前言
熟话说得好,创新点不够,智能优化算法来凑,不要觉得羞耻,因为不仅我们这么干,很多外国人也这么干!因为创新点实在太难想了,和优化算法结合下是最简单的创新点了!
之前给大家分享了66个智能优化算法,更新了最近几年发表在一区期刊的智能优化算法以及改进的优化算法。虽然有这么多个优化算法,但很多小伙伴表示还是不会用,没有目标函数。
BP神经网络以及智能优化算法对其初始参数的优化一直是一个热点的话题,每年的毕设都有N多小伙伴需要这个,而这种复杂的有很多局部最优点的优化问题就是智能优化算法的一个很好的应用,那这期内容我们就分享66个智能优化算法优化BP神经网络的代码实现,但学会这期分享,本质上可以实现任意智能优化算法优化BP神经网络
文末福利:拉到,有必须拿下的福利哦
数据集
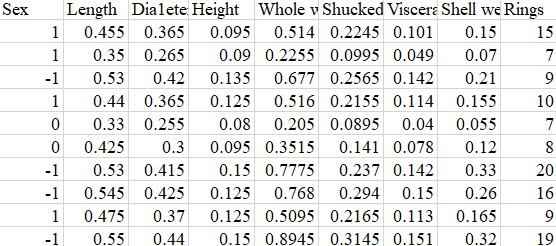
用经典鲍鱼数据集为例,最后Rings是需要预测的即鲍鱼的年龄,用性别(1:雄性,M;0:中性l ; -1:雌性,F)和一些体征如长度、高度、重量等进行预测。因变量是鲍鱼的年龄,有多个自变量,是一个典型多元回归问题。
鲍鱼数据形式如下:

目标函数
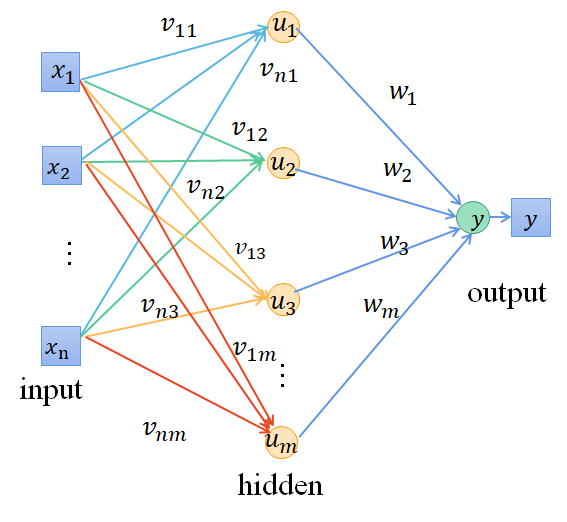
对于一个固定结构的神经网络,即神经网络层数、神经元个数以及激活函数都一样的情况下,可以通过优化网络结构的初始参数来优化整个网络的参数和结构。
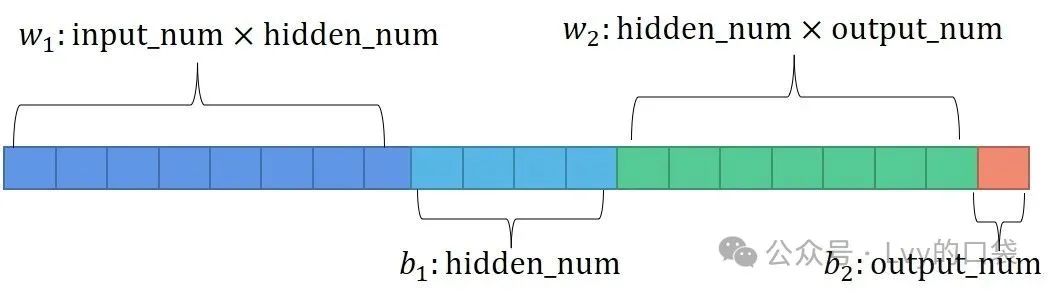
把优化的参数拉平成一条进行优化,优化参数的维度和网络结构有关,我们的优化目标就是优化出一个初始网络结构超参数,能让网络正向传播得到的预测值和真实值最接近。因此我们通用的目标函数可以设置如下:
function fitness_value =objfun(input_pop)global input_num hidden_num output_num input_data output_dataw1=input_pop(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=input_pop(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=input_pop(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=input_pop(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值W1=reshape(w1,hidden_num,input_num);W2=reshape(w2,output_num,hidden_num);B1=reshape(B1,hidden_num,1);B2=reshape(B2,output_num,1);[~,n]=size(input_data);A1=logsig(W1*input_data+repmat(B1,1,n)); %需与main函数中激活函数相同A2=purelin(W2*A1+repmat(B2,1,n)); %需与main函数中激活函数相同error=sumsqr(output_data-A2);fitness_value=error; %误差即为适应度end

数据集划分与超参数设置
clc;clear; close all;load('abalone_data.mat')%鲍鱼数据global input_num hidden_num output_num input_data output_data train_num test_num x_train_mu y_train_mu x_train_sigma y_train_sigma%% 导入数据%设置训练数据和测试数据[m,n]=size(data);train_num=round(0.8*m); %自变量test_num=m-train_num;x_train_data=data(1:train_num,1:n-1);y_train_data=data(1:train_num,n);%测试数据x_test_data=data(train_num+1:end,1:n-1);y_test_data=data(train_num+1:end,n);%% 标准化[x_train_regular,x_train_mu,x_train_sigma] = zscore(x_train_data);[y_train_regular,y_train_mu,y_train_sigma]= zscore(y_train_data);x_train_regular=x_train_regular';y_train_regular=y_train_regular';input_data=x_train_regular;output_data=y_train_regular;input_num=size(x_train_regular,1); %输入特征个数hidden_num=6; %隐藏层神经元个数output_num=size(y_train_regular,1); %输出特征个数num_all=input_num*hidden_num+hidden_num+hidden_num*output_num+output_num;%网络总参数,只含一层隐藏层;%%%自变量的个数即为网络连接权重以及偏置popmax=1.5; %自变量即网络权重和偏置的上限popmin=-1.5; %自变量即网络权重和偏置的下限SearchAgents_no=50; % Number of search agents 搜索麻雀数量Max_iteration=300; % Maximum numbef of iterations 最大迭代次数% Load details of the selected benchmark function
超参数的优化和最终结果的获取
以下展示了,使用智能优化算法优化超参数前后的使用方法,在初始超参数优化完毕后,直接把结果带入到神经网络中,再进行反向传播的训练,
