
而 RR 可以每个任务都执行一段时间。
RR和FIFO属于实时任务。创建时优先级大于0(1-99)。按照可抢占优先级调度算法进行。就绪态的实时任务立即抢占非实时任务。
获得线程设置的最高和最低优先级:
int sched_get_priority_max(int policy); // 获取实时优先级的最大值
int sched_get_priority_min(int policy); // 获取实时优先级的最小值
SCHED OTHER 不支持优先级使用,而SCHED FIFO/SCHED RR支持优先级使用,它们分别为1和99数值越大优先级越高。
实时调度策略 (SCHED FIFO/SCHED RR) 优先级最大值为99;
普通调度策略 (SCHED NORMAL/SCHED BATCH/SCHED IDLE),始终返回0,即普通任务调度的函数,无效果。
设置与获取优先级两个主要函数:
int pthread_attr_setschedparam(pthread attr t *attr, const struct sched param *param); // 创建线程优先级
int pthread_attr_getschedparam(pthread attr t *attr, const struct sched param *param); // 获取线程优先级
param.sched priority=51; // 设置优先级
struct sched_param{
int_sched priority; // 所有设定的线程优先级
}
当系统创建线程时,默认线程是SCHED OTHER。改变调度策略,通过如下函数:
int pthread_attr_setschedpolicy(pthread attr t *attr,int policty); // 设置线程调度策略 struct sched param
RCU 机制及内存优化屏障
RCU 英文全称为 Read-Copy-Update,顾名思义就是 “读 - 拷贝-更新”,是内核中重要的同步机制。
RCU 原理:RCU记录所有指向共享数据的指针的使用者,当要修改该共享数据时,首先创建一个副本,在副本中修改。所有读访问线程都离开读临界区之后 ,指针指向新的修改后副本的指针,并且删除旧数据。
RCU优点:读者开销少,不需要获取任何锁,不需要执行原子指令或内存屏障;没有死锁问题;没有优先级反转的问题;没有内存泄露的危险问题;很好的实时延迟操作。
RCU缺点:写者的同步开销比较大的,写者之间需要互斥处理;使用其它同步机制复杂。
RCU 经常用于读者性能要求比较高的场景。RCU 只能够保护动态分配的数据结构,必须是通过指针访问此数据结构;受 RCU 保护的临界区内不能 sleep;读写不对称,对写者的性能没有要求,但是读者性能要求比较高。
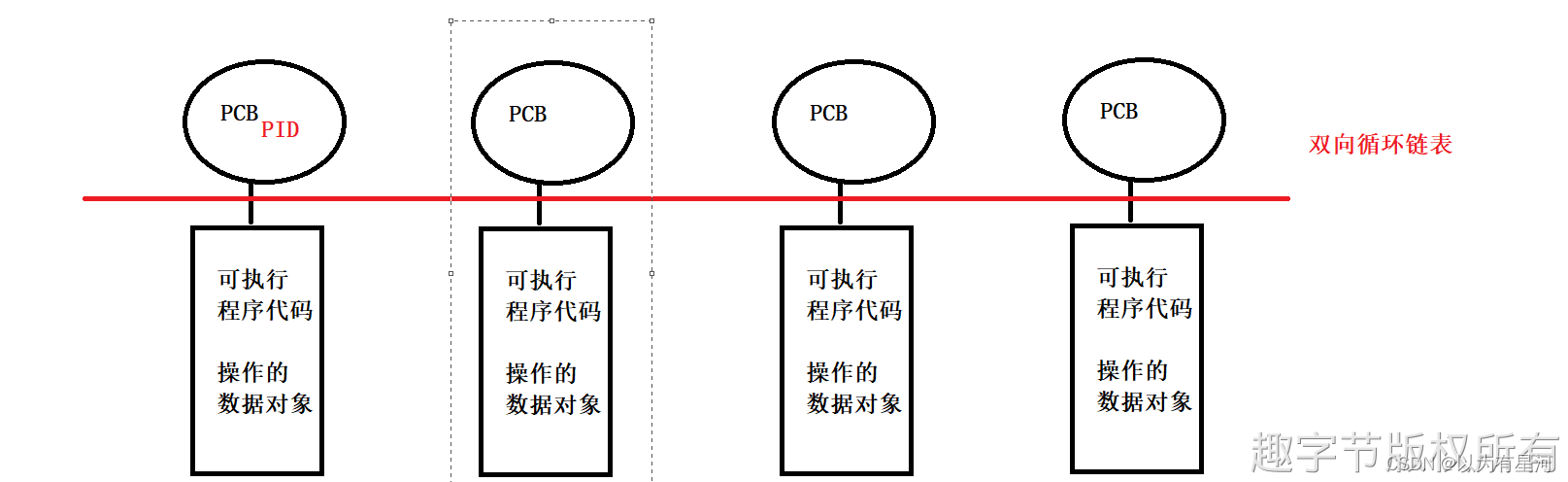
链表操作
内核源码分析:/include/linux/rculist.h
读拷贝更新(RCU)模式添加链表项
// 将新的链表元素 new 添加到表头为 head 的链表头部,而 list_add_tail_rcut 将其添加到链表尾部。
static inline void list_add_tail_rcu(struct list_head *new,
struct list_head *head)
{
__list_add_rcu(new, head->prev, head);
}
static inline void __list_add_rcu(struct list_head *new,
struct list_head *prev, struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
new->next = next;
new->prev = prev;
rcu_assign_pointer(list_next_rcu(prev), new);
next->prev = new;
}
读拷贝更新(RCU)模式删除链表项
