字符串匹配算法一直是我的一大短板,刚好这段时间有需要,借此机会就好好补补。
匹配算法主要是从一段内容中匹配某一部分(pattern,这个词有时候也被翻译成模式,所以有时候也叫模式匹配),比如文本编辑器中查找某个单词、DNA 序列中查找特定序列。
结构上来说,很多字符串匹配算法都由两个部分组成:预处理和匹配。
朴素匹配算法没有预处理。
下面是《算法导论》中列出的四种匹配算法,我就先学会这四种好了。当然还有更多的算法,不过一开始容易贪多嚼不烂。
| 算法 | 预处理时间 | 匹配时间 |
|---|---|---|
| 朴素算法 | 0 0 0 | O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m) |
| Rabin-Karp | Θ ( m ) \Theta(m) Θ(m) | O ( ( n − m + 1 ) m ) O((n-m+1)m) O((n−m+1)m) |
| 有限自动机算法 | Θ ( m ∣ ∑ ∣ ) \Theta(m|\sum|) Θ(m∣∑∣) | Θ ( n ) \Theta(n) Θ(n) |
| KMP | Θ ( m ) \Theta(m) Θ(m) | Θ ( n ) \Theta(n) Θ(n) |
上面表格中的 ∑ \sum ∑是一个集合,这是因为 Rabin-Karp 算法使用了数论里的等价类:比如 1 和 3 对于 mod 2 运算来说结果一样,那么 1 和 3 是 mod 2 关系的等价类。
预处理是为了让匹配速度加快,比如 Rabin-Karp 算法虽然和朴素匹配的最坏时间一样,但是实际使用中,Rabin-Karp 通常要快得多。
注意事项
我不喜欢“模式”这个翻译,所以如果说“匹配字符串”就是指“pattern”,这里的“匹配”是形容词,而不是动词。
朴素字符串匹配算法
计算机科学术语翻译的时候,偏爱把“Naive”翻译成“朴素”,个人感觉不太喜欢这样,所以下文有些地方会将其称作“简单”。
这玩意就是一个个检查,遇到一个字符和要找的字符串的第一个字符相同,就开始比后面的,是最简单直白的算法。
C 代码如下:
#include <stdio.h>
int naiveMatch(char str[], char partern[], int lenstr, int lenpart) {
int s;
for (s=0;s<=(lenstr-lenpart);s++) {
if (str[s]==partern[0]) {
for (int i=1; i<lenpart; i++) {
if (str[s+i]!=partern[i]) {
break;
} else if (i == lenpart-1) {
printf("%d: %c, %d: %c\n", (s+i), str[s+i], i, partern[i]);
return s;
}
}
}
}
//没匹配到,返回-1
return -1;
}
int main(void) {
//这个奇奇怪怪的字符串来自于 KMP 的初始论文
char str[]="babcbabcabcaabcabcabcabcacabc";
char partern[]="abcabcacab";
//注意C字符串最后还有个终止符,所以长度要减1
int lenstr=sizeof(str)/sizeof(char)-1;
int lenpart=sizeof(partern)/sizeof(char)-1;
int s = naiveMatch(str, partern, lenstr, lenpart);
//也可以改成“从第x个开始匹配”,需要注意此时s要+1
printf("从%d开始匹配\n", s);
return 0;
}
运行结果如下:
27: b, 9: b
从18开始匹配
Rabin-Karp算法
Rabin-Karp 算法我觉得有点复杂了,如果你不感兴趣跳过也行。但是从好玩的角度来说,这个算法有点意思。
因为不光使用了数论里的等价类,以及要知道一些多项式算法;在选取关系(也就是模运算的时候)需要考虑机器长度等一系列问题,这些需要开发者有相当的数学和计算机知识储备。
当然这个算法也是有好处的:对于需要匹配到多个内容时非常不错,加上 Bloom Filter 之后效率更高。
算法逻辑
Rabin-Karp 算法的逻辑是:
- 将要匹配的部分转换成一个数(就是等价类,或者说散列值);
- 然后再将字符串的各个子字符串(与匹配部分长度相同)转换成一个个数字。
- 对比这些数字,相同的部分就有可能相同。
- 对数字相同的部分对比字符,防止出现假匹配(算法会导致一些不同的字符串算出来的结果是一样的)。
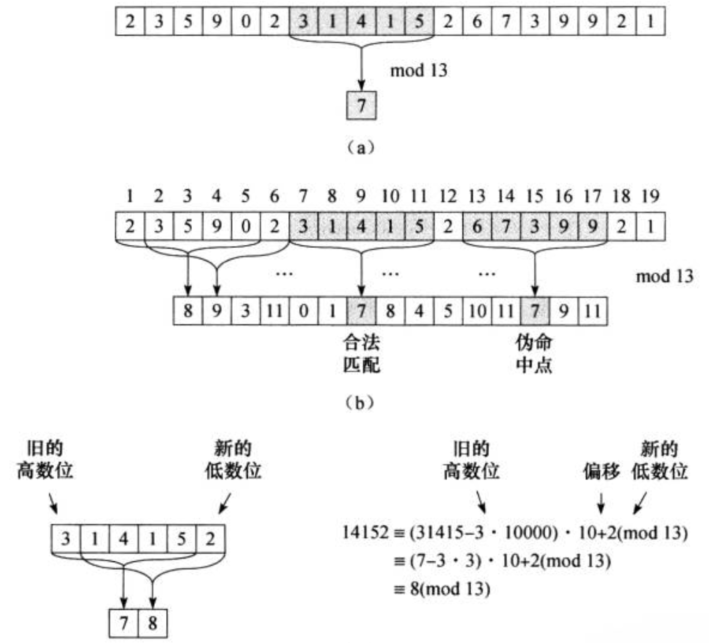
比如 1 和 3 对于
mod 2运算来说结果一样,都是 1,那么 1 和 3 是mod 2关系的等价类。
当然等价类是《算法导论》中的说法,你也可以将其理解成一种散列函数。因为这就是散列的概念,不过一些散列函数还有一些操作来处理相同的生成,这个不展开说了)。
获得等价类(散列值)
首先进行一些预处理,这里是获取等价类(散列值)。
获得等价类的方法如下:
- 利用数字来表示字符,比如可以利用 1~26 来表示 26 个英文字母,也可以使用 ASCII 码,甚至你可以使用 UTF-8、Unicode 等编码集。
- 然后利用霍纳法则来生成这段字符串的值(你也可以使用一些其他的算法,只是需要注意像简单相加这样的运算太容易重复了)。
这里我们使用 0~25 来表示 26 个英文字母来表示字符,因为我们只使用英文字母。此时 ∑ = { 0 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , . . . , 25 , 25 } \sum=\{0,2,3,4,5,6,7,8,...,25,25\} ∑={0,2,3,4,5,6,7,8,...,25,25}。
选模的时候,要选一个素数,这样可以减少产生假匹配的数量(书上给了一些相关分析,感兴趣可以看看)。不小于 26 且为素数的就是 29 了。
《算法导论》上使用的是 1~10 表示对应的数字,然后 13 作为模。
然后利用霍纳法则生成字符串的值的时候,使用以下算法(m为匹配字符串的长度):
H ( s ) = ( s [ m − 1 ] + 26 ( s [ m − 2 ] + . . . + 26 ( s [ 1 ] + 26 s [ 0 ] ) ) ) % 29 H(s)=(s[m-1]+26(s[m-2]+...+26(s[1]+26s[0]))) \% 29 H(s)=(s[m−1]+26(s[m−2]+...+26(s[1]+26s[0])))%29
也就是s[0]x26+s[1]为两个字符的值,以此累加,最后再取 29 的模的结果。
不过最后的模取不取其实都可以,只不过取了的话结果范围就小了很多。不然有时候可能会超过一条指令的长度,这样会降低运算速度。
生成算法如下:
for (int i=0; i<lenpart; i++) {
ph = 26 * ph + (partern[i]-'a');
}
ph = ph % 29;
这样字符串ccd计算出的结果为1743。
找到与匹配值相同的等价类
现在开始就到了真正的匹配阶段了。
不过这里是一个简单的查找算法,直接顺序一个个对比就行,这个没有任何技术难度。
判断是否是假匹配
这个就是前面的朴素字符串匹配算法,只不过工作量大大减少,因为只要对应下标的元素不同就可以直接判假了。
完整代码
#include <stdio.h>
int RabinKarp(char str[], char partern[], int lenstr, int lenpart, int d, int m) {
/* 预处理阶段 */
int ph=0;
int sh[lenstr - lenpart + 1];
//将sh[]每个元素设置为0,不然可能初始值不为0
for (int i=0; i<(lenstr - lenpart + 1); i++) {
sh[i]=0;
}
//生成匹配字符串的值
for (int i=0; i<lenpart; i++) {
ph = 26 * ph + (partern[i]-'a');
}
ph = ph % 29;
//生成子字符串的值
for (int i=0; i<=(lenstr-lenpart+1); i++) {
for (int j=0; j<lenpart; j++) {
sh[i] = 26 * sh[i] + (str[i+j]-'a');
}
sh[i] = sh[i] % 29;
}
/* 匹配阶段 */
//检查相同值
//(这里是返回第一个匹配到的地方,如果你要多个匹配值,那么可以使用链表或者数组存放下标,然后再进行对比)
for (int i=0; i<=(lenstr-lenpart+1); i++) {
//检查是否是假匹配
if (ph==sh[i]) {
for (int j=0; j<lenpart; j++) {
if (str[i+j]!=partern[j]) {
break;
} else if (j==lenpart-1) {
return i;
}
}
}
}
return -1;
}
int main(void) {
char str[]="babcbabcabcaabcabcabcabcacabc";
char partern[]="abcabcacab";
//注意C字符串最后还有个终止符
int lenstr=sizeof(str)/sizeof(char)-1;
int lenpart=sizeof(partern)/sizeof(char)-1;
int s = RabinKarp(str, partern, lenstr, lenpart,10 , 13);
printf("从%d开始匹配\n", s);
return 0;
}
运行结果为:
从18开始匹配
下一篇是关于有限自动机匹配字符串算法的。
希望能帮到有需要的人~























![[Spring] Spring Web MVC基础理论](https://i-blog.csdnimg.cn/direct/f0c5b1e3dbe044769fc9fc5c38accbae.jpeg#pic_center)