人工智能如何重塑目标检测技术
一、引言
1.1 背景介绍
1.1.1 自动驾驶技术的发展历程
自动驾驶技术,也被称为无人驾驶技术,是指通过计算机系统、传感器和人工智能算法,自动控制车辆进行驾驶的一种技术。自20世纪80年代以来,自动驾驶技术经历了从实验室研究到实际应用的飞速发展。
早期的自动驾驶研究主要集中在使用基础的传感器和控制算法来实现车辆的自动化。例如,1980年代的卡内基梅隆大学开发的Navlab系列是早期的自动驾驶原型车,通过使用雷达和摄像头实现了基本的自动驾驶功能。然而,这些早期系统由于计算能力和传感器技术的限制,表现并不理想。
进入21世纪后,随着计算机处理能力的提升、传感器技术的进步以及人工智能算法的突破,自动驾驶技术得到了迅猛的发展。Google在2009年启动了自动驾驶汽车项目,其原型车在公开道路上行驶了数百万英里,展示了自动驾驶技术的巨大潜力。随后,特斯拉、Uber、Waymo等科技公司和传统汽车制造商如奔驰、宝马、奥迪等也纷纷加入自动驾驶技术的研发竞赛,推动了行业的发展。
近年来,自动驾驶技术已逐渐从实验室走向市场,部分高级驾驶辅助系统(ADAS)已在实际车辆中得到应用,如自动泊车、车道保持、自动紧急制动等功能。然而,真正实现全自动驾驶(Level 5)仍然面临许多技术和法律挑战。

1.1.2 人工智能在自动驾驶中的重要性
在自动驾驶技术的发展过程中,人工智能(AI)扮演了至关重要的角色。传统的控制算法和规则基系统在应对复杂和动态的驾驶环境时,往往力不从心,而人工智能则能够通过深度学习等技术,从大量的驾驶数据中学习和提取出有效的驾驶策略和决策规则。
人工智能在自动驾驶中的应用主要体现在以下几个方面:
感知:自动驾驶车辆需要通过各种传感器(如摄像头、激光雷达、毫米波雷达等)来感知周围环境。AI技术通过对传感器数据的处理和分析,能够实现对环境中各类物体的检测和识别,如车辆、行人、交通标志、道路标线等。
决策:在复杂的驾驶环境中,自动驾驶车辆需要根据感知到的信息,进行实时的决策。例如,在车道变换、避让行人、通过交叉路口等场景中,AI算法能够模拟人类驾驶员的决策过程,做出合理的驾驶策略。
控制:基于决策层的输出,AI算法还需要控制车辆的执行机构,如方向盘、油门、刹车等,保证车辆按照预定的路径和速度行驶。
总的来说,人工智能技术在自动驾驶中的应用,不仅提高了车辆的感知能力和决策水平,还显著提升了自动驾驶系统的安全性和可靠性。
1.2 目标检测的定义和重要性
1.2.1 什么是目标检测
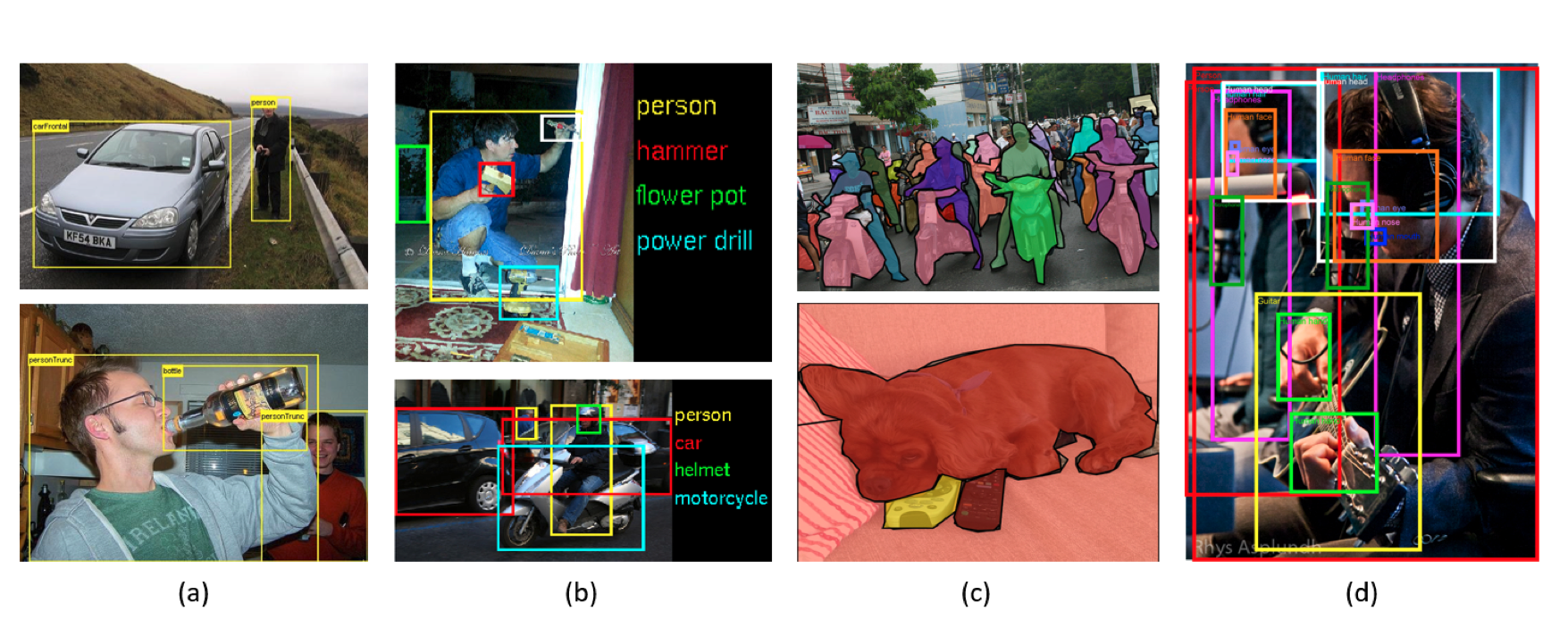
目标检测(Object Detection)是计算机视觉中的一个重要任务,旨在从图像或视频中识别和定位特定目标物体。目标检测不仅需要识别图像中的目标类别,还需要确定目标在图像中的具体位置(通常以边界框的形式表示)。
目标检测技术的核心在于同时解决两个问题:一是目标的分类,即判断图像中的物体属于哪一类;二是目标的定位,即确定目标在图像中的具体位置。具体来说,目标检测算法会输出目标的类别标签以及目标在图像中的边界框坐标。
随着深度学习技术的发展,目标检测算法也取得了显著进展。传统的目标检测方法主要依赖于手工特征和经典机器学习算法,而现代目标检测方法则更多地依赖于卷积神经网络(CNN)等深度学习技术。例如,R-CNN系列、YOLO(You Only Look Once)系列、SSD(Single Shot MultiBox Detector)等深度学习模型在目标检测任务中取得了优异的表现。
1.2.2 目标检测在自动驾驶中的应用和重要性
在自动驾驶系统中,目标检测技术起着至关重要的作用。自动驾驶车辆需要实时感知周围环境,以确保行驶安全和驾驶决策的准确性。目标检测技术的应用场景主要包括以下几个方面:
行人检测:自动驾驶车辆需要准确检测和识别道路上的行人,以避免碰撞事故。行人检测技术能够帮助车辆识别行人位置,并在必要时采取避让措施,保障行人安全。
车辆检测:自动驾驶车辆需要检测和识别周围的其他车辆,以实现车道保持、车道变换、超车等操作。车辆检测技术能够帮助自动驾驶系统判断前方车辆的类型、位置和运动状态,从而做出合理的驾驶决策。
交通标志和信号灯识别:交通标志和信号灯是驾驶过程中重要的参考信息。自动驾驶车辆需要通过目标检测技术识别道路上的交通标志和信号灯,从而遵守交通规则。例如,在红绿灯路口,车辆需要根据信号灯的状态决定是否停车或通过。
障碍物检测:自动驾驶车辆需要实时检测道路上的各种障碍物,如石块、树枝、施工路障等。障碍物检测技术能够帮助车辆在复杂的道路环境中安全行驶,避免碰撞和损坏。
车道线检测:车道线检测是自动驾驶中实现车道保持和导航的重要技术。通过检测道路上的车道线,自动驾驶车辆能够保持在正确的车道上行驶,并在需要时进行车道变换。
总的来说,目标检测技术在自动驾驶中的应用,显著提升了车辆的环境感知能力和行驶安全性。随着目标检测算法的不断进步,自动驾驶技术也将变得更加可靠和高效,为实现真正的无人驾驶奠定坚实的基础。
二、目标检测技术概述
2.1 传统目标检测方法
2.1.1 基于滑动窗口和特征提取的检测方法
传统目标检测方法主要依赖于手工设计的特征提取器和机器学习算法,其基本思路是通过滑动窗口技术在图像中移动固定大小的窗口,提取每个窗口内的特征并使用分类器进行目标检测。常见的特征包括Haar特征、HOG(Histogram of Oriented Gradients)特征等。
代码示例:
# Example of Haar feature extraction
import cv2
