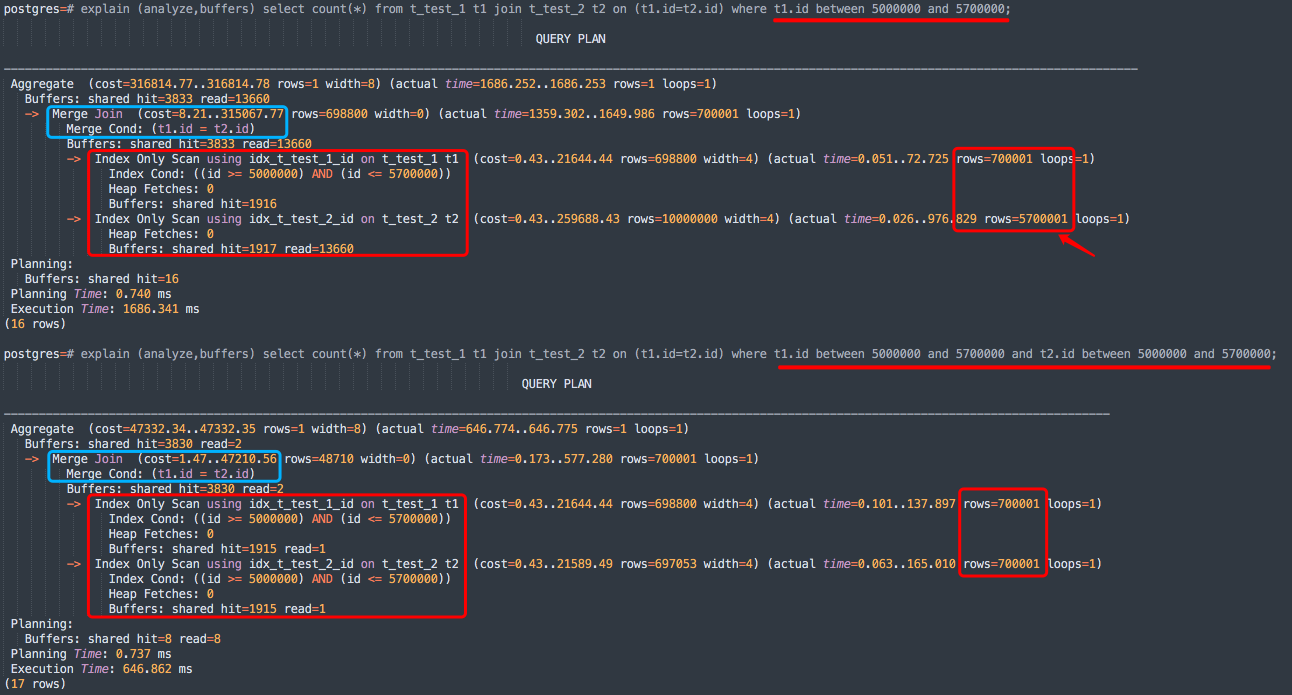
文章目录


在 PostgreSQL 中,对布尔类型数据的查询优化是确保数据库性能高效的重要方面。布尔类型通常用于表示二元的真或假状态,例如某个条件是否满足、某个标志是否设置等。下面我们将详细探讨如何优化对布尔类型数据的查询。
一、索引的合理使用
1. 常规 B-tree 索引
对于经常在 WHERE 子句中用于筛选的布尔列,可以考虑创建一个普通的 B-tree 索引。
假设我们有一个名为 orders 的表,其中有一个 is_paid 布尔类型列表示订单是否已支付,并且经常根据这个列来查询已支付或未支付的订单。
CREATE INDEX idx_is_paid ON orders (is_paid);
当执行以下查询时,索引将发挥作用:
SELECT * FROM orders WHERE is_paid = TRUE;
SELECT * FROM orders WHERE is_paid = FALSE;
PostgreSQL 可以利用索引快速定位到满足条件的数据,而不必扫描全表。
2. 部分索引
如果布尔列的值分布不平衡,例如大部分行的 is_paid 值为 FALSE,而我们主要关心 is_paid = TRUE 的情况,可以创建一个部分索引。
CREATE INDEX partial_idx_is_paid ON orders (is_paid) WHERE is_paid = TRUE;
这样,在查询 is_paid = TRUE 时,数据库将优先使用这个更小、更有针对性的索引,从而提高查询效率。但需要注意,部分索引只对特定的条件有用,对于查询 is_paid = FALSE 的情况,它不会被使用。
二、查询编写技巧
1. 避免不必要的类型转换
在编写查询时,要确保与布尔列进行比较的值也是布尔类型。如果不小心进行了类型转换,可能会导致索引无法使用。
错误的示例:
SELECT * FROM orders WHERE is_paid = 'true';
在上述示例中,将布尔值与字符串进行比较,PostgreSQL 会尝试进行类型转换,这可能会影响查询性能,尤其是当表很大并且有相关索引时。
正确的方式应该是:
SELECT * FROM orders WHERE is_paid = TRUE;
2. 逻辑表达式的优化
当使用多个布尔条件进行组合时,要注意逻辑表达式的优化。
例如,对于条件 A AND B 和 A OR B,如果 A 条件的筛选性更强(即能够排除更多的行),那么将 A 放在前面通常更好。因为数据库在处理条件时是从左到右进行的,先处理筛选性强的条件可以更快地减少需要处理的数据量。
-- 假设 has_discount 也是布尔类型
SELECT * FROM orders WHERE is_paid = TRUE AND has_discount = TRUE;
-- 如果 is_paid 能排除更多的行,将其放在前面可能更好
SELECT * FROM orders WHERE is_paid = TRUE AND has_discount = TRUE;
三、表结构设计
1. 避免过度细分的布尔列
如果有多个相关的布尔条件,并且它们总是一起使用来描述某个特定的状态或特征,考虑将它们合并为一个枚举类型或使用位运算来表示。
假设我们有三个布尔列 is_urgent、is_importtant、is_confidential 来描述一个任务的属性,如果总是一起查询这三个条件,可能不如创建一个整数类型的列,使用位运算来表示这三个属性。
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
attributes INT
);
-- 例如,1 表示 is_urgent,2 表示 is_importtant,4 表示 is_confidential
-- 一个任务既是紧急又是重要,可以将 attributes 设为 3 (1 + 2)
这样在查询时,可以通过位运算进行筛选,并且只需要处理一个列,而不是多个布尔列。
2. 规范化与反规范化
根据实际的业务需求和查询模式,决定是否对包含布尔列的表进行规范化或反规范化。
如果经常需要同时查询与布尔列相关的大量其他数据,并且这些数据在其他表中,可能会导致大量的连接操作,从而影响性能。在这种情况下,适当的反规范化(将相关数据冗余存储在一个表中)可能会提高查询性能,但同时要注意数据一致性的维护。
