这里写自定义目录标题
试用Qwen2做推理
参考:https://qwen.readthedocs.io/en/latest/getting_started/quickstart.html
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
# Now you do not need to add "trust_remote_code=True"
model = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen2-7B-Instruct",
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen2-7B-Instruct")
# Instead of using model.chat(), we directly use model.generate()
# But you need to use tokenizer.apply_chat_template() to format your inputs as shown below
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
# Directly use generate() and tokenizer.decode() to get the output.
# Use `max_new_tokens` to control the maximum output length.
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
执行此操作后模型会缓存到如下目录
/root/.cache/huggingface/hub/models–Qwen–Qwen2-7B-Instruct/
安装LLaMA-Factory
参考:https://github.com/hiyouga/LLaMA-Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"
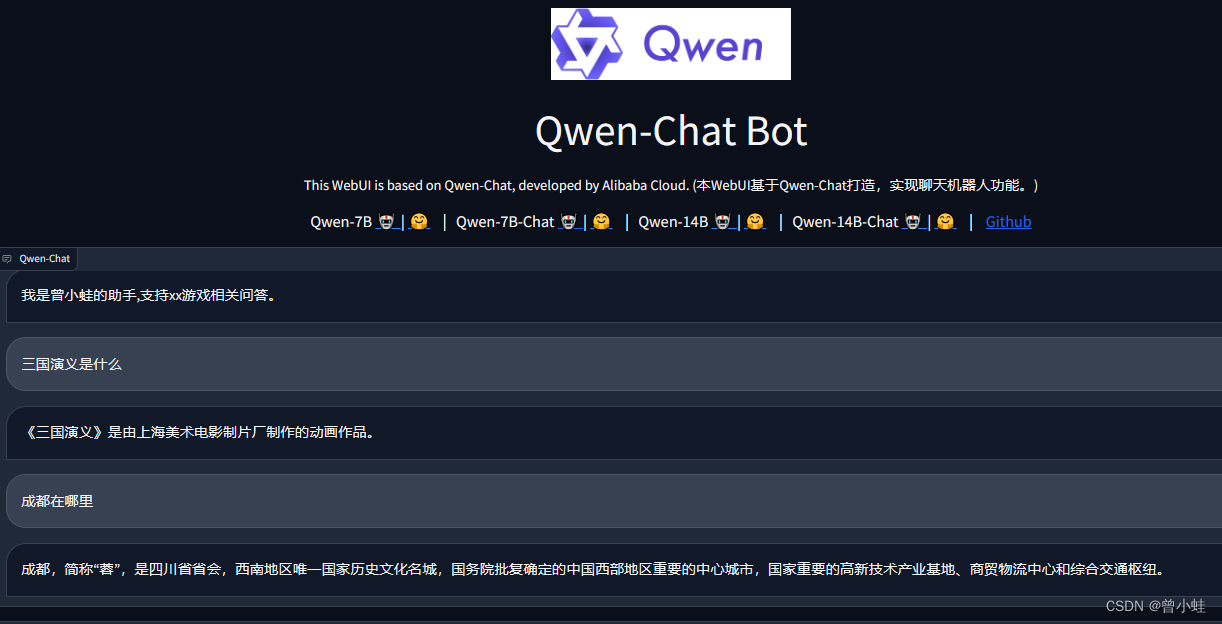
使用自有数据集微调Qwen2
参考:https://qwen.readthedocs.io/en/latest/training/SFT/llama_factory.html
启动web ui 界面来进行微调
llamafactory-cli webui

数据集选择提前准备好的自有数据集
按照自己需求配置训练参数,所有的参数都配置好之后,点一下“预览命令”,确认命令没有问题之后,就可以点击“开始”进行训练了。训练的过程中可以看到 loss的变化曲线、训练耗时等。
参考:https://blog.csdn.net/u012505617/article/details/137864437
验证微调效果
在webui 界面训练好模型之后点击“Export”选项卡,然后,在“模型路径”中输入原始模型路径,然后在“检查点路径”中选择自己微调得到的 checkpoint路径,然后在“最大分块大小(GB)”中设置为4,同时设置一下导出目录,最后点击“开始导出”,就可以看到输出的模型了
本地部署模型,并做推理测试
参考:https://qwen.readthedocs.io/en/latest/run_locally/llama.cpp.html























![[GICv3] 3. 物理中断处理(Physical Interrupt Handling)](https://img-blog.csdnimg.cn/fcb5d44bc81d48b4b449a6573ad5d6cb.png)