1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着人工智能技术的快速发展,深度学习在计算机视觉领域取得了巨大的突破。表情识别是计算机视觉领域的一个重要研究方向,它可以通过分析人脸表情来推断人的情感状态。表情识别在许多领域具有广泛的应用,如人机交互、情感计算、智能监控等。然而,传统的表情识别方法存在着一些问题,如特征提取困难、分类准确率低等。因此,基于深度学习的表情识别人脸打分系统的研究具有重要的理论和实际意义。
首先,基于深度学习的表情识别人脸打分系统可以提高表情识别的准确率。传统的表情识别方法主要依赖于手工设计的特征提取器,这些特征提取器通常需要大量的人工经验和专业知识。而深度学习可以通过学习大量的数据来自动学习特征,从而避免了手工设计特征的困难。深度学习模型如卷积神经网络(CNN)和循环神经网络(RNN)等已经在图像和语音识别等领域取得了很好的效果,因此将深度学习应用于表情识别可以提高识别的准确率。
其次,基于深度学习的表情识别人脸打分系统可以提高实时性。传统的表情识别方法通常需要较长的处理时间,这在实时应用中是不可接受的。而深度学习模型可以通过并行计算来加速处理速度,从而实现实时的表情识别。此外,深度学习模型还可以通过优化算法和硬件加速等技术来进一步提高处理速度,满足实时应用的需求。
此外,基于深度学习的表情识别人脸打分系统还可以提供更多的应用场景。传统的表情识别方法通常只能识别一些基本的表情,如喜、怒、哀、乐等。而深度学习模型可以学习更复杂的表情特征,从而实现更细粒度的表情识别。例如,可以识别微笑的程度、愤怒的强度等。这些细粒度的表情识别可以在情感计算、心理研究等领域提供更多的应用场景。
综上所述,基于深度学习的表情识别人脸打分系统具有重要的研究背景和意义。它可以提高表情识别的准确率和实时性,拓展表情识别的应用场景,为人机交互、情感计算、智能监控等领域提供更多的技术支持。因此,深入研究基于深度学习的表情识别人脸打分系统具有重要的理论和实际价值。
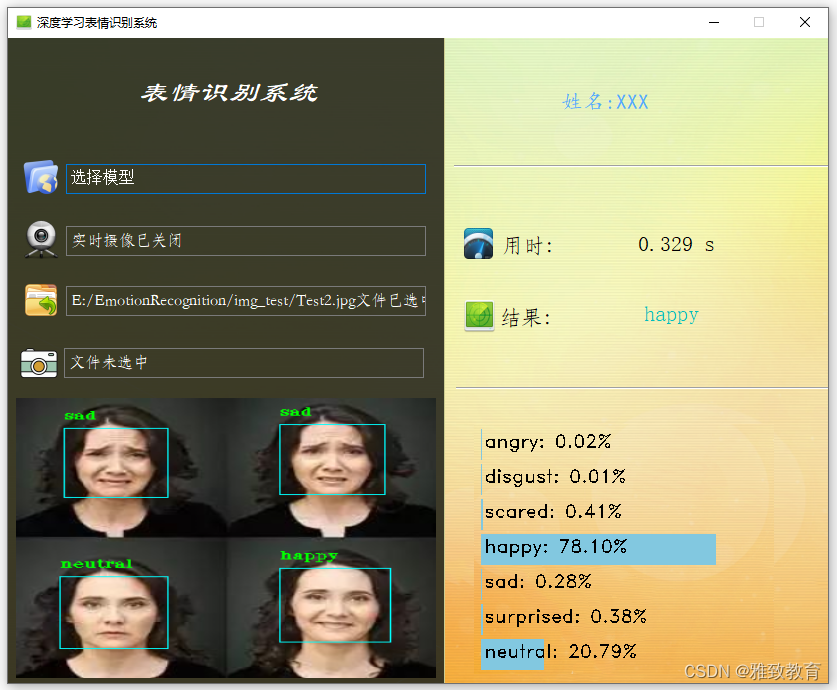
2.图片演示



3.视频演示
基于基于深度学习的表情识别人脸打分系统_哔哩哔哩_bilibili
4.数据预处理
人脸检测和对齐
在对图片中的人脸进行识别时,如果图片中人脸的方向各不一样且相差很大,会影响人脸识别的准确率。正如我们在训练机器学习模型之前通过对一组特征向量进行零中心化或缩放到单位范数来标准化一样,我们往往会先对齐数据集中的人脸。当给定一帧图像,我们首先要找到图像中人脸的位置,这就是一个目标检测问题,我们使用了dlib包中自带的人脸检测模型。在得到脸部位置后,我们需要检测出面部标志,也就是眼睛、眉毛、鼻子、下巴的位置。dlib中也有训练好的面部标志检测模型: dlib.shape_predictor。成功检测到输入图片中的人脸后,再使用FaceAligner类中的人脸对齐算法( align)来对齐检测到的人脸,然后再将对齐的人脸可视化。如图所示。

数据增强
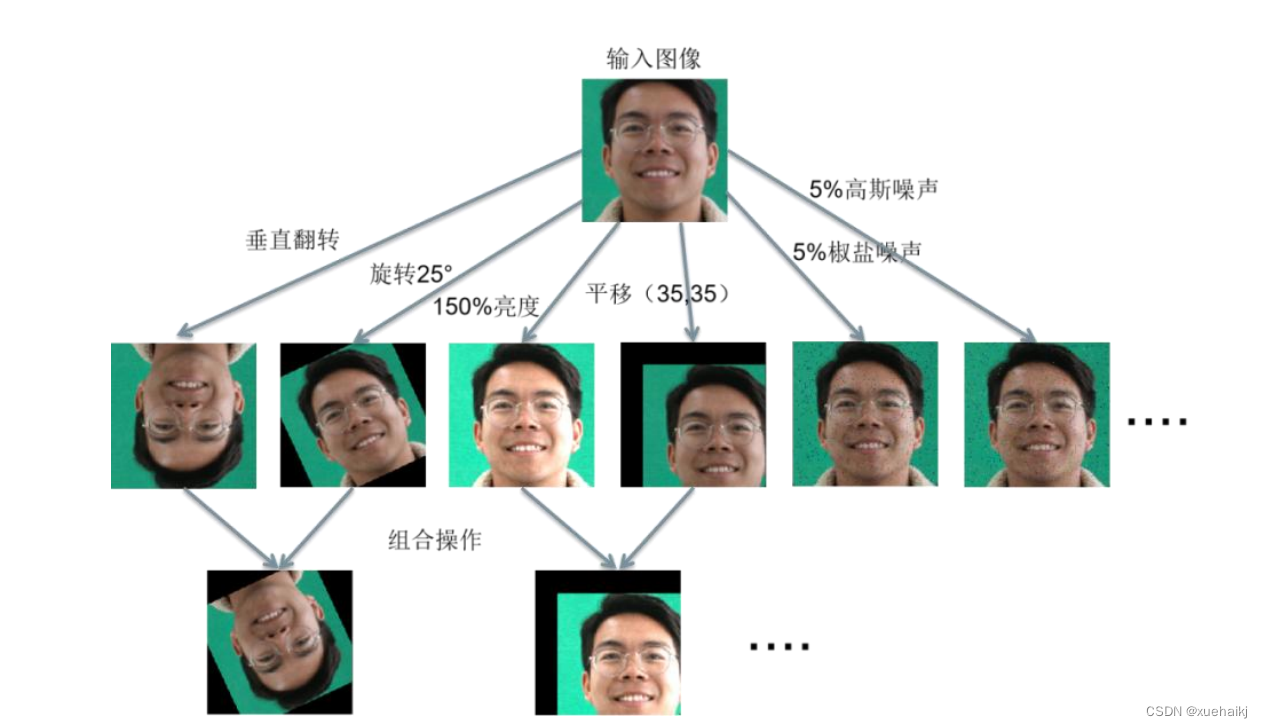
深度神经网络需要足够的训练数据来确保模型能够学习到足够的参数,才能获得好的性能表现。然而,在各种任务中,大多数公开数据集中用于训练的图像往往是不足的,包括FER任务。目前最先进的神经网络采用了成千上万张图片数据,然而我们收集的抑郁症患者的表情数据集只有几百张图像,不足以训练先进的FER模型。因此,数据增强(Data Augmentation)是深度FER的重要一步,由于我们的数据集比较小(smaller dataset),因此我们需要对其进行离线增强(offlineaugmentation)。我们不需要去寻找新奇的图片添加到我们的数据集中,只需要通过对原始数据进行随机扰动和变换,例如裁剪(Crop八、翻转(Flip)、旋转(Rotation)、移位(Translation)、缩放(Scale)、对比度(Contrast)和颜色变换(Color) ;向原始数据中添加高斯噪声(Gaussian Noise)[6l被用来扩大数据量。如图5.2所示,将多个操作进行组合可以生成更多不常见的训练样本,随机改变训练样本可以降低模型对某些属性的依赖,阻止神经网络学习不相关的特征。同时,数据量会变成增强因子(Data Augmentation Factor)乘以原数据集的数目,比如要翻转所有图片,数据集相当于乘以2。在本研究中,我们依次采用垂直翻转-→>旋转25度->亮度提升50%->平移至(x=35,y=35)->5%椒盐噪声>5%高斯噪声的组合操作对抑郁症表情数据集进行数据增强,将样本量扩增到26倍,其中抑郁组与非抑郁组分别包含37,632张图像。通过数据增强可以使神经网络对平移、翻转、移位的人脸图像更加健壮,从而让模型更具泛化能力。
标准化与归一化
当使用深度学习进行图像分类或者人脸检测时,如果原始数据在不同维度的特征的尺度不一致,需要标准化步骤对数据进行标准化或归一化处理。两者都是进行数据变换的方式,目的是将原来的数据转换到某个范围。标准化是将数据变换为均值为o,标准差为1的分布,可以不是正态的。归一化是将数据变化到某个固定区间中,通常是[0,1],而图像像素是[0,255]。标准化处理的公式如下:
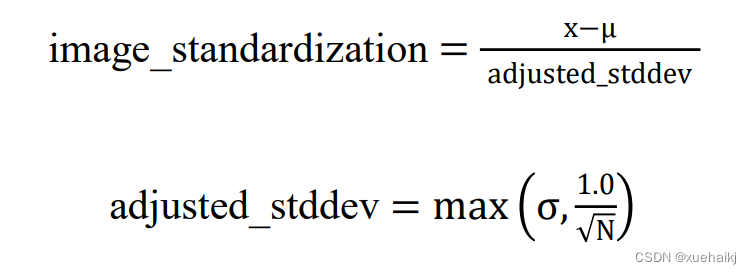
其中u是图像的均值,x是像素矩阵,o是标准方差,N是像素数量。我们使用tensorflow中内置的API函数对图像进行标准化处理,如图5.3所示。
最大最小值归一化的公式如下:
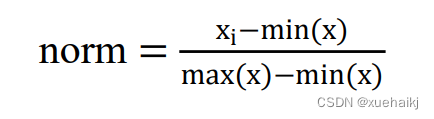
