# python data_utils/pre_video/multi_fps_crop_sync.py
import cv2
import os
from tqdm import tqdm
import subprocess
# 加载人脸检测模型
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
def contains_face(frame):
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
return len(faces) > 0
def crop_center(frame, crop_width, crop_height):
height, width = frame.shape[:2]
start_x = width//2 - crop_width//2
start_y = height//2 - crop_height//2
return frame[start_y:start_y+crop_height, start_x:start_x+crop_width]
def extract_audio(input_path, audio_path):
subprocess.run(['ffmpeg', '-y', '-i', input_path, '-vn', '-acodec', 'copy', audio_path])
def merge_video_audio(video_path, audio_path, output_path):
# 使用ametadata滤镜将音频的时间戳与视频流的时间戳对齐
subprocess.run([
'ffmpeg', '-y', '-i', video_path, '-i', audio_path,
'-filter_complex', "[0:v][0:a]ametadata=mode=video:video_input=0:video_stream=0[a]",
'-map', '0:v', '-map', '[a]',
'-c:v', 'copy', '-c:a', 'aac',
output_path
])
def process_video(path, out_path, fps=25):
print(f'[INFO] ===== process video from {path} to {out_path} =====')
# 创建VideoCapture对象
cap = cv2.VideoCapture(path)
# 检查是否成功打开视频
if not cap.isOpened():
print("Error opening video file")
return
frame_rate = cap.get(cv2.CAP_PROP_FPS)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT)) # 获取视频的总帧数
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) # 获取视频的宽度
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) # 获取视频的高度
print("原视频帧率=", frame_rate, "fps")
print("原视频帧数=", total_frames)
print("原视频尺寸=", frame_width, "x", frame_height)
if frame_rate != fps:
cap.set(cv2.CAP_PROP_FPS, fps)
frame_rate = fps
# 创建VideoWriter对象
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(out_path, fourcc, fps, (512, 512))
frame_count = 0
# 创建一个tqdm进度条
pbar = tqdm(total=total_frames, ncols=70, unit='frame')
while cap.isOpened():
ret, frame = cap.read()
if ret:
if contains_face(frame) and frame_count % (frame_rate // fps) == 0:
frame = crop_center(frame, 512, 512)
out.write(frame)
frame_count += 1
pbar.update(1) # 更新进度条
else:
break
pbar.close() # 关闭进度条
cap.release()
out.release()
print(f'[INFO] ===== processed video =====')
# 打开处理后的视频,获取总帧数、帧率和视频尺寸
cap_out = cv2.VideoCapture(out_path)
total_frames_out = int(cap_out.get(cv2.CAP_PROP_FRAME_COUNT))
frame_rate_out = cap_out.get(cv2.CAP_PROP_FPS)
frame_width = int(cap_out.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap_out.get(cv2.CAP_PROP_FRAME_HEIGHT))
print(f'处理后的视频帧率: {frame_rate_out} fps')
print(f'处理后的视频帧数: {total_frames_out}')
print(f'处理后的视频尺寸: {frame_width}x{frame_height}')
cap_out.release()
def process_video_with_audio(input_path, output_path):
audio_path = output_path.replace('.mp4', '_audio.aac')
output_with_audio_path = output_path.replace('.mp4', '_with_audio.mp4')
# 分离音频
extract_audio(input_path, audio_path)
# 处理视频
process_video(input_path, output_path)
# 重新同步并合并音频和视频
merge_video_audio(output_path, audio_path, output_with_audio_path)
# 删除临时文件
os.remove(output_path)
os.remove(audio_path)
return output_with_audio_path
if __name__ == "__main__":
for i in tqdm(range(1, 75), desc="Processing videos"):
input_path = f"data/{i}/{i}.mp4"
output_path = f"data/{i}/{i}_fc.mp4"
if not os.path.isfile(input_path):
print(f"文件 {input_path} 不存在.")
continue
final_output_path = process_video_with_audio(input_path, output_path)
print(f"处理后的视频已保存至 {final_output_path}")
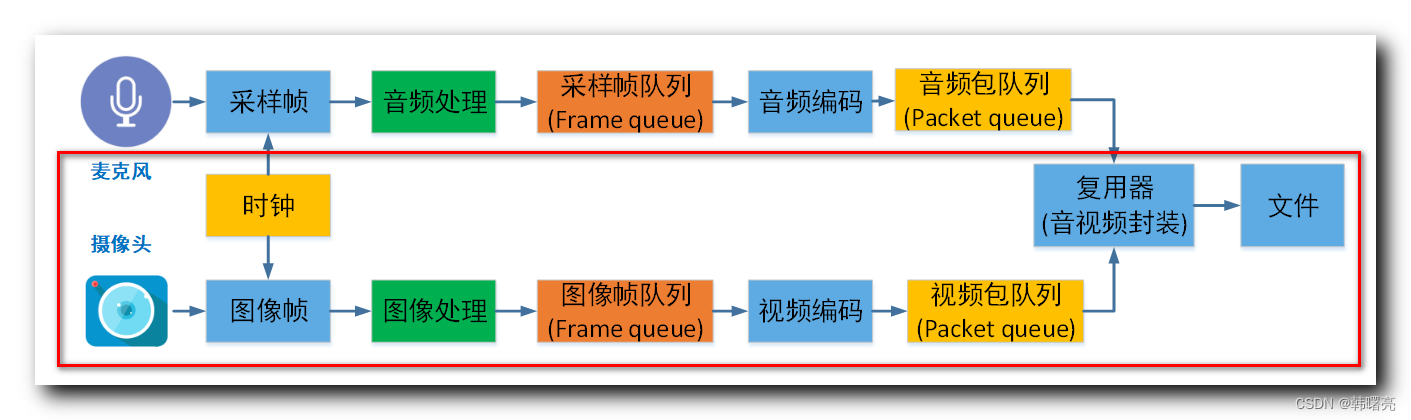
对于音视频不同步的问题,尤其是在使用ffmpeg的adelay滤镜时,如果只是简单地调整延迟,可能会因为视频和音频流的时间戳没有精确对齐而导致最终输出的视频中音画不同步。为了更精确地实现音视频同步,我们可以采取以下步骤:
提取视频流的时间戳:从原始视频中提取视频流的时间戳,这样我们就可以知道每个视频帧应该在什么时间点出现。
提取音频流的时间戳:同样地,从原始音频中提取音频流的时间戳,了解音频数据包的时间位置。
调整音频流的时间戳:根据需要提前或延后的时间,调整音频流的时间戳,使得它与视频流的时间戳对齐。
使用
ffmpeg重新封装:将调整过时间戳的音频流与视频流重新封装在一起,确保时间戳的对齐。
然而,直接在Python中操作音视频流的时间戳可能比较复杂,通常推荐的方式是在ffmpeg中使用[0:v][0:a]ametadata=mode=video:video_input=0:video_stream=0[a]这样的滤镜链,来确保音频流的时间戳与视频流的时间戳对齐。
以下是修改后的merge_video_audio函数,使用ffmpeg的ametadata滤镜来尝试更好地同步音视频:
def merge_video_audio(video_path, audio_path, output_path):
# 使用ametadata滤镜将音频的时间戳与视频流的时间戳对齐
subprocess.run([
'ffmpeg', '-y', '-i', video_path, '-i', audio_path,
'-filter_complex', "[0:v][0:a]ametadata=mode=video:video_input=0:video_stream=0[a]",
'-map', '0:v', '-map', '[a]',
'-c:v', 'copy', '-c:a', 'aac',
output_path
])
但请注意,ametadata滤镜并不总是能完美解决所有不同步问题,特别是当音频和视频的编码器或解码器有时间基(timebase)差异时。在这种情况下,你可能需要更深入地理解ffmpeg的时间基概念以及如何正确地设置它们,或者使用更复杂的滤镜链来确保时间戳的一致性。
另外,上述代码中并没有直接处理时间戳的调整,而是依赖于ffmpeg的滤镜来试图自动对齐音视频的时间戳。如果视频和音频流的时间基不同,或者存在其他复杂的时间偏移,你可能需要手动计算和调整时间戳,这通常涉及到更复杂的ffmpeg命令行技巧或使用专门的音视频处理库。