池化技术

池化技术是一种编程技巧,一般用于优化资源的分配与复用;
当一种资源需要被使用时这意味着这个资源可能会被进行多次使用或者需要同时使用多个该资源,当出现这种情况时内核将会频繁的对该资源进行申请并释放,大大降低整体的效率;
池化技术旨在预先分配一组资源,当用户层需要使用这些资源时将直接对预先分配资源进行使用;
若是预先分配资源不足以当前使用情况时将再次申请一批,动态增长的资源在使用过后将被释放以保证不出现资源浪费情况;
所用资源的数量始终>=预先分配的资源数量;
实现以下几点:
- 减少资源申请及释放
- 提高资源使用效率
- 资源数量控制
- 资源动态拓展
常见的池化技术有如下:
进程池
适用于大量进程执行短期任务的情况;
内存池
预先分配一大块内存,然后在这块内存当中划分出多个小块内存用于动态分配与回收;
线程池
适用于任务处理不需要大量资源单需要大量并发执行情况;
进程池
进程池是一种用于并发执行的资源池技术;
预先创建一定数量的进程用于执行提交给进程池的任务;
这些进程在池中保持活跃状态并可以快速响应并执行任务而不需要每次任务到来时再创建新的进程从而提高整体工作效率;
进程池通常用于以下几种情况:
性能提高
进程的创建与销毁具有开销,尤其在高负载或多任务并发的场景中使用进程池可以避免频繁的 创建/销毁 进程从而提高系统性能;
资源限制
限制进程池的大小可以避免系统资源(CPU,内存等)被过度消耗;
负载均衡
进程池可以通过系统负载情况动态分配任务,使各个进程的工作量保持均衡;
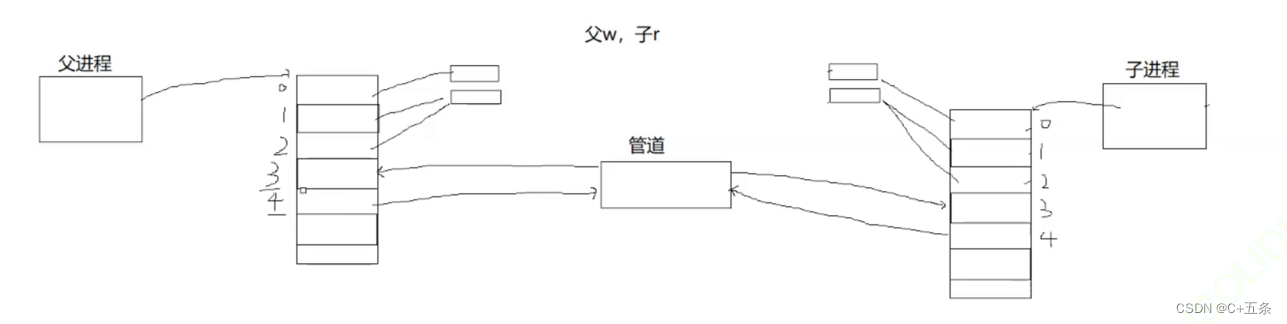
本文模拟实现的进程池通过多个匿名管道实现进程间通信使得一个进程与多个其对应的血缘关系进程进行协同从而形成一个进程池[父写子读];

框架及基本思路
创建文件
ProcessPool.cc本程序不采用声明与定义分离的思路,该文件用于
main函数以及对应的接口函数的声明及其实现定义;Task.hpp用于设计需要投喂给进程池的任务列表;
整体构造采用先描述后组织的方式对进程池进行设置,并以自顶向下的方式进行设计,即先将所需接口以声明的形式标出而后再对接口进行具体实现;
总体为:
#define PROCESSNUM 5 // 控制子进程创建个数
/* 设计为默认预分配5个进程 */
/*
...描述
*/
int main() {
// 初始化任务列表
LoadTask(&tasks);
// 组织
// 0.以数据结构的形式将进程进行组织
std::vector<channel> channels;
// 1.初始化进程池
InitProcessPool(&channels);
// 2.控制子进程
ControlSlaver(channels);
// 3.清理收尾
QuitProcess(channels);
return 0;
}
基本思路为父进程调用pipe()系统调用接口创建管道文件;
再根据进程池的进程数量通过循环调用fork()系统调用接口创建子进程,再根据数据流向调用close()系统调用接口关闭不需要的文件描述符使得父进程能与每个创建的子进程利用管道文件相连接从而构成单向管道通信信道;
当子进程与对应的通信信道被建立后父进程根据描述将子进程以数据结构的方式进行管理;
父进程继续执行后面的代码用于对子进程发送任务,子进程通过循环使其保持活跃状态并等待父进程向管道发送任务并对任务进行处理;
当识别到对应的退出指令后父进程对进程池进行清理同时调用wait()系统调用接口等待并回收子进程;
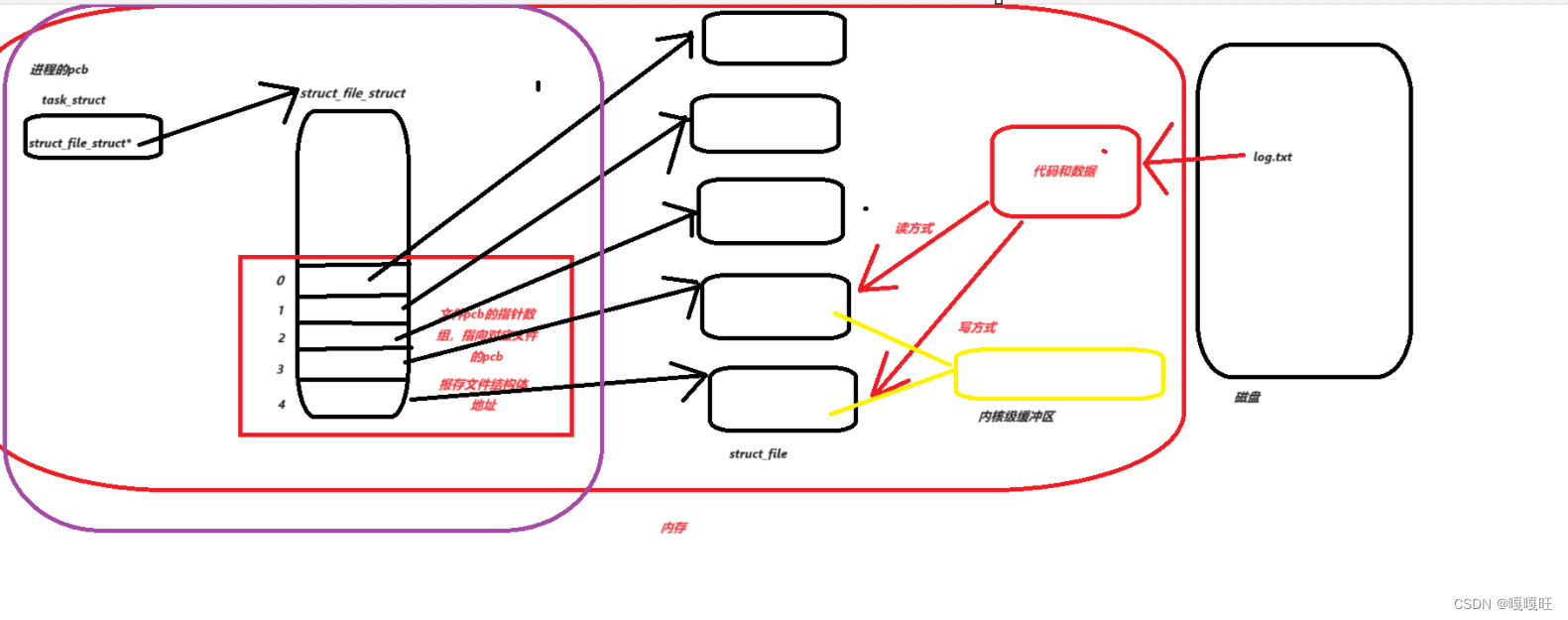
进程的描述
一个进程再被组织与管理前需要被进行描述;
基本的信息为:
- 发送任务用的文件描述符
- 进程的
PID - 进程名
- …
#include "Task.hpp"
#include <unistd.h>
#include <cassert>
#include <string>
#include <vector>
#include <cstdlib>
#include <ctime>
#include <sys/wait.h>
#include <sys/stat.h>
#define PROCESSNUM 5 // 控制子进程创建个数
// 描述
class channel {
public:
// 构造函数
channel(int cmdfd, pid_t slaveryid, const std::string& processname)
: _cmdfd(cmdfd), _slaveryid(slaveryid), _processname(processname) {}
public:
int _cmdfd; // 发送任务用文件描述符
pid_t _slaveryid; // 进程的pid
std::string _processname; // 进程名
};
int main() {
// 初始化任务列表
LoadTask(&tasks);
// 组织
std::vector<channel> channels;
InitProcessPool(&channels);
// 2.控制子进程
ControlSlaver(channels);
// 3.清理收尾
// sleep(1000);
QuitProcess(channels);
return 0;
}
组织
组织的方式为现将所需的进程调用fork()系统调用接口再将用数据结构将其进行组织以方便后期控制子进程以及管理子进程;
void InitProcessPool(std::vector<channel>* channels) {
// 1.初始化
pid_t id = fork();
if (id < 0) {
// 进程创建失败
std::cerr << "fork errno" << std::endl;
assert(id >= 0); // 差错处理 子进程创建失败
}
if (id == 0) {
// 子进程
close(pipefd[1]);
// 子进程读 关闭[1]
/*
slaver(pipefd[0]);
这是一种做法 为从这个描述符当中读取任务数据并执行任务
*/
dup2(pipefd[0], 0);
// 该种做法为 使用dup2接口进行重定向
// 使得子进程的默认输入从键盘改为pipefd[0]中读取
slaver();//默认从文件描述符0 获取任务信息即可
std::cout << "Process : " << getpid() << " quit sucess" << std::endl;
exit(0);
}
// 父进程
close(pipefd[0]); // 父进程关闭读端
// 添加字段
std::string name = "Process" + std::to_string(i);
channels->push_back(channel(pipefd[1], id, name)); // 调用构造函数进行初始化
}
}
int main(){
//...
std::vector<channel> channels;
InitProcessPool(&channels);
//...
return 0;
}
子进程创建后采用数据结构进行管理;
本文中实现的进程池对于管道数据流向为 父写子读 ;
使用if()条件判断区别父子进程,父进程在执行完对应的代码后将自己部分的该函数的栈帧进行销毁;
而子进程将调用slaver()函数从对应的文件描述符中读取父进程写进管道中的数据及任务;
对于父进程而言其管理着channel数组,数组中存放着所有当前子进程的所有信息;
可debug来尝试查看对应的channel数组中所存储的信息;
/* 在main函数中进行调用 */
void Debug(const std::vector<channel>& channels) {
for (auto& c : channels) {
std::cout << "cmdfd : " << c._cmdfd << std::endl
<< "slaveryid : " << c._slaveryid << std::endl
<< "processname : " << c._processname << std::endl;
std::cout << "---------------------" << std::endl;
}
}
debug后的结果为:
cmdfd : 4
slaveryid : 9619
processname : Process0
---------------------
cmdfd : 5
slaveryid : 9620