其中x是像素点i的值,min(x),max(x)是图像的最大像素值与最小像素值。我们基于OpenCV实现了人脸图像的归一化操作,如图5.4和图5.5所示。图像归一化之后与原图像完全一致,这表明归一化操作并不会改变图像本身的信息,而是将像素值变换到[0,1]之间,有利于神经网络的训练。
5.核心代码讲解
5.1 CK.py
class CK(data.Dataset):
def __init__(self, split='Training', fold = 1, transform=None):
self.transform = transform
self.split = split # training set or test set
self.fold = fold # the k-fold cross validation
self.data = h5py.File('./data/CK_data.h5', 'r', driver='core')
number = len(self.data['data_label']) #981
sum_number = [0,135,312,387,594,678,927,981] # the sum of class number
test_number = [12,18,9,21,9,24,6] # the number of each class
test_index = []
train_index = []
for j in range(len(test_number)):
for k in range(test_number[j]):
if self.fold != 10: #the last fold start from the last element
test_index.append(sum_number[j]+(self.fold-1)*test_number[j]+k)
else:
test_index.append(sum_number[j+1]-1-k)
for i in range(number):
if i not in test_index:
train_index.append(i)
print(len(train_index),len(test_index))
# now load the picked numpy arrays
if self.split == 'Training':
self.train_data = []
self.train_labels = []
for ind in range(len(train_index)):
self.train_data.append(self.data['data_pixel'][train_index[ind]])
self.train_labels.append(self.data['data_label'][train_index[ind]])
elif self.split == 'Testing':
self.test_data = []
self.test_labels = []
for ind in range(len(test_index)):
self.test_data.append(self.data['data_pixel'][test_index[ind]])
self.test_labels.append(self.data['data_label'][test_index[ind]])
def __getitem__(self, index):
if self.split == 'Training':
img, target = self.train_data[index], self.train_labels[index]
elif self.split == 'Testing':
img, target = self.test_data[index], self.test_labels[index]
img = img[:, :, np.newaxis]
img = np.concatenate((img, img, img), axis=2)
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
if self.split == 'Training':
return len(self.train_data)
elif self.split == 'Testing':
return len(self.test_data)
该程序文件名为CK.py,是一个用于处理CK+数据集的类。该类继承自torch.utils.data.Dataset,用于创建数据集。
该类的构造函数接受三个参数:split、fold和transform。split参数用于指定数据集的类型,可以是"Training"或"Testing";fold参数用于指定k-fold交叉验证的折数;transform参数用于对图像进行预处理的函数。
在构造函数中,首先打开名为CK_data.h5的HDF5文件,该文件包含了CK+数据集的图像像素和标签信息。然后根据split参数选择加载训练集或测试集的数据。
加载训练集数据时,根据fold参数确定训练集的索引。根据数据集的类别和折数,计算出测试集的索引。然后根据索引从HDF5文件中加载对应的图像像素和标签。
类的__getitem__方法用于获取指定索引的图像和标签。根据split参数选择加载训练集或测试集的数据,并进行相应的预处理。最后返回预处理后的图像和标签。
类的__len__方法用于返回训练集或测试集的数据长度。
