面向新冠肺炎的社会计算应用
1 任务目标
1.1 案例简介
新冠肺炎疫情牵动着我们每一个人的心,在这个案例中,我们将尝试用社会计算的方法对疫情相关的新闻和谣言进行分析,助力疫情信息研究。本次作业为开放性作业,我们提供了疫情期间的社交数据,鼓励同学们从新闻、谣言以及法律文书中分析社会趋势。(提示:运用课上学到的方法,如情感分析、信息抽取、阅读理解等分析数据)
1.2 数据说明
https://covid19.thunlp.org/ 提供了与新冠疫情相关的社交数据信息,分别为疫情相关谣言 CSDC-Rumor、疫情相关中文新闻 CSDC-News和疫情相关法律文书 CSDC-Legal。
疫情相关谣言 CSDC-Rumor
这一部分的数据集收集了:
(1)自 2020 年 1 月 22 日开始的微博不实信息数据,包括被认定为不实信息的微博的内容、发布者,以及举报者、审理时间、结果等信息,截至 2020 年 3 月 1 日共 324 条微博原文,31,284 条转发和 7,912 条评论,用于帮助各位研究者分析研究疫情期间的不实信息传播;
(2)自 2020 年 1 月 18 日开始的腾讯谣言验证平台以及丁香园不实信息数据,包括被认定为正确或不实信息的谣言内容、时间以及用以判断是否为谣言的依据等信息,截至 2020 年 3 月 1 日共 507 条谣言数据,其中事实性数据 124 条,数据分布为,负例:420 正例:33 不确定:54。
疫情相关中文新闻 CSDC-News
这一部分的数据集收集了自 2020 年 1 月 1 日开始的新闻数据,包含了新闻的标题、内容、关键词等信息,截至 2020 年 3 月 16 日共收集 148,960 条新闻以及 1,653,086 条对应评论,用于帮助各位研究者分析研究疫情期间的新闻数据。
疫情相关法律文书 CSDC-Legal
该数据为对从 CAIL 收集的经匿名化的法律文书数据中筛选出的历史上与疫情相关的部分,共 1203 条,每条数据包含了文书标题、案号以及文书全文,供研究者用于进行疫情期间相关法律问题的研究。
1.3 参考思路
- 谣言检测:如何准确快速地识别社交媒体上的谣言是社会计算领域中的一个重要问题,在我们提供的疫情相关谣言数据集上,同学们可以尝试不同的谣言检测方法,比如基于特征[1]、基于神经网络[2, 3]或基于传播模型的方法[4],综述[5]总结了谣言检测的相关技术。
- 新闻情感分析:参考我们的情感分析作业,可以通过关键词识别[6]等技术对疫情相关的中文新闻进行情感分析,并找出情感背后蕴含的社会学原因。
- http://weibo.com/n/%E6%B8%85%E5%8D%8E%E8%87%AA%E7%84%B6%E8%AF%AD%E8%A8%80%E5%A4%84%E7%90%86 清华自然语言处理实验室微博中给出了一些可视化例子,同学们也可以用统计学和语言学方法对文本进行分析和可视化。
1.4 评分标准
本次作业为开放性作业,我们会从
- 选题的合理性和新颖性
- 采用方法的合理性和技术含量
- 作业的完成度和工程量
- 报告和社会学分析的完整性和深入程度
等方面为作业进行评分。
1.5 参考资料
[1] Information credibility on twitter. in Proceedings of WWW, 2011.
[2] Detecting rumors from microblogs with recurrent neural networks. in Proceedings of IJCAI, 2016.
[3] A convolutional approach for misinformation identification. in Proceedings of IJCAI, 2017.
[4] The spread of true and false news online. Science, 2018.
[5] False information on web and social media: A survey. arXiv preprint, 2018.
[6] Characterization of the Affective Norms for English Words by Discrete Emotional Categories. Behavior Research Methods, 2007.
2 疫情相关谣言数据分析
本次实验提供了疫情相关谣言数据集 CSDC-Rumor,通过对数据集内容分析,选择首先对数据集进行定量统计分析,之后使用聚类实现谣言的语义分析,最后设计一个谣言检测系统。
2.1 数据处理
数据格式
本次实验提供了疫情相关谣言数据集 CSDC-Rumor,收集了微博不实信息数据,与辟谣数据。数据集包含以下内容。
rumor │ fact.json │ ├─rumor_forward_comment │ 2020-01-22_K1CaS7Qxd76ol.json │ 2020-01-23_K1CaS7Q1c768i.json ... │ 2020-03-03_K1CaS8wxh6agf.json └─rumor_weibo 2020-01-22_K1CaS7Qth660h.json 2020-01-22_K1CaS7Qxd76ol.json ... 2020-03-03_K1CaS8wxh6agf.json微博不实信息分别由
rumor_weibo和rumor_forward_comment中的两个同名json文件所描述。rumor_weibo中的json具体字段如下:rumorCode: 该条谣言的唯一编码,可以通过该编码直接访问该谣言举报页面。title: 该条谣言被举报的标题内容。informerName: 举报者微博名称。informerUrl: 举报者微博链接。rumormongerName: 发布谣言者的微博名称。rumormongerUr: 发布谣言者的微博链接。rumorText: 谣言内容。visitTimes: 该谣言被访问次数。result: 该谣言审查结果。publishTime: 该谣言被举报时间。related_url: 与该谣言相关的证据、规定等链接。
rumor_forward_comment中的json具体字段如下:uid: 发表用户 ID。text: 评论或转发附言文字。date: 发布时间。comment_or_forward: 二值,要么是comment,要么是forward,表示该条信息是评论还是转发附言。
腾讯与丁香园不实信息内容格式为:
date: 时间explain: 谣言类型tag: 谣言标签abstract: 用以验证谣言的内容rumor: 谣言
数据预处理
通过
json.load()分别提取谣言微博数据weibo_data与 谣言评论转发数据forward_comment_data,然后将其转换为 DataFrame 格式。其中二者同名的文件,微博文章与微博评论转发相对应,在处理rumor_forward_comment文件夹中的数据时,添加rumorCode以便后续匹配。# 文件路径 weibo_dir = 'data/rumor/rumor_weibo' forward_comment_dir = 'data/rumor/rumor_forward_comment' # 初始化数据列表 weibo_data = [] forward_comment_data = [] # 处理rumor_weibo文件夹中的数据 for filename in os.listdir(weibo_dir): if filename.endswith('.json'): filepath = os.path.join(weibo_dir, filename) with open(filepath, 'r', encoding='utf-8') as file: data = json.load(file) weibo_data.append(data) # 处理rumor_forward_comment文件夹中的数据 for filename in os.listdir(forward_comment_dir): if filename.endswith('.json'): filepath = os.path.join(forward_comment_dir, filename) with open(filepath, 'r', encoding='utf-8') as file: data = json.load(file) # 提取rumorCode rumor_code = filename.split('_')[1].split('.')[0] for comment in data: comment['rumorCode'] = rumor_code # 添加rumorCode以便后续匹配 forward_comment_data.append(comment) # 转换为DataFrame weibo_df = pd.DataFrame(weibo_data) forward_comment_df = pd.DataFrame(forward_comment_data)
2.2 谣言的定量统计分析
本节通过定量统计分析,使得对疫情谣言微博数据分布有具体的了解。
谣言被访问次数统计
统计
weibo_df['visitTimes']访问次数分布,并绘制对应的柱状图,结果如下。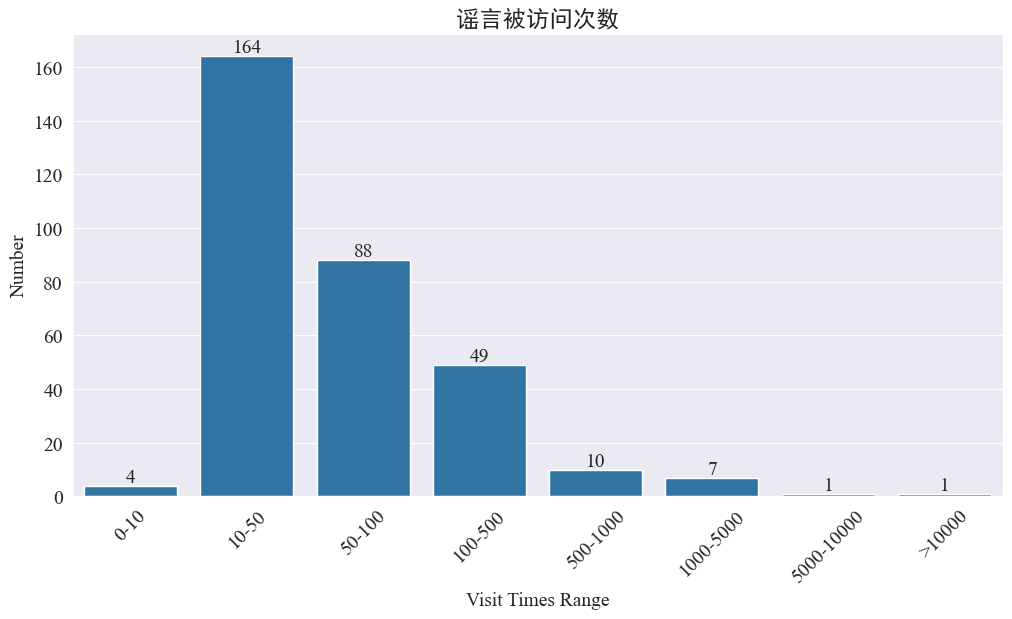
通过微博访问次数得知,大部分疫情谣言微博访问次数都在500次以内,其中10-50次的占比最多。但是也存在访问大于5000次的谣言微博,属于造成严重影响,在法律上达到 “情节严重” 的地步。
造谣者与举报者出现次数统计
通过统计
weibo_df['rumormongerName']与weibo_df['informerName']得到每个发布谣言者发布谣言的数量与每个举报者举报谣言的数量,结果如下。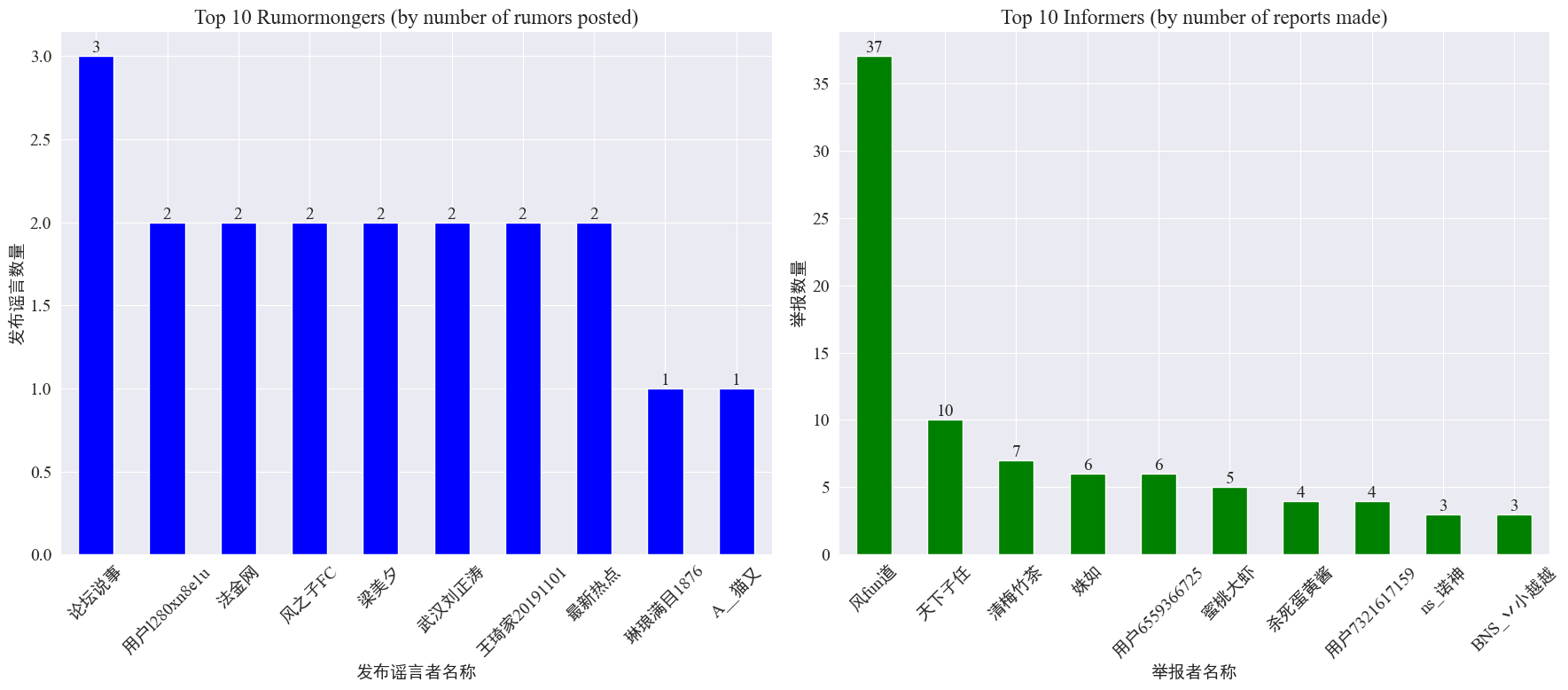
可以看到,发布造谣者发布谣言数量并不是集中在某几个人上,而是比较平均,发布谣言最多的账号发布了3篇谣言微博。而 Top10 举报者每人至少举报了而3篇谣言文章,其中举报者 风fun道 举报造谣微博数量显著高于其他用户,达到37篇。
根据以上数据,可以重点观众举报谣言数量多的账号,方便对谣言的侦测。
谣言转发评论量分布统计
通过统计谣言转发量与评论量分布,得到以下分布图像。

可以看到,大部分谣言微博的评论与转发数量都在10次以内,评论量最多不超过500个,而转发量最多达到了10000以上。根据网络管理法,谣言转发量大于500,属于 “情节严重” 情况。
2.3 谣言语义分析
谣言文本聚类分析
本部分通过对微博谣言文本进行数据预处理,分词后,进行聚类分析,看看微博谣言集中在哪些方面。
数据预处理
首先对谣言数据文本进行清洗,去除缺省值,与
<>括起来的链接内容。# 去除缺失值 weibo_df_rumorText = weibo_df.dropna(subset=['rumorText']) def clean_text(text): # 定义正则表达式模式,匹配 <> pattern = re.compile(r'<.*?>') # 使用 sub 方法删除匹配的部分 cleaned_text = re.sub(pattern, '', text) return cleaned_text weibo_df_rumorText['rumorText'] = weibo_df_rumorText['rumorText'].apply(clean_text)然后加载中文停用词,停用词采用 cn_stopwords ,利用
jieba实现对数据的分词处理,并进行文本向量化。# 加载停用词文件 with open('cn_stopwords.txt', encoding='utf-8') as f: stopwords = set(f.read().strip().split('\n')) # 分词和去停用词函数 def preprocess_text(text): words = jieba.lcut(text) words = [word for word in words if word not in stopwords and len(word) > 1] return ' '.join(words) # 应用到数据集 weibo_df_rumorText['processed_text'] = weibo_df_rumorText['rumorText'].apply(preprocess_text) # 文本向量化 vectorizer = TfidfVectorizer(max_features=10000) X_tfidf = vectorizer.fit_transform(weibo_df_rumorText['processed_text'])确定最佳聚类
通过使用肘部法,确定最佳聚类。