四、数据分布与分区
1. 数据分布的考虑
了解布尔列中不同值(TRUE 和 FALSE)的分布情况。如果数据分布极不均匀,可能需要考虑采取特殊的优化策略。
例如,如果 90% 的行 is_paid = FALSE,而查询主要关注 is_paid = TRUE 的行,可能需要对数据进行重新组织或分区,以便更快地访问所需的数据。
2. 表分区
如果根据布尔列的值进行分区是有意义的,并且数据量很大,可以考虑使用表分区。
假设按照 is_paid 进行分区:
CREATE TABLE orders_paid (
-- 与 orders 表相同的列定义
) PARTITION BY LIST (is_paid);
CREATE TABLE orders_paid_true PARTITION OF orders_paid FOR VALUES ('true');
CREATE TABLE orders_paid_false PARTITION OF orders_paid FOR VALUES ('false');
当查询 is_paid = TRUE 的订单时,数据库可以直接访问 orders_paid_true 分区,跳过 orders_paid_false 分区,从而提高查询效率。
五、数据库参数调整
1. 相关配置参数
PostgreSQL 有一些与查询优化相关的配置参数,可能会对布尔类型数据的查询产生影响。
例如,random_page_cost 参数影响了随机磁盘 I/O 的成本估计,调整这个参数可以改变数据库在索引扫描和顺序扫描之间的选择策略,从而影响查询性能。
2. 定期性能监控与调整
通过定期监控数据库的性能指标,如查询的执行时间、索引的使用情况等,根据实际的性能数据来调整相关的参数和优化策略。
六、示例分析
考虑一个电商数据库中的 orders 表,其中包含 is_paid(布尔型)和 order_date(日期型)列。我们经常需要查询特定日期范围内已支付和未支付的订单。
首先,创建表并插入一些示例数据:
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
is_paid BOOLEAN,
order_date DATE
);
INSERT INTO orders (is_paid, order_date)
VALUES
(TRUE, '2023-01-01'),
(FALSE, '2023-02-01'),
(TRUE, '2023-02-15'),
(FALSE, '2023-03-01'),
(TRUE, '2023-03-10');
如果没有为 is_paid 列创建索引,执行以下查询可能会很慢:
SELECT * FROM orders WHERE is_paid = TRUE AND order_date BETWEEN '2023-02-01' AND '2023-03-01';
为 is_paid 列创建索引后:
CREATE INDEX idx_is_paid ON orders (is_paid);
上述查询的性能将得到显著提升。
此外,如果发现查询主要关注已支付的订单,并且已支付的订单相对较少,可以创建一个部分索引:
CREATE INDEX partial_idx_is_paid ON orders (is_paid) WHERE is_paid = TRUE;
再执行针对已支付订单的查询,性能可能会进一步提高。
七、总结
优化 PostgreSQL 中对布尔类型数据的查询需要综合考虑索引的使用、查询编写技巧、表结构设计、数据分布与分区以及数据库参数调整等多个方面。通过合理的优化策略,可以显著提高查询性能,提升数据库的整体响应速度,为业务应用提供更好的支持。但需要注意的是,每个数据库系统和应用场景都有其独特性,因此优化策略需要根据实际情况进行测试和调整,以达到最佳的性能效果。
希望以上内容对你在 PostgreSQL 中优化布尔类型数据的查询有所帮助。如果在实际应用中遇到特定的问题或需要更深入的优化建议,请根据详细的数据库架构和查询模式进行进一步的分析和调整。

🎉相关推荐
- 🍅关注博主🎗️ 带你畅游技术世界,不错过每一次成长机会!
- 📚领书:PostgreSQL 入门到精通.pdf
- 📙PostgreSQL 中文手册
- 📘PostgreSQL 技术专栏