该类主要用于加载CK+数据集的图像和标签,并提供了获取图像和标签的方法。可以用于创建训练集和测试集的数据加载器。
5.2 config.py
class EmotionDetection:
def __init__(self):
self.path_model = 'emotion_detection/Modelos/model_dropout.hdf5'
self.w, self.h = 48, 48
self.rgb = False
self.labels = ['angry','disgust','fear','happy','neutral','sad','surprise']
class FaceRecognition:
def __init__(self):
self.path_images = "images_db"
这个程序文件名为config.py,它包含了两个部分的配置信息。
第一部分是关于情绪检测的模型的配置信息:
- 模型文件的路径为’emotion_detection/Modelos/model_dropout.hdf5’。
- 模型要求输入的图像大小为48x48像素,且为灰度图像。
- 模型的输出标签包括了’angry’,‘disgust’,‘fear’,‘happy’,‘neutral’,‘sad’,'surprise’这些情绪类别。
第二部分是关于人脸识别的配置信息:
- 图像文件夹的路径为"images_db"。
5.3 deep_face.py
class FaceAnalyzer:
def __init__(self, image_path):
self.image_path = image_path
def analyze_face(self):
demography = DeepFace.analyze(self.image_path, actions=['age', 'gender', 'race', 'emotion'])
return demography
def get_age(self):
demography = self.analyze_face()
return demography["age"]
def get_gender(self):
demography = self.analyze_face()
return demography["gender"]
def get_emotion(self):
demography = self.analyze_face()
return demography["dominant_emotion"]
def get_race(self):
demography = self.analyze_face()
return demography["dominant_race"]
这个程序文件名为deep_face.py,它使用了deepface库来进行人脸分析。代码中使用DeepFace.analyze函数来分析名为"juan.jpg"的图片中的人脸,分析的内容包括年龄、性别、种族和情绪。程序输出了分析结果中的年龄、性别、主要情绪和主要种族。
5.4 Face_info.py
class FaceInfo:
def __init__(self, input_type, path_im=None):
self.input_type = input_type
self.path_im = path_im
def process_image(self):
frame = cv2.imread(self.path_im)
out = f_Face_info.get_face_info(frame)
res_img = f_Face_info.bounding_box(out, frame)
cv2.imshow('Face info', res_img)
cv2.waitKey(0)
def process_webcam(self):
cv2.namedWindow("Face info")
cam = cv2.VideoCapture(0)
while True:
star_time = time.time()
ret, frame = cam.read()
frame = imutils.resize(frame, width=720)
out = f_Face_info.get_face_info(frame)
res_img = f_Face_info.bounding_box(out, frame)
end_time = time.time() - star_time
FPS = 1/end_time
cv2.putText(res_img, f"FPS: {
round(FPS,3)}", (10,50), cv2.FONT_HERSHEY_COMPLEX, 1, (0,0,255), 2)
cv2.imshow('Face info', res_img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
这个程序文件名为Face_info.py,主要功能是通过调用f_Face_info模块来获取人脸信息并在图像上绘制边界框。程序使用了OpenCV、time、imutils和argparse等库。
程序首先导入了f_Face_info模块以及其他所需的库。然后使用argparse库创建了一个命令行参数解析器,用于指定输入类型和图像路径。
接下来,程序通过cv2.imread函数读取了一张图像,并调用f_Face_info模块的get_face_info函数获取人脸信息。然后,使用f_Face_info模块的bounding_box函数在图像上绘制了边界框,并将结果显示在窗口中。