肘部法(Elbow Method)是一种用于确定聚类分析中最佳聚类数目的方法。它基于误差平方和(SSE,Sum of Squared Errors)与聚类数目之间的关系。SSE是聚类中所有数据点到其所属聚类中心的欧氏距离的平方和,它反映了聚类的效果:SSE越小,表示聚类效果越好。
# 使用肘部法确定最佳聚类数量 def plot_elbow_method(X): sse = [] for k in range(1, 21): kmeans = KMeans(n_clusters=k, random_state=42, n_init='auto') kmeans.fit(X) sse.append(kmeans.inertia_) plt.plot(range(1, 21), sse, marker='o') plt.xlabel('Number of clusters') plt.ylabel('SSE') plt.title('Elbow Method For Optimal k') plt.show() # 绘制肘部法图 plot_elbow_method(X_tfidf)肘部法通过寻找“肘部”来确定最佳聚类数量,即在曲线上寻找一个点,这个点之后SSE下降的速率明显减慢,这个点就像胳膊的肘部一样,因此得名“肘部法”。这个点通常被认为是最佳的聚类数目。
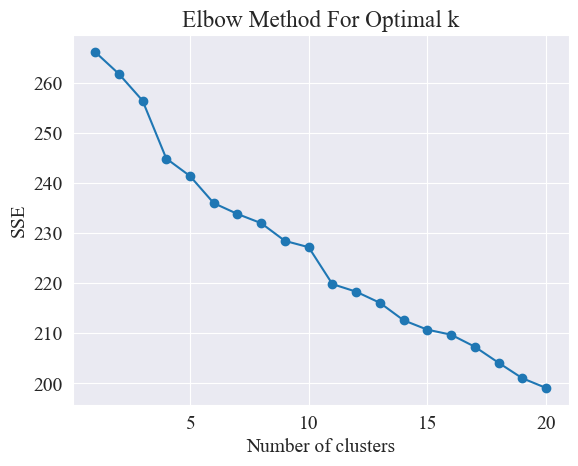
由上图,确定肘部的聚类值为 11,绘制相应散点图,结果如下。
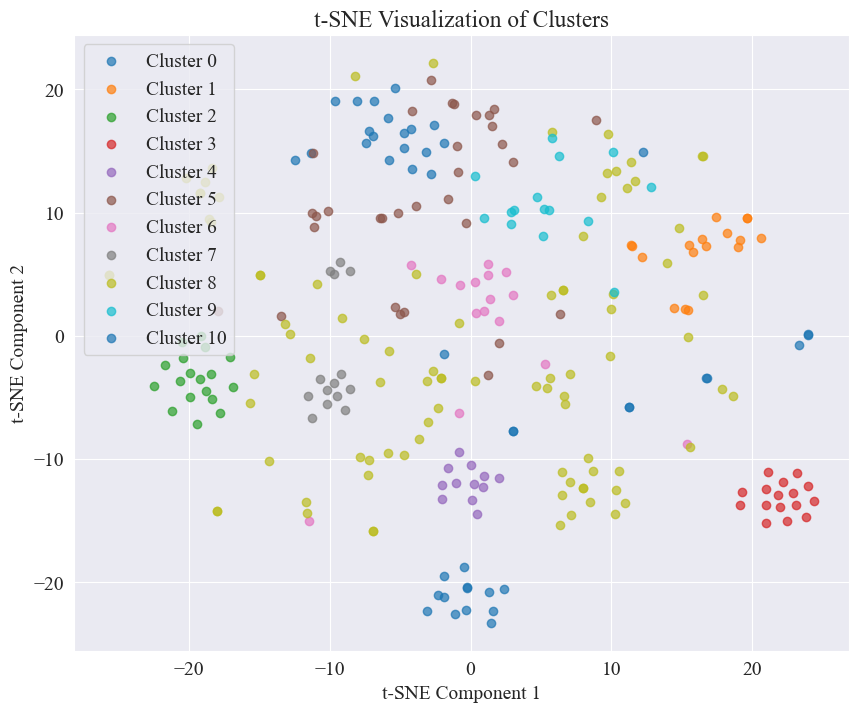
可以看出,大部分谣言微博进行了较好的聚类,3号与4号;也有的分布比较广,没有十分好的聚类,如5号,8号。
聚类结果
为了明显的表示每个类都聚类了哪些谣言,将每个类都绘制一副云图,结果如下。

打印出一些聚类较好的谣言微博内容,结果如下。
Cluster 2: 13 #封城日记#我的城市是湖北最后一个被封城的城市,金庸笔下的襄阳,郭靖黄蓉守城战死的地方。至此... 17 #襄阳封城#最后一座城被封,自此,湖北封省。在这大年三十夜。春晚正在说,为中国七十年成就喝彩... 18 #襄阳封城#过会襄阳也要封城了,到O25号0点,湖北省全省封省 ,希望襄阳的疑似患者能尽快确... 19 截止2020年1月25日00:00时❌湖北最后一个城市襄阳,整个湖北所有城市封城完毕,无公交... 21 #襄阳封城# 湖北省最后的一个城市于2020年1月25日零点零时零分正式封城至此,湖北省,封... Name: rumorText, dtype: object Cluster 3: 212 希望就在眼前…我期待着这一天早点到来。一刻都等不及了…西安学校开学时间:高三,初三,3月2日... 213 学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二,3月9日开学,小学4一6年级... 224 #长春爆料#【马上要解放了?真的假的?】长春学校开学时间:高三,初三,3月2日开学,高一,高... 225 有谁知道这是真的吗??我们这些被困湖北的外地人到底什么时候才能回家啊!(市政府会议精神,3月... 226 山东邹平市公布小道消息公布~:学校开学时间:高三,初三,3月2日开学,高一,高二,初一,初二... Name: rumorText, dtype: object
谣言审查结果聚类分析
通过谣言文本内容聚类可能对谣言内容分析表示还没那么好,于是选择对谣言审查结果聚类分析。
确定最佳聚类
使用肘部图,确定最佳聚类。
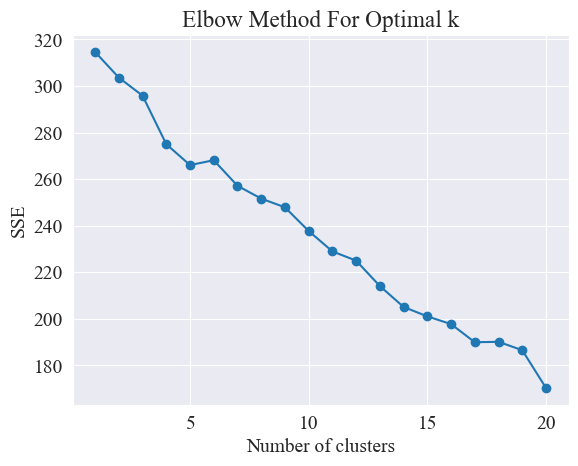
由以上肘部图,可以确定两个肘部,一个是在聚类为5时,一个是聚类位20时,我选择20进行聚类。
聚20类得到的散点图如下。
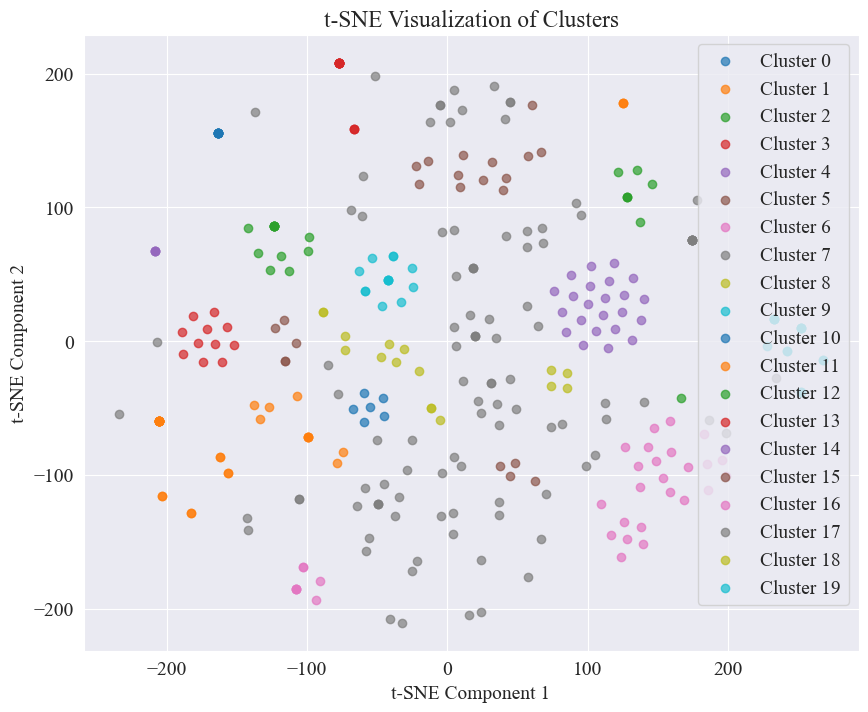
可以看到,大部分得到了很好聚类,但是第7类和17类没有很好聚类。
聚类结果
为了明显的表示每个类都聚类了哪些谣言审查结果,将每个类都绘制一副云图,结果如下。

打印出一些聚类较好的谣言审查结果内容,结果如下。
Cluster 4: 52 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车 53 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车 54 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车 55 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车 56 从武汉撤回来的日本人,迎接他们的是每个人一台救护车,206人=206台救护车 Name: result, dtype: object Cluster 10: 214 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织 215 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织 216 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织 217 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织 218 所有被啃噬、机化的肺组织都不会再恢复了,愈后会形成无任何肺功能的瘢痕组织 Name: result, dtype: object Cluster 15: 7 在福州,里面坐的是周杰伦 8 周杰伦去福州自备隔离仓 9 周杰伦去福州自备隔离仓 10 周杰伦福州演唱会,给自己整了个隔离舱 12 周杰伦福州演唱会,给自己整了个隔离舱 Name: result, dtype: object
2.4 谣言检测
本次谣言检测,选择采用已经辟谣的数据集 fact.json 中的辟谣谣言与真实谣言进行对比相似度,选择与谣言微博相似度最高的辟谣文章,作为谣言检测的依据。
加载微博谣言数据和辟谣数据集
# 定义一个空的列表来存储每个 JSON 对象 fact_data = [] # 逐行读取 JSON 文件 with open('data/rumor/fact.json', 'r', encoding='utf-8') as f: for line in f: fact_data.append(json.loads(line.strip())) # 创建辟谣数据的 DataFrame fact_df = pd.DataFrame(fact_data) fact_df = fact_df.dropna(subset=['title'])使用预训练的语言模型将微博谣言和辟谣标题编码成嵌入向量
本次实验使用