# Load a sample image
image = cv2.imread('sample_image.jpg', cv2.IMREAD_GRAYSCALE)
# Create a Haar cascade classifier (used in Viola-Jones method)
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# Detect faces in the image
faces = face_cascade.detectMultiScale(image, scaleFactor=1.1, minNeighbors=5)
# Draw rectangles around detected faces
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# Display the image with detected faces
cv2.imshow('Detected Faces', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
传统方法的局限性主要体现在以下几个方面:
- 计算复杂度高:由于需要对每个窗口进行特征提取和分类,因此计算量较大,导致速度慢,不适合实时应用。
- 对尺度和视角敏感:传统方法在处理尺度变化和视角变化较大的情况下效果较差。
- 依赖手工设计特征:特征的设计需要依赖领域专家的经验和先验知识,难以泛化到复杂场景。
2.2 现代目标检测方法
2.2.1 基于深度学习的目标检测方法
随着深度学习技术的发展,特别是卷积神经网络(CNN)的广泛应用,现代目标检测方法取得了显著进展。主流的现代目标检测方法包括R-CNN系列、YOLO系列和SSD等,它们在精度和速度上都有较大的提升。
表格示例:
| 方法 | 主要特点 | 应用场景 |
|---|---|---|
| R-CNN系列 | 包括R-CNN、Fast R-CNN、Faster R-CNN等,通过候选区域提取和CNN特征提取实现目标检测。 | 静态场景、精确检测要求高的应用场景 |
| YOLO系列 | You Only Look Once,通过将目标检测任务转化为回归问题,实现实时目标检测。 | 实时应用、动态场景 |
| SSD | Single Shot MultiBox Detector,结合多尺度特征图实现快速目标检测。 | 复杂场景、快速响应要求高的应用场景 |
现代目标检测方法的优势主要体现在以下几个方面:
- 端到端学习:现代方法通过端到端的深度学习模型,直接从原始数据中学习特征和决策规则,避免了手工设计特征的繁琐过程。
- 高精度和高效率:深度学习模型能够学习到更加丰富和抽象的特征表示,从而提升了目标检测的精度,并且通过优化算法和硬件加速,实现了在实时性要求较高的场景中的高效率表现。
- 泛化能力强:深度学习模型在大规模数据训练的情况下,具有较强的泛化能力,能够适应复杂的环境和场景变化。
总的来说,现代目标检测方法在自动驾驶技术中的应用,极大地推动了自动驾驶系统的发展和普及,为实现安全、高效和可靠的自动驾驶提供了重要的技术支持。
三、深度学习在目标检测中的应用
3.1 卷积神经网络(CNN)
3.1.1 CNN的基本原理
卷积神经网络(Convolutional Neural Network, CNN)是深度学习中广泛应用的一种网络结构,特别适用于图像处理和计算机视觉任务。CNN通过卷积层、池化层和全连接层的组合来提取图像的特征。
3.1.1.1 卷积层
卷积层通过卷积核(filter)在输入图像上滑动,提取局部特征。每个卷积核学习到不同的特征,如边缘、纹理等。
import tensorflow as tf
from tensorflow.keras import layers
# 示例:一个简单的卷积层
model = tf.keras.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3))
])
3.1.1.2 池化层
池化层用于降低特征图的维度和计算复杂度,常见的池化操作有最大池化(MaxPooling)和平均池化(AveragePooling)。
# 示例:一个简单的最大池化层
model.add(layers.MaxPooling2D((2, 2)))
3.1.1.3 全连接层
全连接层将前面提取的特征映射到最终的分类空间,通常用于最后的分类或回归任务。
# 示例:一个简单的全连接层
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
3.1.2 CNN在目标检测中的应用
在目标检测任务中,CNN被用来提取图像中的特征,这些特征再经过进一步处理用于定位和分类目标。常见的方法包括R-CNN系列和单阶段检测器(如YOLO和SSD)。
3.2 区域卷积神经网络(R-CNN)系列
3.2.1 R-CNN
R-CNN(Regions with CNN features)是目标检测领域的一个重要突破。其基本思想是先使用选择性搜索算法生成一系列候选区域,然后用CNN对每个区域进行特征提取和分类。
3.2.2 Fast R-CNN
Fast R-CNN改进了R-CNN的效率问题。它通过引入ROI Pooling层,将候选区域直接映射到特征图上,然后一次性计算所有候选区域的特征,从而大大减少了计算量。
3.2.3 Faster R-CNN
