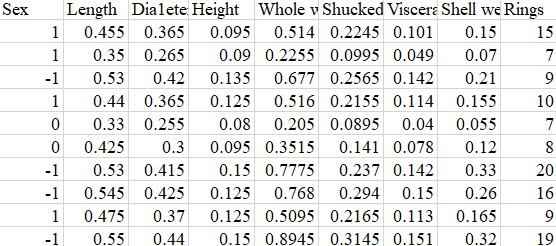
用到了jsdom库,直接现成处理html标签结构,只需要关心format格式化样式即可。
比较简易,待后续优化,目前只是短时间批量转换html文件。
const { JSDOM } = require('jsdom');
const getText = (htmlString) => {
if (!htmlString) return "";
if (typeof (htmlString) !== 'string') {
htmlString = htmlString.textContent;
}
return htmlString.replaceAll(/\s+/g, ' ');
}
const format = {
h1: (element) => {
return `\n# ${getText(element)}\n`;
},
h2: (element) => {
return `\n## ${getText(element)}\n`;
},
h3: (element) => {
return `\n### ${getText(element)}\n`;
},
h4: (element) => {
return `\n#### ${getText(element)}\n`;
},
h5: (element) => {
return `\n##### ${getText(element)}\n`;
},
h6: (element) => {
return `\n###### ${getText(element)}\n`;
},
code: (element) => {
let className = element.getAttribute('class') || '';
className = className.replace('language-', '');
return '\n```' + className + "\n" + element.textContent + "\n```\n";
},
blockquote: (element) => {
let result=reformat(element);
let arr=result.split("\n\n");
return "> "+arr.join("> ");
},
p: (element) => {
return `\n${getText(reformat(element))}\n`;
},
strong: (element) => {
return `**${getText(element)}**`
},
a: (element) => {
return `[${getText(element)}](${element.getAttribute("href")})`
},
s: (element) => {
return `~~${getText(element)}~~`
},
em: (element) => {
return `*${getText(element)}*`
},
img: (element) => {
return `})`;
},
ol: (element) => {
let result = "\n";
let index = 1;
for (let child of element.childNodes) {
if (child.tagName && child.tagName.toLowerCase() === 'li') {
result += `${index++}. ${getText(child)}\n`;
}
}
return result;
},
ul: (element) => {
let result = "\n";
for (let child of element.childNodes) {
if (child.tagName && child.tagName.toLowerCase() === 'li') {
result += `- ${getText(child)}\n`;
}
}
return result;
},
table: (element) => {
let result = "\n";
let row = 0;
const getTRString = (tr) => {
let str = "|";
if (tr) {
for (let td of tr.childNodes) {
if (td.tagName && td.tagName.toLowerCase() === 'td') {
str += " " + getText(td) + " |"
}
}
}
if (str.length == 1) str = '| |'
return str + "\n";
}
for (let child of element.childNodes) {
if (child.tagName) {
for (let tr of child.childNodes) {
if (tr.tagName && tr.tagName.toLowerCase() === 'tr') {
result += getTRString(tr);
row++;
if (row == 1) {//这个是markdown识别表格的标识 |---|---|--|----|--| 一般情况下宽度会自适应
result += "|"
for (let td of tr.childNodes) {
if (td.tagName && td.tagName.toLowerCase() === 'td') {
result += "---|";
}
}
result += "\n";
}
}
}
}
}
return result;
}
}
//二次格式化,如<p><strong>123</strong></p> 第一次格式化只会匹配到p,因此需要二次格式化处理内在元素
const reformat = (element) => {
let result = "";
for (let child of element.childNodes) {
if (child.tagName && format[child.tagName.toLowerCase()]) {//拦截命中
result += format[child.tagName.toLowerCase()](child);
} else {//没有需要处理的标签,深入处理
result += getText(child.textContent);
}
}
return result;
}
const dp = (element) => {
let markdownStringArray = [];
for (let child of element.childNodes) {
if (child.tagName) {
let functionName = child.tagName.toLowerCase();//取出标签名称
if (format[functionName]) {//拦截命中
markdownStringArray.push(format[functionName](child));
} else {//没有需要处理的标签,深入处理
markdownStringArray = markdownStringArray.concat(dp(child));
}
}
}
return markdownStringArray;
}
exports.html_to_markdown = (htmlString) => {
const dom = new JSDOM(htmlString);
const body = dom.window.document.body;
let arr = dp(body);
return arr.join("");
}使用方法
const markdownString= html_to_markdown(html);