文本和布局的预训练由于其有效的模型架构和大规模未标记扫描/数字出生文档的优势,在各种视觉丰富的文档理解任务中被证明是有效的。我们提出了具有新的预训练任务的LayoutLMv2架构,以在单个多模态框架中对文本、布局和图像之间的交互进行建模。具体而言,LayoutLMv2采用双流多模态Transformer编码器,不仅使用了现有的掩模视觉语言建模任务,还使用了新的文本-图像对齐和文本-图像匹配任务,从而更好地捕捉了预训练阶段的跨模态交互。同时,在Transformer架构中集成了空间感知自关注机制,使模型能够充分理解不同文本块之间的相对位置关系。实验结果表明,LayoutLMv2在FUNSD(0.7895→0.8420)、CORD(0.9493→0.9601)、SROIE(0.9524→0.9781)、klester - nda(0.8340→0.8520)、RVL-CDIP(0.9443→0.9564)、DocVQA(0.7295→0.8672)等多种下游视觉丰富的文档理解任务上取得了比LayoutLM更好的结果。我们在https://aka.ms /layoutlmv2上公开了模型和代码。
可视化丰富的文档理解(VrDU,Visually-rich Document Understanding)旨在分析扫描/数字生成的业务文档(发票图像,PDF格式的表单等),其中结构化信息可以自动提取和组织用于许多业务应用程序。与传统的信息提取任务不同,VrDU任务不仅依赖于文本信息,还依赖于视觉和布局信息,这些信息对于视觉丰富的文档至关重要。不同类型的文档表明感兴趣的文本字段位于文档中的不同位置,这通常由每种类型的样式和格式以及文档内容决定。因此,为了准确地识别感兴趣的文本字段,不可避免地要利用视觉丰富文档的跨模态特性,在单个框架中,文本、视觉和布局信息应该被端到端地联合建模和学习。
VrDU的最新进展主要有两个方向。第一个方向通常建立在文本和视觉/布局/样式信息之间的浅层融合上(Yang et al., 2017;Liu et al., 2019;Sarkhel and Nandi, 2019;Yu et al., 2020;Majumder et al., 2020;Wei et al., 2020;Zhang等人,2020)。这些方法分别利用预训练的NLP和CV模型,并将来自多种模式的信息结合起来进行监督学习。虽然已经取得了良好的性能,但是一种文档类型的领域知识不能轻易地转移到另一种文档类型,因此一旦文档类型发生变化,这些模型通常需要重新训练。因此,不能充分利用一般文档布局(左右布局中的键值对、网格布局中的表等)中的局部不变性。为此,第二个方向依赖于来自不同领域的大量未标记文档的文本、视觉和布局信息之间的深度融合,其中预训练技术在以端到端方式学习跨模态交互方面发挥重要作用(Lockard et al., 2020;Xu et al., 2020)。通过这种方式,预训练的模型吸收了来自不同文档类型的跨模态知识,其中保留了这些布局和样式之间的局部不变性。此外,当需要将模型转移到具有不同文档格式的另一个领域时,仅需要少量标记的样本就足以对通用模型进行微调,以达到最先进的精度。因此,本文提出的模型遵循第二个方向,我们探索如何进一步改进VrDU任务的预训练策略。
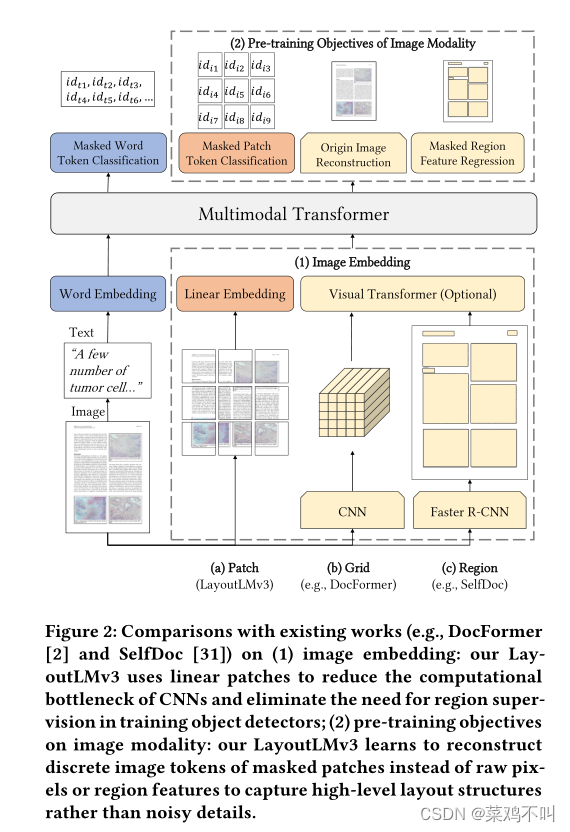
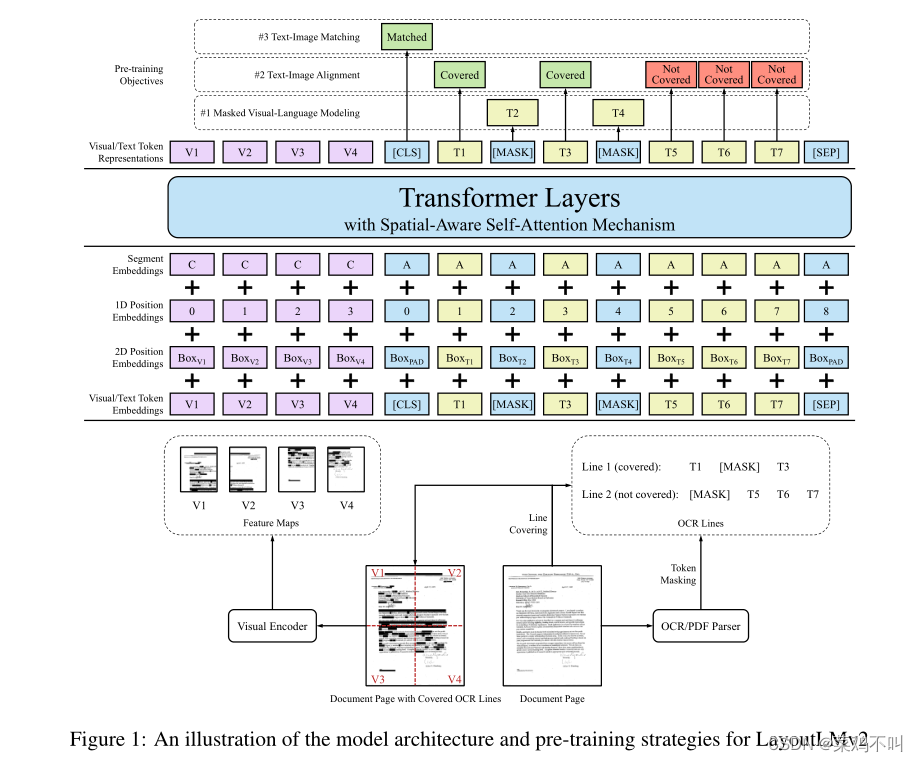
在本文中,我们提出了LayoutLM的改进版本(Xu et al., 2020),即LayoutLMv2。与传统的LayoutLM模型在微调阶段结合视觉嵌入不同,我们在LayoutLMv2中利用Transformer架构在预训练阶段整合视觉信息,学习视觉信息和文本信息之间的跨模态交互。此外,受一维相对位置表示的启发(Shaw et al., 2018;拉斐尔等人,2020;Bao等人,2020),我们提出了LayoutLMv2的空间感知自注意机制,该机制涉及令牌对的二维相对位置表示。与LayoutLM用来对页面布局建模的绝对二维位置嵌入不同,相对位置嵌入明确地为上下文空间建模提供了更广阔的视角。对于预训练策略,除了屏蔽视觉语言建模之外,我们还为LayoutLMv2使用了两个新的训练目标。首先是本文提出的文本-图像对齐策略,该策略将文本行和相应的图像区域对齐。第二种是在之前的视觉语言预训练模型中流行的文本-图像匹配策略(Tan and Bansal, 2019;Lu et al., 2019;Su et al., 2020;Chen et al., 2020;Sun et al., 2019),其中模型学习文档图像和文本内容是否相关。
我们选择了六个公开可用的基准数据集作为下游任务,以评估预训练的LayoutLMv2模型的性能,它们是用于表单理解的fundd数据集(Jaume等人,2019),用于收据理解的CORD数据集(Park等人,2019)和SROIE数据集(Huang等人,2019),用于复杂布局的长文档理解的Kleister-NDA数据集(Grali ' nski等人,2020),用于RVL-CDIP数据集(Harley等人,2019)。2015)用于文档图像分类,以及DocVQA数据集(Mathew et al., 2021)用于文档图像的视觉问答。实验结果表明,LayoutLMv2模型显著优于强基线(包括普通LayoutLM),并在所有这些任务中获得了最新的结果。本文的贡献总结如下:•我们提出了一个多模态Transformer模型来集成文档文本、布局和可视化信息
2方法
在本节中,我们将介绍LayoutLMv2的模型架构和多模态预训练任务,如图1所示。
2.1模型架构
2.1模型架构我们构建了一个多模态的Transformer架构作为LayoutLMv2的主干,它以文本、视觉和布局信息作为输入,建立深度的跨模态交互。我们还在模型体系结构中引入了空间感知自关注机制,以便更好地对文档布局进行建模。模型的详细描述如下。
Text Embedding 按照通常的做法,我们使用WordPiece (Wu et al., 2016)对OCR文本序列进行标记,并将每个标记分配给特定的片段si∈{[A], [B]}。然后,我们在序列的开头添加[CLS],在每个文本片段的末尾添加[SEP]。额外的[PAD]标记被附加到末尾,以便最终序列的长度正好是最大序列长度L.最终文本嵌入是三个嵌入的总和。令牌(token)嵌入表示令牌本身,一维位置嵌入表示令牌索引,段嵌入用于区分不同的文本段。形式上,我们有第i次(0≤i < L)文本嵌入。Token embedding rep-resents the token itself, 1D positional embedding represents the token index, and segment embed-ding is used to distinguish different text segments.Formally, we have the i-th (0 ≤ i < L) text em-bedding
![]()
视觉嵌入 虽然我们需要的所有信息都包含在页面图像中,但该模型很难在整个页面的单个信息丰富的表示中捕获详细特征。因此,我们利用基于cnn的视觉编码器的输出特征映射,它将页面图像转换为固定长度的序列。我们使用ResNeXt-FPN (Xie et al., 2017;Lin et al., 2017)架构作为视觉编码器的主干,其参数可以通过反向传播更新。给定文档页面图像I,将其大小调整为224 × 224,然后输入视觉主干。然后将输出的特征图平均池化为固定大小,宽度为W,高度为h。然后将其平展为可视化嵌入序列lengthW×H。该序列被命名为VisTokEmb(I)。然后对每个视觉标记嵌入应用线性投影层,使其维度与文本嵌入统一。由于基于cnn的视觉主干无法捕获位置信息,我们还在这些视觉标记嵌入中添加了一维位置嵌入。一维位置嵌入与文本嵌入层共享。对于片段嵌入,我们将所有的视觉标记附加到视觉片段上[C]。第i个(0≤i < WH)视觉嵌入可以表示为

布局嵌入 布局嵌入层用于从OCR结果中嵌入以轴线对齐的令牌边界框表示的空间布局信息,其中识别框的宽度和高度以及角坐标。遵循LayoutLM,我们将所有坐标归一化并离散为[0,1000]范围内的整数,并使用两个嵌入层分别嵌入x轴特征和y轴特征。给定第i个(0≤i < WH L)文本/视觉标记boxi = (xmin, xmax, ymin, ymax, width, height)的归一化边界框,布局嵌入层将6个边界框特征连接起来,构建一个标记级二维位置嵌入,即布局嵌入

注意,cnn进行了局部变换,因此视觉标记嵌入可以一个接一个地映射回图像区域,既没有重叠也没有遗漏。在计算边界框时,可视标记可以视为均匀划分的网格。空边界框boxPAD =(0,0,0,0,0,0)附加到特殊令牌[CLS], [SEP]和[PAD]。
具有空间感知自注意机制的多模态编码器, vWH−1}和文本嵌入{0,…, tL−1}进行统一序列,通过添加布局嵌入融合空间信息,得到第i(0≤i < WH L)层输入Multi-modal Encoder with Spatial-Aware Self-Attention Mechanism The encoder concate-nates visual embeddings {v0, ..., vWH−1} and text embeddings {t0, ..., tL−1} to a unified sequence and fuses spatial information by adding the layout embeddings to get the i-th (0 ≤ i < WH + L) first layer input
就是文本嵌入和视觉嵌入加上布局嵌入

按照Transformer的架构,我们用一堆多头自关注层和一个前馈网络来构建我们的多模态编码器。然而,原始的自注意机制只能隐式地捕获输入标记与绝对位置提示之间的关系。为了有效地对文档布局中的局部不变性进行建模,需要显式地插入相对位置信息。因此,我们将空间意识自注意机制引入自注意层。为简单起见,下面的描述是针对单个自关注层中的单个头部,头部的大小为隐藏,投影矩阵为WQ, WK, WV。原始的自注意机制通过投影两个向量并计算注意分数来捕获查询xi和键xj之间的相关性

考虑到位置的大范围,我们将语义相对位置和空间相对位置建模为偏置项,以避免添加过多的参数。类似的实践已被证明在纯文本Transformer架构上是有效的(rafael等人,2020;Bao et al., 2020)。设b(1D), b(2Dx), b(2Dy)分别表示可学习的1D和2D相对位置偏差。这种偏差在注意头之间是不同的,但在所有编码器层中是共享的。假设(xi, yi)锚定第i个边界框的左上角坐标,我们得到空间感知注意力得分

最后,将输出向量表示为所有投影值向量相对于标准化的空间感知注意力得分的加权平均值