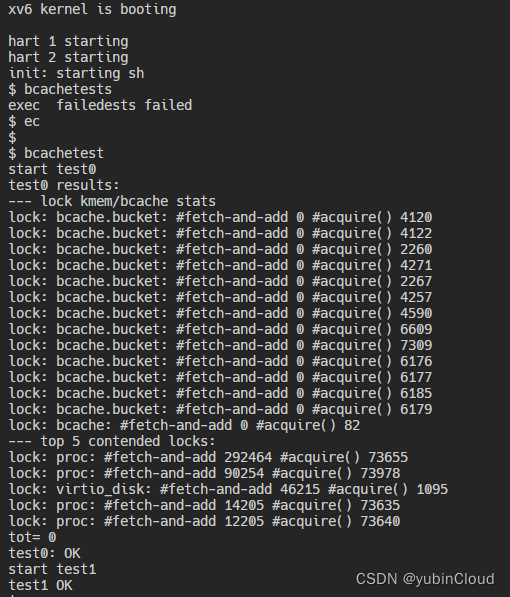
Task 1:Memory allocator (moderate)
这个任务就是练习将一把大锁拆分为多个小锁,同时可以更加深入地理解 memory allocator 运行的原理。
task 的内容是:原来的 memory allocator(kernel/kalloc.c)在分配内存和释放内存时只有一把大锁(也就是原来代码中的 kmem.lock),一把大锁带来的问题就是锁竞争的问题严重。为了减少锁的竞争,现在需要将这把大锁拆成多个小锁,每个 CPU 都有一把锁和一个 freelist,当需要分配内存时,优先从本 CPU 自己所对应的 freelist 中分配,当自己的 freelist 为空时,才会去其他 CPU 的 freelist 中寻找空闲的 page。
所以我们需要做的就是,为每个 CPU 设置一个 lock,并将原来的 freelist 拆分成多个,并分给所有 CPU 来用,从而提高并发度。
这里我采用的思路是,假如一共有 NCPU 个 CPU,那按照内存页号平分给这些 CPU。比如有 15 个内存页,那 0 ~ 4 就分给第一个 CPU 的 freelist,5 ~ 9 就分给第二个 CPU 的 freelist,10 ~ 14 就分给第三个 CPU 的 freelist。这样,根据一个物理地址,我们就知道这是应该放在哪个 freelist 中。
代码实现过程(所有修改均在 kernel/kalloc.c 中):
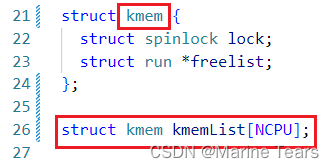
首先需要为每个 CPU 分配一个 lock 和 freelist,所以将之前的结构体 kmem 改为了一个数组:
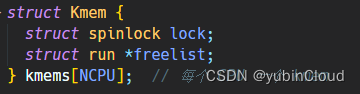
这样 i 号 CPU 就对应 kmems[i]。
然后我们在 kinit() 中初始化各个 lock:
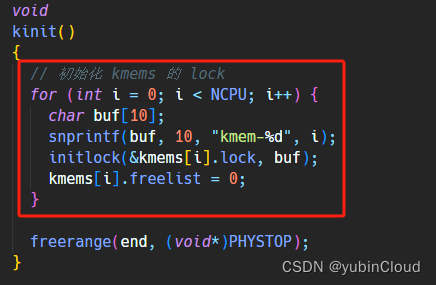
为了平分所有内存页,我们应该知道每个 CPU 能分到多少个内存页,也就是总内存页的数量除以 CPU 的数量,用一个变量 freelist_size 来表示:

然后在 freerange() 函数中遍历所有内存 page 时计算出 freelist_size:

有了 freelist_size,那我们就可以根据一个物理地址计算出这个内存属于哪个 freelist 了,这个转换的逻辑封装为函数:
// 计算物理地址 pa 应该由哪个 kmem 的 freelist 来管
int kmem_number(void* pa) {
return ( (uint64)pa - (uint64)end ) / PGSIZE / freelist_size;
}
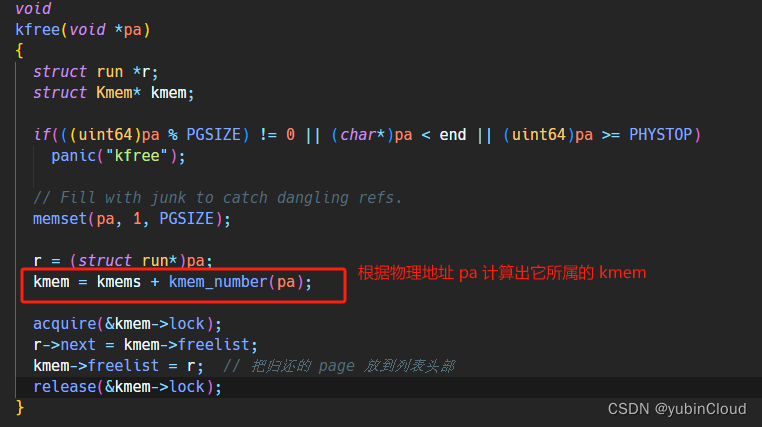
修改 kfree() 函数的实现,在归还某个内存 page 时,需要先计算出这个 page 属于哪个 freelist,然后再将其加入到那个 freelist 中:
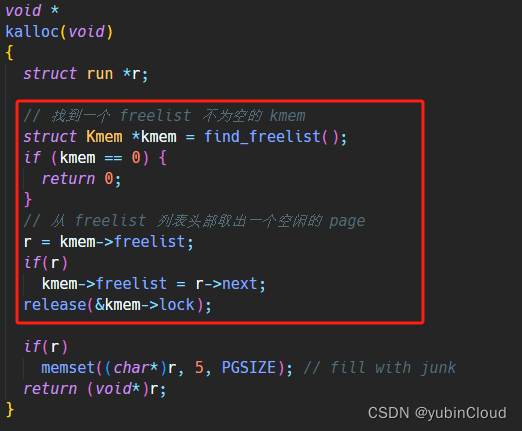