%%fobj=@objfun;Time_compare=[]; %算法的运行时间比较Fival_compare=[]; %算法的最终目标比较Fival_compare1=[]; %优化过后的初始参数经过反向传播的优化Fival_compare2=[];curve_compare=[]; %算法的过程函数比较name_all=[]; %算法的名称记录dim=num_all;lb=popmin;ub=popmax;pop_num=SearchAgents_no;Max_iter=Max_iteration;%% 不进行优化,随机赋值iter=1;bestX=lb+(ub-lb).*rand(1,num_all);ER_=Fun1(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_1=Fun2(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);Fival_compare1=[Fival_compare1,ER_];Fival_compare2=[Fival_compare2,ER_1];name_all{1,iter}='NO-opti';iter=iter+1;%% 麻雀搜索算法t1=clock;[fMin_SSA,bestX_SSA,SSA_curve]=SSA(pop_num,Max_iter,lb,ub,dim,fobj); %麻雀搜索算法ER_SSA=Fun1(bestX_SSA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_SSA1=Fun2(bestX_SSA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);t2=clock;time_SSA=(t2(end)+t2(end-1)*60+t2(end-2)*3600-t1(end)-t1(end-1)*60-t1(end-2)*3600);Fival_compare=[Fival_compare,fMin_SSA];Fival_compare1=[Fival_compare1,ER_SSA];Fival_compare2=[Fival_compare2,ER_SSA1];Time_compare=[Time_compare,time_SSA(end)];curve_compare=[curve_compare;SSA_curve];name_all{1,iter}='SSA';iter=iter+1;
第一个神经网络计算函数是MATLAB自带的BP工具箱
function [EcRMSE]=Fun1(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data)global input_num output_num x_train_mu y_train_mu x_train_sigma y_train_sigmabestchrom=bestX;net=newff(x_train_regular,y_train_regular,hidden_num,{'logsig','purelin'},'trainlm');w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值net.iw{1,1}=reshape(w1,hidden_num,input_num);net.lw{2,1}=reshape(w2,output_num,hidden_num);net.b{1}=reshape(B1,hidden_num,1);net.b{2}=reshape(B2,output_num,1);net.trainParam.epochs=200; %最大迭代次数net.trainParam.lr=0.1; %学习率net.trainParam.goal=0.00001;[net,~]=train(net,x_train_regular,y_train_regular);%将输入数据归一化test_num=size(x_test_data,1);x_test_regular = (x_test_data-repmat(x_train_mu,test_num,1))./repmat(x_train_sigma,test_num,1);%放入到网络输出数据y_test_regular=sim(net,x_test_regular');%将得到的数据反归一化得到预测数据test_out_std=y_test_regular;%反归一化SSA_BP_predict=test_out_std*y_train_sigma+y_train_mu;errors_nn=sum(abs(SSA_BP_predict'-y_test_data)./(y_test_data))/length(y_test_data);EcRMSE=sqrt(sum((errors_nn).^2)/length(errors_nn));% disp(EcRMSE)end
第二个神经网络计算函数是小编自己写的BP函数
function [EcRMSE]=Fun2(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data)global input_num output_num x_train_mu y_train_mu x_train_sigma y_train_sigmatrain_num=length(y_train_regular); %自变量test_num=length(y_test_data);bestchrom=bestX;% net=newff(x_train_regular,y_train_regular,hidden_num,{'tansig','purelin'},'trainlm');w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值x_train_std=x_train_regular;y_train_std=y_train_regular;%vij = reshape(w1,hidden_num,input_num) ;%输入和隐藏层的权重theta_u = reshape(B1,hidden_num,1);%输入与隐藏层之间的阈值Wj = reshape(w2,output_num,hidden_num);%%输出和隐藏层的权重theta_y =reshape(B2,output_num,1);%输出与隐藏层之间的阈值%learn_rate = 0.0001;%学习率Epochs_max = 10000;%最大迭代次数error_rate = 0.1;%目标误差Obj_save = zeros(1,Epochs_max);%损失函数% 训练网络epoch_num=0;while epoch_num <Epochs_maxepoch_num=epoch_num+1;y_pre_std_u=vij * x_train_std + repmat(theta_u, 1, train_num);y_pre_std_u1 = logsig(y_pre_std_u);y_pre_std_y = Wj * y_pre_std_u1 + repmat(theta_y, 1, train_num);y_pre_std_y1=y_pre_std_y;obj = y_pre_std_y1-y_train_std ;Ems = sumsqr(obj);Obj_save(epoch_num) = Ems;if Ems < error_ratebreak;end%梯度下降%输出采用rule函数,隐藏层采用sigomd激活函数c_wj= 2*(y_pre_std_y1-y_train_std)* y_pre_std_u1';c_theta_y=2*(y_pre_std_y1-y_train_std)*ones(train_num, 1);c_vij=Wj'* 2*(y_pre_std_y1-y_train_std).*(y_pre_std_u1).*(1-y_pre_std_u1)* x_train_std';c_theta_u=Wj'* 2*(y_pre_std_y1-y_train_std).*(y_pre_std_u1).*(1-y_pre_std_u1)* ones(train_num, 1);Wj=Wj-learn_rate*c_wj;theta_y=theta_y-learn_rate*c_theta_y;vij=vij- learn_rate*c_vij;theta_u=theta_u-learn_rate*c_theta_u;end%x_test_regular = (x_test_data-repmat(x_train_mu,test_num,1))./repmat(x_train_sigma,test_num,1);% x_test_regular = mapminmax('apply',x_test_data,x_train_maxmin);%放入到网络输出数据x_test_std=x_test_regular';test_put = logsig(vij * x_test_std + repmat(theta_u, 1, test_num));test_out_std = Wj * test_put + repmat(theta_y, 1, test_num);%反归一化SSA_BP_predict=test_out_std*y_train_sigma+y_train_mu;errors_nn=sum(abs(SSA_BP_predict'-y_test_data)./(y_test_data))/length(y_test_data);EcRMSE=sqrt(sum((errors_nn).^2)/length(errors_nn));disp(EcRMSE)end
得到不同优化函数优化BP神经网络的适应度曲线如下
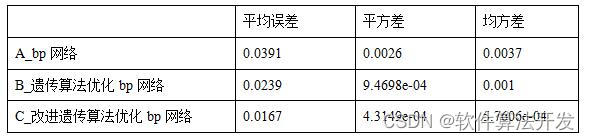
将初始参数带入到BP网络模型中,反向传播训练可以得到BP工具箱优化的结果以及自己写的网络结果,两者效果相差不太大
以下是两种实现方式的对比

运行多次记录结果
不可否认的是,因为智能优化算法的存在,每次优化是有一定的随机性的,因此我们可以多次运行取均值和方差去衡量总体的结果
clc;clear; close all;load('data_test1.mat')global input_num hidden_num output_num input_data output_data train_num test_num x_train_mu y_train_mu x_train_sigma y_train_sigma%% 循环5次记录结果 训练集和测试集随机%% 导入数据%设置训练数据和测试数据NUM=5; %随机测试数for NN=1:NUM[m,n]=size(data);train_num=round(0.8*m); %自变量randlabel=randperm(m); %随机标签test_num=m-train_num;x_train_data=data(randlabel(1:train_num),1:n-1);y_train_data=data(randlabel(1:train_num),n);%测试数据x_test_data=data(randlabel(train_num+1:end),1:n-1);y_test_data=data(randlabel(train_num+1:end),n);% x_train_data=x_train_data';% y_train_data=y_train_data';% x_test_data=x_test_data';%% 