一、逻辑回归概述
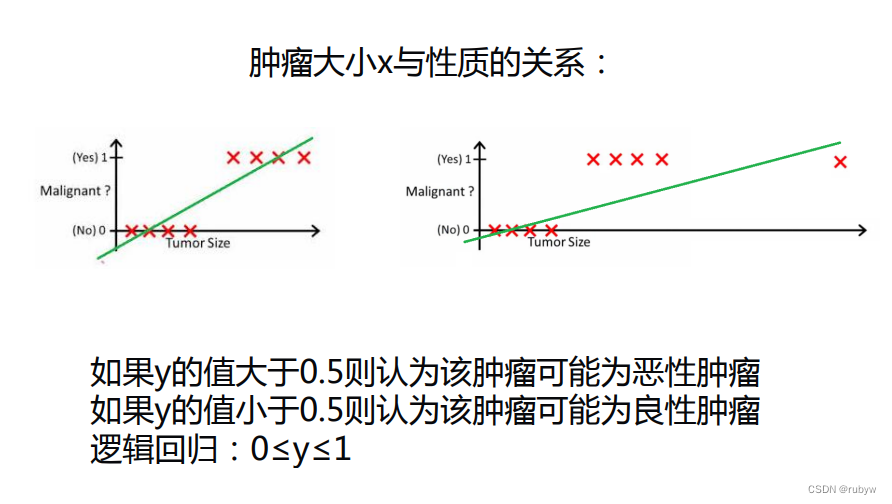
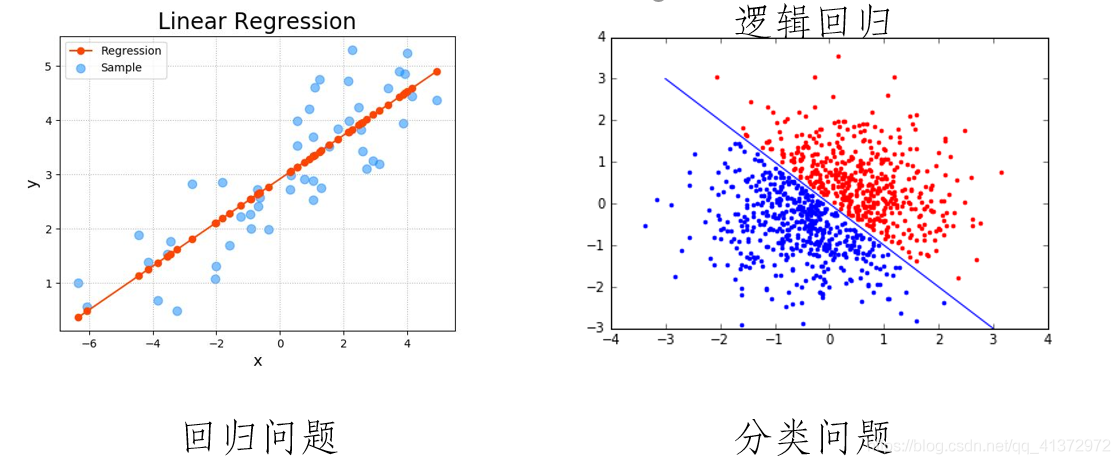
逻辑回归是一种常用于分类问题的算法。大家熟悉的线性回归一般形式为 Y = a X + b \mathbf{Y} = \mathbf{aX} + \mathbf{b} Y=aX+b,其输出范围是 [ − ∞ , + ∞ ] [-∞, +∞] [−∞,+∞]。然而,对于分类问题,我们需要将输出结果映射到一个有限的区间,这样才能实现分类。
这时候,我们可以借助一个非线性变换函数,即 Sigmoid 函数。Sigmoid 函数的定义为:
S ( Y ) = 1 1 + e − Y \mathbf{S(Y)} = \frac{1}{1 + e^{-\mathbf{Y}}} S(Y)=1+e−Y1
该函数可以将任意实数映射到 [ 0 , 1 ] [0, 1] [0,1] 区间内。我们可以将线性回归模型的输出 Y \mathbf{Y} Y 带入 Sigmoid 函数,得到一个介于 [ 0 , 1 ] [0, 1] [0,1] 之间的值 S \mathbf{S} S,这个值可以解释为一个概率。
在实际应用中,我们通常将 S \mathbf{S} S 视为样本属于正类的概率。如果我们设定一个概率阈值,比如 0.5 0.5 0.5,当 S \mathbf{S} S 大于 0.5 0.5 0.5 时,我们认为样本属于正类;反之,当 S \mathbf{S} S 小于 0.5 0.5 0.5 时,我们认为样本属于负类。通过这种方式,逻辑回归模型就能够对样本进行分类。
总的来说,逻辑回归通过线性回归模型输出结果并应用 Sigmoid 函数,将连续值映射为概率,从而实现对分类问题的处理。这种方法不仅简单有效,而且在二分类问题中具有广泛的应用。
二、Sigmoid函数与损失函数
2.1 Sigmoid函数
Sigmoid 函数是一种常用于分类模型中的激活函数,其定义上一小节有写。通常,分类问题有两种结果:一种是“是”,另一种是“否”。我们可以将 0 0 0 对应于“否”, 1 1 1 对应于“是”。

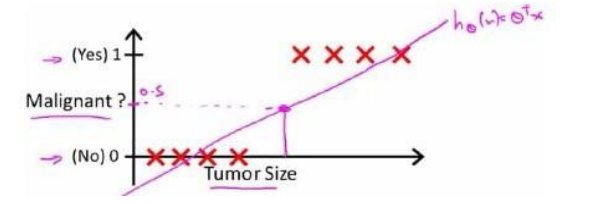
既然输出是 [ 0 , 1 ] [0, 1] [0,1] 的连续区间,为什么结果只有 0 0 0 和 1 1 1?这里我们引入一个阈值(通常设为 0.5 0.5 0.5)。当输出的概率大于 0.5 0.5 0.5 时,我们将其归为正类(即 1 1 1 类);当输出的概率小于 0.5 0.5 0.5 时,我们将其归为负类(即 0 0 0 类)。当然,这个阈值可以根据具体问题的需要自行设定。
接下来,我们将线性模型 a X + b \mathbf{aX + b} aX+b 代入 Sigmoid 函数中,就得到了逻辑回归的一般模型方程:
H ( a , b ) = 1 1 + e − ( a X + b ) \mathbf{H(a, b)} = \frac{1}{1 + e^{-(\mathbf{aX + b})}} H(a,b)=1+e−(aX+b)1
其中, H ( a , b ) \mathbf{H(a, b)} H(a,b) 表示样本属于正类的概率。当该概率大于 0.5 0.5 0.5 时,我们将其判定为正类;当该概率小于 0.5 0.5 0.5 时,我们将其判定为负类。这样,逻辑回归通过将线性回归模型的输出映射到 [ 0 , 1 ] [0, 1] [0,1] 区间,从而实现分类的目的。
2.2 损失函数
逻辑回归的损失函数称为对数损失函数(log loss),也被称为对数似然损失函数(log-likelihood loss)。其具体形式如下:
Cost ( h θ ( x ) , y ) = { − log ( h θ ( x ) ) if y = 1 − log ( 1 − h θ ( x ) ) if y = 0 \text{Cost}(\mathbf{h_{\theta}(x)}, y) = \begin{cases} -\log(\mathbf{h_{\theta}(x)}) & \text{if } y = 1 \\ -\log(1 - \mathbf{h_{\theta}(x)}) & \text{if } y = 0 \end{cases} Cost(hθ(x),y)={−log(hθ(x))−log(1−hθ(x))if y=1if y=0
在这个公式中, y = 1 y = 1 y=1 时使用第一个表达式,而 y = 0 y = 0 y=0 时使用第二个表达式。这是因为我们希望当模型预测接近真实值时,损失较小;反之,预测偏离真实值时,损失较大。
引入对数函数的原因在于其独特的性质:当真实值为 1 1 1 而模型预测概率 h \mathbf{h} h 接近 0 0 0 时, − log ( h ) -\log(\mathbf{h}) −log(h) 会趋向于无穷大,表示极大的惩罚。同样地,当真实值为 0 0 0 而模型预测概率 h \mathbf{h} h 接近 1 1 1 时, − log ( 1 − h ) -\log(1 - \mathbf{h}) −log(1−h) 也会趋向于无穷大。因此,对数函数能够有效地对错误的预测进行严厉的惩罚,而对准确的预测则几乎没有惩罚。
通过使用梯度下降等优化算法,我们可以最小化损失函数,找到使损失函数达到最小值的参数,从而训练出最佳的逻辑回归模型。
三、多分类逻辑回归与优化方法
3.1 多分类逻辑回归
逻辑回归可以通过一种称为“一对多”(one-vs-rest)的策略来处理多分类问题。具体步骤如下:
- 首先,将某个类别视为正类,而将其他所有类别视为负类,然后训练一个逻辑回归模型来计算样本属于该类别的概率 p 1 \mathbf{p1} p1。
- 接下来,将另一个类别(如 class2)视为正类,而将其他所有类别视为负类,训练另一个逻辑回归模型来计算样本属于该类别的概率 p 2 \mathbf{p2} p2。
- 重复上述过程,对每一个类别都进行类似处理,计算样本属于每个类别的概率 p i \mathbf{p_i} pi。
最终,我们将所有类别的概率进行比较,选择概率最大的那个类别作为最终预测结果。
通过这种方法,我们可以将多分类问题转化为多个二分类问题,并通过选择概率最大的类别来完成多分类任务。
3.2 优化方法
逻辑回归的优化方法包括一阶方法和二阶方法:
- 一阶方法:
- 梯度下降:通过计算损失函数的梯度,并根据梯度更新参数。梯度下降的速度较慢,但简单易用。
- 随机梯度下降(SGD):每次迭代只使用一个样本更新参数,速度更快,适用于大规模数据。
- Mini-batch随机梯度下降:对数据进行小批量处理,结合了全量梯度下降和SGD的优点,提高计算效率。
- 二阶方法:
- 牛顿法:通过二阶泰勒展开来更新参数,收敛速度较快,但计算Hessian矩阵的复杂度较高,且可能无法保证函数值稳定下降。
- 拟牛顿法:不直接计算Hessian矩阵,而是构造其近似矩阵。常用的拟牛顿法包括DFP法(逼近Hessian的逆)、BFGS法(直接逼近Hessian矩阵)、L-BFGS法(减少存储空间需求)。
四、特征离散化
在逻辑回归中,特征离散化可以带来以下好处:
- 引入非线性:将连续特征离散化后,可以捕捉到非线性特征,提高模型的表达能力。
- 计算速度快:稀疏向量的内积运算速度较快,计算结果也便于存储和扩展。
- 鲁棒性强:离散化后的特征对异常数据具有较强的鲁棒性,减少了异常值对模型的影响。
- 特征组合:离散化后可以进行特征交叉,增加模型的复杂度和表达能力。
- 模型稳定性:离散化后,模型对特征的微小变化更为稳定,避免了极端值对模型的干扰。
- 简化模型:特征离散化有助于简化模型,降低过拟合的风险。
参考:


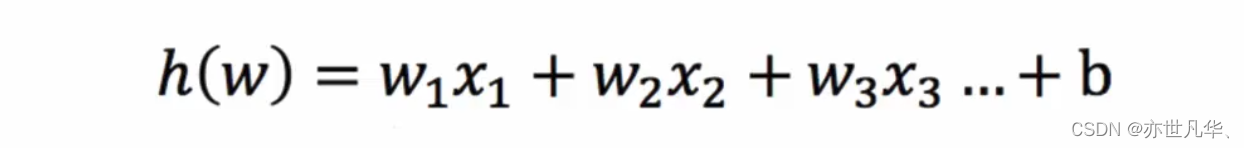
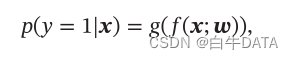
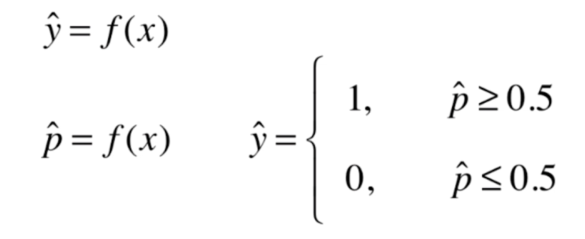

















![[Python学习篇] Python异常](https://i-blog.csdnimg.cn/direct/bf34cc637d3745468da9ba3c54d6f4dc.png)


![[web]-sql注入-白云搜索引擎](https://i-blog.csdnimg.cn/direct/b475a36efecd40278a15c64ff2e28f88.png)