接下来修改 kalloc() 的实现,在这里我们分配时,优先从当前 CPU 自己的 freelist 中寻找一个空闲 page,当自己没有空闲 page 时,需要再从其他人手中找一个出来,我们将这个寻找存在空闲 page 的 freelist 的逻辑封装为 find_freelist() 函数,它寻找含有空闲 page 的 freelist 所在的 kmem:
struct Kmem*
find_freelist()
{
int cpu_id = cpuid();
struct Kmem* kmem = kmems + cpu_id;
// 先检查自己的 freelist 是否能够分配
acquire(&kmem->lock);
if (kmem->freelist) {
return kmem;
}
release(&kmem->lock);
// 如果自己的 freelist 空了的话,就从通过**遍历**来从其他人那里找
for (int i = 0; i < NCPU; i++) {
if (i == cpu_id) {
continue;
}
kmem = kmems + i;
acquire(&kmem->lock);
if (kmem->freelist) {
return kmem;
}
release(&kmem->lock);
}
return 0;
}
如果没找到就返回 0。
注意 find_freelist() 在实现时有个大坑!因为它在遍历各个 CPU 所对应的 freelist 时需要加锁,这种依次加锁很可能产生死锁的问题,为了规避死锁,我们应该按一定的顺序来依次加锁解锁,不可以产生交叉(比如一个进程先加了 A 再准备加 B,另一个进程有可能先加了 B 再准备加 A),在这里,我们决定在遍历时,无论自己的 cpu id 是多少,都从 0 号 kmem 开始遍历,而不是从自己的 cpu 号开始进行环形遍历。
有了这个函数,kalloc() 就好实现了:
Task 2:Buffer cache (hard)
这个题目依然也是需要将一把大锁拆分成小锁从而提高并发度的任务。
bcache 用来缓存文件系统的 block,一个 bcache 由多个 buf 组成,每个 buf 可以存放一个 block,原有实现将这些 buf 串联成一个 linked list,并利用这个 linked list 来使用 LRU 算法淘汰出无用的 buf cache。
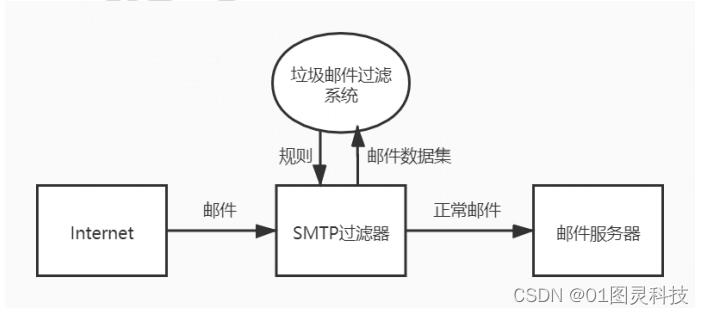
task 的内容是,原有的 bcache 在分配 block cache 时会使用一把大锁 bcache.lock,无论是寻找 cache、分配新 cache 等都是加这一把锁,从而导致 bcache 部分具有严重的锁竞争。在之前的实现中,所有的 block buf 被串联成 linked list,现在我们需要将其改成 hash table 的形式,这个 hash table 由多个 buckets 组成,每个 bucket 有一个 buf 指针的 linked list 并对应一个 lock,bucket 记录了 block 号哈希值正好映射到这个 bucket 号的所有 buf 的指针,图解如下:
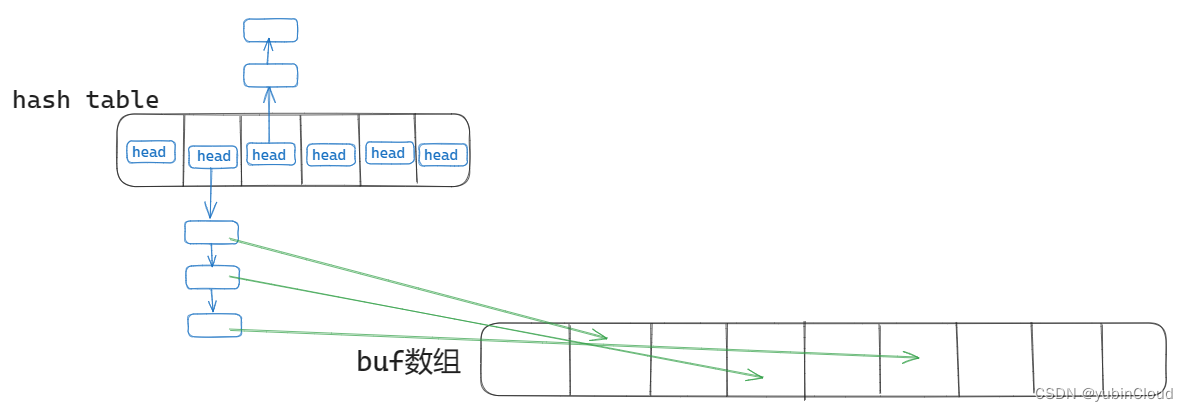
buf 数组声明在 bcache 中,同时有一个 hash table 使用拉链法来记录了 bucketno -> bufs 的映射。所以,对于一个 block,对其 block 号进行取模得到 bucket 号,再从 hash table 的这个 bucket 中存储的 linked list 寻找出一个 buf 来做 block 的缓存。
代码实现如下:
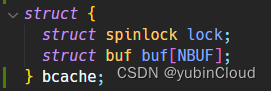
首先将 bcache 结构体中的 head 删掉,只保留 lock 和 buf 数组:
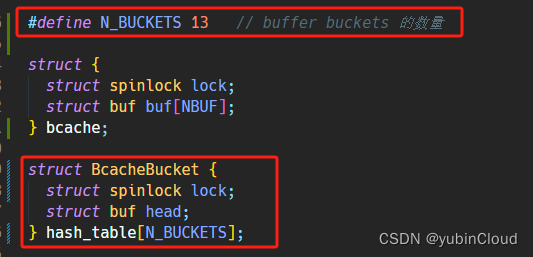
之后初始化一个 hash table,也就是 buckets 数组,bucket 数量选择质数 13:
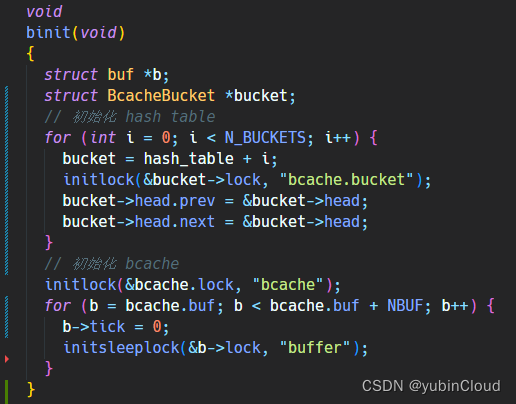
在初始化函数 binit() 中,实现对 bcache 和 hash table 中的锁和相关指针的初始化:
然后我们实现一个辅助函数 replace_buffer() 用来在 buffer 中填充我们新的 block 缓存的相关信息:

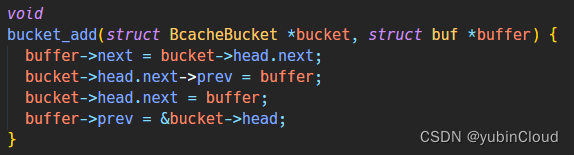
在实现一个辅助函数 bucket_add() 用来向一个 bucket 加入一个 buffer,这里的实现是将其加到链表的第一个元素上(也就是 head 的 next):
然后就是实现 bget() 函数,也就是传入一个 block 信息,让我们找到一个存放这个 block 的 buf cache,这里分两种情况:
- case 1:已经在 cache 中,所以我们需要找到 block 所在的 bucket,并从中找到存放这个 block 缓存的 buf
- case 2:cache 中没有这个 block 的缓存,需要我们从现有的 cache 中根据 LRU 策略淘汰出不用的 buf 作为新 block 的缓存
这个关键函数的代码实现如下,已经做了详细的注释:
// 在一个 buffer 中填入缓存块的信息
void
replace_buffer(struct buf* buffer, uint dev, uint blockno, uint tick) {
buffer->dev = dev;
buffer->blockno = blockno;
buffer->tick = tick;
buffer->valid = 0; // 表示数据还未写入 buffer 的 data 字段中
buffer->refcnt = 1;
}
void
bucket_add(struct BcacheBucket *bucket, struct buf *buffer) {
buffer->next = bucket->head.next;
bucket->head.next->prev = buffer;
bucket->head.next = buffer;
buffer->prev = &bucket->head;
}
// Look through buffer cache for block on device dev.