标准化[x_train_regular,x_train_mu,x_train_sigma] = zscore(x_train_data);[y_train_regular,y_train_mu,y_train_sigma]= zscore(y_train_data);x_train_regular=x_train_regular';y_train_regular=y_train_regular';input_data=x_train_regular;output_data=y_train_regular;input_num=size(x_train_regular,1); %输入特征个数hidden_num=6; %隐藏层神经元个数output_num=size(y_train_regular,1); %输出特征个数num_all=input_num*hidden_num+hidden_num+hidden_num*output_num+output_num;%网络总参数,只含一层隐藏层;%自变量的个数即为网络连接权重以及偏置popmax=1.5; %自变量即网络权重和偏置的上限popmin=-1.5; %自变量即网络权重和偏置的下限SearchAgents_no=50; % Number of search agents 搜索麻雀数量Max_iteration=300; % Maximum numbef of iterations 最大迭代次数% Load details of the selected benchmark function%%fobj=@objfun;Time_compare=[]; %算法的运行时间比较Fival_compare=[]; %算法的最终目标比较Fival_compare1=[]; %优化过后的初始参数经过反向传播的优化Fival_compare2=[];curve_compare=[]; %算法的过程函数比较name_all=[]; %算法的名称记录dim=num_all;lb=popmax*ones(1,dim);ub=popmin*ones(1,dim);pop_num=SearchAgents_no;Max_iter=Max_iteration;%% 不进行优化,随机赋值iter=1;bestX=lb+(ub-lb).*rand(1,num_all);ER_=Fun1(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_1=Fun2(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);Fival_compare1=[Fival_compare1,ER_];Fival_compare2=[Fival_compare2,ER_1];name_all{1,iter}='ON-opti';iter=iter+1;%%% [ER_1,WW]=Fun2(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);% % [fMin_SSA,bestX_SSA,SSA_curve]=SSA2(pop_num,pop_or,Max_iter,lb,ub,dim,fobj);% % ER2=fun3(bestX_SSA,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data);% pop_num11=500;% [fMin_SSA,bestX_SSA1,SSA_curve]=SSA2(pop_num11,WW,Max_iter,lb,ub,dim,fobj);% ER_2=fun3(bestX_SSA1,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data);% Fival_compare1=[Fival_compare1,ER_2];% Fival_compare2=[Fival_compare2,ER_2];% name_all{1,iter}='BP-SSA';% iter=iter+1;%% 改进麻雀搜索算法t1=clock;[fMin_SSA,bestX_SSA,SSA_curve]=G_SSA(pop_num,Max_iter,lb,ub,dim,fobj); %麻雀搜索算法ER_SSA=Fun1(bestX_SSA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_SSA1=Fun2(bestX_SSA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);t2=clock;time_SSA=(t2(end)+t2(end-1)*60+t2(end-2)*3600-t1(end)-t1(end-1)*60-t1(end-2)*3600);ER_SSA2=fun3(bestX_SSA,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data); %不进行BP反向Fival_compare=[Fival_compare,ER_SSA2];Fival_compare1=[Fival_compare1,ER_SSA];Fival_compare2=[Fival_compare2,ER_SSA1];Time_compare=[Time_compare,time_SSA(end)];curve_compare=[curve_compare;SSA_curve];name_all{1,iter}='G-SSA';iter=iter+1;%%%改进鲸鱼优化算法t1=clock;[fMin_EWOA,bestX_EWOA,EWOA_curve]=BKA(pop_num,Max_iter,lb,ub,dim,fobj);ER_EWOA=Fun1(bestX_EWOA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_EWOA1=Fun2(bestX_EWOA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);t2=clock;time_EWOA=(t2(end)+t2(end-1)*60+t2(end-2)*3600-t1(end)-t1(end-1)*60-t1(end-2)*3600);ER_EWOA2=fun3(bestX_EWOA,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data); %不进行BP反向Fival_compare=[Fival_compare,ER_EWOA2];Fival_compare1=[Fival_compare1,ER_EWOA];Fival_compare2=[Fival_compare2,ER_EWOA1];Time_compare=[Time_compare,time_EWOA(end)];curve_compare=[curve_compare;EWOA_curve];name_all{1,iter}='BKA';iter=iter+1;%%%正弦余弦优化算法 