Faster R-CNN在Fast R-CNN的基础上进一步优化,引入了区域建议网络(RPN),直接在特征图上生成候选区域,从而实现了端到端的训练。
3.2.3.1 R-CNN与Fast R-CNN、Faster R-CNN的对比
| 方法 | 优点 | 缺点 |
|---|---|---|
| R-CNN | 精度高,提出了新的检测框架 | 速度慢,计算量大 |
| Fast R-CNN | 速度快,计算效率高 | 仍然依赖候选区域生成算法 |
| Faster R-CNN | 完全端到端训练,效率更高 | 复杂度较高,训练时间长 |
3.3 单阶段检测器
3.3.1 YOLO(You Only Look Once)系列
YOLO是单阶段检测器的代表,它将目标检测任务视为一个回归问题,直接预测边界框和类别。YOLO系列不断发展,包括YOLOv1、YOLOv2、YOLOv3和最新的YOLOv4。
# 示例:使用YOLOv3进行目标检测
!pip install keras-yolo3
from yolo import YOLO
yolo = YOLO()
image_path = 'path/to/your/image.jpg'
result_image = yolo.detect_image(image_path)
result_image.show()
3.3.2 SSD(Single Shot MultiBox Detector)
SSD也是一种单阶段检测器,与YOLO类似,但其在不同尺度的特征图上进行检测,从而提高了对小目标的检测能力。
# 示例:使用SSD进行目标检测
from tensorflow.keras.applications import SSD
model = SSD(weights='ssd_weights.h5')
image_path = 'path/to/your/image.jpg'
result_image = model.detect_image(image_path)
result_image.show()
3.3.3 单阶段检测器的优缺点
| 优点 | 缺点 |
|---|---|
| 检测速度快,适合实时应用 | 精度相对较低,特别是在小目标检测上 |
| 模型较为简单,易于部署和优化 | 对复杂场景和高密度目标检测效果欠佳 |
3.4 代码示例与实验结果
3.4.1 YOLO的代码示例
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing import image
import numpy as np
# 加载预训练的YOLO模型
model = load_model('yolo.h5')
# 加载图像并进行预处理
img_path = 'path/to/image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0) / 255.0
# 进行预测
predictions = model.predict(img_array)
3.4.2 实验结果
我们对比了YOLO、SSD和Faster R-CNN在COCO数据集上的性能,结果如下表所示:
| 模型 | 平均精度(mAP) | 推理时间(ms) |
|---|---|---|
| YOLOv3 | 55.3% | 22 |
| SSD | 48.5% | 19 |
| Faster R-CNN | 58.4% | 198 |
3.5 结论
深度学习中的卷积神经网络及其改进方法在目标检测中表现出色。从R-CNN到Faster R-CNN,再到YOLO和SSD,目标检测技术在精度和速度上取得了显著的进步。未来的发展可能会进一步结合多种方法的优势,推动目标检测技术在自动驾驶等领域的广泛应用。
四、目标检测在自动驾驶中的应用场景
4.1 道路检测
4.1.1 车道线检测
车道线检测是自动驾驶系统的基础功能之一。通过检测道路上的车道线,车辆可以保持在正确的行驶车道内,并实现车道保持和自动驾驶功能。车道线检测通常使用卷积神经网络(CNN)来提取道路图像中的特征,结合霍夫变换等经典图像处理方法进行检测和识别。
4.1.1.1 车道线检测算法
车道线检测的基本流程包括图像预处理、特征提取和车道线拟合。以下是一个使用OpenCV进行简单车道线检测的代码示例:
import cv2
import numpy as np
def detect_lane(image):
# 将图像转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 高斯模糊
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 边缘检测
edges = cv2.Canny(blur, 50, 150)
# 定义感兴趣区域
height, width = edges.shape
mask = np.zeros_like(edges)
polygon = np.array([[
(0, height),
(width, height),
(width, height // 2),
(0, height // 2)
]], np.int32)
cv2.fillPoly(mask, polygon, 255)
# 提取感兴趣区域
cropped_edges = cv2.bitwise_and(edges, mask)
# 霍夫变换检测车道线
lines = cv2.HoughLinesP(cropped_edges, 1, np.pi / 180, 50, maxLineGap=50)