processname : Process1
---------------------
cmdfd : 6
slaveryid : 9621
processname : Process2
---------------------
cmdfd : 7
slaveryid : 9622
processname : Process3
---------------------
cmdfd : 8
slaveryid : 9623
processname : Process4
---------------------
结果中父进程将通过文件描述符 4 ~ 8 向各个子进程发送数据,这些文件描述符是管道的写端;
子进程将从文件描述符 3 读取数据;
slaver()为子进程读取对应文件描述符,其需要传入一个参数为文件描述符fd;
子进程读取管道数据的方式有两种:
从文件描述符
3中读取这个数组是一个临时的空间,存放着管道文件的读写文件描述符,需要父子进程根据数据流向来关闭另外一个不需要的文件描述符;
本文中的文件描述符中父进程为写方,需要关闭文件描述符
pipefd[0]即读端,而子进程需要关闭写端,但其可以从文件描述符3也就是pipefd[1]中读取父进程写入管道的数据,但需在调用slaver()函数时传入对应的文件描述符即调用
slaver(pipefd[1])即可;从文件描述符
0中读取文件描述符
0一般作为标准输入,默认从键盘等文件进行读取;即调用
dup2()系统调用接口将文件描述符3重定向至文件描述符0,以减少调用slaver()函数的传参步骤,变相减少程序的可维护成本;
管道通信建立的潜在问题
在组织的初始化中存在一个问题,即子进程将冗余存在多个写端;
子进程为父进程的一份拷贝,当父子进程中其中一个进程被修改时(即对物理内存进行修改);
为了避免一个进程的写入操作影响到另一个进程,将会发生写时拷贝操作(不是本节重点);
管道文件是一种内存级文件,没有实质的Inode与对应的 数据块 ;
但是其写入与读取的操作是根据文件描述符进行的,在进行fork()系统调用接口创建子进程时文件描述符也会被拷贝一份,这造成了子进程中存在着冗余的写端(继承其父进程的写端);

本文设计的进程池为退出时父进程关闭写端从而使子进程读端读取失败即读取到文件末尾并返回0后逐步回收子进程;
但出现文件描述符冗余情况时父进程关闭写端时依旧可能有其他子进程指向该位置的写端从而导致无法正常将程序退出;
解决办法有两种:
倒序关闭文件描述符
int main(){ // 初始化任务列表... // 组织... // 2.控制子进程... // 3.清理收尾... int last = channels.size()-1; for (; last >= 0;--last){ close(channels[last]._cmdfd); sleep(3); waitpid(channels[last]._slaveryid, nullptr, 0); sleep(3); } /* 采用倒序关闭文件描述符的方法确实可以确保在结束时逐一关闭每个子进程对应的写端 这会导致子进程读端在读到文件结尾(EOF)时退出循环 并且子进程会调用 exit(0) 进入僵尸状态等待父进程回收 */ for(const auto &c:channels ){ close(c._cmdfd); }ss sleep(5); for (const auto& c : channels) { waitpid(c._slaveryid, nullptr, 0); } sleep(5); return 0; }在父进程发出退出指令时倒序遍历
channel数组,父进程依次关闭对应的写端,当关闭最后一个进程的写端时其读端将会读取到0,而后根据程序设计对资源进行回收;当该子进程退出时其指向上一个管道文件的写端指向将消失,而后依次进行回收;

该方法可以使得程序正常退出,但无法解决实质性问题即父子进程中建立的为单向通信信道,在程序运行中不符合管道的单向信道规范;
在初始化中关闭多余的文件描述符
在初始化中关闭文件描述符可以保证程序在运行当中可以存在正确的单向通信规范;
具体操作为父进程采用数据结构保留对应的写端文件描述符,并在下次
