监督学习和无监督学习
本文介绍机器学习的分类,监督学习和无监督学习
监督学习
监督学习(Supervised Learning)是机器学习的一个核心分支,大部分的机器学习任务都是由监督学习完成的。
它涉及到使用带有标签的训练数据来训练模型,以便模型能够学会从输入数据映射到输出数据的函数。在监督学习中,我们提供给算法的训练数据不仅包含输入特征,还包含相应的正确答案或目标输出,这些答案或目标被称为标签。
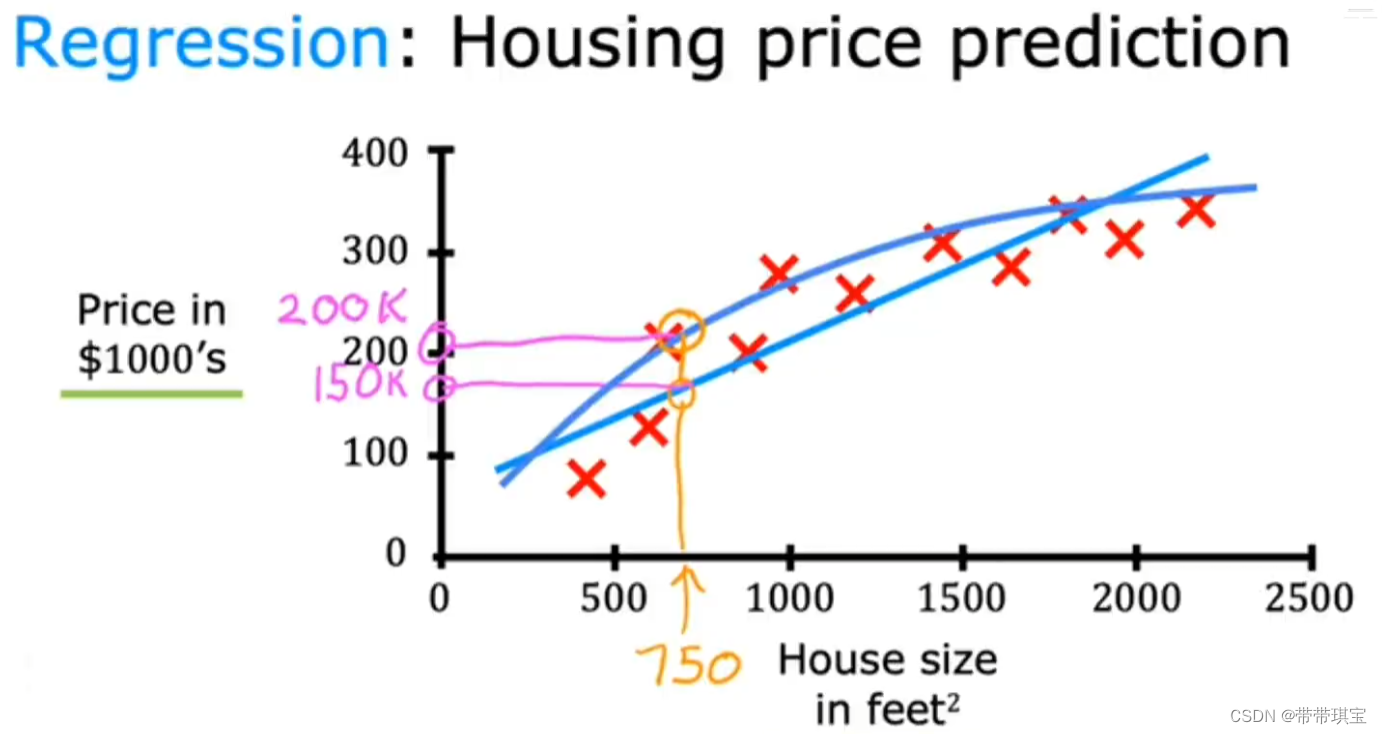
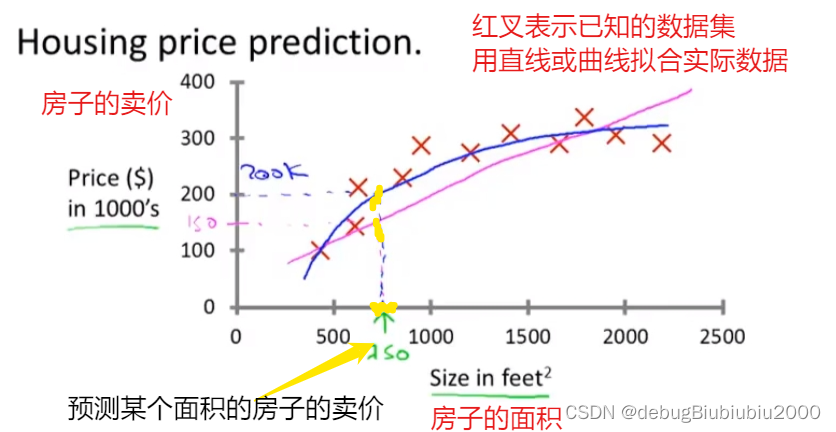
比如在一个很经典的例子房价预测中,我们提供一些列面积和对应房价的关系,然后让机器学习来拟合出一个对应的关系,如果是线性关系,结果为图中品红色的线,这时,如果你有一个170平方英尺的房间,根据结果进行预测得到的房价可能是150k$, 如果是非线性关系,得到图中蓝色的线,此时的拟合曲线好像更加接近于真实情况,这时你的170平方英尺的房间房价则为200k$

观察上述例子,不论哪条线,都是根据我们提供的输入信息(房子面积)和对应的标签(房价)进行拟合一个函数,然后再利用这个函数进行预测操作,我们通常将这种类型的机器学习称为回归。
再来看一个乳腺癌的例子,我们根据提供的肿瘤大小和是否为恶性肿瘤作为输入,但此时我们并不需要一个函数曲线,因为结果只有两类,我们需要的就是将这两类分开,如果有新的没有标记的数据,我们需要能将其分到最有可能正确的概率的类别中。再这个例子中,我们可以使用下面的表现形式,这时候只需在两个类型的中间划一条线就可以大致将两类数据分开。

在很多分类问题中,我们面对的不仅是一个特征,比如在医学中判断肿瘤是否为恶性,还需要考虑肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等,还有一些其他的特征。我们使用一个叫支持向量机的算法可以将多个特征都进行考虑,详细地算法我会在后续的博客中进行讲解。
总而言之,机器学习的基本思想是,我们数据集中的每个样本都有相应的“标签”。再根据这些样本作出预测,就像房子和肿瘤的例子中做的那样。 我们还介绍了回归问题,即通过回归来推出一个连续的输出,之后我们介绍了分类问题,其目标是推出一组离散的结果。
无监督学习
无监督学习(Unsupervised Learning)是机器学习的另一个重要分支,它处理的数据是没有标记的,即没有预定义的输出或目标变量。交给算法大量的数据,并让算法为我们从数据 中找出某种结构。
机器学习中,无监督学习最常被用到的场景是聚类。将数据点分组到不同的集群中,使得同一群集内的数据点彼此相似,而不同群集之间的数据点差异较大。
在下面的例子中,我们没有提供这些数据的所属类别,但我们系统通过机器学习,可以对数据进行类别的划分。