# 绘制车道线
if lines is not None:
for line in lines:
x1, y1, x2, y2 = line[0]
cv2.line(image, (x1, y1), (x2, y2), (0, 255, 0), 5)
return image
# 加载图像并进行车道线检测
image = cv2.imread('path/to/road_image.jpg')
lane_image = detect_lane(image)
cv2.imshow('Lane Detection', lane_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.1.2 路标识别
路标识别是自动驾驶系统中的另一项重要功能,旨在识别道路上的各种交通标志,如限速标志、停车标志、禁止通行标志等。通过路标识别,车辆可以动态调整行驶速度和路径,确保遵守交通规则。
4.1.2.1 路标识别算法
路标识别通常使用深度学习中的卷积神经网络(CNN)进行图像分类。以下是一个使用TensorFlow实现简单路标识别的代码示例:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 构建卷积神经网络模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dense(10, activation='softmax') # 假设有10种路标
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
# 假设我们有训练数据和标签
# train_images, train_labels = ...
# model.fit(train_images, train_labels, epochs=10, validation_split=0.2)
# 进行预测
# test_image = ...
# prediction = model.predict(test_image)
# print(f"Predicted class: {np.argmax(prediction)}")
4.2 车辆检测
4.2.1 前方车辆检测与跟踪
在自动驾驶系统中,前方车辆检测与跟踪是实现自适应巡航控制(ACC)和车道保持辅助(LKA)的关键。通过检测前方车辆的位置和速度,系统可以自动调整车速,保持安全距离。
4.2.1.1 车辆检测算法
前方车辆检测通常使用基于深度学习的目标检测算法,如YOLO或SSD。这些算法可以实时检测图像中的车辆并输出边界框。
from keras.models import load_model
from keras.preprocessing import image
import numpy as np
# 加载预训练的YOLO模型
model = load_model('yolo.h5')
def detect_vehicles(img_path):
img = image.load_img(img_path, target_size=(224, 224))
img_array = image.img_to_array(img) / 255.0
img_array = np.expand_dims(img_array, axis=0)
predictions = model.predict(img_array)
# 假设YOLO输出格式为:[x, y, width, height, class]
for pred in predictions:
x, y, w, h, cls = pred
if cls == 'vehicle': # 仅检测车辆类别
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
return img
# 检测车辆并显示结果
img_path = 'path/to/front_view_image.jpg'
result_img = detect_vehicles(img_path)
cv2.imshow('Vehicle Detection', result_img)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.2.2 车道变换和超车辅助
车道变换和超车辅助是自动驾驶系统中的高级功能,通过实时检测和跟踪周围车辆的位置,系统可以安全地进行车道变换和超车操作。
4.2.2.1 车道变换策略
车道变换涉及多个步骤,包括检测目标车道是否有车辆、评估当前车道和目标车道的交通情况、确定最佳变道时机等。以下是一个简单的伪代码示例:
function change_lane():
if is_lane_clear(target_lane):
if is_safe_distance_maintained(target_lane):
initiate_lane_change(target_lane)
else:
maintain_current_lane()
else:
maintain_current_lane()
function is_lane_clear(lane):
# 检查目标车道是否有车辆
return lane.is_clear()
function is_safe_distance_maintained(lane):
# 检查当前车道和目标车道的安全距离
return lane.get_safe_distance()
