网上关于爬虫大部分教程和编辑器用的都不是vscode ,此教程用到了vscode、Python、bs4、requests。
vscode配置Python安装环境可以看看这个大佬的教程 03-vscode安装和配置_哔哩哔哩_bilibili
vscode配置爬虫环境可以参考这个大佬的教程【用Vscode实现简单的python爬虫】从安装到配置环境变量到简单爬虫以及python中pip和request,bs4安装_vscode爬虫-CSDN博客
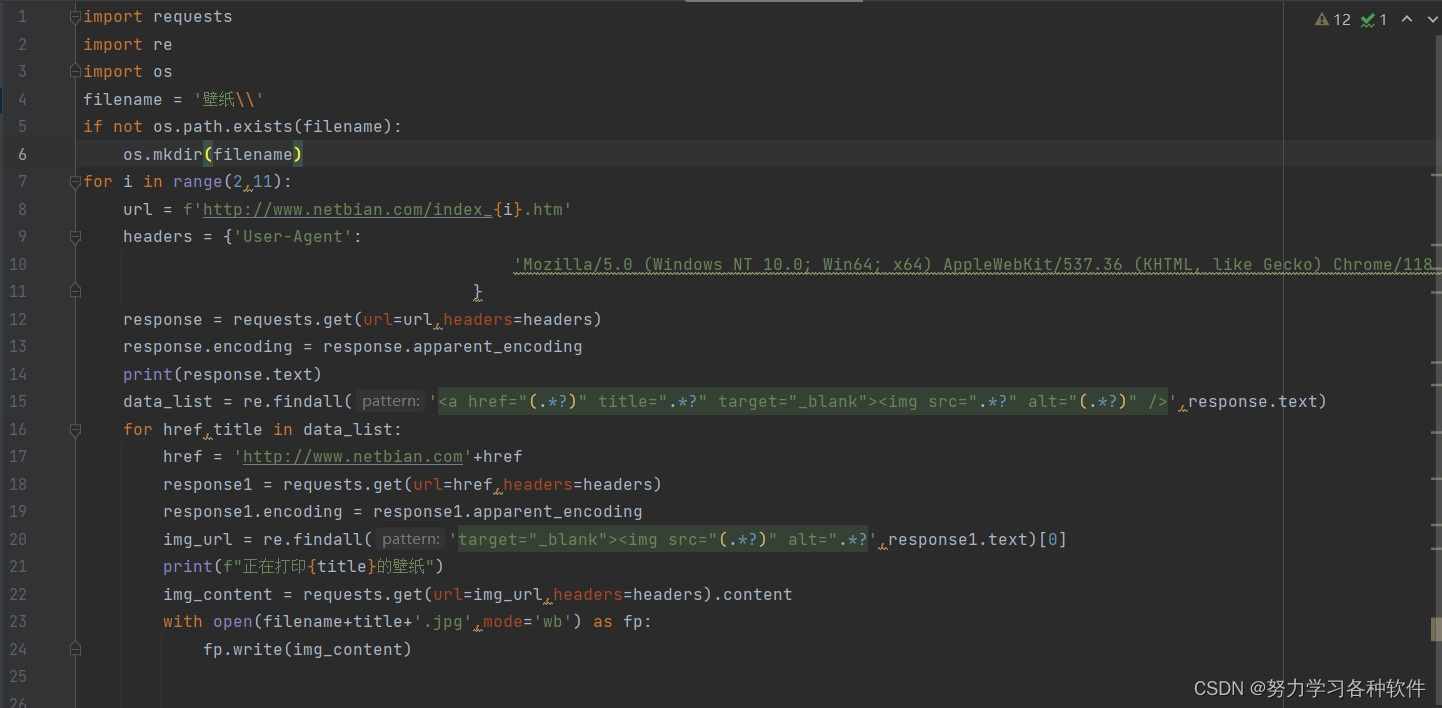
爬虫代码如下
#按照指令升级pip库,如果无法解析pip指令说明系统变量环境path中缺少了Python的路径,解决办法:https://zhuanlan.zhihu.com/p/655640807
#发送请求的模块 pip install requests
import requests
#解析HTML的模块 pip install bs4
from bs4 import BeautifulSoup
import os
import re
headers1={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0"
}
def requests_url(req_url):
response= requests.get(req_url,headers=headers1)
response.encoding='gbk' #网页编码gbk
return response.text
#获取英雄列表里面的英雄详情页网址以及英雄编号
#https://pvp.qq.com/web201605/herolist.shtml
#解析标签,获取到英雄详情页以及英雄名字<a href="herodetail/lianpo.shtml" target="_blank"><img src="//game.gtimg.cn/images/yxzj/img201606/heroimg/105/105.jpg" width="91" height="91" alt="廉颇">廉颇</a>
#
herolist_resp= requests_url("https://pvp.qq.com/web201605/herolist.shtml")
soup = BeautifulSoup(herolist_resp,"html.parser")
ul = soup.find_all("ul",attrs={"class":"herolist clearfix"})
icon_list = ul[0].find_all("a")
for i,n in enumerate(icon_list):
hrefs=n.get("href")
url = "https://pvp.qq.com/web201605/"+ hrefs
id = re.findall(r'\d+',hrefs)[0] #获取英雄编号
imgs=n.findAll('img')[0]
c_name= imgs.get("alt")
local_path = "王者荣耀\\"+c_name+"\\" #创建英雄文件夹
if not os.path.exists(local_path):
os.makedirs(local_path)
#获取详情页
herodetail_resp = requests_url(url)
soup = BeautifulSoup(herodetail_resp,"html.parser")
ul = soup.findAll("ul",attrs={"class":"pic-pf-list pic-pf-list3"})
#data-imgname属性获取
names = ul[0].get("data-imgname")
names=[name[0:name.index('&')]for name in names.split('|')]
print(names)
#提取皮肤名字
for i,n in enumerate(names) :
print (n)
# for num in range(105,108): #563
#response = requests.get(f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{num}/{num}-bigskin-1.jpg",headers=headers1)
response = requests.get(f"https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id}/{id}-bigskin-{i+1}.jpg",headers=headers1)
#保存图片
with open (local_path+f"{n}.jpg",'wb') as f:
f.write(response.content)
此爬虫支持不同英雄的壁纸根据皮肤名称分类存放,具体效果可以观看B站视频vscode编写Python爬虫,爬取王者荣耀皮肤壁纸_哔哩哔哩_bilibili。
























![[AutoSar]状态管理(一)单核 ECUM](https://img-blog.csdnimg.cn/33a405d400ac47fabd94f961dbcb6eb1.png)