二分查找
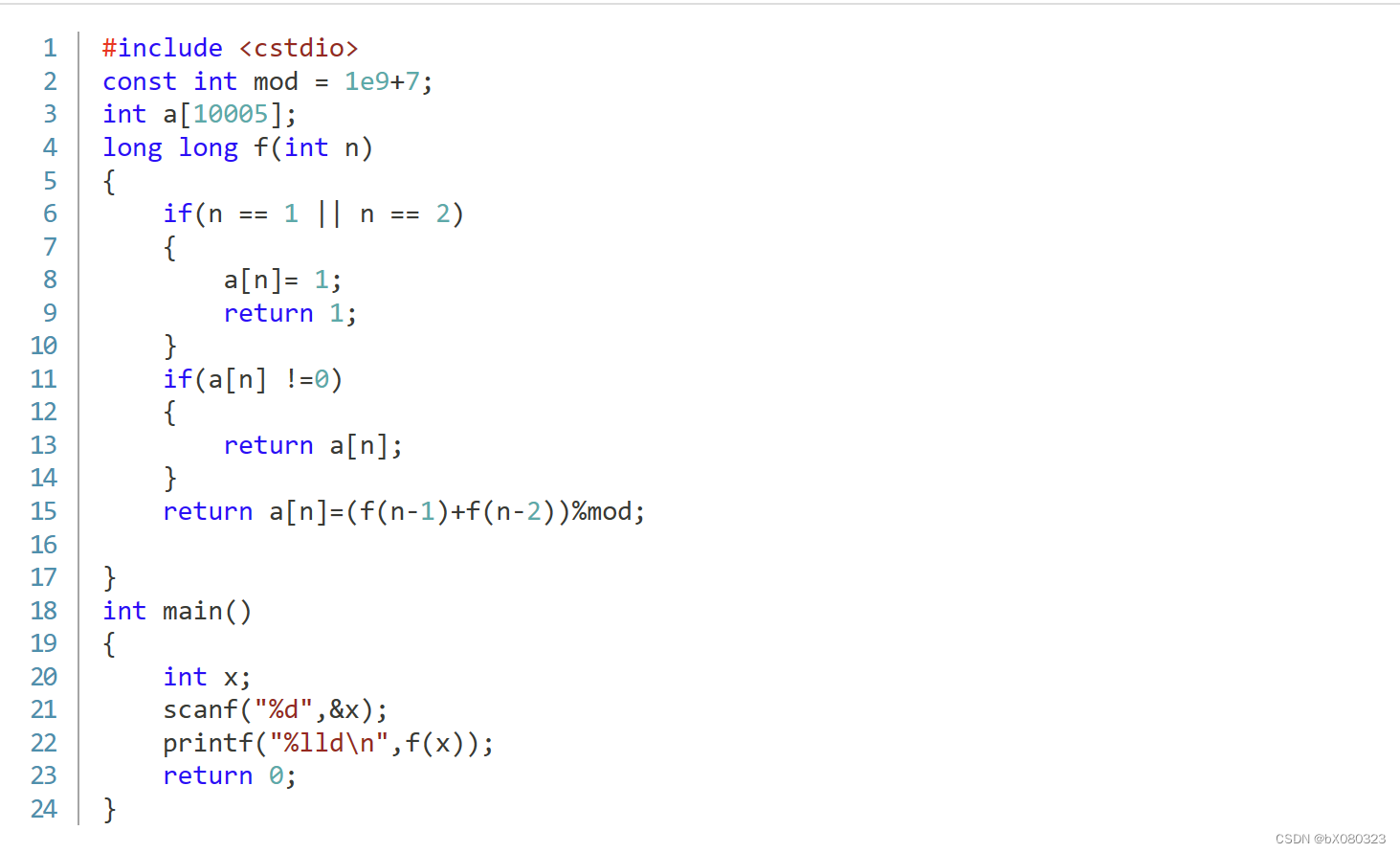
int binSearch(int* arr, int lo, int hi,int target)
{
while (lo < hi){
int mid = lo + ((hi - lo) >> 1);
if (arr[mid] > target) hi = mid;
else if (arr[mid] < target) lo = mid + 1;
else return mid;
}
return -1;
}
通过选择中点,不断迭代
斐波那契查找
与二分查找思想一致,划分点选取不一样
二分查早的话,一次迭代有三种情况,
中点值和目标值进行 > 比较后,满足则进入左半区间,
不满足,进入 < 比较,满足则进入右半区间,
不满足,则相等,返回
所以这样的话,想进入左半区间,进行一次比较,想进入右半区间,会进行两次比较,右侧比较会多
所以改进方法:调整左、右区域的宽度,适当地加长(缩短)左(右)子向量
class Fib {
private:
int fibNumber;
int Rank;
int* arr;
public:
Fib(int n)
{
this->fibNumber = n + 1;
this->arr = new int[this->fibNumber];
for (int i = 0; i < this->fibNumber; i++) {
arr[i] = fib(i);
this->Rank = i;
}
}
int fib(int n)
{
int f = 0, g = 1;
while (n-- > 0) {
g += f; f = g - f;
}
return f;
}
~Fib()
{
if (arr != NULL)
delete[] arr;
arr = NULL;
}
int get() { return this->arr[this->Rank]; }
void prev() { this->Rank--; }
};
Fib为斐波那契类,构造函数为创建一个0到n的斐波那契数列,总共n+1项
get()函数为返回当前索引的斐波那契数
prev()函数为索引向前移动一项,即前一项的斐波那契数。
int fibSearch(int* arr, int lo, int hi, int target)
{
Fib fib(hi - lo);
while (lo < hi)
{
while (hi - lo < fib.get()) fib.prev();
int mid = lo + fib.get() - 1;
if (arr[mid] > target) hi = mid;
else if (arr[mid] < target) lo = mid + 1;
else return mid;
}
return -1;
}
先实例化一个Fib类,初始化为一个hi-lo个数的斐波那契数列,