如果条件判断语句if 0为真,则进入webcam模式。程序创建了一个名为"Face info"的窗口,并通过cv2.VideoCapture函数打开摄像头。然后,程序循环读取摄像头的帧,使用imutils库调整帧的大小为720像素宽度。
在每一帧中,程序调用f_Face_info模块的get_face_info函数获取人脸信息,并使用bounding_box函数在图像上绘制边界框。同时,程序计算帧率并在图像上显示。最后,程序通过cv2.imshow函数显示图像,并通过按下键盘上的"q"键退出循环。
总之,这个程序文件主要用于获取人脸信息并在图像上绘制边界框,可以通过命令行参数指定输入类型和图像路径,支持图像和摄像头两种模式。
5.5 fer.py
class FER2013(data.Dataset):
def __init__(self, split='Training', transform=None):
self.transform = transform
self.split = split # training set or test set
self.data = h5py.File('./data/data.h5', 'r', driver='core')
# now load the picked numpy arrays
if self.split == 'Training':
self.train_data = self.data['Training_pixel']
self.train_labels = self.data['Training_label']
self.train_data = np.asarray(self.train_data)
self.train_data = self.train_data.reshape((28709, 48, 48))
elif self.split == 'PublicTest':
self.PublicTest_data = self.data['PublicTest_pixel']
self.PublicTest_labels = self.data['PublicTest_label']
self.PublicTest_data = np.asarray(self.PublicTest_data)
self.PublicTest_data = self.PublicTest_data.reshape((3589, 48, 48))
else:
self.PrivateTest_data = self.data['PrivateTest_pixel']
self.PrivateTest_labels = self.data['PrivateTest_label']
self.PrivateTest_data = np.asarray(self.PrivateTest_data)
self.PrivateTest_data = self.PrivateTest_data.reshape((3589, 48, 48))
def __getitem__(self, index):
if self.split == 'Training':
img, target = self.train_data[index], self.train_labels[index]
elif self.split == 'PublicTest':
img, target = self.PublicTest_data[index], self.PublicTest_labels[index]
else:
img, target = self.PrivateTest_data[index], self.PrivateTest_labels[index]
img = img[:, :, np.newaxis]
img = np.concatenate((img, img, img), axis=2)
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self):
if self.split == 'Training':
return len(self.train_data)
elif self.split == 'PublicTest':
return len(self.PublicTest_data)
else:
return len(self.PrivateTest_data)
这个程序文件是用来处理FER2013数据集的。它定义了一个名为FER2013的类,继承自torch.utils.data.Dataset类,用于创建FER2013数据集。
FER2013数据集包含了人脸表情识别的图像数据,分为训练集、测试集和验证集三部分。这个程序文件根据参数split的值来确定使用哪个数据集。
在初始化方法中,程序会加载数据集文件data.h5,并根据split的值将数据集分为训练集、测试集和验证集三部分。每个数据集都包含图像数据和对应的标签。
在getitem方法中,根据split的值选择对应的数据集,然后返回图像数据和对应的标签。在返回之前,程序会对图像数据进行一些处理,如将图像数据的维度进行调整,将图像数据转换为PIL图像,并应用transform函数对图像进行变换。
在len方法中,根据split的值返回对应数据集的长度。
这个程序文件主要用于加载FER2013数据集,并提供了获取图像数据和标签的方法,方便后续的数据处理和模型训练。
5.6 f_Face_info.py
class FaceRecognition:
def __init__(self):
self.rec_face = self.rec()
