Lab2 Raft-Part 2C: persistence(持久化)
文章目录
Lab1:MapReduce
Lab2:Raft 实验解读
Lab2A:领导者选举 Leader Election
Lab 2B Raft-日志复制Log Replication
Lab2D:日志压缩 log compaction
代码实现(附带详细代码注释)
直达gitee链接
https://gitee.com/zhou-xiujun/xun-go/tree/master/com/xun/Mit-6.824-xun
实验2C要求
如果基于 Raft 的服务器重新启动,它应该从之前中断的地方恢复服务。这需要 Raft 保持持久状态,以便在重启后仍然存在。论文中的图 2 提到了哪些状态应该是持久的。
一个实际的实现会在每次状态改变时将 Raft 的持久状态写入磁盘,并在重启后从磁盘读取状态。你的实现不会使用磁盘;相反,它将从一个 Persister 对象(参见 persister.go)保存和恢复持久状态。调用 Raft.Make() 的函数会提供一个 Persister,该 Persister 初始保存了最近一次持久化的 Raft 状态(如果有的话)。Raft 应该从该 Persister 初始化其状态,并在每次状态变化时使用它来保存持久状态。使用 Persister 的 ReadRaftState() 和 SaveRaftState() 方法。
完成 raft.go 中的 persist() 和 readPersist() 函数,添加代码以保存和恢复持久状态。需要将状态编码(或“序列化”)为字节数组,以便传递给 Persister。使用 labgob 编码器;参见 persist() 和 readPersist() 中的注释。labgob 类似于 Go 的 gob 编码器,但如果你试图编码具有小写字段名称的结构,它会打印错误消息。在你的实现中改变持久状态的点插入对 persist() 的调用。一旦你完成了这些,并且如果你的实现的其余部分是正确的,你应该通过所有的 2C 测试。
提示
2C 测试比 2A 或 2B 更苛刻,失败可能是由你在 2A 或 2B 代码中的问题引起的。
你可能需要一种优化,将 nextIndex 一次备份多个条目。查看 Raft 论文的第 7 页底部和第 8 页顶部(以灰线标记)。论文对于细节描述得比较模糊,你需要填补这些空白,或许可以借助 6.824 课程的 Raft 讲义。
你的代码应该通过所有的 2C 测试(如下所示),以及 2A 和 2B 测试。
$ go test -run 2C
Test (2C): basic persistence ...
... Passed -- 5.0 3 86 22849 6
Test (2C): more persistence ...
... Passed -- 17.6 5 952 218854 16
Test (2C): partitioned leader and one follower crash, leader restarts ...
... Passed -- 2.0 3 34 8937 4
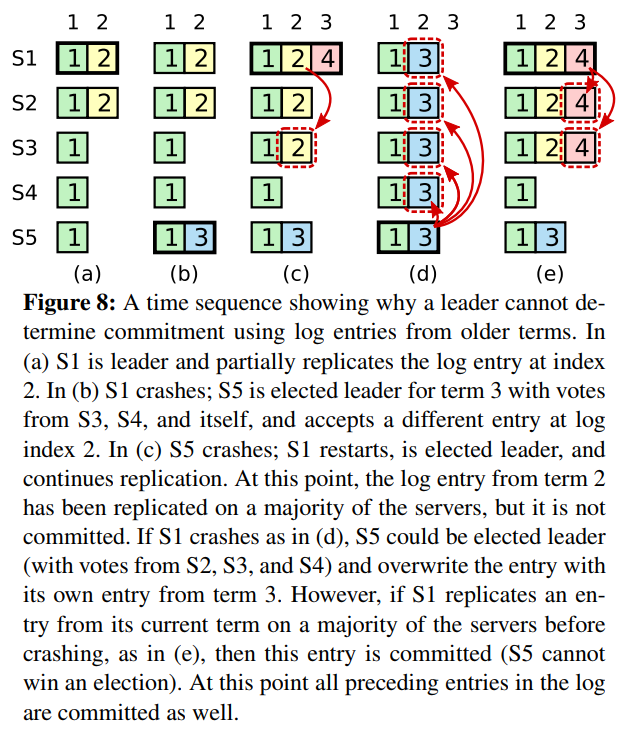
Test (2C): Figure 8 ...