// If not found, allocate a buffer.
// In either case, return locked buffer.
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b;
int bucketNo = blockno % N_BUCKETS; // 根据 blockno 计算 hash table 的 bucket 序号
struct BcacheBucket *bucket = hash_table + bucketNo;
acquire(&bucket->lock);
// 检查这个 block 是否存在于 cache 中
for (b = bucket->head.next; b != &bucket->head; b = b->next) { // 遍历这个 bucket 的链表
// 如果没找到:
if (b->dev != dev || b->blockno != blockno) {
continue;
}
// 如果找到了:
b->tick = ticks;
b->refcnt++;
release(&bucket->lock);
acquiresleep(&b->lock);
return b;
}
// 如果 bucket 中没有找到 cache,则需要从 kcache 中找一块未使用的 buffer
acquire(&bcache.lock);
struct buf* victim = 0; // 根据 LRU 策略所决定淘汰的 buffer
for (b = bcache.buf; b < bcache.buf + NBUF; b++) { // 遍历所有 buffer,寻找一个未使用的 buffer
// 如果 buffer 不能使用:
if (b->refcnt != 0) {
continue;
}
// 如果 buffer 可以使用,则根据时间戳来决定是否将它作为 victim
else {
if (victim == 0 || victim->tick > b->tick) {
victim = b;
}
}
}
// 是否能够找到 victim?
if (victim == 0) {
panic("bget: no buffers");
}
// 将 victim 的 buffer 中填入数据,并将其移动到 bucket 中
if (victim->tick == 0) { // 如果 victim 还未加入到 hash table 中
replace_buffer(victim, dev, blockno, ticks);
bucket_add(bucket, victim);
} else if ((victim->blockno % N_BUCKETS) != bucketNo) { // 如果 victim 之前所在的 bucket 与现在需要加入的 bucket 不同的话
struct BcacheBucket *old_bucket = &hash_table[victim->blockno % N_BUCKETS];
acquire(&old_bucket->lock);
replace_buffer(victim, dev, blockno, ticks);
victim->prev->next = victim->next;
victim->next->prev = victim->prev;
release(&old_bucket->lock);
bucket_add(bucket, victim);
} else { // 如果 victim 之前就是在现在需要加入的 bucket 的话
replace_buffer(victim, dev, blockno, ticks);
}
// 释放掉相关的 lock
release(&bcache.lock);
release(&bucket->lock);
acquiresleep(&victim->lock);
return victim;
}
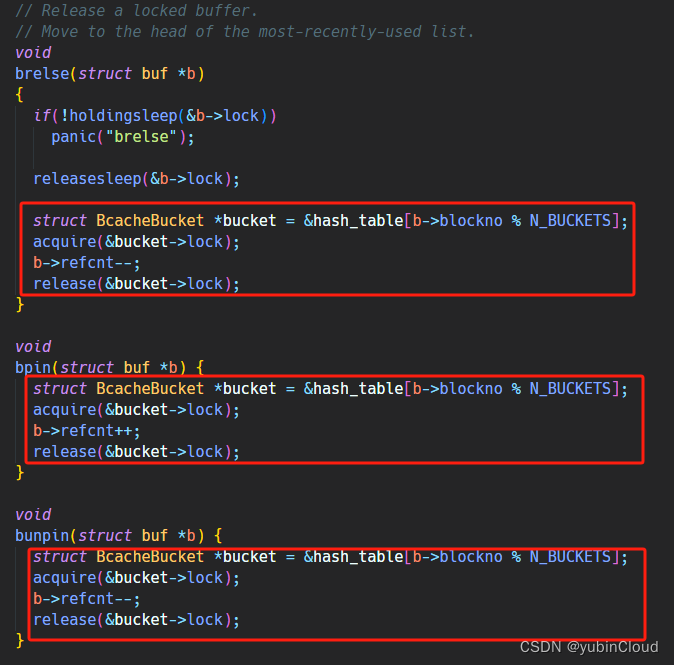
bget() 实现之后,剩下的几个函数就容易修改了,大致就是将原来对大锁的加解锁改成”寻找 buf 对应的 bucket 的小锁在加解锁“:
完成上述修改后,即可通过测试: