为什么要做Boost搜索引擎这个项目,为什么不是其他什么的搜索项目?
此项目的目的就是为了体现搜索功能,并不是为实现什么搜索,因为搜索需要资源,如要搜索的内容,设备需要存储搜素内容所需要的资源等,条件的限制,所以本项目就是通过对Boost库网页文件(*。html)文件进行搜索,该文件数据相对于计算机资源来说,恰到好处,项目可以跑起来,如果搜索内容过大,就不能正常运行。
Boost库文件下载
对下载下来的文件做处理,将网页文件中的,标题,内容,以及url网址,都提取出来。
读取文件:
既然是对网页文件做搜索,就需要程序中有网页文件。
所以就需要将网页文件从下载的目录中,读到程序中,也就是读到内存储存起来,方便后续的处理。
那如何对文件进行读取呢?
这里只记录C++17中使用 boost::filesystem实现遍历文件夹的方法。
通过使用boost::filesystem提供的迭代器和成员函数实现对目录文件的便利。
bool EnumFile(const std::string &src_path, std::vector<std::string> *files_list)
{
namespace fs = boost::filesystem;
fs::path root_path(src_path);
//判断路径是否存在,不存在,就没有必要再往后走了
if(!fs::exists(root_path)){
std::cerr << src_path << " not exists" << std::endl;
return false;
}
//定义一个空的迭代器,用来进行判断递归结束
fs::recursive_directory_iterator end;
for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++){
//判断文件是否是普通文件,html都是普通文件
if(!fs::is_regular_file(*iter)){
continue;
}
if(iter->path().extension() != ".html"){ //判断文件路径名的后缀是否符合要求
continue;
}
//std::cout << "debug: " << iter->path().string() << std::endl;
//当前的路径一定是一个合法的,以.html结束的普通网页文件
files_list->push_back(iter->path().string()); //将所有带路径的html保存在files_list,方便后续进行文本分析
}
return true;
}代码解析:首先用文件目录src_path实例化root_path对象,在判断该对象存不存在,不存在就没必要再向下执行,将迭代器用src_path目录进行实例化,再用迭代器去递归式的遍历该目录文件,如果不是普通文件或者不是网页文件,就不进行读取,反之,将网页文件读取到file_list文件链表中。
网页文件的解析:
将文件读取到file_list中(也就是内存中)之后,接着就需要对网页文件进行解析,解析里面的:标题,内容,url网址。
我们在解析网页文件时,需要了解网页文件的结构,你对结构不了解,就无法进行解析,解析出来也是错的。
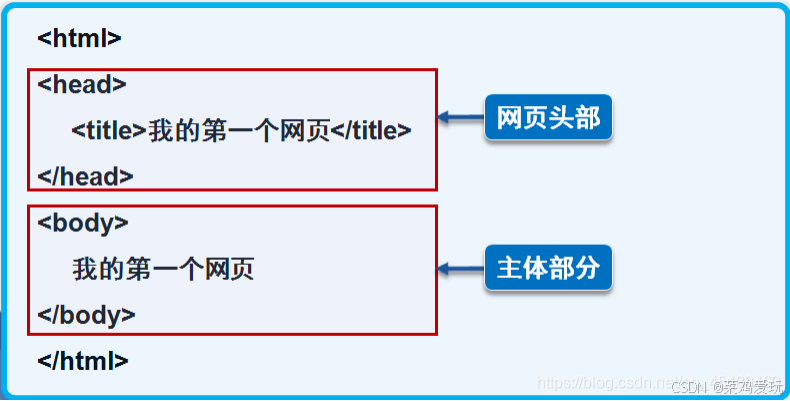
也就是<title>和</title>之间就是标题,<body>和</body>之间就是网页内容。
我们可以利用string中提供的find()找到<title>和</title>的位置,中间就时标题,再利用substr()将标题进行截取,再将标题返回。
static bool ParseTitle(const std::string &file, std::string *title)
{
std::size_t begin = file.find("<title>");
if(begin == std::string::npos){
return false;
}
std::size_t end = file.find("</title>");
if(end == std::string::npos){
return false;
}
begin += std::string("<title>").size();
if(begin > end){
return false;
}
*title = file.substr(begin, end - begin);
return true;
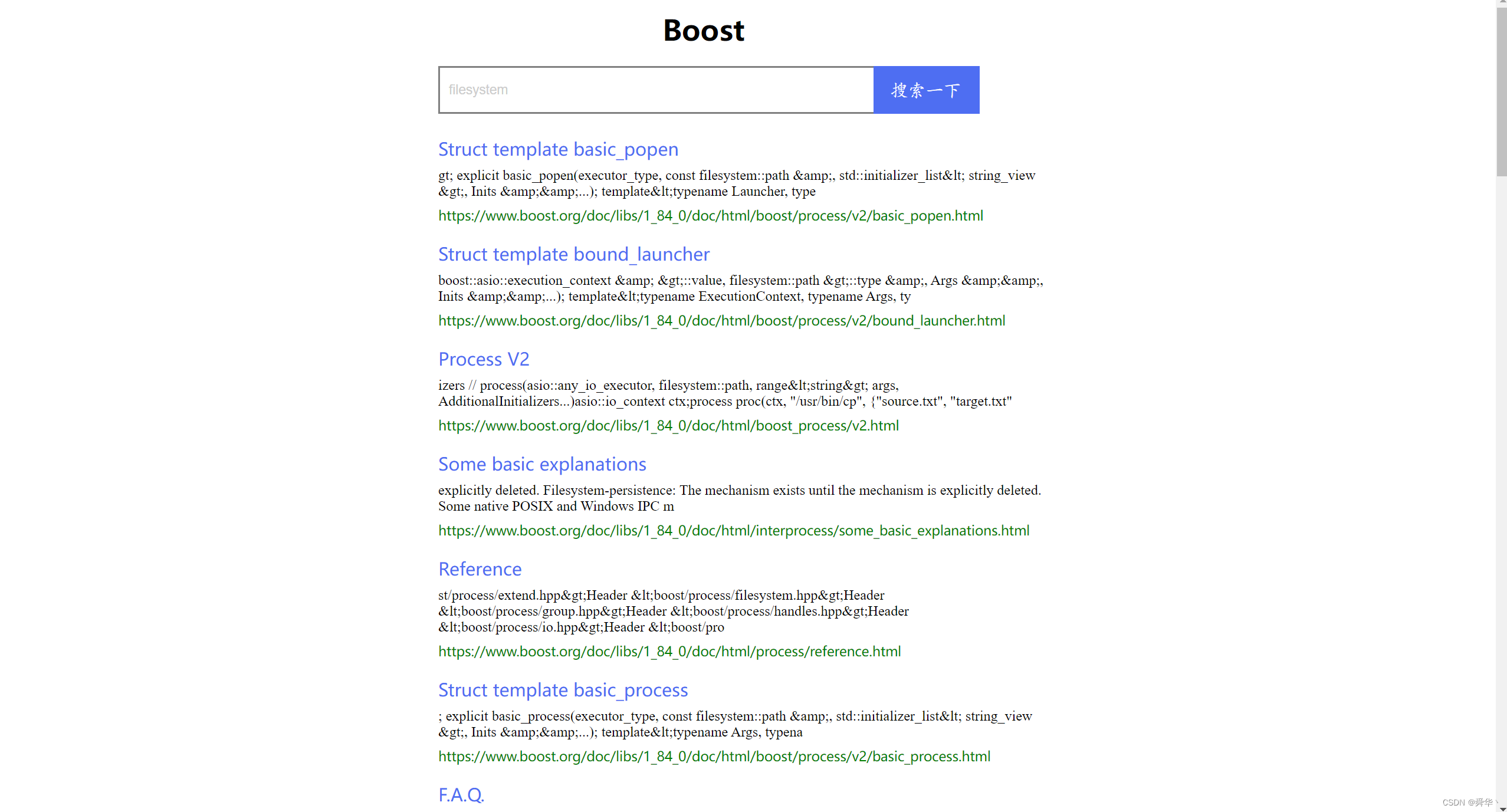
}然而,网页文件的内容,却不像,文件标题那样容易好找,下图是文件内容的示例图
通过上图可以看出,内容是在>和<之间,那我们只需要向上面那样找到>和<之间的内容,将他们返回即可。
我们需要利用了一个简易的状态机进行标记,利用枚举定义两个常量CONTENT和LABLE,分别表示内容和标签,遍历到‘>’时就标记CONTENT,遍历到'<'时,就标记为LABLE,然后利用switch语句进行判断和读取。
我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符,所以这里用' '空格进行分割。
static bool ParseContent(const std::string &file, std::string *content)
{
//去标签,基于一个简易的状态机
enum status{
LABLE,
CONTENT
};
enum status s = LABLE;
for( char c : file){
switch(s){
case LABLE:
if(c == '>') s = CONTENT;
break;
case CONTENT:
if(c == '<') s = LABLE;
else {
//我们不想保留原始文件中的\n,因为我们想用\n作为html解析之后文本的分隔符
if(c == '\n') c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}构建url
官方url样例
https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html我们下载下来的url样例
boost_1_78_0/doc/html/accumulators.html因为我们将下载下来的文件放到了"data/input"目录下,拷贝到我们项目中的样例就变成:data/input/accumulators.html
官方网址:url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
我们下载下来的文件就是官方网址下的一个目录:(所以将前面的"data/input"删除就是官网文档下的文件名)
url_tail = [data/input](删除) /accumulators.html -> url_tail = /accumulators.html
最终的网址:url = url_head + url_tail ; 相当于形成了⼀个官网链接。
static bool ParseUrl(const std::string &file_path, std::string *url)
{
std::string url_head = "https://www.boost.org/doc/libs/1_78_0/doc/html";
std::string url_tail = file_path.substr(src_path.size());
*url = url_head + url_tail;
return true;
}既然我们已经提取到了,标题,内容,和url网址,那我们就将提取到的这些内容利用结构体组织起来组织起来。
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{
for(const std::string &file : files_list){
//1. 读取文件,Read();
std::string result;
if(!ns_util::FileUtil::ReadFile(file, &result)){
continue;
}
DocInfo_t doc;
//2. 解析指定的文件,提取title
if(!ParseTitle(result, &doc.title)){
continue;
}
//3. 解析指定的文件,提取content,就是去标签
if(!ParseContent(result, &doc.content)){
continue;
}
//4. 解析指定的文件路径,构建url
if(!ParseUrl(file, &doc.url)){
continue;
}
//done,一定是完成了解析任务,当前文档的相关结果都保存在了doc里面
results->push_back(std::move(doc)); //bug:todo;细节,本质会发生拷贝,效率可能会比较低
//for debug
//ShowDoc(doc);
//break;
}
return true;
}里面运用了std::move()将左值变为右值,vector中提供了移动拷贝和移动赋值,可以很好的将右值拷贝到vector中,减少了一定的拷贝,提高了效率。这个是C++中容器结合右值引用之间的特性设计出来的。
如果不理解右值引用,那就不用了关了,只知道push_back()是将结构体插入vector中即可。
保存处理好的网页文件:
关于std::ofstream向文件中写入数据,这里不做介绍。请参考:
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
#define SEP '\3'
//按照二进制方式进行写入
std::ofstream out(output, std::ios::out | std::ios::binary);
if(!out.is_open()){
std::cerr << "open " << output << " failed!" << std::endl;
return false;
}
//就可以进行文件内容的写入了
for(auto &item : results){
std::string out_string;
out_string = item.title;
out_string += SEP;
out_string += item.content;
out_string += SEP;
out_string += item.url;
out_string += '\n';
out.write(out_string.c_str(), out_string.size());
}
out.close();
return true;
}以上就是网络文件处理模块的内容,我们将处理好的文件放到"data/raw_html/raw.txt"这个目录下,在接下来的模块中,会对处理好的文件再次操作。
建立索引:
什么是索引,索引该怎么建立?
什么是正排索引?怎么建立?
什么是倒排索引?怎么建立?