... Passed -- 31.2 5 580 130675 32
Test (2C): unreliable agreement ...
... Passed -- 1.7 5 1044 366392 246
Test (2C): Figure 8 (unreliable) ...
... Passed -- 33.6 5 10700 33695245 308
Test (2C): churn ...
... Passed -- 16.1 5 8864 44771259 1544
Test (2C): unreliable churn ...
... Passed -- 16.5 5 4220 6414632 906
PASS
ok 6.824/raft 123.564s
$
在提交代码之前,可以多次运行测试并确保每次运行都打印 PASS 。这样可以确保你的代码在各种情况下都是稳定和可靠的,并且能够通过所有的测试用例。
$ for i in {0..10}; do go test; done
测试结果

实现细节
1、ConflictTerm 和 ConflictIndex 进行回退优化
// AppendEntriesReply 是附加日志条目(包括心跳)的 RPC 响应结构。回退优化
type AppendEntriesReply struct {
Term int // 当前任期,用于领导者更新自己的任期
Success bool // 如果跟随者包含了匹配的日志条目且日志条目已成功存储,则为 true
ConflictTerm int //在跟随者日志中与领导者发送的日志条目发生冲突的那条日志的任期号
ConflictIndex int //在跟随者日志中发生冲突的具体条目的索引。索引是日志条目在日志文件中的索引
}
在Raft一致性算法中,AppendEntries RPC(远程过程调用)用于领导者向跟随者复制日志条目。当跟随者收到AppendEntries请求时,它会检查请求中的日志条目是否与它自己日志中的条目冲突。如果发现冲突,跟随者会通过AppendEntriesReply结构体中的ConflictTerm和ConflictIndex字段来通知领导者,这两个字段的作用如下:
- ConflictTerm: 这个字段表示在跟随者日志中与领导者发送的日志条目发生冲突的那条日志的任期号。任期号是Raft算法中用于确定日志条目有效性的关键标识,较高的任期号意味着日志条目更“新”。通过报告冲突的任期号,领导者可以了解到跟随者日志中某个特定任期的条目与自己的不一致,这有助于领导者采取后续行动来解决冲突。
- ConflictIndex: 这个字段表示在跟随者日志中发生冲突的具体条目的索引。索引是日志条目在日志文件中的位置标识。通过报告冲突的索引,领导者可以定位到日志中的具体位置,从而知道从哪个位置开始日志条目需要被替换或删除。
当领导者收到带有非零ConflictTerm和ConflictIndex的回复时,它会根据这些信息调整其日志复制策略。例如,领导者可能需要回退到冲突索引之前的日志条目,并重新发送从那个点开始的全部日志条目,以确保日志的一致性。领导者也可能需要检查自己的日志条目,以确保它所持有的日志是最新的,并且与集群中大多数节点的日志相匹配。
ConflictTerm和ConflictIndex字段在Raft算法中用于在日志复制过程中识别和解决日志不一致的问题,确保所有节点的日志最终达到一致状态。
2、怎么进行回退
在Raft一致性算法中,当领导者接收到跟随者发送的AppendEntriesReply,其中包含ConflictTerm和ConflictIndex时,领导者需要采取适当的措施来解决日志不一致的问题。这里使用的先搜索任期(ConflictTerm)再使用冲突索引(ConflictIndex)的策略,是为了确保日志条目的正确性和一致性。以下是具体的解释:
- 搜索任期(ConflictTerm)的重要性:
- 识别日志冲突的来源:ConflictTerm指出了跟随者日志中与领导者日志发生冲突的任期号。这帮助领导者定位到具体的任期,从而了解冲突发生的背景。
- 确保日志条目的权威性:在Raft中,更高的任期号通常意味着日志条目更“新”和更权威。通过查找与ConflictTerm匹配的任期,领导者可以确保它正在处理的是最新的、有效的日志条目。
- 使用冲突索引(ConflictIndex)的时机:
- 细化冲突的位置:一旦领导者确定了冲突的任期,它需要进一步定位到日志中的具体位置。ConflictIndex提供了冲突条目的确切索引,帮助领导者了解从哪个点开始日志不一致。
- 处理日志不一致:在找到冲突任期的条目后,领导者会根据该任期条目的索引来决定如何调整nextIndex,从而决定从哪个位置开始重新发送日志条目,以解决不一致问题。
- 策略的逻辑:
- 如果领导者找到了ConflictTerm对应的任期条目,这意味着跟随者日志中的冲突条目是在领导者日志中的某条任期条目之后添加的。在这种情况下,领导者应该将nextIndex设置为该任期最后一个条目的下一个索引,这样在下次AppendEntries请求中,领导者只会发送冲突点之后的日志条目。
- 如果领导者没有找到ConflictTerm对应的任期条目,这可能意味着跟随者日志中的冲突条目是领导者日志中没有的。此时,领导者应将nextIndex设置为ConflictIndex,这意味着领导者将从ConflictIndex开始重新发送日志条目,以覆盖或修正跟随者日志中的冲突部分。
总结来说,先搜索任期再使用冲突索引的策略,是为了确保领导者能够准确地识别和处理日志不一致的问题,同时最小化日志复制的开销,提高日志复制的效率和准确性。这种策略体现了Raft算法在处理分布式系统中日志复制和一致性问题时的精巧设计。
3、持久化函数
// persist
// 将Raft的持久状态保存到稳定存储中,这使得在崩溃和重启后能够恢复这些状态。
// 参考论文图2以了解哪些状态应该被持久化。
// 函数负责将Raft的几个关键状态持久化存储,确保系统在遭遇故障重启后能够恢复到最近一次的已知安全状态。
// 持久化内容包括当前任期号(currentTerm)、已投票给的候选者(votedFor)以及日志条目(logs)。
func (rf *Raft) persist() {
// 初始化一个字节缓冲区用于序列化数据
w := new(bytes.Buffer)
// 创建一个labgob编码器,用于将Go对象编码为字节流
e := labgob.NewEncoder(w)
// 需要保存的内容,使用编码器将关键状态信息序列化到缓冲区
// 如果编码过程中出现错误,则通过log.Fatal终止程序,防止数据损坏或不完整状态的保存
if e.Encode(rf.currentTerm) != nil || e.Encode(rf.votedFor) != nil || e.Encode(rf.logs) != nil {
log.Fatal("Errors occur when encode the data!")
}
// 序列化完成后,从缓冲区获取字节切片准备存储
data := w.Bytes()
// 调用persister的SaveRaftState方法,将序列化后的数据保存到稳定的存储介质中
rf.persister.SaveRaftState(data)
}
// readPersist
// restore previously persisted state.
// 恢复先前持久化保存的状态。
// 这个函数在启动时调用,确保从稳定存储中加载之前保存的Raft状态。
func (rf *Raft) readPersist(data []byte) {
rf.mu.Lock()
defer rf.mu.Unlock()
if data == nil || len(data) < 1 { // bootstrap without any state?
// 如果没有数据或数据长度不足,可能是初次启动,无需恢复状态
return
}
// 初始化字节缓冲区以读取数据
r := bytes.NewBuffer(data)
// 创建一个labgob解码器,用于将字节流转换回Go对象
d := labgob.NewDecoder(r)
// 定义变量以接收解码后的状态信息
var currentTerm int
var votedFor int
var logs []LogEntries
// 按编码的顺序使用解码器从字节流中读取并还原状态信息
// 如果解码过程中出现错误,通过log.Fatal终止程序,防止使用损坏或不完整的状态数据
if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil || d.Decode(&logs) != nil {
log.Fatal("Errors occur when decode the data!")
} else {
// 解码成功后,将读取的状态信息赋值给Raft实例的对应字段
rf.currentTerm = currentTerm
rf.votedFor = votedFor
rf.logs = logs
}
}
4、ticker函数
// The ticker go routine starts a new election if this peer hasn't received
// heartsbeats recently.