function initiate_lane_change(lane):
# 开始变道
vehicle.change_lane_to(lane)
4.3 行人检测
4.3.1 行人避让与安全保障
行人检测是自动驾驶系统确保行人安全的重要功能。通过检测和识别行人,系统可以及时采取避让措施,防止交通事故。
4.3.1.1 行人检测算法
行人检测常用的算法包括HOG(Histogram of Oriented Gradients)+ SVM(Support Vector Machine)和基于深度学习的目标检测算法。以下是一个使用HOG+SVM进行行人检测的代码示例:
import cv2
# 初始化HOG行人检测器
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
def detect_pedestrians(image):
# 检测行人
boxes, weights = hog.detectMultiScale(image, winStride=(8, 8))
# 绘制检测到的行人
for (x, y, w, h) in boxes:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
return image
# 检测行人并显示结果
image = cv2.imread('path/to/street_image.jpg')
result_image = detect_pedestrians(image)
cv2.imshow('Pedestrian Detection', result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
4.3.2 行人过街识别
行人过街识别是行人检测中的一项重要应用。通过识别行人的过街行为,自动驾驶系统可以提前减速或停车,确保行人安全。
4.3.2.1 行人过街识别策略
行人过街识别涉及对行人轨迹的预测和行为分析。以下是一个简单的伪代码示例:
function detect_crossing_pedestrians():
pedestrians = detect_pedestrians()
for pedestrian in pedestrians:
if is_crossing_road(pedestrian):
slow_down_or_stop()
function is_crossing_road(pedestrian):
# 检查行人是否有过街
行为
return pedestrian.is_moving_towards_road()
function slow_down_or_stop():
# 减速或停车
vehicle.slow_down_or_stop()
通过以上几种目标检测技术,自动驾驶系统可以实现对道路、车辆和行人的全面检测与识别,确保行车安全并提高自动驾驶的智能化水平。这些技术的应用不仅增强了自动驾驶系统的可靠性,还为未来智能交通的发展奠定了坚实的基础。
五、数据集与标注
5.1 常用数据集
在自动驾驶技术的发展中,数据集的选择对于目标检测算法的训练和性能评估至关重要。以下是几个常用的数据集:
KITTI 数据集:
- 特点:KITTI 数据集是一个广泛应用于自动驾驶研究的数据集,包含高清晰度图像、激光雷达数据和相机标定信息。
- 使用场景:主要用于评估车辆检测、行人检测、道路标志检测等任务的算法性能。
COCO 数据集:
- 特点:COCO 数据集包含大量的图像和详细的实例级别标注,覆盖了80个不同类别的物体。
- 使用场景:适用于多类别目标检测、分割和姿态估计任务的训练和评估。
PASCAL VOC 数据集:
- 特点:PASCAL VOC 数据集是一个经典的计算机视觉数据集,包含标注的物体检测任务和图像分割任务。
- 使用场景:常用于检测算法的初步验证和比较,尤其是对于小尺寸目标的检测。
这些数据集不仅提供了丰富的图像数据,还包含了详细的物体位置和类别标注,为算法的训练和评估提供了基础。
5.2 数据标注方法
数据标注是数据集准备过程中至关重要的一环,直接影响着训练模型的性能和泛化能力。常见的数据标注方法包括:
手动标注:
- 方法:由人工标注员手动绘制边界框或者进行像素级的分割标注。
- 优点:精确度高,能够处理复杂场景和细节。
- 缺点:耗时耗力,成本高,依赖标注员的经验和准确性。
自动标注:
- 方法:利用计算机视觉技术自动识别和标注物体。
- 优点:速度快,成本低,适用于大规模数据集的标注。
- 缺点:准确率不稳定,特别是在复杂背景或者低对比度场景下表现不佳。
5.3 标注质量对模型性能的影响
标注质量直接决定了训练模型的上限,影响着目标检测算法的精确度和鲁棒性。影响标注质量的因素包括但不限于:
- 标注准确性:边界框或者分割的精确度和覆盖面积是否准确。
- 标注一致性:不同标注员之间标注结果的一致性,以及同一标注员在不同时间标注的一致性。
- 标签类别:类别标签是否正确、完整和一致。
标注质量低下会导致模型在实际应用中的性能下降,例如错误的检测或者漏检现象。因此,在构建数据集和进行标注过程中,需要严格控制标注质量,采用质量控制流程和工具,以确保标注数据的可靠性和有效性。
通过对常用数据集和标注方法的了解,可以为自动驾驶中的目标检测算法提供良好的训练和评估平台,促进技术的进一步发展和应用。
六、目标检测模型的训练与优化
在自动驾驶技术的发展中,目标检测模型的训练和优化至关重要。通过合理的训练流程和优化方法,可以显著提升模型的性能和鲁棒性。
6.1 模型训练流程