def rec(self):
# 实例化人脸识别器
return f_main.rec()
def get_face_info(self, im):
# 人脸信息获取
boxes_face = face_recognition.face_locations(im)
out = []
if len(boxes_face) != 0:
for box_face in boxes_face:
box_face_fc = box_face
x0, y1, x1, y0 = box_face
box_face = np.array([y0, x0, y1, x1])
face_features = {
"name": [],
"bbx_frontal_face": box_face
}
face_image = im[x0:x1, y0:y1]
face_features["name"] = self.rec_face.recognize_face2(im, [box_face_fc])[0]
out.append(face_features)
else:
face_features = {
"name": [],
"bbx_frontal_face": []
}
out.append(face_features)
return out
class SocialTraitPrediction:
def __init__(self, attributes, trait_scores):
self.attributes = attributes
self.trait_scores = trait_scores
self.scaler = MinMaxScaler()
def preprocess_data(self):
# 数据预处理,归一化属性值
self.attributes = self.scaler.fit_transform(self.attributes)
def train_model(self):
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
self.attributes, self.trait_scores, test_size=0.2, random_state=42
)
# 创建神经网络模型
model = MLPRegressor(hidden_layer_sizes=(100,), activation='logistic', max_iter=1000)
# 模型
model.fit(X_train, y_train)
# 在测试集上评估模型
score = model.score(X_test, y_test)
def predict_traits(self, new_attributes):
# 对新的属性值进行预测
new_attributes = self.scaler.transform(new_attributes)
predicted_scores = model.predict(new_attributes)
return predicted_scores
class FaceFeatures:
def __init__(self):
self.predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def get_physical_features(self, landmarks):
eye_size = min(abs(landmarks.part(36).x - landmarks.part(39).x) / 300, 1)
nose_length = min(abs(landmarks.part(27).y - landmarks.part(30).y) / 300, 1)
mouth_width = min(abs(landmarks.part(48).x - landmarks.part(54).x) / 300, 1)
return {
"eye_size": eye_size, "nose_length": nose_length, "mouth_width": mouth_width}
def get_face_scores(self, physical_features):
approachability = physical_features["eye_size"]
youthful_attractiveness = physical_features["nose_length"]
dominance = physical_features["mouth_width"]
return {
"Approachability": approachability, "Youthful-Attractiveness": youthful_attractiveness, "Dominance": dominance}
class FaceBoundingBox:
def __init__(self):
self.predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
def bounding_box(self, out, img):
for data_face in out:
box = data_face["bbx_frontal_face"]
if len(box) == 0:
continue
else:
x0, y0, x1, y1 = box
img = cv2.rectangle(img, (x0, y0), (x1, y1), (0, 0, 255), 5)