// ticker 协程在近期没有收到心跳的情况下启动新的选举。
func (rf *Raft) ticker() {
// dead置为1后为true,则退出运行
for rf.killed() == false {
//fmt.Println(rf.me, rf.role, rf.currentTerm, rf.logs, rf.votedFor, rf.voteCount)
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// time.Sleep().
// 在这里添加代码以检查是否应该启动领导者选举
// 并使用 time.Sleep() 随机化休眠时间。
switch rf.role {
case Candidate:
select {
case <-rf.VoteMsgChan:
// 不需要continue跳过当前循环
case resp := <-rf.appendEntriesChan:
if resp.Term >= rf.currentTerm {
// 关键点:候选者收到更大任期的leader的心跳信息或者日志复制信息后,需要转为follower
rf.ConvertToFollower(resp.Term)
continue
}
case <-time.After(electionTimeout + time.Duration(rand.Int31()%300)*time.Millisecond):
// 选举超时 重置选举状态
if rf.role == Candidate {
rf.ConvertToCandidate()
// 发起投票请求
go rf.sendAllRequestVote()
}
case <-rf.LeaderMsgChan:
}
case Leader:
// Leader 定期发送心跳和同步日志
rf.SendAllAppendEntries()
// 更新commitIndex对子节点中超过半数复制的日志进行提交
go rf.checkCommitIndex()
select {
case resp := <-rf.appendEntriesChan:
// 处理跟随者的响应,如发现更高的任期则转为Follower
if resp.Term > rf.currentTerm {
rf.ConvertToFollower(resp.Term)
continue
}
case <-time.After(heartBeatInterval):
// 超时后继续发送心跳
continue
}
case Follower:
// 如果是跟随者,等待不同的事件发生
select {
case <-rf.VoteMsgChan:
// 收到投票消息,继续等待
case resp := <-rf.appendEntriesChan:
// 收到附加日志条目消息,继续等待
if resp.Term > rf.currentTerm {
rf.ConvertToFollower(resp.Term)
continue
}
case <-time.After(appendEntriesTimeout + time.Duration(rand.Int31()%300)*time.Millisecond):
// 附加日志条目超时,转换为候选人,发起选举
// 增加扰动避免多个Candidate同时进入选举
rf.ConvertToCandidate()
// 发起投票请求
go rf.sendAllRequestVote()
}
}
}
}
5、SendAppendEntries 函数发送 AppendEntries RPC 请求
// SendAppendEntries 向指定的节点发送 AppendEntries RPC 请求。
// 发送具体的 AppendEntries 请求,并处理响应
func (rf *Raft) SendAppendEntries(id int, args *AppendEntriesArgs, reply *AppendEntriesReply) {
// 调用指定节点的 AppendEntriesHandler 方法,并传递请求和响应结构
ok := rf.peers[id].Call("Raft.AppendEntriesHandler", args, reply)
// 发送失败直接返回即可。
if !ok {
return
}
rf.mu.Lock()
defer rf.mu.Unlock()
// 函数退出前,持久化状态
defer rf.persist()
// 阻止过时RPC:leader 发送的请求的任期与当前任期不同,则直接返回
if args.Term != rf.currentTerm {
return
}
// 如果响应中的任期大于当前任期,当前节点会转换为跟随者
if reply.Term > rf.currentTerm {
rf.ConvertToFollower(reply.Term)
}
// 如果当前节点不再是领导者,则直接返回
if rf.role != Leader {
return
}
// If AppendEntries fails because of log inconsistency:
// decrement nextIndex and retry (§5.3)
// 当接收到AppendEntries RPC的响应失败,意味着跟随者上的日志与领导者尝试追加的日志条目之间存在不一致。