Sine Cosine Algorithmt1=clock;[fMin_SCA,bestX_SCA,SCA_curve]=SCA(pop_num,Max_iter,lb,ub,dim,fobj);ER_SCA=Fun1(bestX_SCA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_SCA1=Fun2(bestX_SCA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);t2=clock;time_SCA=(t2(end)+t2(end-1)*60+t2(end-2)*3600-t1(end)-t1(end-1)*60-t1(end-2)*3600);ER_SCA2=fun3(bestX_EWOA,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data); %不进行BP反向Fival_compare=[Fival_compare,ER_SCA2];Fival_compare1=[Fival_compare1,ER_SCA];Fival_compare2=[Fival_compare2,ER_SCA1];Time_compare=[Time_compare,time_SCA(end)];curve_compare=[curve_compare;SCA_curve];name_all{1,iter}='SCA';iter=iter+1;%%%POA%IGOA%IGWOt1=clock;[fMin_SCA,bestX_SCA,SCA_curve]=G_DBO(pop_num,Max_iter,lb,ub,dim,fobj);ER_SCA=Fun1(bestX_SCA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);ER_SCA1=Fun2(bestX_SCA,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data);t2=clock;ER_SCA2=fun3(bestX_EWOA,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data); %不进行BP反向time_SCA=(t2(end)+t2(end-1)*60+t2(end-2)*3600-t1(end)-t1(end-1)*60-t1(end-2)*3600);Fival_compare=[Fival_compare,ER_SCA2];Fival_compare1=[Fival_compare1,ER_SCA];Fival_compare2=[Fival_compare2,ER_SCA1];Time_compare=[Time_compare,time_SCA(end)];curve_compare=[curve_compare;SCA_curve];name_all{1,iter}='G-DBO';iter=iter+1;FFival_compare1(NN,:)=Fival_compare1;FFival_compare2(NN,:)=Fival_compare2;end%%load('color_list.mat')figure(3)color=color_list(randperm(length(color_list)),:);width=0.7; %柱状图宽度for i=1:length(Fival_compare1)set(bar(i,Fival_compare1(i),width),'FaceColor',color(i,:),'EdgeColor',[0,0,0],'LineWidth',2)hold on%在柱状图 x,y 基础上 绘制误差 ,low为下误差,high为上误差,LineStyle 误差图样式,'Color' 误差图颜色% 'LineWidth', 线宽,'CapSize',误差标注大小% errorbar(i, y(i), low(i), high(i), 'LineStyle', 'none', 'Color', color(i+3,:), 'LineWidth', 1.5,'CapSize',18);endylabel('obj-value')ylim([min(Fival_compare1)-0.01,max(Fival_compare1)+0.01]);ax=gca;ax.XTick = 1:1:length(Fival_compare1);set(gca,'XTickLabel',name_all,"LineWidth",2);set(gca,"FontSize",12,"LineWidth",2)title('优化工具箱')%%load('color_list.mat')figure(4)color=color_list(randperm(length(color_list)),:);width=0.7; %柱状图宽度for i=1:length(Fival_compare2)set(bar(i,Fival_compare2(i),width),'FaceColor',color(i,:),'EdgeColor',[0,0,0],'LineWidth',2)hold on%在柱状图 x,y 基础上 绘制误差 ,low为下误差,high为上误差,LineStyle 误差图样式,'Color' 误差图颜色% 'LineWidth', 线宽,'CapSize',误差标注大小% errorbar(i, y(i), low(i), high(i), 