bert-base-chinese作为预训练模型,进行模型训练。并采用SimCSE模型,通过对比学习来提升句子语义的表示和相似度度量。# 加载SimCSE模型 model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2') # 加载到 GPU model.to('cuda') # 加载预训练的NER模型 ner_pipeline = pipeline('ner', model='bert-base-chinese', aggregation_strategy="simple", device=0)计算相似度
计算相似度选择采用了SimCSE模型的句子嵌入和命名实体相似度计算综合相似度。
extract_entities函数使用NER模型提取文本中的命名实体。# 提取命名实体 def extract_entities(text): entities = ner_pipeline(text) return {entity['word'] for entity in entities}entity_similarity函数计算两个文本之间的命名实体相似度。# 计算命名实体相似度 def entity_similarity(text1, text2): entities1 = extract_entities(text1) entities2 = extract_entities(text2) if not entities1 or not entities2: return 0.0 intersection = entities1.intersection(entities2) union = entities1.union(entities2) return len(intersection) / len(union)combined_similarity函数结合SimCSE模型的句子嵌入和命名实体相似度计算综合相似度。# 结合句子嵌入相似度和实体相似度 def combined_similarity(text1, text2): embed_sim = util.pytorch_cos_sim(model.encode([text1]), model.encode([text2])).item() entity_sim = entity_similarity(text1, text2) return 0.5 * embed_sim + 0.5 * entity_sim
实现谣言检测
通过对比相似度,实现谣言检测机制。
def debunk_rumor(input_rumor): # 计算输入谣言与所有辟谣标题的相似度 similarity_scores = [] for fact_text in fact_df['title']: similarity_scores.append(combined_similarity(input_rumor, fact_text)) # 找到最相似的辟谣标题 most_similar_index = np.argmax(similarity_scores) most_similar_fact = fact_df.iloc[most_similar_index] # 输出辟谣判断及依据 print("微博谣言:", input_rumor) print(f"辟谣判断:{most_similar_fact['explain']}") print(f"辟谣依据:{most_similar_fact['title']}") weibo_rumor = "据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。" debunk_rumor(weibo_rumor)输出结果如下:
微博谣言: 据最新研究发现,此次新型肺炎病毒传播途径是华南海鲜市场进口的豺——一种犬科动物携带的病毒,然后传给附近的狗,狗传狗,狗传人。狗不生病,人生病。人生病后又传给狗,循环传染。 辟谣判断:尚无定论 辟谣依据:狗能感染新型冠状病毒成功找到辟谣依据,给出辟谣判断。
3 疫情相关中文新闻数据分析
3.1 数据处理
数据格式
本次实验提供了疫情相关新闻数据集 CSDC-News,收集了2020年上半年的新闻与评论内容。数据集包含以下内容。
news │ ├─comment │ 01-01.txt │ 01-02.txt ... │ 03-08.txt └─data 01-01.txt 01-02.txt ... 08-31.txt数据文件夹中总共分为三个部分包括:
data,comment。data文件夹中包含了若干个文件,每个文件对应某个日期的数据,格式为json。这部分的内容对应新闻的正文数据(会随着日期逐步更新),其中的字段包括:time:新闻发布的时间。title:新闻的标题。url:新闻的原地址链接。meta:新闻的正文信息,其中包括以下字段:content:新闻的正文内容。description:新闻的简短描述。title:新闻的标题。keyword:新闻关键词。type:新闻的类型。
comment文件夹中包含了若干个文件,每个文件对应某个日期的数据,格式为json。这部分的内容对应新闻的评论数据(评论数据和新闻正文数据之间可能会有一周左右的延迟),其中的字段包括:time:新闻发布的时间,与data文件夹内数据相对应。title:新闻的标题,与data文件夹内数据相对应。url:新闻的原地址链接,与data文件夹内数据相对应。comment:新闻的评论信息,该字段为一个数组,数组每一个元素包含如下信息:area:评论人地区。content:评论内容。nickname:评论人昵称。reply_to:评论人回复对象,若无则代表不是回复。time:评论时间。
数据预处理
在对新闻文章数据