// 为了解决这种不一致并重新尝试AppendEntries过程:
// 减小(nextIndex)指向该跟随者(id标识)的日志条目索引,
// 这是为了找到一个双方都有相同前缀的日志位置,从而恢复一致性。
// 回退优化:
// 在收到一个冲突响应后,领导者首先应该搜索其日志中任期为 conflictTerm 的条目。
// 如果领导者在其日志中找到此任期的一个条目,则应该设置 nextIndex 为其日志中此任期的最后一个条目的索引的下一个。
// 如果领导者没有找到此任期的条目,则应该设置 nextIndex = conflictIndex。
if !reply.Success {
if reply.ConflictTerm == -1 {
rf.nextIndex[id] = reply.ConflictIndex
} else {
flag := true
for j := args.PrevLogIndex; j >= 0; j-- {
// 找到冲突任期的最后一条日志(冲突任期号为跟随者日志中最后一条条目的任期号)
if rf.logs[j].Term == reply.ConflictTerm {
rf.nextIndex[id] = j + 1
flag = false
break
} else if rf.logs[j].Term < reply.ConflictTerm {
break
}
}
if flag {
// 如果没有找到冲突任期,则设置nextIndex为冲突索引
rf.nextIndex[id] = reply.ConflictIndex
}
}
} else {
// 同步成功:在分布式系统中,可能存在消息延迟、乱序或重试的情况。如果领导者在这次成功响应处理之前,已经尝试过发送更靠后的日志条目(即已经增大了nextIndex[id]),
// 直接使用args.PrevLogIndex+len(args.Entries)+1可能会导致nextIndex[id]被错误地回退到一个小于已知可安全发送的日志索引值。
// 取最大值还确保了同步的效率。如果由于某种原因(例如,领导者在等待此响应的同时又发送了一个包含更多日志条目的AppendEntries请求),直接设置nextIndex[id]为
// args.PrevLogIndex+len(args.Entries)+1可能会忽略掉领导者已经做出的更优的尝试。
rf.nextIndex[id] = max(args.PrevLogIndex+len(args.Entries)+1, rf.nextIndex[id])
// 更新(已匹配索引)matchIndex[id]为最新的已知被复制到跟随者的日志索引,
// PrevLogIndex + 新追加的日志条目数量
// 这有助于领导者跟踪每个跟随者已复制日志的最大索引。
rf.matchIndex[id] = max(args.PrevLogIndex+len(args.Entries), rf.matchIndex[id])
}
}
6、AppendEntriesHandler 函数 处理 AppendEntries 请求
// AppendEntriesHandler 由Leader向每个其余节点发送
// 处理来自领导者的 AppendEntries RPC 请求
// 处理接收到的 AppendEntries 请求,包括心跳和日志条目的复制
// 这是除Leader以外其余节点的处理逻辑
// 在Raft中,领导者通过强迫追随者的日志复制自己的日志来处理不一致。
// 这意味着跟随者日志中的冲突条目将被来自领导者日志的条目覆盖。
// 第5.4节将说明,如果加上另外一个限制,这样做是安全的。
func (rf *Raft) AppendEntriesHandler(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
// 函数退出前,持久化状态
defer rf.persist()
defer DPrintf("{Node %v}'s state is {state %v,term %v,commitIndex %v,lastApplied %v,firstLog %v,lastLog %v} before processing AppendEntriesRequest %v and reply AppendEntriesResponse %v", rf.me, rf.role, rf.currentTerm, rf.commitIndex, rf.lastApplied, rf.logs[0], rf.logs[len(rf.logs)-1], args, reply)
// 传一个带有当前任期的结构体表示接收到了Leader的请求。
// 初始化响应的任期为当前任期
reply.Term = rf.currentTerm
// 老Leader重连后Follower不接受旧信号
if rf.currentTerm > args.Term {
return
}
// 收到Leader更高的任期时,更新自己的任期,转为 leader 的追随者
// 或者如果当前节点是候选者,则更新自己的任期,转为追随者
if rf.currentTerm < args.Term || (rf.currentTerm == args.Term && rf.role == Candidate) {
