"""
文档注释: 三引号 出现在文件开头
爬虫流程:1.请求 2.解析 3.保存
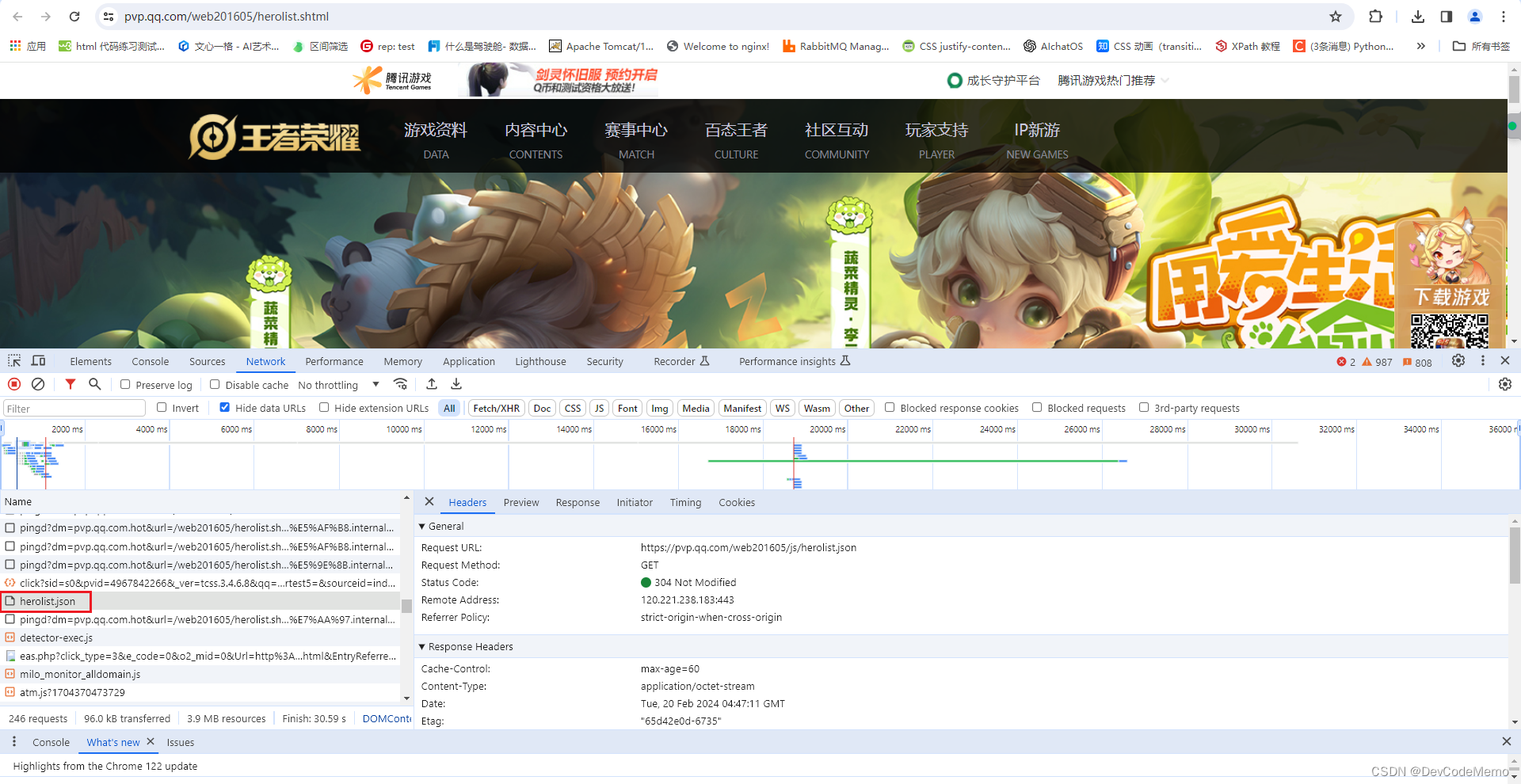
1. 需要找到请求地址(F12 调试工具 网络页签 刷新 搜索 查找)
url = "https://pvp.qq.com/web201605/js/herolist.json"
需要使用请求工具 urllib 包 (python 内置的请求工具)
2. 解析(遍历 提取目标数据)
3. 保存
"""
# 从urllib 包下导入 request请求工具
from urllib import request
# 导入 数据转换模块
import json
# 请求一个网址 将返回内容存入response响应对象
response = request.urlopen("https://pvp.qq.com/web201605/js/herolist.json")
# 读取结果 解码utf8 将最终内容放入response
response = response.read().decode("utf8")
# 将字符串response 转换为方便使用的对象
response = json.loads(response)
# 使用for遍历response
for data in response:
# 解析中文名 和头像地址
head_url = f'https://game.gtimg.cn/images/yxzj/img201606/heroimg/{data["ename"]}/{data["ename"]}.jpg'
cname = data["cname"]
# print(cname, head_url)
# 向头像地址 再次发起请求
head_response = request.urlopen(head_url)
head_response = head_response.read()
# 将返回的头像数据保存到文件
file = open(f"./heads/{cname}.jpg", "wb")
file.write(head_response)
file.close()
print(f"保存 {cname} 成功")
爬虫学习笔记-requests爬取王者荣耀皮肤图片
2024-07-12 18:42:04 39 阅读



















![【YOLOv10改进[注意力]】使用iRMB倒置残差块注意力(2023.8)改进C2f+ 含全部代码和详细修改方式 + 手撕结构图](https://i-blog.csdnimg.cn/direct/d913ab0e9c364cb9816ff6f0fce728ea.png)