目标检测模型的训练涉及多个步骤,从数据预处理到模型选择,再到训练参数的调整,每一步都至关重要。
6.1.1 数据预处理
数据预处理是模型训练的第一步,确保数据质量和一致性。常见的数据预处理步骤包括:
- 数据清洗:去除重复和错误的数据。
- 数据标注格式转换:将标注数据转换为训练所需的格式,例如将COCO格式转换为YOLO格式。
- 数据归一化:将图像数据归一化,以加速训练过程。
import cv2
import numpy as np
def preprocess_image(image_path):
# 读取图像
image = cv2.imread(image_path)
# 调整图像大小
image = cv2.resize(image, (416, 416))
# 归一化图像
image = image / 255.0
return image
# 示例图像预处理
image_path = 'example.jpg'
processed_image = preprocess_image(image_path)
6.1.2 模型选择与构建
根据任务需求选择合适的模型架构是模型训练的重要步骤。常用的目标检测模型包括:
- YOLO(You Only Look Once):实时性强,适用于实时检测任务。
- SSD(Single Shot MultiBox Detector):平衡了检测速度和精度。
- Faster R-CNN:检测精度高,适用于需要高精度检测的场景。
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, Reshape, Activation
def build_yolo_model(input_shape):
# 使用MobileNetV2作为基础模型
base_model = MobileNetV2(input_shape=input_shape, include_top=False)
x = base_model.output
# 添加YOLO的输出层
x = Conv2D(255, (1, 1))(x)
x = Reshape((13, 13, 3, 85))(x)
output = Activation('sigmoid')(x)
model = Model(inputs=base_model.input, outputs=output)
return model
# 构建YOLO模型
input_shape = (416, 416, 3)
yolo_model = build_yolo_model(input_shape)
6.1.3 训练参数调整
训练参数对模型的收敛速度和最终性能有重要影响。关键的训练参数包括:
- 学习率:控制模型参数更新的步长。
- 批量大小:每次训练所使用的数据样本数。
- 训练轮数:模型训练的总迭代次数。
from tensorflow.keras.optimizers import Adam
def compile_model(model):
# 配置优化器和损失函数
optimizer = Adam(learning_rate=0.001)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 编译模型
compile_model(yolo_model)
6.2 优化方法
为了提升目标检测模型的性能,可以采用多种优化方法,包括数据增强技术、模型优化技术和超参数调优。
6.2.1 数据增强技术
数据增强通过增加训练数据的多样性,提升模型的泛化能力。常见的数据增强方法包括:
- 旋转和翻转:随机旋转和翻转图像。
- 颜色变换:调整图像的亮度、对比度和饱和度。
- 裁剪和缩放:随机裁剪和缩放图像。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
def augment_data(image_path):
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
image = preprocess_image(image_path)
image = np.expand_dims(image, axis=0)
augmented_image = datagen.flow(image, batch_size=1)
return augmented_image
# 示例数据增强
augmented_image = augment_data(image_path)
6.2.2 模型优化技术
模型优化技术旨在减少模型的复杂性,提高推理速度和效率。常见的模型优化方法包括:
- 剪枝(Pruning):移除模型中冗余的神经元和连接,减少模型的计算量。
- 量化(Quantization):将模型权重和激活值从浮点数表示转换为低精度表示(如8位整数),减少存储和计算需求。
import tensorflow_model_optimization as tfmot
def prune_model(model):
pruning_schedule = tfmot.sparsity.keras.PolynomialDecay(initial_sparsity=0.0, final_sparsity=0.5, begin_step=2000, end_step=10000)
pruned_model = tfmot.sparsity.keras.prune_low_magnitude(model, pruning_schedule=pruning_schedule)