假设目标数列即要进行二分查找的数列在lo到hi索引之间有n个数(左闭右开),则初始化的斐波那契数列也是n个数
while (hi - lo < fib.get())
这个循环中的比较是为了找出fib(k-1),数列中总数为fib(k)-1

二分查找改进B
原二分法问题,左右方向不平衡
斐波那契查找改进其一,调整前、后区域的宽度,适当地加长(缩短)前(后)子向量
实际上还有另一更为直接的方法,即令以上两项的常系数同时等于
1。也就是说,无论朝哪个方向深入,都只需做1次元素的大小比较,其二,统一沿两个方向深入所需要执行的比较次数,比如都统一为一次
在每个切分点A[mi]
处,仅做一次元素比较。具体地,若目标元素小于A[mi],则深入前端子向量A[lo, mi)继续查
找;否则,深入后端子向量A[mi, hi)继续查找。
int binSearchB(int* arr, int lo, int hi, int target)
{
while (hi-lo>1) {//区间长度不是缩短为0时退出循环,而是区间长度缩短为1时退出循环
int mid = lo + ((hi - lo) >> 1);
//if (arr[mid] > target) hi = mid;//hi这面是开区间
//else lo = mid;
(arr[mid] > target) ? hi = mid : lo = mid;
}
/*if (arr[lo] == target)
return lo;
else return -1;*/
return (arr[lo] == target) ? lo : -1;
}
二分查找改进C
在有序向量中的查找,遇到重复的元素时会返回秩最大的那个,上述查找无法实现这个功能,因此加以改进
int binSearchC(int* arr, int lo, int hi, int target)
{
while (hi > lo) {//区间长度缩短为0时退出循环
int mid = lo + ((hi - lo) >> 1);
(arr[mid] > target) ? hi = mid : lo = mid + 1;
}
return --lo;
}
版本C与版本B的差异,主要有三点。
首先,只有当有效区间的宽度缩短至0(而不是1)时,查找方告终止。
另外,在每次转入后端分支时,子向量的左边界取作mi + 1而不是mi。
表面上看,后一调整存在风险,此时只能确定切分点arr[mid]>target ,“贸然”地将arr[mi]排除在进一步的查找范围之外,似乎可能因遗漏这些元素,而导致本应成功的查找以失败告终。
但其实没问题


























![[吃瓜教程]南瓜书第6章支持向量机](https://i-blog.csdnimg.cn/direct/fd9e6f80d10e42d0b3465334dd9bd5f7.png)