data数据预处理过程中,需要把meta中的内容释放出来,存储为DataFrame格式。# 加载新闻数据 def load_news_data(data_dir): news_data = [] files = sorted(os.listdir(data_dir)) for file in files: if file.endswith('.txt'): with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f: daily_news = json.load(f) for news in daily_news: news_entry = { 'time': news.get('time', 'NULL'), 'title': news.get('title', 'NULL'), 'url': news.get('url', 'NULL'), 'content': news.get('meta', {}).get('content', 'NULL'), 'description': news.get('meta', {}).get('description', 'NULL'), 'keyword': news.get('meta', {}).get('keyword', 'NULL'), 'meta_title': news.get('meta', {}).get('title', 'NULL'), 'type': news.get('meta', {}).get('type', 'NULL') } news_data.append(news_entry) return pd.DataFrame(news_data)在对评论数据
comment数据预处理过程中,需要把comment中的内容释放出来,存储为DataFrame格式。# 加载评论数据 def load_comment_data(data_dir): comment_data = [] files = sorted(os.listdir(data_dir)) for file in files: if file.endswith('.txt'): with open(os.path.join(data_dir, file), 'r', encoding='utf-8') as f: daily_comments = json.load(f) for comment in daily_comments: for com in comment.get('comment', []): comment_entry = { 'news_time': comment.get('time', 'NULL'), 'news_title': comment.get('title', 'NULL'), 'news_url': comment.get('url', 'NULL'), 'comment_area': com.get('area', 'NULL'), 'comment_content': com.get('content', 'NULL'), 'comment_nickname': com.get('nickname', 'NULL'), 'comment_reply_to': com.get('reply_to', 'NULL'), 'comment_time': com.get('time', 'NULL') } comment_data.append(comment_entry) return pd.DataFrame(comment_data)加载数据集
根据以上数据预处理函数,加载数据集。
# 数据文件夹路径 news_data_dir = 'data/news/data/' comment_data_dir = 'data/news/comment/' # 加载数据 news_df = load_news_data(news_data_dir) comment_df = load_comment_data(comment_data_dir) # 展示加载的数据 print(f"新闻数据长度:{len(news_df)},评论数据:{len(comment_df)}")打印结果显示,新闻数据长度:502550,评论数据:1534616。
3.2 新闻内容数据分析
新闻时间分布统计
分别统计
news_df的每月新闻文章数量与每时新闻文章数量,用柱状图与折线图表示,结果如下。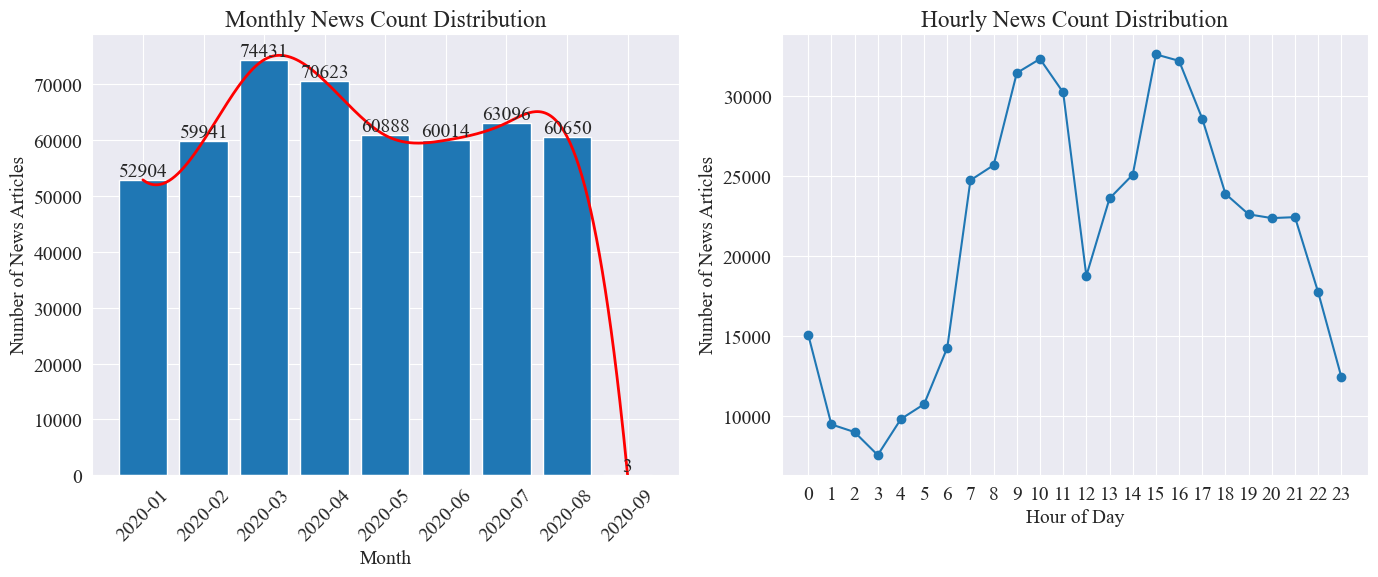
由上图可知,随着疫情的爆发,新闻数量逐月增加,在3月份达到顶峰,有7.4万篇新闻,之后逐渐下降平稳到6万篇每月,其中9月份数据为0点时的3篇,可不计入统计。
根据每小时新闻数量分布可知,每日的10点与15点是新闻发布的峰值,各发布了3万篇以上。而12点为午休时间,新闻发布数呈现峰谷。每日0点到5点新闻发布数量最少,其中3点为最小点。
新闻热点追踪
本实验打算采取提取新闻关键词的方式,来对这8个月的新闻热点进行追踪。通过统计现有的关键词分布,并绘制柱状图,结果如下。
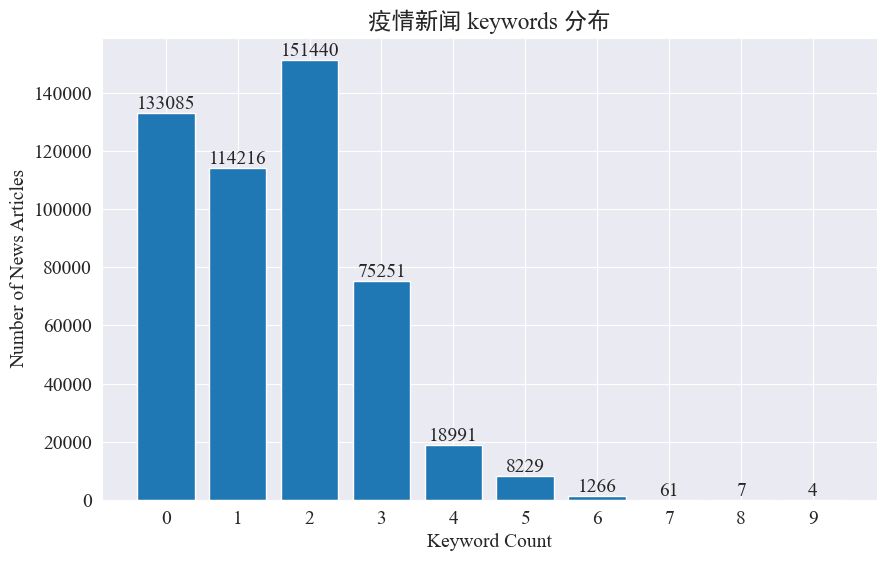
可以看出,大部分新闻文章的关键词都在3个以内,甚至有大比例的文章没有关键词。因此,需要自己统计总结关键词,用于进行热点追踪。本次使用
jieba.analyse.textrank()来统计关键词。import jieba import jieba.analyse def extract_keywords(text): # 基于jieba的textrank算法实现 keywords = jieba.analyse.textrank(text,topK=5,withWeight=True) return ' '.join([keyword[0] for keyword in keywords]) news_df['keyword_new'] =news_df['content'].map(lambda x: extract_keywords(x)) keyword_data = news_df[['time','keyword','keyword_new']] keyword_data统计出5个新的关键词,存到 keyword_new 中,然后将 keyword 与其合并,并去除重复的词。
# 合并并去除重复的词 def merge_keywords(row): # 将keyword列和keyword_new列合并 keywords = set(row['keyword']) | set(row['keyword_new'].split()) return ' '.join(keywords) keyword_data['merged_keywords'] = keyword_data.apply(merge_keywords, axis=1) keyword_data合并后打印
keyword_data,打印出的结果如下。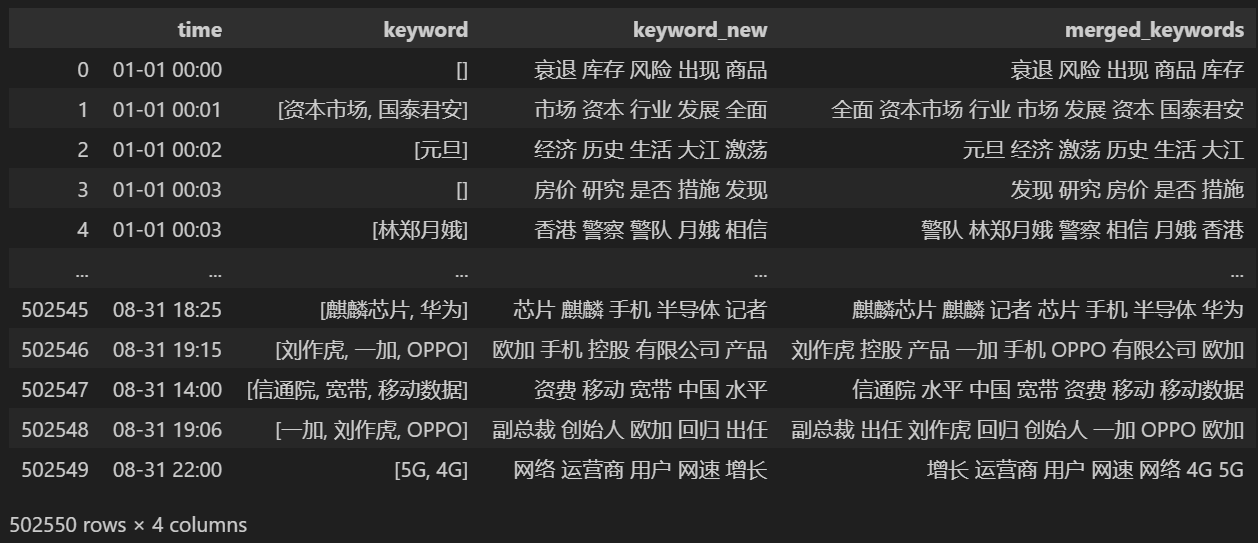
为了追踪热点,统计所有出现词汇的词频,并统计到