fork()创建子进程时在子进程中遍历数组从而能够关闭对应的文件描述符;void InitProcessPool(std::vector<channel>* channels) { // 1.初始化 //version 2 -- 确保每个子进程只有一个写端 std::vector<int> oldfds; for (int i = 0; i < PROCESSNUM; ++i) { // 子进程创建时先创建管道 int pipefd[2]; int n = pipe(pipefd); assert(!n); // 差错处理 pipe创建管道失败 (void)n; pid_t id = fork(); if (id < 0) { // 进程创建失败 std::cerr << "fork errno" << std::endl; assert(id >= 0); // 差错处理 子进程创建失败 } if (id == 0) { // 子进程 close(pipefd[1]); for(const auto& fd:oldfds){ close(fd); /* 这里的close不会调用失败 在下文中的oldfds数组将会记录父进程对上一个子进程的写端 所以会导致子进程会对其他子进程存在写端 所以这里的close并不会调用失败 因为对于每个子进程而言 数组中的所有文件描述符都是有效的文件描述符 */ } // 子进程读 关闭[1] /* slaver(pipefd[0]); 这是一种做法 为从这个描述符当中读取任务数据并执行任务 */ dup2(pipefd[0], 0); // 该种做法为 使用dup2接口进行重定向 // 使得子进程的默认输入从键盘改为pipefd[0]中读取 slaver();//默认从文件描述符0 获取任务信息即可 std::cout << "Process : " << getpid() << " quit sucess" << std::endl; exit(0); } // 父进程 close(pipefd[0]); // 父进程关闭读端 // 添加字段 std::string name = "Process" + std::to_string(i); channels->push_back(channel(pipefd[1], id, name)); // 进行初初始化 oldfds.push_back(pipefd[1]); // Debug // std::cout << "==============================" << std::endl; // std::cout << "对oldfds数组进行打印 [" << debugn <<"]@ "<< std::endl; // debugn++; // for (const auto& fd : oldfds) { // std::cout << fd << std::endl; // } // std::cout << "==============================" << std::endl; } }
任务的描述与组织
任务的描述与组织在Task.hpp文件当中;
思路为以数据结构和函数指针相配合的方式将函数(任务)以加载的方式进行管理(在main函数所在文件中需要注意使用extern声明);
/* ######## */
/* Task.hpp */
/* ######## */
#pragma once
#include <iostream>
#include <vector>
typedef void (*task_t)(); // 定义函数指针
void task1() {
std::cout << "任务1 : 数据初始化(Data Initialization)" << std::endl;
}
void task2(){
std::cout << "任务2 : 更新数据(Update Data)" << std::endl;
}
void task3(){
std::cout << "任务3 : 获取数据(Retrieve Data)" << std::endl;
}
void task4(){
std::cout << "任务4 : 数据验证(Data Validation)" << std::endl;
}
void task5(){
std::cout << "任务5 : 生成报告(Generate Report)" << std::endl;