// 从链表删除链表元素entry
static inline void list_del_rcu(struct list_head *entry)
{
__list_del_entry(entry);
entry->prev = LIST_POISON2;
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
读拷贝更新(RCU)模式更新链表项
// 将链表元素old替换为new。
static inline void list_replace_rcu(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->prev = old->prev;
rcu_assign_pointer(list_next_rcu(new->prev), new);
new->next->prev = new;
old->prev = LIST_POISON2;
}
RCU层次架构
RCU 根据 CPU 数量的大小按照树形结构来组成其层次结构,称为 RCU Hierarchy
内核源码分析:/kernel/rcu/rcu_node_tree.h
/*
* Define shape of hierarchy based on NR_CPUS, CONFIG_RCU_FANOUT, and
* CONFIG_RCU_FANOUT_LEAF.
* In theory, it should be possible to add more levels straightforwardly.
* In practice, this did work well going from three levels to four.
* Of course, your mileage may vary.
*/
#ifdef CONFIG_RCU_FANOUT
#define RCU_FANOUT CONFIG_RCU_FANOUT
#else /* #ifdef CONFIG_RCU_FANOUT */
# ifdef CONFIG_64BIT
# define RCU_FANOUT 64
# else
# define RCU_FANOUT 32
# endif
#endif /* #else #ifdef CONFIG_RCU_FANOUT */
#ifdef CONFIG_RCU_FANOUT_LEAF
#define RCU_FANOUT_LEAF CONFIG_RCU_FANOUT_LEAF
#else /* #ifdef CONFIG_RCU_FANOUT_LEAF */
#define RCU_FANOUT_LEAF 16
#endif /* #else #ifdef CONFIG_RCU_FANOUT_LEAF */
#define RCU_FANOUT_1 (RCU_FANOUT_LEAF)
#define RCU_FANOUT_2 (RCU_FANOUT_1 * RCU_FANOUT)
#define RCU_FANOUT_3 (RCU_FANOUT_2 * RCU_FANOUT)
#define RCU_FANOUT_4 (RCU_FANOUT_3 * RCU_FANOUT)
RCU 层次结构根据 CPU 数量决定,内核中有宏帮助构建 RCU 层次架构,其中 CONFIG_RCU_FANOUT_LEAF 表示一个子叶子的 CPU 数量,CONFIG_RCU_FANOUT 表示每个层数最多支持多少个叶子数量。
优化内存屏障
优化屏障:在编程时,指令一般不按照源程序顺序执行,原因是为提高程序执行性能,会对它进行优化,主要为两种:编译器优化和CPU执行优化。优化屏障避免编译的重新排序优化操作,保证编译程序时在优化屏障之前的指令不会在优化屏障之后执行。
编译器优化:提高系统的性能,编译器在不影响逻辑的情况下会调整指令的顺序。
CPU执行优化:提高流水线的性能,CPU的乱序执行可能会让后面的没有寄存器冲突的汇编指令先于前面的指令完成。
Linux 使用宏 barrier 实现优化屏障,如 gcc 编译器的优化屏障宏定义:

barrier 插入一个优化屏障,该指令告知编译器,保存在 CPU 寄存器中、在屏障之前有效的所有的内存地址,在屏障之后全部都会消失。本质,意味着编译器在屏障之前发出的读写请求完成之前,会处理屏障之后 的任何读写请求。
关键字为_volatile_告诉编译器:禁止优化代码,不需要改变barier()前面的代码块、barier()和后面的代码块这3个代码块的顺序。
内存屏障:也称内存栅障或屏障指令等,是一类同步屏障指令,是编译器或CPU对内存访问操作的时候,严格按照一定顺序来执行,也就是 memory barrier 之前的指令和 memory barrier 之后的指令不会由于系统优化等原因而导致乱序。
A、编译器编译代码时可能重新排序汇编指令,使编译出来的程序在处理器上执行速度更快,但是有的时候优化结果可能不符合软件开发工程师意图。
B、新式处理器采用超标量体系结构和乱序执行技术,能够在一个时钟周期并行执行多条指令。一句话总结为:顺序取指令,乱序执行,顺序提交执行结果。
C、多处理器系统当中,硬件工程师使用存储缓冲区、使无效队列协助缓存和缓存一致性协议实现高效性能,引入处理器之间的内存访问乱序问题。


处理器内存屏障:解决CPU之间的内存访问乱序问题和处理器访问外围设备的乱序问题。

除数据依赖屏障之外,所有处理器内存屏障隐含编译器优化屏障。
内核内存布局与堆管理
Shell 命令了解系统信息
cat /proc/cpuinfo 查看系统 cpu 信息


vendor_id :CPU制造商
cpu family :CPU产品系列代号
model :CPU属于其系列中的哪一代的代号
model name:CPU属于的名字及其编号、标称主频
stepping :CPU属于制作更新版本
cpu MHz :CPU的实际使用主频
cache size :CPU二级缓存大小
physical id :单个CPU的标号
siblings :单个CPU逻辑物理核数
core id :当前物理核在其所处CPU中的编号,这个编号不一定连续
cpu cores :该逻辑核所处CPU的物理核数
apicid :用来区分不同逻辑核的编号,系统中每个逻辑核的此编号必然不同,此编号不一定连续
fpu :是否具有浮点运算单元(Floating Point Unit)
fpu_exception :是否支持浮点计算异常
cpuid level :执行cpuid指令前,eax寄存器中的值,根据不同的值cpuid指令会返回不同的内容
wp :表明当前CPU是否在内核态支持对用户空间的写保护(Write Protection)
flags :当前CPU支持的功能
bogomips :在系统内核启动时粗略测算的CPU速度(Million Instructions Per Second)
clflush size :每次刷新缓存的大小单位
cache_alignment :缓存地址对齐单位
address sizes :可访问地址空间位数
https://blog.csdn.net/oy5348/article/details/84112396
cat /proc/meminfo 了解 Linux 系统内存使用状况的主要接口

MemTotal: 所有可用内存空间的大小
MemFree: 系统还没有使用的内存
MemAvailable: 真正系统可用内存
Buffers: 专门用来给块设备做缓存的内存
Cached: 分配给文件缓冲区的内存
SwapCached: 被高速缓冲缓存使用的交换空间大小
Active: 使用高速缓冲存储器页面文件大小
Inactive: 没有使用的高速缓存存储器大小
Active(anon): 活跃的匿名内存
Inactive(anon): 不活跃的匿名内存
Active(file): 活跃的文件使用内存
Inactive(file): 不活跃的文件使用内存
Unevictable: 不能释放的内存页
Mlocked: 系统调用 mlock 允许程序在物理内存上锁住部分或全部地址空间
SwapTotal: 交换空间总内存大小
SwapFree: 交换空间空闲的内存大小
Dirty: 等待被写回到磁盘
Writeback: 正在被写回的大小
AnonPages: 未映射页的内存/映射到用户空间的非文件页表大小
Mapped: 映射文件内存
Shmem: 已经被分配的共享内存
KReclaimable: 可回收的 Slab 内存
Slab: 内存数据结构缓存大小

CommitLimit: 系统实际可以分配的内存
Committed_AS: 系统当前已经分配的内存
VmallocTotal: 预留虚拟内存的总量
VmallocUsed: 已经被使用的虚拟内存
VmallocChunk: 可分配的最大逻辑地址连续的虚拟内存
Linux内核动态内存分配通过系统接口实现
alloc_pages/get free_page:以页为单位分配
vmalloc:以字节为单位分配虚拟地址连续的内存块
kmalloc:以字节为单位分配物理地址连续的内存块,它是以slab为中心