'LineStyle', 'none', 'Color', color(i+3,:), 'LineWidth', 1.5,'CapSize',18);endylabel('obj-value')ylim([min(Fival_compare2)-0.01,max(Fival_compare2)+0.01]);ax=gca;ax.XTick = 1:1:length(Fival_compare2);set(gca,'XTickLabel',name_all,"LineWidth",2);set(gca,"FontSize",12,"LineWidth",2)title('自写网络')%%figure(5)bar([Fival_compare1;Fival_compare2]')ylabel('obj-value')ylim([min(Fival_compare2)-0.01,max(Fival_compare2)+0.01]);ax=gca;ax.XTick = 1:1:length(Fival_compare2);set(gca,'XTickLabel',name_all,"LineWidth",2);set(gca,"FontSize",12,"LineWidth",2)legend('工具箱','自写网络')%%figure(7)color=[0.741176470588235,0.729411764705882,0.725490196078431;0.525490196078431,...0.623529411764706,0.752941176470588;0.631372549019608,0.803921568627451,...0.835294117647059;0.588235294117647,0.576470588235294,0.576470588235294;...0.0745098039215686,0.407843137254902,0.607843137254902;0.454901960784314,...0.737254901960784,0.776470588235294;0.0156862745098039,0.0196078431372549,0.0156862745098039];% 颜色1mean_compare1=mean(FFival_compare1);std1_compare1=std(FFival_compare1);mean_compare2=mean(FFival_compare2);std1_compare2=std(FFival_compare2);b=bar([mean_compare1;mean_compare2]');data=[mean_compare1;mean_compare2]';hold onerro_data=[std1_compare1;std1_compare1]';ax = gca;for i = 1 : 2x_data(:, i) = b(i).XEndPoints';endfor i=1:2errorbar(x_data(:,i),data(:,i),erro_data(:,i),'LineStyle', 'none','Color',color(i+3,:) ,'LineWidth', 2,'CapSize',18)endfor i =1:2b(i).FaceColor = color(i,:);b(i).EdgeColor= color(i+3,:);b(i).LineWidth=1.5;endylabel('obj-value')maxl=max([mean_compare1,mean_compare2]);minl=min([mean_compare1,mean_compare2]);ylim([minl-0.01,maxl+0.01]);ax=gca;ax.XTick = 1:1:length(Fival_compare2);set(gca,'XTickLabel',name_all,"LineWidth",2);set(gca,"FontSize",12,"LineWidth",2)legend('工具箱','自写网络')box off% net=newff(x_train_regular,y_train_regular,hidden_num,{'logsig','purelin'},'trainlm','deviderand');%%% function fitness_value =objfun(input_pop,input_num,hidden_num,output_num,input_data,output_data)function fitness_value =objfun(input_pop)global input_num hidden_num output_num input_data output_dataw1=input_pop(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=input_pop(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=input_pop(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=input_pop(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值W1=reshape(w1,hidden_num,input_num);W2=reshape(w2,output_num,hidden_num);B1=reshape(B1,hidden_num,1);B2=reshape(B2,output_num,1);[~,n]=size(input_data);A1=logsig(W1*input_data+repmat(B1,1,n)); %需与main函数中激活函数相同A2=purelin(W2*A1+repmat(B2,1,n)); %需与main函数中激活函数相同error=sumsqr(output_data-A2);fitness_value=error; %误差即为适应度end%%function