keyword_data['rolling_keyword_freq']。# 按时间排序 keyword_data = keyword_data.sort_values(by='time') # 计算滚动频率 def get_rolling_keyword_freq(df, window=7): rolling_keyword_freq = [] for i in range(len(df)): start_time = df.iloc[i]['time'] - timedelta(days=window) end_time = df.iloc[i]['time'] mask = (df['time'] > start_time) & (df['time'] <= end_time) recent_data = df.loc[mask] keywords = ' '.join(recent_data['merged_keywords']).split() keyword_counter = Counter(keywords) top_keywords = keyword_counter.most_common(20) rolling_keyword_freq.append(dict(top_keywords)) return rolling_keyword_freq keyword_data['rolling_keyword_freq'] = get_rolling_keyword_freq(keyword_data) keyword_df = pd.DataFrame(keyword_data['rolling_keyword_freq'].tolist()).fillna(0) keyword_df = keyword_df.astype(int) # 将原始的时间列合并到新的DataFrame中 result_df = pd.concat([keyword_data['time'], keyword_df], axis=1) # 保存为CSV文件 result_df.to_csv('./data/news/output/keyword_frequency.csv', index=False)然后根据以上统计数据,绘制每天的热点词汇变化图。
# 读取数据 file_path = './data/news/output/keyword_frequency.csv' data = pd.read_csv(file_path, parse_dates=['time']) # 聚合数据,按日期合并统计 data['date'] = data['time'].dt.date daily_data = data.groupby('date').sum().reset_index() # 准备颜色列表,确保每个关键词都有不同的颜色 colors = plt.cm.get_cmap('tab20', len(daily_data.columns[1:])).colors color_dict = {keyword: colors[i] for i, keyword in enumerate(daily_data.columns[1:])} def update(frame): plt.clf() date = daily_data['date'].iloc[frame] day_data = daily_data[daily_data['date'] == date].drop('date', axis=1).T day_data.columns = ['count'] day_data = day_data.sort_values(by='count', ascending=False).head(10) bars = plt.barh(day_data.index, day_data['count'], color=[color_dict[keyword] for keyword in day_data.index]) plt.xlabel('Count') plt.title(f'Keyword Frequency on {date}') for bar in bars: plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'{bar.get_width()}', va='center') plt.gca().invert_yaxis() # 创建动画 fig = plt.figure(figsize=(10, 6)) anim = FuncAnimation(fig, update, frames=len(daily_data), repeat=False) # 保存动画 anim.save('keyword_trend.gif', writer='imagemagick')最终得到疫情新闻关键词变化gif图,结果如下。
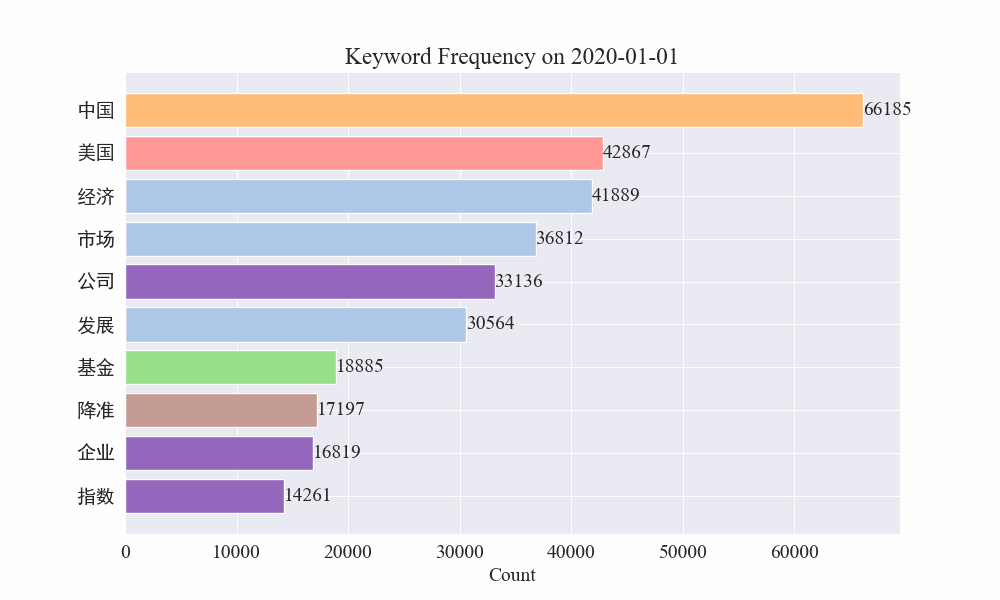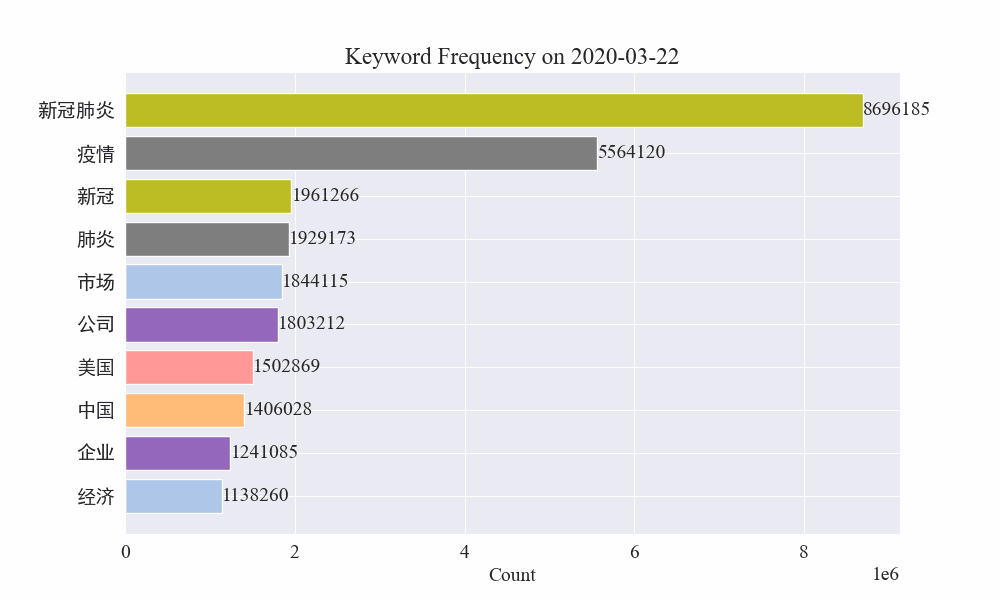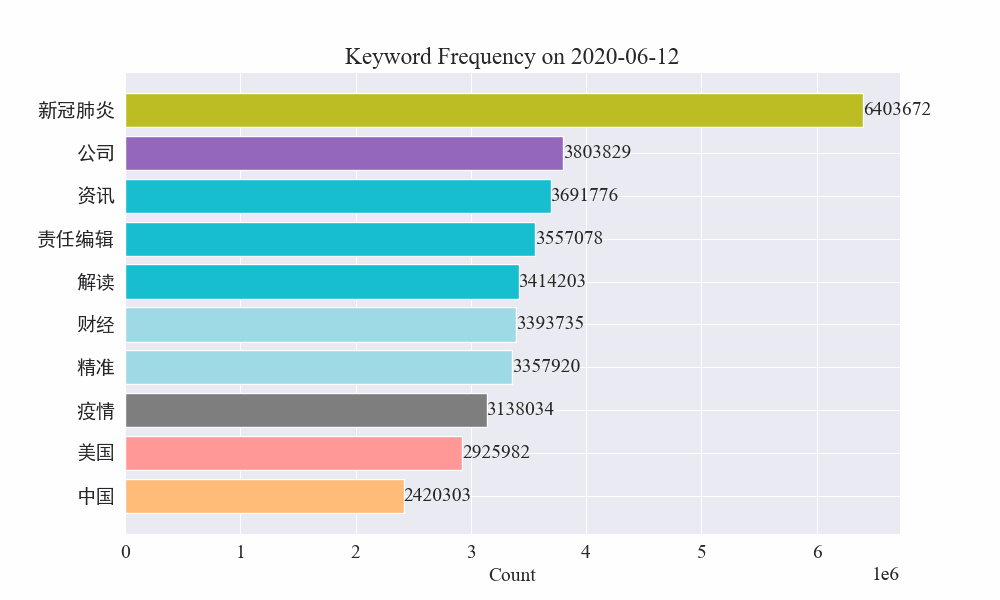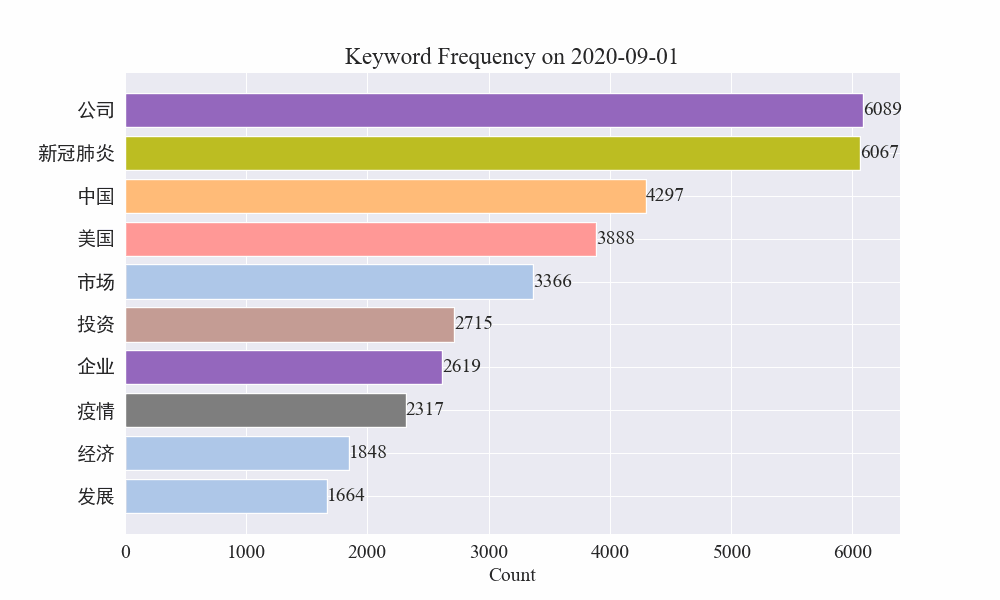
在疫情爆发之前,“公司”与“伊朗”词条保持在高位。可以看到从疫情爆发之后,2月份开始疫情相关新闻数量飙升,之后"新冠肺炎"词条飙升,持续保持在第一,直到8月底,第一波疫情放缓,变为第二。
3.3 新闻评论数据分析
本节对新闻评论先是进行定量统计分析,然后对不同评论进行情感分析。
每日新闻评论数量统计
统计新闻评论数量的走势,用柱状图表示,并绘制近似曲线,代码如下。