rf.ConvertToFollower(args.Term)
}
// 向 appendEntriesChan 发送一个空结构体,以表示接收到了领导者的请求
//rf.appendEntriesChan <- struct {}{}
// 发送心跳重置计时器或日志条目后
rf.appendEntriesChan <- AppendEntriesReply{Term: rf.currentTerm, Success: true}
// 如果追随者的日志中没有 preLogIndex,它应该返回 conflictIndex = len(log) 和 conflictTerm = None。
if args.PrevLogIndex >= len(rf.logs) {
// 该检查是为了确保领导者请求的前一个日志条目索引没有超过跟随者当前日志的实际长度。如果args.PrevLogIndex大于跟随者日志的长度,
// 这意味着领导者认为跟随者应该有一个比实际更长的日志,这通常是因为领导者和跟随者之间的日志出现了不一致,或者跟随者落后很多且领导者的信息过时。
// 领导者收到这样的失败响应后,会根据跟随者的反馈调整其nextIndex值,然后重试发送AppendEntries请求,从一个更早的索引开始,
// 以解决日志不一致的问题。这样,通过一系列的尝试与调整,Raft算法能够最终确保集群间日志的一致性。
reply.ConflictTerm = -1
reply.ConflictIndex = len(rf.logs)
return
}
lastLog := rf.logs[args.PrevLogIndex]
// 最后的日志对不上 因此需要让Leader对该节点的nextIndex - 1
// 优化逻辑:处理日志条目任期不匹配的情况
// 当领导者尝试追加的日志条目与跟随者日志中的前一条条目任期不一致时,
// 跟随者需要向领导者反馈冲突信息,以便领导者能够正确地调整日志复制策略。
// 如果追随者的日志中有 preLogIndex,但是任期不匹配,它应该返回 conflictTerm = log[preLogIndex].Term,
// 即返回与领导者提供的前一条日志条目任期不同的任期号。
// 然后在它的日志中搜索任期等于 conflictTerm 的第一个条目索引。
if args.PrevLogTerm != lastLog.Term {
// 设置冲突任期号为跟随者日志中最后一条条目的任期号,
// 这是因为跟随者日志的最后一条条目与领导者提供的前一条条目任期不一致。
reply.ConflictTerm = lastLog.Term
// 然后在它的日志中搜索任期等于 conflictTerm 的第一个条目索引。
// 从 args.PrevLogIndex 开始向前遍历日志条目,直到找到任期不匹配的第一个条目,
// 或者遍历到日志的起始位置。
for j := args.PrevLogIndex; j >= 0; j-- {
// 当找到任期不匹配的条目时,记录其下一个条目的索引作为冲突索引,
// 这意味着从这个索引开始,日志条目需要被重新同步。
if rf.logs[j].Term != lastLog.Term {
reply.ConflictIndex = j + 1
break
}
}
// 完成冲突信息的收集后,返回处理结果,结束函数执行。
return
}
reply.Success = true
//领导者尝试让跟随者追加的日志条目范围完全落在跟随者已知的已提交日志区间内,那就不需要再复制了
if args.PrevLogIndex+len(args.Entries) <= rf.commitIndex {
return
}
// 在PrevLogIndex处开始复制一份日志
// 实现了 Raft 算法中跟随者接收到领导者发送的日志条目后,根据日志条目的任期号进行日志条目的复制或替换逻辑。
// 这里要循环判断冲突再复制 不然可能由于滞后性删除了logs
for idx := 0; idx < len(args.Entries); idx++ {
// 计算当前条目在跟随者日志中的目标索引位置
curIdx := idx + args.PrevLogIndex + 1
// 检查当前条目索引是否超出跟随者日志的长度,或者
// 日志条目的任期号与跟随者现有日志条目中的任期号是否不一致
if curIdx >= len(rf.logs) || rf.logs[curIdx].Term != args.Entries[idx].Term {
// 如果存在落后或者冲突,以当前领导者的日志为主,从当前位置开始,用领导者发送的日志条目替换或追加到跟随者日志中
// 这里使用切片操作,保留原有日志的前半部分,然后追加领导者发送的日志条目
rf.logs = append(rf.logs[:curIdx], args.Entries[idx:]...)
// 替换或追加完毕后,跳出循环
break
}
}
// 更新commitIndex
if args.LeaderCommit > rf.commitIndex {
rf.commitIndex = min(len(rf.logs)-1, args.LeaderCommit)
}
}
我的代码实现(附带详细代码注释)
直达gitee链接
https://gitee.com/zhou-xiujun/xun-go/tree/master/com/xun/Mit-6.824-xun
相关链接