EcRMSE =fun3(input_pop,x_test_data,x_train_mu,x_train_sigma,y_train_mu,y_train_sigma,y_test_data)global input_num hidden_num output_numw1=input_pop(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=input_pop(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=input_pop(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=input_pop(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值% W1=reshape(w1,hidden_num,input_num);% W2=reshape(w2,output_num,hidden_num);% B1=reshape(B1,hidden_num,1);% B2=reshape(B2,output_num,1);vij = reshape(w1,hidden_num,input_num) ;%输入和隐藏层的权重theta_u = reshape(B1,hidden_num,1);%输入与隐藏层之间的阈值Wj = reshape(w2,output_num,hidden_num);%%输出和隐藏层的权重theta_y =reshape(B2,output_num,1);%输出与隐藏层之间的阈值% [~,n]=size(input_data);% A1=logsig(W1*input_data+repmat(B1,1,n)); %需与main函数中激活函数相同% A2=purelin(W2*A1+repmat(B2,1,n)); %需与main函数中激活函数相同% error=sumsqr(output_data-A2);% fitness_value=error; %误差即为适应度test_num=size(x_test_data,1);x_test_regular = (x_test_data-repmat(x_train_mu,test_num,1))./repmat(x_train_sigma,test_num,1);% x_test_regular = mapminmax('apply',x_test_data,x_train_maxmin);%放入到网络输出数据x_test_std=x_test_regular';test_put = logsig(vij * x_test_std + repmat(theta_u, 1, test_num));test_out_std = Wj * test_put + repmat(theta_y, 1, test_num);%反归一化SSA_BP_predict=test_out_std*y_train_sigma+y_train_mu;errors_nn=sum(abs(SSA_BP_predict'-y_test_data)./(y_test_data))/length(y_test_data);EcRMSE=sqrt(sum((errors_nn).^2)/length(errors_nn));% disp(EcRMSE)end%%function [EcRMSE,net1]=Fun1(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data)global input_num output_num x_train_mu y_train_mu x_train_sigma y_train_sigmabestchrom=bestX;net=newff(x_train_regular,y_train_regular,hidden_num,{'logsig','purelin'},'trainlm');w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值net.iw{1,1}=reshape(w1,hidden_num,input_num);net.lw{2,1}=reshape(w2,output_num,hidden_num);net.b{1}=reshape(B1,hidden_num,1);net.b{2}=reshape(B2,output_num,1);net.trainParam.epochs=200; %最大迭代次数net.trainParam.lr=0.1; %学习率net.trainParam.goal=0.00001;[net,~]=train(net,x_train_regular,y_train_regular);%将输入数据归一化test_num=size(x_test_data,1);x_test_regular = (x_test_data-repmat(x_train_mu,test_num,1))./repmat(x_train_sigma,test_num,1);%放入到网络输出数据y_test_regular=sim(net,x_test_regular');net1=net;%将得到的数据反归一化得到预测数据test_out_std=y_test_regular;%反归一化SSA_BP_predict=test_out_std*y_train_sigma+y_train_mu;errors_nn=sum(abs(SSA_BP_predict'-y_test_data)./(y_test_data))/length(y_test_data);EcRMSE=sqrt(sum((errors_nn).