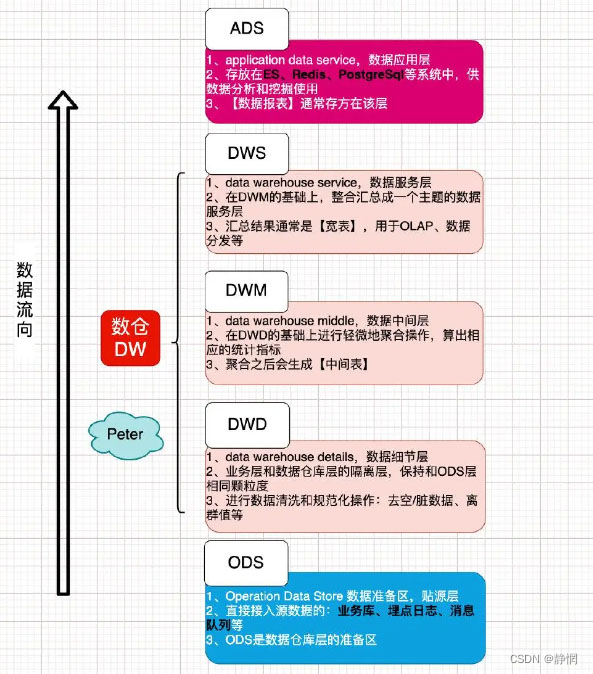
维度表概述
维度表是维度建模的基础和灵魂。前文提到,事实表紧紧围绕业务过程进行设计,而维度表则围绕业务过程所处的环境进行设计。维度表主要包含一个主键和各种维度字段,维度字段称为维度属性。
表设计步骤
确定维度(表)
在设计事实表时,已经确定了与每个事实表相关的维度,理论上每个相关维度均需对应一张维度表。需要注意到,可能存在多个事实表与同一个维度都相关的情况,这种情况需保证维度的唯一性,即只创建一张维度表。另外,如果某些维度表的维度属性很少,例如只有一个名称,则可不创建该维度表,而把该表的维度属性直接增加到与之相关的事实表中,这个操作称为维度退化。
确定主维表和相关维表
此处的主维表和相关维表均指业务系统中与某维度相关的表。例如业务系统中与商品相关的表有sku_info,spu_info,base_trademark,base_category3,base_category2,base_category1等,其中sku_info就称为商品维度的主维表,其余表称为商品维度的相关维表。维度表的粒度通常与主维表相同。
确定维度属性
确定维度属性即确定维度表字段。维度属性主要来自于业务系统中与该维度对应的主维表和相关维表。维度属性可直接从主维表或相关维表中选择,也可通过进一步加工得到。
确定维度属性时,需要遵循以下要求:
- 尽可能生成丰富的维度属性
维度属性是后续做分析统计时的查询约束条件、分组字段的基本来源,是数据易用性的关键。维度属性的丰富程度直接影响到数据模型能够支持的指标的丰富程度。
2.尽量不使用编码,而使用明确的文字说明,一般可以编码和文字共存。
3.尽量沉淀出通用的维度属性
有些维度属性的获取需要进行比较复杂的逻辑处理,例如需要通过多个字段拼接得到。为避免后续每次使用时的重复处理,可将这些维度属性沉淀到维度表中。
维度设计要点
规范化与反规范化
规范化是指使用一系列范式设计数据库的过程,其目的是减少数据冗余,增强数据的一致性。通常情况下,规范化之后,一张表的字段会拆分到多张表。
反规范化是指将多张表的数据冗余到一张表,其目的是减少join操作,提高查询性能。
在设计维度表时,如果对其进行规范化,得到的维度模型称为雪花模型,如果对其进行反规范化,得到的模型称为星型模型。 
数据仓库系统的主要目的是用于数据分析和统计,所以是否方便用户进行统计分析决定了模型的优劣。采用雪花模型,用户在统计分析的过程中需要大量的关联操作,使用复杂度高,同时查询性能很差,而采用星型模型,则方便、易用且性能好。所以出于易用性和性能的考虑,离线维度表一般是很不规范化的-星型模型。
实时数仓维度设计
在电商离线数仓中,普通维度表是通过主维表和相关维表做关联查询生成的。与之对应的业务数表数据是通过每日一次全量同步导入到 HDFS 的,只须每日做一次全量数据的关联查询即可。而实时数仓中,系统上线后我们采集的是所有表的变化数据,这样就会导致一旦主维表或相关维表中的某张表数据发生了变化,就需要和其它表的历史数据做关联。
此时我们会面临一个问题:如何获取历史数据?
对于这个问题,一种方案是在某张与维度表相关的业务表数据发生变化时,执行一次 maxwell-bootstrap 命令,将相关业务数据库维度表的数据导入 Kafka。但是这样做又会面临三个问题:
- Kafka 中存储冗余数据;
- maxwell-bootstrap 命令交给谁去执行?必然要引入调度组件或功能;
- 实时数仓中的数据是以流的形式存在的,如果不同流中数据进入程序的机器时间差异过大就会出现 join 不上的情况。如何保证导入的历史数据和变化数据可以关联上?势必要尽可能及时地执行历史数据导入命令且在 Flink 程序中设置足够的延迟。而前者难以保证,后者又会影响整个实时数仓的时效性。综上,这种方案并不合理。
另一种方案是维度表发生变化时去HBase中读取关联后的维表,筛选受影响的数据,与变化或新增的维度信息(通常生产环境的业务数据库是不会删除的)做关联,再把关联后的数据写入HBase。但是考虑这样一种情况,以商品表为例,主维表为sku_info,相关维表有spu_info, base_trademark,base_category1,base_category2,base_category3等,假设base_category1表的某条数据发生了变化,HBase表受影响的数据非常多(base_category1表的粒度较粗),我们需要把这些数据取出来,修改,然后再写回HBase。显然,这种方案也不合理。
第三种方案是将分表导入HBase,关联操作在HBase中完成。首先HBase的join性能很差,其次,关联操作不在流处理的DAG图中,需要单独调度,增加了系统复杂度。最后,当粒度较粗的维表数据发生变化时,受影响的数据很多。综上,这种方案也不合理。
基于上述分析,对业务表做 join 形成维度表的方式并不适用于实时数仓。
因此,在实时数仓中,我们不再对业务数据库中的维度表进行合并,仅对一些不需要的字段进行过滤,然后将维度数据写入 HBase 的维度表中,业务数据库的维度表和 HBase 的维度表是一一对应的。
写入维度数据使用HBase的put方法,实现幂等写入。当维度数据发生变化时,程序会用变化后的新数据覆盖旧数据。从而保证HBase中保存的是一份全量最新的维度数据。
这样做会产生一个问题:实时数仓没有保存历史维度数据,与数仓特征(保存历史数据)相悖。那么,维度表可以按照上述思路设计吗?
首先,我们要明确:数仓之所以要保存历史数据,是为了运用历史数据做一些相关指标的计算,而实时数仓本就是对最新的业务数据做分析计算,不涉及历史数据,因此无须保存。
此外,生产环境中实时数仓的上线通常不会早于离线数仓,如果有涉及到历史数据的指标,在离线数仓中计算即可。因此,实时数仓中只需要保留一份最新的维度数据,上述方案是切实可行的。
特别地,对于字典表,数据一般不会变化,而且我们至多只会用到 dic_code,dic_name 和parent_code三个字段,建立单独的维度表意义不大,选择将维度字段退化到事实表中。