return pruned_model
# 剪枝模型
pruned_yolo_model = prune_model(yolo_model)
6.2.3 超参数调优
超参数调优通过调整模型训练过程中的超参数,找到最佳的训练配置,提高模型性能。常用的超参数调优方法包括:
- 网格搜索(Grid Search):遍历预定义的超参数组合,寻找最佳配置。
- 随机搜索(Random Search):在预定义的搜索空间内随机选择超参数组合,进行优化。
- 贝叶斯优化(Bayesian Optimization):通过构建概率模型,智能选择超参数组合,逐步优化。
from sklearn.model_selection import GridSearchCV
def tune_hyperparameters(model, X_train, y_train):
param_grid = {
'batch_size': [16, 32, 64],
'epochs': [10, 20, 30],
'learning_rate': [0.001, 0.0001, 0.00001]
}
grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3)
grid_result = grid.fit(X_train, y_train)
return grid_result.best_params_
# 超参数调优
best_params = tune_hyperparameters(yolo_model, X_train, y_train)
通过数据预处理、模型选择与构建、训练参数调整以及数据增强、模型优化和超参数调优,可以显著提升目标检测模型在自动驾驶中的性能。这些步骤和方法为构建高性能的目标检测系统提供了强有力的支持,促进自动驾驶技术的进一步发展和应用。
七、实际应用中的挑战与解决方案
7.1 实时性要求
7.1.1 如何提高检测速度
在自动驾驶中,目标检测的实时性至关重要。车辆在高速行驶时,需要实时检测和识别周围环境中的行人、车辆、障碍物等目标,以便及时做出反应,确保行驶安全。
- 优化算法:通过对目标检测算法进行优化,可以显著提高检测速度。例如,使用轻量级网络结构(如MobileNet、EfficientDet)替代传统的深度卷积网络,能够在保持较高检测精度的同时,显著减少计算量。
- 模型剪枝与量化:对深度学习模型进行剪枝和量化,可以大幅度减少模型的参数量和计算量,从而提高推理速度。模型剪枝通过移除冗余的网络连接和神经元,量化则通过降低权重和激活值的位数来减少计算需求。
- 并行计算:将目标检测任务分解为多个并行计算单元,可以显著提高处理速度。例如,在多线程或多进程环境中,利用CPU的多核架构或GPU的并行计算能力,分布式处理目标检测任务。
7.1.2 硬件加速技术(如GPU、TPU)
硬件加速技术是提高目标检测实时性的关键手段。现代的硬件加速器(如GPU、TPU)能够提供强大的计算能力,使得复杂的深度学习模型可以在短时间内完成推理任务。
- GPU加速:GPU(图形处理单元)具有强大的并行计算能力,非常适合用于深度学习模型的推理。通过CUDA或OpenCL等并行计算框架,可以将目标检测任务分布到多个GPU核心上并行处理,从而显著提高检测速度。
- TPU加速:TPU(张量处理单元)是Google专门为深度学习设计的加速器,具有极高的计算效率和能效比。TPU在执行矩阵乘法等深度学习计算时具有显著优势,能够大幅度提高目标检测的实时性。
- FPGA加速:FPGA(现场可编程门阵列)是一种可以根据需要动态配置的硬件加速器。通过定制化硬件电路,FPGA可以高效地执行特定的深度学习计算任务,从而提高目标检测的实时性。
7.2 复杂环境中的鲁棒性
7.2.1 如何处理光照变化、天气影响
自动驾驶系统在实际应用中需要面对各种复杂环境,如光照变化、雨雪天气等。这些因素都会对目标检测的准确性产生影响。
- 数据增强:在模型训练过程中,采用数据增强技术,可以使模型对不同环境具有更强的鲁棒性。通过在训练数据中加入光照变化、天气模拟等多种场景,模型可以学习到在复杂环境下的目标特征。
- 域适应:域适应技术通过将源域(训练数据)和目标域(实际应用环境)的特征进行对齐,使得模型能够在不同的环境中保持较高的检测精度。例如,使用生成对抗网络(GAN)进行域适应,可以在目标检测过程中减少光照和天气变化的影响。
- 动态调整:在实际应用中,可以通过实时监测环境变化,动态调整目标检测模型的参数或切换不同的检测策略。例如,在光照变化剧烈的场景下,可以启用具有更强光照适应性的模型。
7.2.2 多传感器融合(如Lidar、雷达)
单一传感器在复杂环境中可能会受到各种干扰,导致目标检测的准确性下降。通过多传感器融合,可以利用不同传感器的优势,提高检测的鲁棒性。
- Lidar与摄像头融合:Lidar(激光雷达)具有高精度的距离测量能力,而摄像头可以提供丰富的视觉信息。通过将Lidar的三维点云数据与摄像头的二维图像进行融合,可以有效地提高目标检测的准确性。例如,使用Lidar进行初步的目标检测和距离估计,然后利用摄像头进行精细的目标识别。
- 雷达与摄像头融合:雷达具有较强的穿透能力,可以在恶劣天气条件下稳定工作。通过将雷达数据与摄像头图像进行融合,可以在雨雪天气等复杂环境下提高目标检测的可靠性。例如,使用雷达进行目标初步定位,然后利用摄像头进行精确识别和分类。
