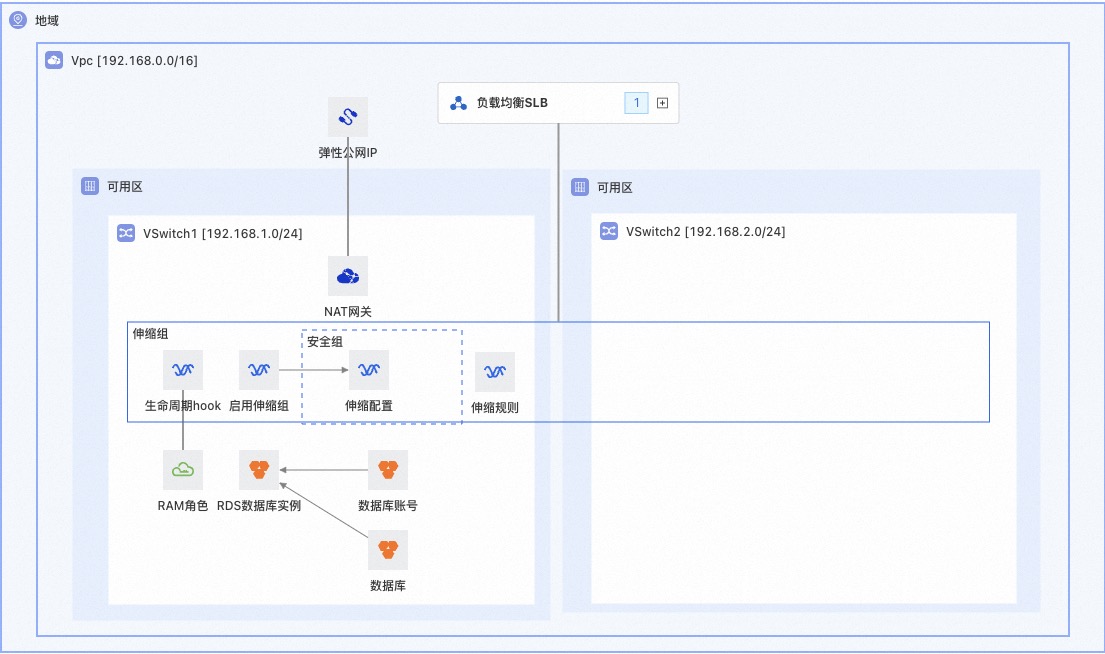
Vision Transformer (ViT) 图像分类总结
概述
使用Vision Transformer (ViT)模型进行图像分类任务。以下是主要内容和注意点:
1. 数据准备
- 数据集:使用ImageNet数据集。
- 数据处理:包括图像的读取、归一化、数据增强等步骤。
2. ViT模型介绍
- ViT模型结构:
- Patch Embedding:将输入图像切分为固定大小的patches,并通过线性变换映射到高维空间。
- Class Token:为每个输入图像添加一个特殊的分类标记。
- 位置嵌入 (Positional Embedding):加入位置信息,以保持输入图像的空间结构。
- Transformer Encoder:由多层Multi-Head Attention和Feed Forward Neural Network组成,进行特征提取和信息融合。
- 分类头 (Classification Head):通过全连接层实现最终分类。
3. 模型训练与推理
- 损失函数和优化器:设定损失函数(如交叉熵损失)和优化器(如Adam)。
- 回调函数:用于监控训练过程中的指标,如loss和accuracy。
- 训练过程:调整epoch_size,观察每个epoch的step信息,监控训练损失和时间等指标。
- 推理过程:使用训练好的模型对新图像进行预测,输出分类结果。
4. 实验结果
- 训练结果:展示训练过程中loss和accuracy的变化情况。
- 推理结果:展示推理图像的预测结果,与期望结果进行对比验证模型准确性。
5. 总结
- 关键概念:Multi-Head Attention, Transformer Encoder, Positional Embedding等。
注意点
- 数据处理:确保输入数据的格式和预处理步骤正确,以便模型能够正常训练和推理。
- 模型超参数:根据具体任务和数据集调整模型的超参数,如patch size, embed_dim, num_heads, num_layers等。
- 训练资源:ViT模型训练需要大量计算资源和时间
- 调试和监控:使用回调函数和日志记录工具监控训练过程中的各项指标,及时调整参数和模型结构。