}
void task6(){
std::cout << "任务6 : 备份数据(Backup Data)" << std::endl;
}
void LoadTask(std::vector<task_t> *tasks){
tasks->push_back(task1);
tasks->push_back(task2);
tasks->push_back(task3);
tasks->push_back(task4);
tasks->push_back(task5);
tasks->push_back(task6);
}
该处task数组中的下标即为任务码;
通过数组的形式访问函数指针从而调用对应函数;
子进程读取管道信息
void slaver() {
// 子进程读取父进程向管道内写入的信息
while (true) {
/*
debug
//每个子进程都将从文件描述符rfd中进行读取
在当前程序中 rfd为3
重定向后为0
// std::cout << getpid() << " - read fd is : " << rfd << std::endl;
*/
int cmdcode = 0;
int n = read(0,&cmdcode,sizeof(int));
if(n == sizeof(int)){
//执行cmdcode对应的任务列表
std::cout <<"slaver get a cmdcode @["<< getpid() << "] : cmdcode : " << cmdcode << std :: endl;
if (cmdcode < 0 || cmdcode > (int)tasks.size()) continue;
tasks[cmdcode]();//指针数组
std::cout << "--------------------------" << std::endl;
}
if(n == 0)//说明写端被关闭 0表示文件结尾
break;
// sleep(100);
}
}
以循环的方式通过调用read()系统调用接口分别向各自管道内读取数据,若是管道不存在数据则进行等待(默认行为),意味着子进程不需要调用sleep()等接口来进行时间的延长;
子进程读取到对应信息时将对数据进行分析并进行处理(根据需求,当前简易进程池中不需要对数据进行分析);
当读取到0时说明读取到文件末尾,即写端被关闭,此时子进程退出并进入僵尸状态等待被父进程回收;
控制子进程
子进程可以读取父进程写入管道文件的数据时父进程可以根据需求将对应的任务码通过write()系统调用接口写入管道文件当中并等待子进程读取处理;
该处为三步操作:
选择任务
任务即为
tasks函数指针数组中所存储的各个函数指针;通过下标的方式进行选择,其中下标即为任务对应的任务码;
选择进程
为避免多个任务在同一个进程下进行等待而降低效率,进程的选择需要依靠负载均衡;
常见的负载均衡包括:
随机
通过伪随机或是真随机的方式为各个子进程分配任务;
轮询/轮转
通过轮询/轮转的方式时多个子进程为一个周期轮流分配任务;
最少连接
选择当前连接数(需处理数据数量)最少的进程优先为其分配任务;
…
发送任务(任务码)
调用
write()系统调用接口将任务码和所需数据写入至管道文件中;
void ControlSlaver(const std::vector<channel> &channels){
//向子进程派发任务
//需要随机
Menu();
for (int i = 1; i <= 100; ++i) {
//(1) 选择任务
// int cmdcode = rand() % tasks.size();
std::cout << "Please Enter your choic :";
int choice = 0;
std::cin >> choice;
if(choice==0){
std::cout << "正在退出" << std::endl;
return;
}
choice -= 1;
//(2) 选择进程 -- 需要负载均衡 (随机数或是轮询 此处使用随机)
int fd = rand() % PROCESSNUM;
//(3) 发送任务 (任务码)