ARM64架构处理器采用 48 位物理寻址机制,最大可寻找256TB的物理地址空间。对于目前应用完全足够,不需要扩展到64位的物理寻址。虚拟地址也同样最大支持 48 位寻址,所以在处理器架构设计上,把虚拟地址空间划分为两个空间,每个空间最大支持256TB,linux内核在大多数体系结构上都把两个地址划分为:用户空间和内核空间。
用户空间:0x0000_0000_0000_0000 至 0x0000_ffff_ffff_ffff。
内核空间:0xffff_0000_0000_0000至0xffff_ffff_ffff_ffff。
堆管理
堆是进程中主要用于动态分配变量和数据的内存区域,堆的管理对应程序员不是直接可见的。因为它依赖标准库提供的各个辅助函数(其中最重要的是malloc)来分配任意长度的内存区。malloc 和 内核之间的经典接口是brk系统调用,负责扩展/收缩堆。
堆是一个连续的内存区域,在扩展时自下至上增长。其中mm_struct结构,包含堆在虚拟地址空间中的起始和当前结束地址(start_brk和brk)。
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
u64 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif

Linux 系统中两个创建堆的方法:
brk系统调用用于指定堆在虚拟地址空间中新的结束地址(如果堆将要收缩,当然可以小于当前值)。brk系统调用通过do_brk增长动态分配区。

mmap()向操作系统申请一段虚拟地址空间(使用映射到某个文件)。当不用此空间来映射到某个文件时,这块空间称为匿名空间可以用来作为堆空间。
per-CPU 计数器
操作系统中有多个 CPU,假设只有一个 CPU 计数器工作 , 如果某个 CPU 正在访问计数器,其它 CPU 需要等待计数器释放才能访问 CPU 计数器,这里 CPU 计数器会出现瓶颈,影响系统性能 ;
Linux 内核中,引入了per-CPU 计数器,用于加速 SMP 系统的计数器操作 ;
per_cpu 机制 就是让每个CPU都有自己的私有数据段,便于保护与访问。每个处理器变量为每个cpu都生成一个变量的副本,每个处理器使用自己的副本,从而避免了处理器之间的互斥和同步,提高了程序的执行速度。
基本原理:计数器的准确值存储在内存中某一个地址,准确值所在内存位置之后是一个数组,每个数组项对应于系统中的一个CPU。【计数器有个总的计数值,每个处理器有一个临时计数值,每个处理器先把计数累加到自己的临时计数值上,当临时计数值达到或超过阈值的时候,再把临时计数值累加到总计数值上】

raw_spinlock_t lock 是一个 自旋锁 ;
s64 count 是计数器的值 ;
多核调度分析
超线程(SMT,Simultaneous Multithreading):超线程是一种技术,允许单个物理处理器核心模拟出多个逻辑处理器核心。这意味着在一个物理处理器核心上可以并行执行多个线程,从而提高处理器的利用率和性能。在 Linux 内核中,针对超线程技术,可以使用 CONFIG_SCHED_SMT 进行分类和配置。
多核(MC,Multiple Cores):多核处理器是指在一个集成电路芯片上集成了多个独立的物理处理器核心。每个核心都可以独立地执行任务,因此多核处理器可以同时处理多个线程或进程,从而提高系统的并行处理能力和整体性能。在Linux内核中,针对多核处理器,可以使用CONFIG_SCHED_MC进分类和配置。
Linux内 核对CPU管理主要是通过使用bitmap来实现,同时定义了四种状态:possible、online、active、present。