thickness = 3
fontSize = 1
step = 30
try:
cv2.putText(img, "name: " + data_face["name"], (x0, y0 - step * 4), cv2.FONT_HERSHEY_SIMPLEX, fontSize, (0, 255, 0), thickness)
except:
pass
dlib_rect = dlib.rectangle(x0, y0, x1, y1)
landmarks = self.predictor(img, dlib_rect)
for n in range(0, 68):
x = landmarks.part(n).x
y = landmarks.part(n).y
cv2.circle(img, (x, y), 1, (255, 0, 0), -1)
physical_features = FaceFeatures().get_physical_features(landmarks)
face_scores = FaceFeatures().get_face_scores(physical_features)
cv2.putText(img, "Approachability: " + str(face_scores['Approachability']), (x0, y0 - step * 3), cv2.FONT_HERSHEY_SIMPLEX, fontSize, (0, 255, 0), thickness)
cv2.putText(img, "Youthful-Attractiveness: " + str(face_scores['Youthful-Attractiveness']), (x0, y0 - step * 2), cv2.FONT_HERSHEY_SIMPLEX, fontSize, (0, 255, 0), thickness)
cv2.putText(img, "Dominance: " + str(face_scores['Dominance']), (x0, y0 - step), cv2.FONT_HERSHEY_SIMPLEX, fontSize, (0, 255, 0), thickness)
with open('./result.txt', 'a', encoding='utf-8') as f:
f.write("Name: " + data_face["name"] + '\n')
with open('./result.txt', 'a', encoding='utf-8') as f:
f.write("Approachability: " + str(face_scores['Approachability']) + '\n')
with open('./result.txt', 'a', encoding='utf-8') as f:
f.write("Youthful-Attractiveness: " + str(face_scores['Youthful-Attractiveness']) + '\n')
with open('./result.txt', 'a', encoding='utf-8') as f:
f.write("Dominance: " + str(face_scores['Dominance']) + '\n')
return img
这个程序文件名为f_Face_info.py,它包含了以下几个部分:
导入所需的库:cv2、numpy、face_recognition、my_face_recognition、dlib。
实例化人脸识别器rec_face。
加载人脸关键点检测器predictor。
定义了一个函数get_face_info,用于获取人脸信息。该函数使用face_recognition库检测人脸位置,并对每个人脸进行以下操作:
- 提取人脸图像。
- 使用rec_face.recognize_face2函数识别人脸。
- 将人脸信息保存到字典face_features中。
- 将face_features添加到列表out中。
- 返回out。
定义了一个类SocialTraitPrediction,用于预测社交特征。该类包含以下方法:
- init:初始化属性和特征得分。
- preprocess_data:对属性值进行归一化处理。
- train_model:将数据分为训练集和测试集,并创建神经网络模型进行训练和评估。
- predict_traits:对新的属性值进行预测。
定义了一个函数get_physical_features,用于获取人脸的物理特征。该函数使用dlib的关键点检测器预测关键点,并计算眼睛大小、鼻子长度和嘴巴宽度。
定义了一个函数get_face_scores,用于计算人脸因子得分。该函数根据物理特征计算可亲近性、年轻吸引力和支配性得分。
定义了一个函数bounding_box,用于在图像上绘制人脸框和关键点,并计算人脸因子得分。该函数接受一个包含人脸信息的列表out和一个图像img作为输入,对每个人脸进行以下操作:
- 绘制人脸框和关键点。
- 获取物理特征和人脸因子得分。
- 在图像上添加人脸因子得分。
- 将人脸信息和得分写入result.txt文件。
- 返回绘制了人脸框和关键点的图像。
总体来说,这个程序文件实现了人脸检测、人脸识别、人脸关键点检测和人脸因子得分计算等功能。
6.系统整体结构
整体功能和构架概括:
该项目是一个基于深度学习的表情识别人脸打分系统。它包含了多个程序文件,每个文件负责不同的功能模块。主要功能包括数据预处理、模型训练、模型测试、结果可视化和用户界面等。
