人脸表情识别项目是一个结合了计算机视觉和深度学习技术的高级应用,主要用于分析和理解人类面部表情所传达的情感状态。这样的系统可以用于多种场景,比如情绪分析、用户交互、市场调研、医疗诊断以及人机接口等领域。
一个典型的人脸表情识别项目可以分为以下几个步骤:
数据收集: 首先需要一个包含各种表情的大型数据集。这些数据集通常包含成千上万张标注了不同表情类别的面部图像。一些常用的公开数据集有FER2013、JAFFE和CK+等。
数据预处理: 对收集到的数据进行清洗、标准化和增强。这可能包括调整图像大小、灰度化、归一化像素值、数据扩增等步骤。
人脸检测: 在实时视频流或静态图像中检测出人脸的位置。这通常使用如SSD(Single Shot MultiBox Detector)、MTCNN(Multi-task Cascaded Convolutional Networks)或其他人脸检测算法来完成。
特征提取: 从检测到的人脸区域中提取有助于表情识别的特征。早期的方法可能使用手工设计的特征,如LBP(Local Binary Patterns)或HOG(Histogram of Oriented Gradients),但现代方法更倾向于使用深度学习模型直接从原始图像中学习特征。
模型训练: 使用深度学习框架(如TensorFlow或PyTorch)训练一个神经网络模型。模型架构可能包括卷积神经网络(CNNs),如VGG、ResNet或MobileNet等。训练过程中,模型会学习到如何将输入的面部图像映射到特定的表情类别。
模型评估: 在独立的测试集上评估模型的性能,确保它能够准确地识别未见过的面部表情。
部署和优化: 将训练好的模型部署到实际应用中,可能是在移动设备、服务器或嵌入式系统上。此外,可能还需要进行性能优化,以确保实时性或低功耗需求。
UI/UX设计: 如果项目包含用户界面,则需要设计直观的UI来展示识别结果,使用户能够轻松理解和使用系统。
持续监控和更新: 部署后,系统应持续监测其性能,必要时进行重新训练或参数调优,以适应新的数据或环境变化。
以上步骤构成了一个完整的人脸表情识别项目的生命周期,从概念验证到产品化,每一阶段都需要细致的技术考虑和工程实践。
本项目简介:
简介
使用卷积神经网络构建整个系统,在尝试了Gabor、LBP等传统人脸特征提取方式基础上,深度模型效果显著。在FER2013、JAFFE和CK+三个表情识别数据集上进行模型评估。
环境部署
基于Python3和Keras2(TensorFlow后端),具体依赖安装如下(推荐使用conda虚拟环境)。
git clone https://github.com/luanshiyinyang/FacialExpressionRecognition.git
cd FacialExpressionRecognition
conda create -n FER python=3.6 -y
conda activate FER
conda install cudatoolkit=10.1 -y
conda install cudnn=7.6.5 -y
pip install -r requirements.txt数据准备
数据集和预训练模型均已经上传到百度网盘。下载后将model.zip移动到根目录下的models文件夹下并解压得到一个*.h5的模型参数文件,将data.zip移动到根目录下的dataset文件夹下并解压得到包含多个数据集压缩文件,均解压即可得到包含图像的数据集。
项目说明
传统方法
- 数据预处理
- 图片降噪
- 人脸检测(HAAR分类器检测(opencv))
- 特征工程
- 人脸特征提取
- LBP
- Gabor
- 人脸特征提取
- 分类器
- SVM
深度方法
- 人脸检测
- HAAR分类器
- MTCNN(效果更好)
- 卷积神经网络
- 用于特征提取+分类
网络设计
使用经典的卷积神经网络,模型的构建主要参考2018年CVPR几篇论文以及谷歌的Going Deeper设计如下网络结构,输入层后加入(1,1)卷积层增加非线性表示且模型层次较浅,参数较少(大量参数集中在全连接层)。