Linux 内核把所有同一级别的CPU归纳为一个调度组,然后把同一个级别的调度组组成一个调度域。
调度组是一组具有相似特性的CPU核心。比如,它们可能位于同一个物理芯片上、共享同一个高速缓存等。通过将这些核心组织在一起,内核可以更有效地进行资源分配和任务调度。调度组通常由内核自动创建,并根据硬件拓扑关系进行组织。
调度域是一组调度组的集合,它们具有相同的调度策略和目标。调度域用于确定任务在系统中的调度范围和选择可用的CPU核心。通过将调度组组合在一起,内核可以更好地控制任务的调度和负载均衡。
处理器拓扑结构是指处理器内部各个组件之间的连接关系和层次结构。在多核处理器中,常见的两种拓扑结构是NUMA(Non-Uniform Memory Access)和SMP(Symmetric Multiprocessing)。
NUMA结构:在NUMA结构中,处理器由多个物理节点组成,每个节点包含一部分处理器核心、内存和I/O设备。不同节点之间的访问延迟和带宽不同,因此是“非均匀内存访问”结构。在NUMA结构下,任务调度算法需要考虑到任务在不同节点之间的迁移和负载均衡,以优化系统性能。
SMP结构:在SMP结构中,所有处理器核心都共享同一个物理地址空间,内存访问延迟和带宽相同,因此是“对称多处理”结构。在SMP结构下,任务调度算法可以采用简单的轮转或抢占式算法来实现任务的负载均衡。
https://blog.csdn.net/weixin_52622200/article/details/135886010
内核数据结构
红黑树。。。。
进程管理常用 API
find_get_pid(...):根据进程编号获取对应的进程描述符;
获取进程描述符,且描述符的count+1,表示进程多一个用户
struct pid *find_get_pid(pid_t nr) // nr 进程对应的进程编号
{
struct pid *pid;
rcu_read_lock();
pid = get_pid(find_vpid(nr)); // 调用get_pid增加引用计数操作
rcu_read_unlock();
return pid;
}
struct pid
{
refcount_t count; // 引用计数
unsigned int level; // 所属 pid namespace 的层级
spinlock_t lock;
/* lists of tasks that use this pid */
struct hlist_head tasks[PIDTYPE_MAX]; // 每种类型 pid 哈希表头
struct hlist_head inodes;
/* wait queue for pidfd notifications */
wait_queue_head_t wait_pidfd;
struct rcu_head rcu;
struct upid numbers[1];
};
pid_task(...):获取任务的任务描述符数据信息;
struct task_struct *pid_task(struct pid *pid, enum pid_type type)
{ // 参数 pid:pid 类型指针变量,存储进程描述符的数据信息
// 参数 type: pid_ type类型变量
struct task_struct *result = NULL;
if (pid) {
struct hlist_node *first;
first = rcu_dereference_check(hlist_first_rcu(&pid->tasks[type]),
lockdep_tasklist_lock_is_held());
if (first)
result = hlist_entry(first, struct task_struct, pid_links[(type)]);
}
return result;
}
enum pid_type {PIDTYPE_PID = 0, PIDTYPE_TGID, PIDTYPE_PGID};
// 进程号、线程组ID、进程组ID
pid_nr(...):获取进程的全局进程号,也就是从init 所在的namespace看到的pid号;
static inline pid_t pid_nr(struct pid *pid)
{
pid_t nr = 0;
if (pid)
nr = pid->numbers[0].nr;
return nr;
}
__task_pid_nr_ns(...):获取进程编号;
pid_t __task_pid_nr_ns(struct task_struct *task, enum pid_type type,
struct pid_namespace *ns)
{
pid_t nr = 0;
rcu_read_lock();
if (!ns)
ns = task_active_pid_ns(current);
nr = pid_nr_ns(rcu_dereference(*task_pid_ptr(task, type)), ns);
rcu_read_unlock();
return nr;
}
进程调度常用 API
kthread_create_on_node:创建线程;
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node,
const char namefmt[],
...)
{
struct task_struct *task;
va_list args;
va_start(args, namefmt);
task = __kthread_create_on_node(threadfn, data, node, namefmt, args);
va_end(args);
return task;
}
需要注意,__kthread_create_on_node()函数并不执行真正的内核线程创建,而是创建一个对象,然后把对象递交一个链表上面,唤醒创建内核线程的线程来执行创建。而原先的创建者则进行等待。
wake_up_process:一般当队列里面为空的时候,核心调度器(是否是核心调度器还需要后续去confirm)会在已经睡眠的task中通过调用wake_up_process函数将其唤醒,然后选择合适的cpu来运行。
int wake_up_process(struct task_struct *p)
{
/*wake_up_process直接调用try_to_wake_up函数,并添加三个限定参数*/
return try_to_wake_up(p, TASK_NORMAL, 0, 1);
}
EXPORT_SYMBOL(wake_up_process);
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags,
int sibling_count_hint)
{
unsigned long flags;
int cpu, success = 0;
/*
* If we are going to wake up a thread waiting for CONDITION we
* need to ensure that CONDITION=1 done by the caller can not be