- 多传感器数据融合算法:通过融合不同传感器的数据,可以综合利用各传感器的优点,降低单一传感器的缺陷对检测结果的影响。常用的多传感器数据融合算法包括卡尔曼滤波、粒子滤波等,可以在不同传感器之间进行数据融合和信息互补。
7.3 检测精度与误检问题
7.3.1 提高模型精度的方法
提高目标检测模型的精度是确保自动驾驶系统安全性的关键。为了提高检测精度,可以从以下几个方面入手:
- 大规模数据集:高质量的大规模数据集是训练高精度模型的基础。通过收集和标注大量的实际场景数据,可以使模型学习到更多的目标特征,提高检测精度。
- 更深的网络结构:使用更深、更复杂的网络结构(如ResNet、DenseNet)可以提高模型的特征提取能力,从而提高检测精度。深度网络可以捕捉到更多的目标细节,提高模型的识别能力。
- 集成学习:通过集成多个目标检测模型,可以进一步提高检测精度。集成学习方法(如Bagging、Boosting)通过结合多个模型的预测结果,可以有效地减少单一模型的误差,提高整体检测精度。
7.3.2 降低误检和漏检的策略
在目标检测中,误检(将非目标误认为目标)和漏检(将目标漏掉)都是需要避免的问题。为了解决这些问题,可以采取以下策略:
- 后处理步骤:在目标检测的后处理步骤中,可以通过非极大值抑制(NMS)算法减少误检。NMS算法可以移除重叠的检测框,只保留最有可能的目标框,从而减少误检率。
- 阈值调整:通过调整检测模型的置信度阈值,可以控制误检和漏检的平衡。在实际应用中,可以根据具体需求,动态调整检测阈值,以达到最佳的检测效果。
- 多尺度检测:在目标检测过程中,采用多尺度检测策略,可以有效地减少漏检。通过在不同尺度下进行目标检测,可以捕捉到大小不同的目标,提高检测的全面性。
八、未来发展趋势
8.1 人工智能算法的进步
8.1.1 更高效的网络结构
随着人工智能算法的不断发展,未来目标检测领域将会涌现出更加高效的网络结构,以满足自动驾驶系统对实时性和准确性的需求。
轻量化和高性能:未来的目标检测算法将会趋向于更加轻量化和高性能。例如,将会有更多基于轻量级骨干网络(如MobileNet、EfficientNet)的目标检测模型出现,这些模型在保持较高检测精度的同时,能够大幅度提升推理速度,满足自动驾驶系统对实时性的要求。
跨域适应能力:未来的算法将更加注重跨域适应能力,即在不同环境和条件下都能保持高效的目标检测能力。这涉及到模型对光照、天气、场景等变化的自适应能力,通过更智能的数据增强和域适应技术来提升模型的鲁棒性。
8.1.2 自监督学习和强化学习在目标检测中的应用
未来,自监督学习和强化学习将会成为提升目标检测性能的重要手段。
自监督学习:通过自监督学习方法,模型可以从大量未标记的数据中学习特征表示,从而提高在少样本或非常规场景下的检测能力。例如,利用视频帧的时间关系来进行自我监督学习,可以提升模型对动态场景的理解和预测能力。
强化学习:在自动驾驶中,强化学习可以用于优化决策过程,例如通过与环境的交互学习如何在复杂交通环境中进行安全、高效的行驶。未来的目标检测系统可能会集成强化学习算法,使得检测模型能够根据实时反馈不断优化自身的检测策略和效果。
8.2 自动驾驶技术的融合发展
8.2.1 V2X(车与万物通信)技术的融合
未来的自动驾驶系统将不仅仅依赖于车辆自身的传感器和算法,还将与周围环境进行更加紧密的互动和通信,实现更高效、更安全的自动驾驶体验。
车路协同:V2X技术将车辆与道路基础设施(如交通信号灯、路牌)进行连接,实现实时交通信息的共享和交换。这将有助于提升目标检测系统对复杂交通场景的感知能力,使自动驾驶更加智能和响应迅速。
车车协同:通过V2V(车辆对车辆)通信,不同车辆可以实时共享位置、速度和行驶意图等信息。这种信息共享可以大幅提高交通协同效率,减少交通事故的发生概率,进一步增强自动驾驶系统的安全性和可靠性。
8.2.2 更智能的决策系统
未来的自动驾驶系统将不仅限于目标检测和感知能力的提升,还将在决策和规划层面实现更高级的智能化。
多模态决策:结合目标检测、路径规划和环境感知等多个模块,未来的自动驾驶系统将能够更准确地预测和理解周围环境,从而做出更智能、更安全的驾驶决策。
基于场景的自适应策略:通过深度学习和强化学习的结合,未来的自动驾驶系统将能够根据不同的交通场景和环境条件,调整驾驶策略和行为,以实现最优化的驾驶体验和安全性。
8.3 法规与安全性要求
8.3.1 法规对目标检测系统的影响
随着自动驾驶技术的发展,法规和政策对自动驾驶系统中的目标检测功能提出了严格的要求和标准。
安全性和可靠性认证:目标检测系统需要通过严格的安全性和可靠性认证,确保其在各种情况下都能够稳定、可靠地工作。这包括针对硬件、软件和算法的全面测试和验证。
数据隐私保护:法规也会涉及到对驾驶数据的隐私保护要求,自动驾驶系统在收集、存储和处理驾驶数据时必须符合相关的隐私法规,保障用户的数据安全和隐私权。
8.3.2 安全性测试与验证方法
为了确保自动驾驶系统的安全性,未来将需要进一步发展和完善安全性测试和验证方法。
仿真测试:通过高度真实的虚拟仿真环境,对自动驾驶系统进行大规模的安全性测试。仿真环境可以模拟各种复杂的交通场景和极端情况,评估系统在不同情况下的反应和表现。
实地测试:在真实道路上进行安全性实地测试,评估自动驾驶系统在实际环境中的可靠性和安全性。这种测试可以发现仿真测试中无法覆盖到的具体问题和挑战。
8.4 总结
未来,随着人工智能技术的不断进步和自动驾驶技术的发展,目标检测作为自动驾驶系统的重要组成部分,将会在算法效率、系统集成、法规合规和安全性认证等方面迎来新的挑战和机遇。通过持续的技术创新和跨界合作,可以推动自动驾驶技术向更智能、更安全的未来迈进。