下表整理了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| CK.py | 加载CK+数据集的图像和标签 |
| config.py | 配置情绪检测模型和人脸识别的信息 |
| deep_face.py | 使用deepface库进行人脸分析 |
| Face_info.py | 获取人脸信息并绘制边界框 |
| fer.py | 加载FER2013数据集的图像和标签 |
| f_Face_info.py | 获取人脸信息并计算人脸因子得分 |
| k_fold_train.py | 使用k-fold交叉验证训练模型 |
| mainpro_CK+.py | CK+数据集的主程序 |
| mainpro_FER.py | FER2013数据集的主程序 |
| old.py | 旧版本的程序,功能未知 |
| plot_CK+_confusion_matrix.py | 绘制CK+数据集的混淆矩阵 |
| plot_fer2013_confusion_matrix.py | 绘制FER2013数据集的混淆矩阵 |
| preprocess_CK+.py | 预处理CK+数据集 |
| preprocess_fer2013.py | 预处理FER2013数据集 |
| test.py | 测试模型的准确率和损失 |
| train.py | 训练模型 |
| ui.py | 用户界面程序 |
| utils.py | 包含一些工具函数 |
| visualize.py | 可视化结果的函数 |
| models\resnet.py | ResNet模型的定义 |
| models\vgg.py | VGG模型的定义 |
| models_init_.py | 模型初始化文件 |
| my_face_recognition\f_face_recognition.py | 人脸识别模块 |
| my_face_recognition\f_main.py | 人脸识别的主程序 |
| my_face_recognition\f_storage.py | 人脸识别的存储模块 |
| transforms\functional.py | 数据转换的函数 |
| transforms\transforms.py | 数据转换的类 |
| transforms_init_.py | 数据转换的初始化文件 |
7.ResNet进行表情分类
为了验证我们的猜想,我们使用未经预训练的ResNet18残差网络在抑郁症表情数据集和其它公开的面部表情数据集(CK+、FER2013、FERPLUS)中测试了面部表情分类性能,以多分类准确率为评估标准。
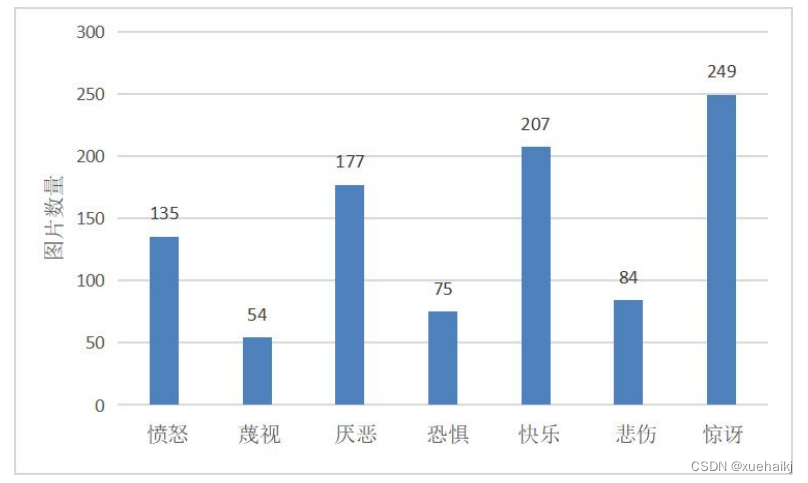
Extended CohnKanade(CK+)面部表情数据集是用于评估FER模型分类性能的实验室采集的数据库[⒆]。由于CK+面部表情数据集不提供指定的训练集和测试集,最常见的是数据获取方法是提取每个视频序列中具有峰值形成的最后1~3帧和第1帧。在本研究中,我们共从中抽取了981张面部表情图像,其在七种情绪类别上的数量分布如图所示。
FER2013面部表情数据集是一个通过Google图片搜索API自动收集的大型无约束数据库,共有35,886张面部表情图片组成,其中包含28,709张训练(Training )图像、3,589张验证(PublicTest)图像和3,589张测试(PrivateTest)图像[50。所有图像都是48×48像素的灰度图像。在本研究中,我们使用了FER2013面部表情数据集的28,709张训练图像,其在七种情绪类别上的数量分布如图5.12所示。

8.模型的训练
我们将以上四种面部表情数据集分别进行训练集和测试集的随机划分,接着挑选其中任意80%的数据用作训练集,剩余20%的数据用作测试集。然后使用random模块中的shuffle()函数打乱训练集和测试集中的样本次序,依次写入train.txt和 test.txt文本文件。我们从pytorch框架的torchvision包的子包models直接导入ResNet18网络架构,接下来对输入图像进行处理:对于训练集,将图片大小调整为224×224像素,然后对图片进行随机的水平翻转及垂直翻转,再将图片转为tensor格式,最后进行图像标准化操作;对于测试集,同样将图片大小调整为224x224像素,然后将图片转为tensor格式,最后进行图像标准化操作。将训练图像送入ResNet18网络进行训练,并在测试集验证了分类效果。
结果显示,当我们以未经预训练的ResNet18 网络作为baseline验证分类性能时,在CK+面部表情数据集得到了78.8%的准确率(七分类),在FER2013面部表情数据集得到了65.1%的准确率(七分类),在FERPLUS面部表情数据集得到了77.5%的准确率(八分类),而在我们的抑郁症面部表情数据集仅得到了15.1%的准确率(七分类),这与我们的数据集有关。根据第4章对抑郁组和非抑郁组面部情绪表达的统计分析可知,抑郁症患者在通过面部表情表达真实情感时具有更高的消极倾向和更低的积极偏向,这会导致抑郁症表情数据集中出现标签不一致或标签不正确的问题。这种不确定性问题阻碍了神经网络在面部表情分类的进展,特别是对于基于数据驱动的深度学习的FER而言。