* reordered with p->state check below. This pairs with mb() in
* set_current_state() the waiting thread does.
*/
raw_spin_lock_irqsave(&p->pi_lock, flags);
/*很有可能需要唤醒一个thread的函数,某个条件必须成立,为了取到最新的没有没优化
的条件数值,使用内存屏障来实现.*/
smp_mb__after_spinlock();
/*如果进程不是在:TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE下,则就不是normal
task,直接退出wakeup流程.所以在内核里面看到的wake_up_process,可以看到起主函数都会
将进程设置为TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE这两种状态之一*/
if (!(p->state & state))
goto out;
trace_sched_waking(p);
/* We're going to change ->state: */
success = 1;
/*获取这个进程当前处在的cpu上面,并不是时候进程就在这个cpu上运行,后面会挑选cpu*/
cpu = task_cpu(p);
/*
* Ensure we load p->on_rq _after_ p->state, otherwise it would
* be possible to, falsely, observe p->on_rq == 0 and get stuck
* in smp_cond_load_acquire() below.
*
* sched_ttwu_pending() try_to_wake_up()
* [S] p->on_rq = 1; [L] P->state
* UNLOCK rq->lock -----.
* \
* +--- RMB
* schedule() /
* LOCK rq->lock -----'
* UNLOCK rq->lock
*
* [task p]
* [S] p->state = UNINTERRUPTIBLE [L] p->on_rq
*
* Pairs with the UNLOCK+LOCK on rq->lock from the
* last wakeup of our task and the schedule that got our task
* current.
*/
smp_rmb();
/*使用内存屏障保证p->on_rq的数值是最新的.如果task已经在rq里面,即进程已经处于
runnable/running状态.ttwu_remote目的是由于task p已经在rq里面了,并且并没有完全
取消调度,再次会wakeup的话,需要将task的状态翻转,将状态设置为TASK_RUNNING,这样
task就一直在rq里面运行了.这种情况直接退出下面的流程,并对调度状态/数据进行统计*/
if (p->on_rq && ttwu_remote(p, wake_flags))
goto stat;
#ifdef CONFIG_SMP
/*
* Ensure we load p->on_cpu _after_ p->on_rq, otherwise it would be
* possible to, falsely, observe p->on_cpu == 0.
*
* One must be running (->on_cpu == 1) in order to remove oneself
* from the runqueue.
*
* [S] ->on_cpu = 1; [L] ->on_rq
* UNLOCK rq->lock
* RMB
* LOCK rq->lock
* [S] ->on_rq = 0; [L] ->on_cpu
*
* Pairs with the full barrier implied in the UNLOCK+LOCK on rq->lock
* from the consecutive calls to schedule(); the first switching to our
* task, the second putting it to sleep.
*/
smp_rmb();
/*
* If the owning (remote) CPU is still in the middle of schedule() with
* this task as prev, wait until its done referencing the task.
*
* Pairs with the smp_store_release() in finish_lock_switch().
*
* This ensures that tasks getting woken will be fully ordered against
* their previous state and preserve Program Order.
*/
smp_cond_load_acquire(&p->on_cpu, !VAL);
walt_try_to_wake_up(p);
p->sched_contributes_to_load = !!task_contributes_to_load(p);
p->state = TASK_WAKING;
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
/*根据进程p相关参数设定和系统状态,为进程p选择合适的cpu供其运行*/
cpu = select_task_rq(p, p->wake_cpu, SD_BALANCE_WAKE, wake_flags,
sibling_count_hint);
/*如果选择的cpu与进程p当前所在的cpu不相同,则将进程的wake_flags标记添加需要迁移
,并将进程p迁移到cpu上.*/
if (task_cpu(p) != cpu) {
wake_flags |= WF_MIGRATED;
psi_ttwu_dequeue(p);
set_task_cpu(p, cpu);
}
#else /* CONFIG_SMP */
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
#endif /* CONFIG_SMP */
/*进程p入队操作并标记p为runnable状态,同时执行wakeup preemption,即唤醒抢占.*/
ttwu_queue(p, cpu, wake_flags);
stat:
/*调度相关的统计*/
ttwu_stat(p, cpu, wake_flags);
out:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
return success;
}
。。。用的时候再学吧
零声教育的视频:Linux内核源码