# 提取日期和小时信息 dates = [] hours = [] for time_str in comment_df['news_time']: try: time_obj = datetime.strptime('2020-' + time_str, '%Y-%m-%d %H:%M') dates.append(time_obj.strftime('%Y-%m-%d')) hours.append(time_obj.hour) except ValueError: pass # 统计每日新闻数量 daily_comment_counts = Counter(dates) daily_comment_counts = dict(sorted(daily_comment_counts.items())) # 统计每小时新闻数量 hourly_news_count = Counter(hours) hourly_news_count = dict(sorted(hourly_news_count.items())) # 绘制每月新闻数量分布柱状图 plt.figure(figsize=(14, 6)) days = list(daily_comment_counts.keys()) comment_counts = list(daily_comment_counts.values()) bars = plt.bar(days, comment_counts, label='Daily Comment Count') plt.xlabel('Date') plt.ylabel('Comment Count') plt.title('Daily Comment Counts on News') plt.xticks(rotation=80, fontsize=10) # 绘制近似曲线 x = np.arange(len(days)) y = comment_counts spl = UnivariateSpline(x, y, s=100) xs = np.linspace(0, len(days) - 1, 500) ys = spl(xs) plt.plot(xs, ys, 'r', lw=2, label='Smoothed Curve') plt.show()绘制得到每日新闻评论数量统计图如下。
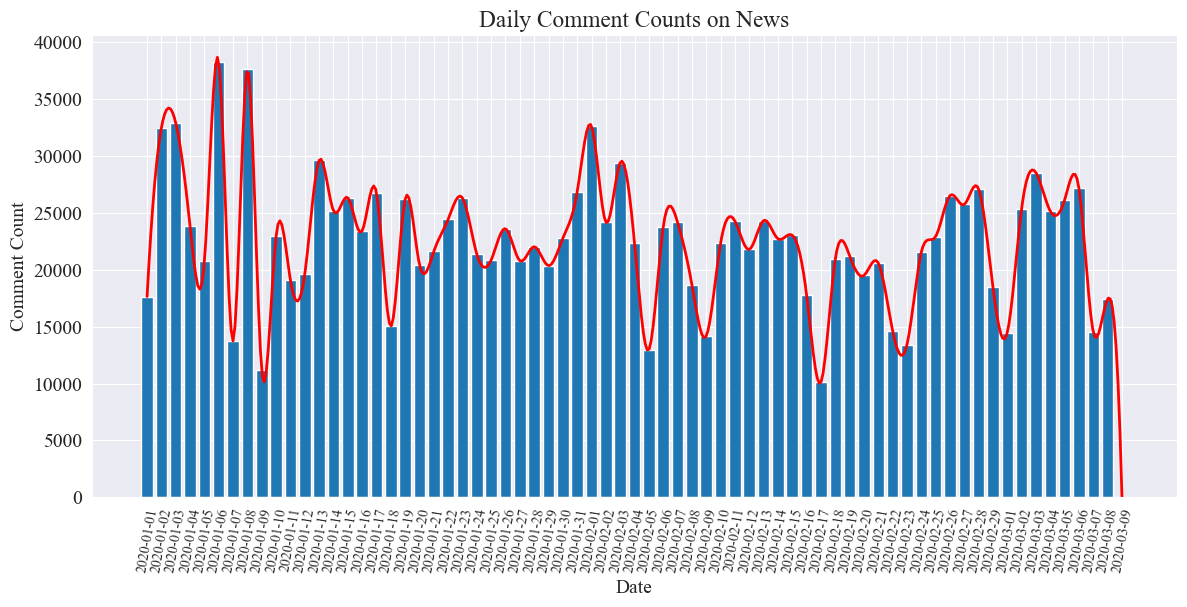
可以看到,疫情期间新闻评论数量在1万到4万之间波动,平均每日约为2万条评论。
疫情新闻按地区统计
通过按照省份
comment_df['province']统计每省的新闻数量,统计各省疫情新闻评论数量。首先需要通过对
comment_df['province']提取省份信息。# 统计包含全国34个省、直辖市、自治区名称的地域数据 province_name = ['北京', '天津', '上海', '重庆', '河北', '河南', '云南', '辽宁', '黑龙江', '湖南', '安徽', '山东', '新疆', '江苏', '浙江', '江西', '湖北', '广西', '甘肃', '山西', '内蒙古', '陕西', '吉林', '福建', '贵州', '广东', '青海', '西藏', '四川', '宁夏', '海南', '台湾', '香港', '澳门'] # 提取省份信息 def extract_province(comment_area): for province in province_name: if province in comment_area: return province return None comment_df['province'] = comment_df['comment_area'].apply(extract_province) # 过滤出省份不为空的行 comment_df_filtered = comment_df[comment_df['province'].notnull()] # 统计每个省份的评论数量 province_counts = comment_df_filtered['province'].value_counts().to_dict()然后根据统计数据,绘制各省份新闻评论数量占比的饼状图。
# 计算总评论数量 total_comments = sum(province_counts.values()) # 计算各省份评论数量占比 provinces = [] comments = [] labels = [] for province, count in province_counts.items(): if count / total_comments >= 0.02: provinces.append(province) comments.append(count) labels.append(province + f" ({count})") # 绘制饼图 plt.figure(figsize=(10, 8)) plt.pie(comments, labels=labels, autopct='%1.1f%%', startangle=140) plt.title('各省疫情新闻评论数量占比') plt.axis('equal') # 保证饼图是圆形 plt.show()
本次实验,还采用
pyecharts.charts的Map组件,绘制了中国地图按省份的评论数量分布图。from pyecharts.charts import Map from pyecharts import options as opts # 省份简称到全称的映射字典 province_full_name = { '北京': '北京市', '天津': '天津市', '上海': '上海市', '重庆': '重庆市', '河北': '河北省', '河南': '河南省', '云南': '云南省', '辽宁': '辽宁省', '黑龙江': '黑龙江省', '湖南': '湖南省', '安徽': '安徽省', '山东': '山东省', '新疆': '新疆维吾尔自治区', '江苏': '江苏省', '浙江': '浙江省', '江西': '江西省', '湖北': '湖北省', '广西': '广西壮族自治区', '甘肃': '甘肃省', '山西': '山西省', '内蒙古': '内蒙古自治区', '陕西': '陕西省', '吉林': '吉林省', '福建': '福建省', '贵州': '贵州省', '广东': '广东省', '青海': '青海省', '西藏': '西藏自治区', '四川': '四川省', '宁夏': '宁夏回族自治区', '海南': '海南省', '台湾': '台湾省', '香港': '香港特别行政区', '澳门': '澳门特别行政区' } # 将省份名称替换为全称 full_province_counts = {province_full_name[key]: value for key, value in province_counts.items()} # 创建中国地图 map_chart = ( Map(init_opts=opts.InitOpts(width="1200px", height="800px")) .add("评论数量", [list(z) for z in zip(full_province_counts.keys(), full_province_counts.values())], "china") .set_global_opts( title_opts=opts.TitleOpts(title="中国各省疫情新闻评论数量分布"), visualmap_opts=opts.VisualMapOpts(max_=max(full_province_counts.values())) ) ) # 渲染图表为 HTML 文件 map_chart.render("comment_area_distribution.html")得到的HTML中,中国各省疫情新闻评论数量分布图如下。