模型训练
主要在FER2013、JAFFE、CK+上进行训练,JAFFE给出的是半身图因此做了人脸检测。最后在FER2013上Pub Test和Pri Test均达到67%左右准确率(该数据集爬虫采集存在标签错误、水印、动画图片等问题),JAFFE和CK+5折交叉验证均达到99%左右准确率(这两个数据集为实验室采集,较为准确标准)。
执行下面的命令将在指定的数据集(fer2013或jaffe或ck+)上按照指定的batch_size训练指定的轮次。训练会生成对应的可视化训练过程,下图为在三个数据集上训练过程的共同绘图。
python src/train.py --dataset fer2013 --epochs 300 --batch_size 32
模型应用
与传统方法相比,卷积神经网络表现更好,使用该模型构建识别系统,提供GUI界面和摄像头实时检测(摄像必须保证补光足够)。预测时对一张图片进行水平翻转、偏转15度、平移等增广得到多个概率分布,将这些概率分布加权求和得到最后的概率分布,此时概率最大的作为标签(也就是使用了推理数据增强)。
GUI界面
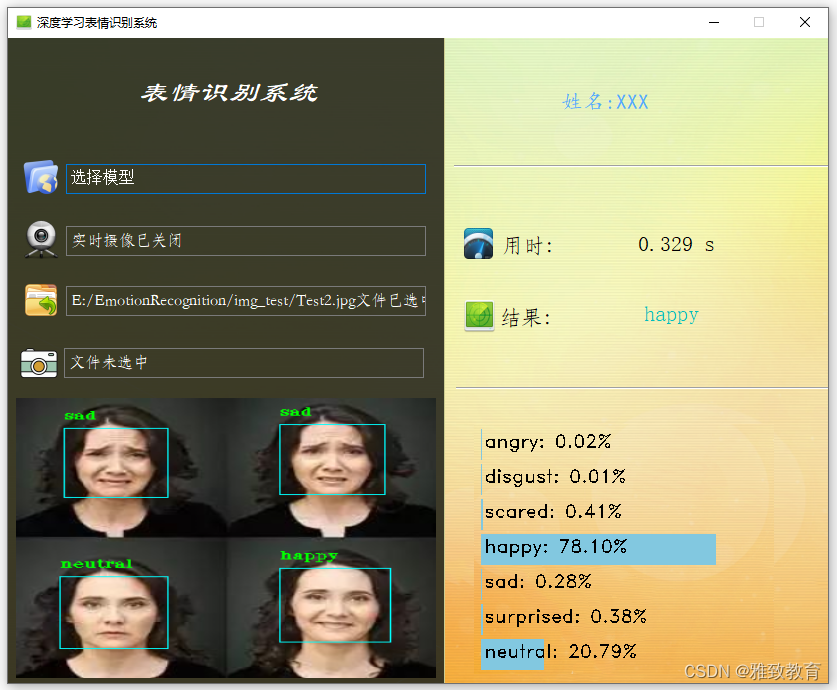
注意,GUI界面预测只显示最可能是人脸的那个脸表情,但是对所有检测到的人脸都会框定预测结果并在图片上标记,标记后的图片在output目录下。
执行下面的命令即可打开GUI程序,该程序依赖PyQT设计,在一个测试图片(来源于网络)上进行测试效果如下图。
python src/gui.py 
上图的GUI反馈的同时,会对图片上每个人脸进行检测并表情识别,处理后如下图。

实时检测
实时检测基于Opencv进行设计,旨在用摄像头对实时视频流进行预测,同时考虑到有些人的反馈,当没有摄像头想通过视频进行测试则修改命令行参数即可。
使用下面的命令会打开摄像头进行实时检测(ESC键退出),若要指定视频进行进行检测,则使用下面的第二个命令。
python src/recognition_camera.py
python src/recognition_camera.py --source 1 --video_path 视频绝对路径或者相对于该项目的根目录的相对路径下图是动态演示的在某个视频的识别结果。






























![[spring] Spring MVC - security(下)](https://img-blog.csdnimg.cn/direct/b434e2bc3c554e179c23e3e1ffbe3bd3.png)