一般来说,当使用不确定性数据训练FER模型时可能会导致模型对不确定样本过度拟合,同时学习到的面部特征可能是有害的[52]。因此,为了处理标签的不确定性问题,有研究利用一小组干净的数据在训练过程中评估标签的质量[53-55];或估计噪声分布l56;或训练特征提取器[S7]。Veit等人使用一个多任务网络,该网络联合学习清理不确定的注释,然后对图像进行了分类[58]。有的方法不使用干净的数据集,但它们在噪声样本上设定了额外的约束或分布[59;例如随机翻转标签的特定损失[60l;通过将潜在正确标签连接到噪声标签来使用softmax层对噪声进行建模的方法[6]。基于上述研究,我们希望通过抑制抑郁症表情数据集中标签的不确定性来识别抑郁症患者的真实情感。
自注意力重要性加权模块
将一批(batch)受试者的面部表情图像通过卷积神经网络提取人脸特征,然后自注意力重要性加权模块为每个输入特征学习一个重要性权重。预计某些样本可能具有较高的重要性权重,而不确定的样本可能具有较低的重要性权重,如图5.14所示。令F=[x1,X2,… XN]∈RDNN表示N张图像的人脸特征,每个人脸特征的重要性权重在(0,1)中任意。人脸特征经过全连接层和sigmoid激活函数就可以得到对应的权重,可以表示为:
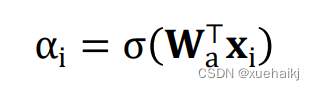
其中α,是第i个样本的重要性权重,W是用于注意力的全连接层的参数,o是sigmoid 函数。通过对网络的全连接层加入注意力因子q,来确定样本的准确性,数值越高表现越好,通过重新加权,网络将注意力集中到更有效的样本上,从而提高训练准确率。此外,因为预测的是一个概率分布,该模块从文献[62]引入了Logit-Weighted Cross-Entropy损失(WCE-Loss)作为评判标准,公式如下:
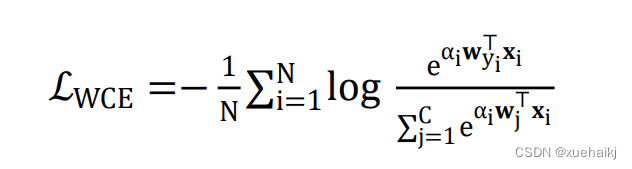
其中w{是第j个分类器,文献[63]已证明LwcE与α呈正相关。

9.系统整合

10.参考文献
[1]李凌江.中国抑郁障碍防治指南(第二版)解读[J].中华医学信息导报.2016,(19).21.DOI:10.3969/cma.j.issn.1000-8039.2016.19.026 .
[2]黄悦勤.中国精神卫生调查概况[J].心理与健康.2018,(10).14-16.
[3]成都中科云集信息技术有限公司.一种基于特征金字塔网络的双向LSTM微表情识别抑郁症方法 :CN201910747125.3[P].2019-08-14.
[4]Andrew J. Arnold,Piotr Winkielman.Smile (but only deliberately) though your heart is aching: Loneliness is associated with impaired spontaneous smile mimicry[J].Social Neuroscience.2021,16(1).26-38.DOI:10.1080/17470919.2020.1809516 .
[5]Zwick, Julia C.,Wolkenstein, Larissa.Facial emotion recognition, theory of mind and the role of facial mimicry in depression[J].Journal of affective disorders.2017.21090-99.DOI:10.1016/j.jad.2016.12.022 .
[6]Diah Anggraeni Pitaloka,Ajeng Wulandari,T. Basaruddin,等.Enhancing CNN with Preprocessing Stage in Automatic Emotion Recognition[J].Procedia Computer Science.2017.116523-529.DOI:10.1016/j.procs.2017.10.038 .
[7]JiaxingLi,DexiangZhang,JingjingZhang,等.Facial Expression Recognition with Faster R-CNN[J].Procedia Computer Science.2017.107135-140.DOI:10.1016/j.procs.2017.03.069 .
[8]Sun, Bo,Li, Liandong,Zhou, Guoyan,等.Facial expression recognition in the wild based on multimodal texture features[J].Journal of electronic imaging.2016,25(6).61407.1.DOI:10.1117/1.JEI.25.6.061407 .
[9]Tracy, Air,Michael J, Weightman,Bernhard T, Baune.Symptom severity of depressive symptoms impacts on social cognition performance in current but not remitted major depressive disorder.[J].Frontiers in psychology.2015.61118.
[10]Evgeny A. Smirnov,Denis M. Timoshenko,Serge N. Andrianov.Comparison of Regularization Methods for ImageNet Classification with Deep Convolutional Neural Networks[J].AASRI Procedia.2014,6(1).89-94.