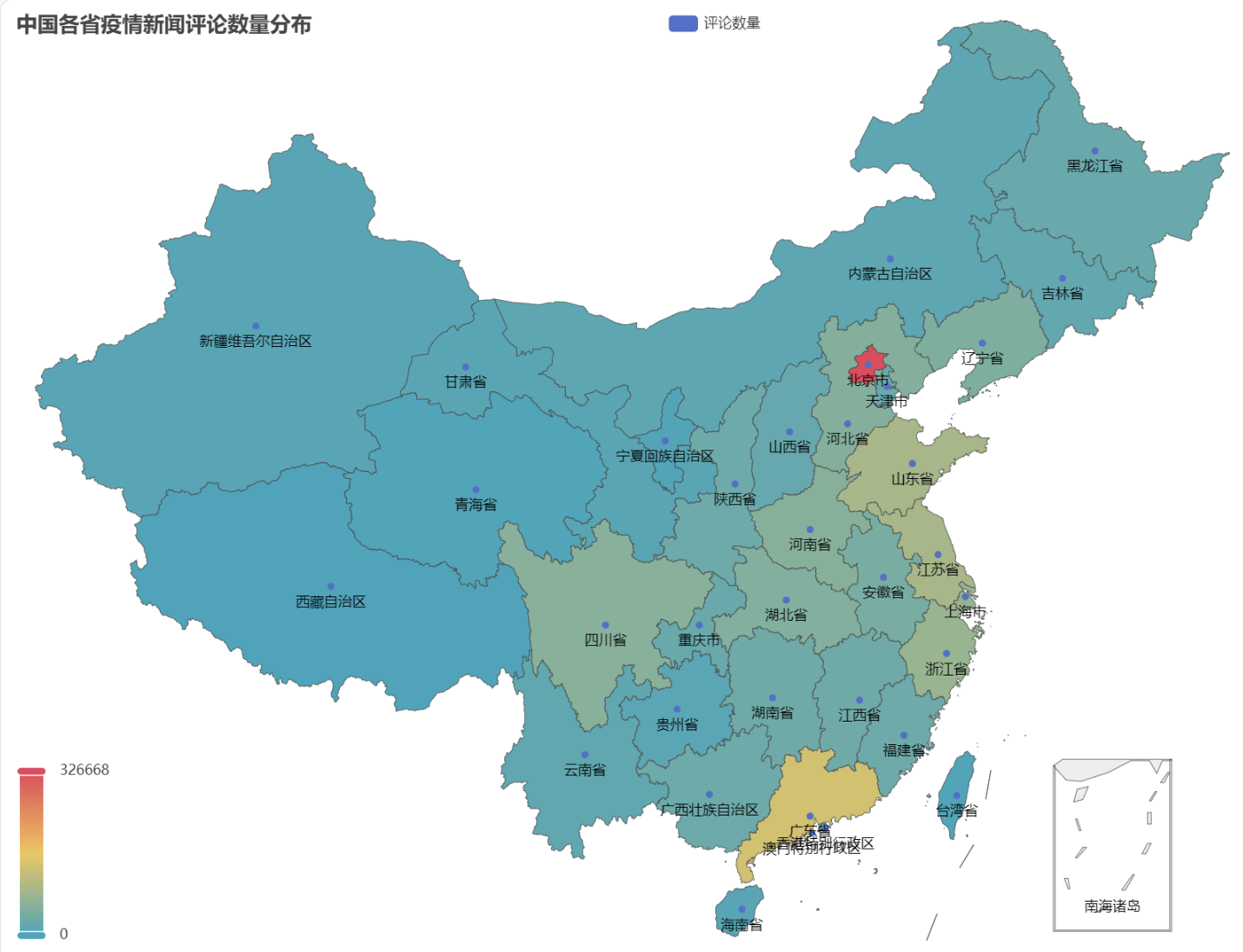
可以看到,疫情期间北京地区的评论数量占比最高,其次为广东省,其他省份评论数量较为平均。
疫情评论情感分析
本次实验通过使用用于处理中文文本的NLP库
SnowNLP,实现中文情感分析,通过分析每一条评论,给出相应的sentiment值,该值在0到1之间,越接近1越积极,越接近0越消极。from snownlp import SnowNLP # 定义一个函数来计算情感得分,并处理可能的错误 def sentiment_analysis(text): try: s = SnowNLP(text) return s.sentiments except ZeroDivisionError: return None # 对每条评论内容进行情感分析 comment_df['sentiment'] = comment_df['comment_content'].apply(sentiment_analysis) # 删除情感得分为 None 的评论 comment_df = comment_df[comment_df['sentiment'].notna()] # 将评论按正向(sentiment > 0.5)和负向(sentiment < 0.5)分类 comment_df['sentiment_label'] = comment_df['sentiment'].apply(lambda x: 'positive' if x > 0.5 else 'negative')本次实验将0.5作为阈值,大于该值的为积极评论,小于该值的为消极评论。通过编写代码,绘制每日新闻评论情感分析图,统计每日新闻的积极评论数与消极评论数,积极数量为正值,消极为负值。
# 提取新闻日期 comment_df['news_date'] = pd.to_datetime('2020-' + comment_df['news_time'].str[:5]).dt.date # 统计每一天的正向和负向评论数量 daily_sentiment_counts = comment_df.groupby(['news_date', 'sentiment_label']).size().unstack(fill_value=0) # 绘制柱状图 plt.figure(figsize=(14, 8)) # 绘制正向评论数量的柱状图 plt.bar(daily_sentiment_counts.index, daily_sentiment_counts['positive'], label='Positive', color='green') # 绘制负向评论数量的柱状图(负数,以使其在 x 轴下方显示) plt.bar(daily_sentiment_counts.index, -daily_sentiment_counts['negative'], label='Negative', color='red') # 添加标签和标题 plt.xlabel('Date') plt.ylabel('Number of Comments') plt.title('Daily Sentiment Analysis of Comments') plt.legend() # 设置x轴刻度旋转 plt.xticks(rotation=45) # 显示图表 plt.tight_layout() plt.show()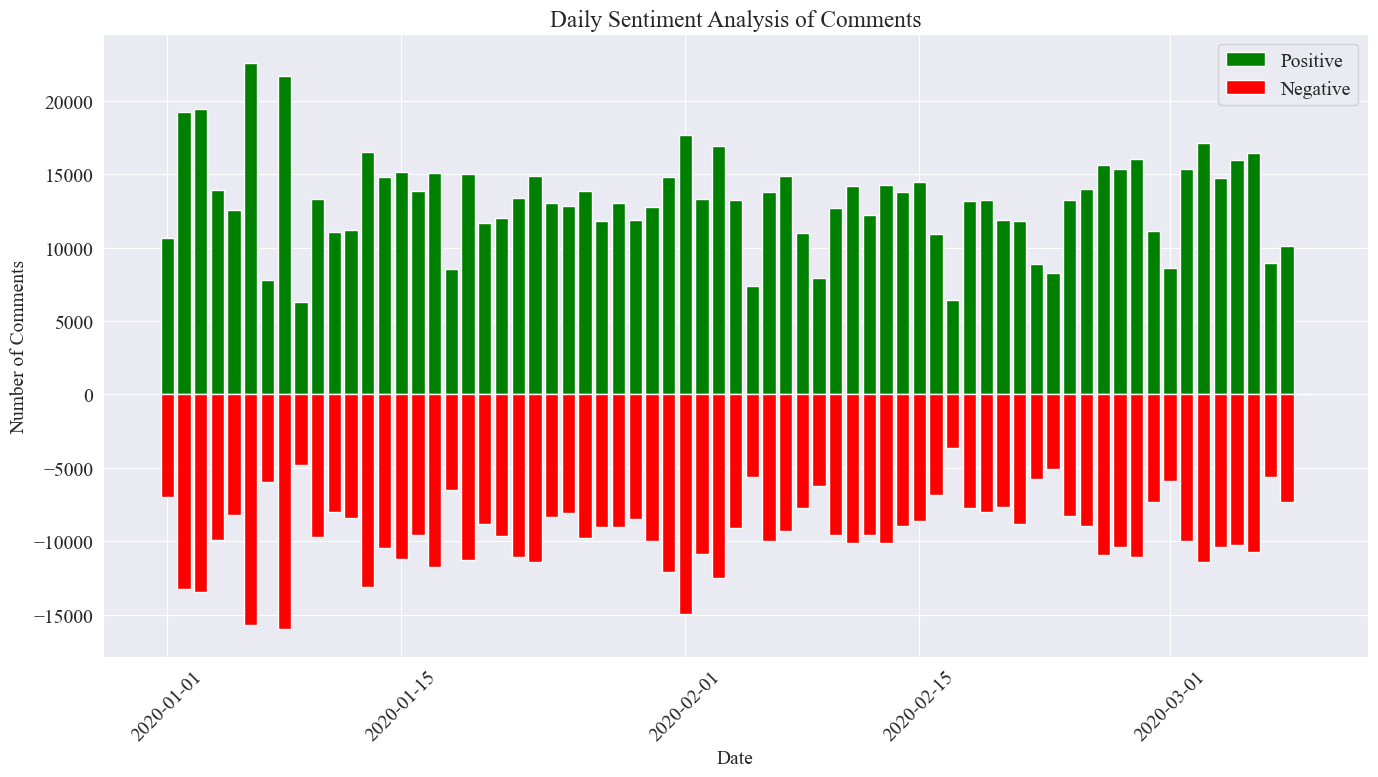
得到最终统计图像如上,可以看出疫情期间积极评论略微高于消极评论,通过统计积极评论占比,得知积极评论占比为58.63%,说明民众对疫情态度较为积极。
各地区评论情感分析
通过统计各省份地区发布评论的积极评论占比,得到各地区积极评论占比图。
# 计算各地区的积极评论数量和总评论数量 area_sentiment_stats = comment_df.groupby('province').agg( total_comments=('comment_content', 'count'), positive_comments=('sentiment', lambda x: (x > 0.5).sum()) ) # 计算各地区的积极评论占比 area_sentiment_stats['positive_ratio'] = area_sentiment_stats['positive_comments'] / area_sentiment_stats['total_comments'] # 绘制柱状图 plt.figure(figsize=(14, 7)) plt.bar(area_sentiment_stats.index, area_sentiment_stats['positive_ratio'], color='skyblue') plt.xlabel('地区') plt.ylabel('积极评论占比') plt.title('各地区的积极评论占比') plt.xticks(rotation=90) plt.tight_layout() plt.show()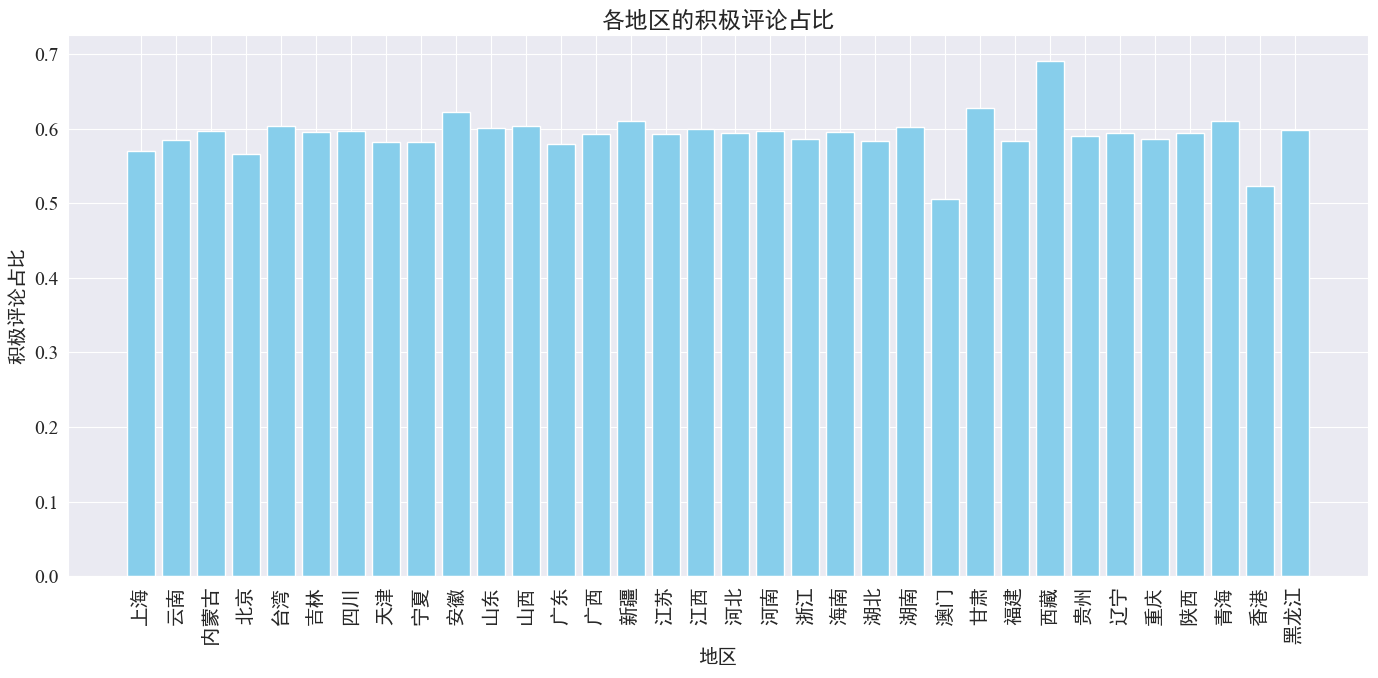
由上图可知,大多数省份的积极评论占比在60%左右,其中香港、澳门的积极评论占比最低,约为50%,而西藏的积极评论占比最高,接近70%。
通过以上评论分布占比可知,大陆地区评论多为积极评论,而港澳地区消极评论明显增多,其中西藏积极评论最高可能是因为西藏地区样本量较少导致的误差。
新闻评论词云图绘制
分别统计所有评论、积极评论与消极评论的词云图,在词云图绘制中,将积极评论列为0.6以上,消极评论列为0.4以下,以下为绘制的三张词云图。

可以看出,大部分人的疫情期间评论比较简单,如“哈哈”、“good”等,积极评论中,可以看到“中国加油”,“武汉加油”等鼓励文字,而消极评论中则有“呵呵”、“发国难财”等批评文字。