std::cout << "Parent Process say : " << std::endl
<< "cmdcode = " << choice << " alread sendto "
<< channels[fd]._processname << channels[fd]._slaveryid
<< std::endl;
write(channels[fd]._cmdfd, &choice, sizeof(choice));
sleep(1);
}
}
需要时可在控制接口中打印菜单:
void Menu(){
std::cout << "#############################################\n";
std::cout << "# 主菜单 #\n";
std::cout << "#############################################\n";
std::cout << "# 1. 数据初始化 #\n";
std::cout << "# 2. 更新数据 #\n";
std::cout << "# 3. 获取数据 #\n";
std::cout << "# 4. 数据验证 #\n";
std::cout << "# 5. 生成报告 #\n";
std::cout << "# 6. 备份数据 #\n";
std::cout << "# 0. 退出 #\n";
std::cout << "#############################################\n";
}
进程退出及资源回收
两种回收方式:
倒序关闭文件描述符
参考上文,此处不赘述;
正常退出回收
正常回收的情况下父子进程间的匿名管道必须是单向信道;
即当进程池的一批子进程被创建完毕后应及时对冗余的写端(子进程的)进行关闭;
即可正常回收;
退出与回收即为父进程遍历对应的channels数组,将对应的写端(文件描述符)进行关闭;
当关闭文件描述符时读端(子进程)的read()系统调用接口将默认读取到0表示读取到了文件结束符号,在子进程的slaver()接口中根据依次判断是否读取到0来依次退出子进程的循环,使得子进程正常退出进入僵尸状态;
父进程则调用waitpid()系统调用接口轮流回收已经进入僵尸状态的子进程;
void QuitProcess(const std::vector<channel> channels)
{
// 正常回收 - 对应的需要在一批子进程被创建完毕后应及时对冗余的写端(子进程的)进行关闭
for(const auto &c:channels ){
close(c._cmdfd);
waitpid(c._slaveryid, nullptr, 0);
}
// // version 1 - 倒序关闭文件描述符回收法
// int last = channels.size()-1;
// for (; last >= 0;--last){
// close(channels[last]._cmdfd);
// sleep(3);
// waitpid(channels[last]._slaveryid, nullptr, 0);
// sleep(3);
// }
// /*
// 采用倒序关闭文件描述符的方法确实可以确保在结束时逐一关闭每个子进程对应的写端
// 这会导致子进程读端在读到文件结尾(EOF)时退出循环
// 并且子进程会调用 exit(0)
// 进入僵尸状态等待父进程回收
// */
// for(const auto &c:channels ){
// close(c._cmdfd);
// }ss
// sleep(5);
// for (const auto& c : channels) {
// waitpid(c._slaveryid, nullptr, 0);
// }
// sleep(5);
}
- 完整代码(供参考):
[参考代码(gitee) - DIo夹心小面包 (半介莽夫)]




































![[SWPUCTF 2021 新生赛]ez_unserialize](https://img-blog.csdnimg.cn/img_convert/0460a0c3a400e4625f39df0af39a7c98.png)