^2)/length(errors_nn));disp(EcRMSE)end%%function [EcRMSE,WW]=Fun2(bestX,x_train_regular,y_train_regular,hidden_num,x_test_data,y_test_data)global input_num output_num x_train_mu y_train_mu x_train_sigma y_train_sigmatrain_num=length(y_train_regular); %自变量test_num=length(y_test_data);bestchrom=bestX;% net=newff(x_train_regular,y_train_regular,hidden_num,{'tansig','purelin'},'trainlm');w1=bestchrom(1:input_num*hidden_num); %输入和隐藏层之间的权重参数B1=bestchrom(input_num*hidden_num+1:input_num*hidden_num+hidden_num); %隐藏层神经元的偏置w2=bestchrom(input_num*hidden_num+hidden_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num); %隐藏层和输出层之间的偏置B2=bestchrom(input_num*hidden_num+hidden_num+hidden_num*output_num+1:input_num*hidden_num+...hidden_num+hidden_num*output_num+output_num); %输出层神经元的偏置%网络权值赋值x_train_std=x_train_regular;y_train_std=y_train_regular;%vij = reshape(w1,hidden_num,input_num) ;%输入和隐藏层的权重theta_u = reshape(B1,hidden_num,1);%输入与隐藏层之间的阈值Wj = reshape(w2,output_num,hidden_num);%%输出和隐藏层的权重theta_y =reshape(B2,output_num,1);%输出与隐藏层之间的阈值%learn_rate = 0.0001;%学习率Epochs_max = 30000;%最大迭代次数error_rate = 0.001;%目标误差Obj_save = zeros(1,Epochs_max);%损失函数% 训练网络epoch_num=0;while epoch_num <Epochs_maxepoch_num=epoch_num+1;y_pre_std_u=vij * x_train_std + repmat(theta_u, 1, train_num);y_pre_std_u1 = logsig(y_pre_std_u);y_pre_std_y = Wj * y_pre_std_u1 + repmat(theta_y, 1, train_num);y_pre_std_y1=y_pre_std_y;obj = y_pre_std_y1-y_train_std ;Ems = sumsqr(obj);Obj_save(epoch_num) = Ems;if Ems < error_ratebreak;end%梯度下降%输出采用rule函数,隐藏层采用sigomd激活函数c_wj= 2*(y_pre_std_y1-y_train_std)* y_pre_std_u1';c_theta_y=2*(y_pre_std_y1-y_train_std)*ones(train_num, 1);c_vij=Wj'* 2*(y_pre_std_y1-y_train_std).*(y_pre_std_u1).*(1-y_pre_std_u1)* x_train_std';c_theta_u=Wj'* 2*(y_pre_std_y1-y_train_std).*(y_pre_std_u1).*(1-y_pre_std_u1)* ones(train_num, 1);Wj=Wj-learn_rate*c_wj;theta_y=theta_y-learn_rate*c_theta_y;vij=vij- learn_rate*c_vij;theta_u=theta_u-learn_rate*c_theta_u;endWW=[vij(:);theta_u;Wj(:);theta_y];% W1=[Wj(:),theta_y,vij(:),theta_u];x_test_regular = (x_test_data-repmat(x_train_mu,test_num,1))./repmat(x_train_sigma,test_num,1);% x_test_regular = mapminmax('apply',x_test_data,x_train_maxmin);%放入到网络输出数据x_test_std=x_test_regular';test_put = logsig(vij * x_test_std + repmat(theta_u, 1, test_num));test_out_std = Wj * test_put + repmat(theta_y, 1, test_num);%反归一化SSA_BP_predict=test_out_std*y_train_sigma+y_train_mu;errors_nn=sum(abs(SSA_BP_predict'-y_test_data)./(y_test_data))/length(y_test_data);EcRMSE=sqrt(sum((errors_nn).^2)/length(errors_nn));disp(EcRMSE)end
福利:
包含:
Java、云原生、GO语音、嵌入式、Linux、物联网、AI人工智能、python、C/C++/C#、软件测试、网络安全、Web前端、网页、大数据、Android大模型多线程、JVM、Spring、MySQL、Redis、Dubbo、中间件…等最全厂牌最新视频教程+源码+软件包+面试必考题和答案详解。
福利:想要的资料全都有 ,全免费,没有魔法和套路
————————————————————————————

关注公众号:资源充电吧
点击小卡片关注下,回复:学习