目录
引言
聚类(Clustering)是数据挖掘和统计学中的一个重要概念,它是一种无监督学习的方法,用于将数据集中的样本或观测值分组为若干个类或簇(Cluster),使得同一簇内的样本之间相似度较高,而不同簇的样本之间相似度较低。与监督学习(如分类)不同,聚类不需要事先知道每个样本的类别标签,它完全基于数据本身的特征来进行分组。
聚类的主要特点
- 无监督学习:聚类算法不需要训练数据集中的标签信息,它们仅根据数据本身的特征来发现数据的内在结构。
- 发现隐藏模式:聚类可以帮助我们发现数据中的隐藏模式或群组,这些群组可能对应着数据的不同类别或子群体。
- 多样性和灵活性:存在多种聚类算法,每种算法都有其独特的优势和适用场景,如基于距离的聚类(如K-means)、基于密度的聚类(如DBSCAN)、基于层次的聚类(如AGNES和DIANA)等。
聚类算法的主要步骤
- 特征选择:选择用于聚类的数据特征。
- 相似性度量:定义如何计算样本之间的相似性或距离。
- 聚类算法选择:根据数据的特性和需求选择合适的聚类算法。
- 执行聚类:应用选定的聚类算法对数据进行分组。
- 评估聚类结果:评估聚类结果的质量,可能需要根据实际需求进行多次迭代调整。
- 结果解释和应用:解释聚类结果,并将其应用于实际问题解决中。
聚类的应用场景
聚类在多个领域都有广泛的应用,包括但不限于:
- 市场细分:将消费者根据购买行为、偏好等特征进行分组,以制定更精准的营销策略。
- 生物信息学:对基因表达数据进行聚类,以发现具有相似表达模式的基因群组。
- 图像处理:对图像中的像素或特征进行聚类,以实现图像分割、目标检测等任务。
- 社交网络分析:对用户或群组进行聚类,以发现社交网络中的社区结构或用户行为模式。
- 文本挖掘:对文档或文本数据进行聚类,以发现主题或信息类别。
聚类算法的局限性
尽管聚类具有广泛的应用,但它也存在一些局限性:
- 聚类结果的不确定性:由于聚类是无监督学习,聚类结果可能受到算法选择、参数设置等多种因素的影响,导致结果具有一定的不确定性。
- 对数据质量的依赖:聚类效果很大程度上依赖于输入数据的质量,如数据的完整性、准确性等。
- 难以解释性:在某些情况下,聚类结果可能难以直观解释或理解,特别是对于高维数据或复杂数据集。
总之,聚类是一种强大的数据分析工具,它可以帮助我们发现数据中的隐藏模式和群组结构,为后续的决策分析提供有力支持。然而,在实际应用中,我们也需要充分考虑其局限性和挑战,以选择合适的聚类方法和策略。
聚类方法
常用的聚类方法多种多样,每种方法都有其独特的优势和适用场景。以下是一些常用的聚类方法及其详细介绍:
1. K-means聚类算法
概述:
K-means聚类算法是一种基于划分的聚类方法,由James MacQueen在1967年提出。该算法将数据分为K个簇,通过迭代的方式优化簇内数据点的平均距离,使得同一簇内的数据点尽可能相似,而不同簇间的数据点尽可能不同。
步骤:
- 随机选择K个数据点作为初始的聚类中心。
- 计算每个数据点与各个聚类中心之间的距离,将数据点分配到最近的聚类中心所在的簇中。
- 重新计算每个簇的聚类中心(通常是簇内数据点的均值)。
- 重复步骤2和3,直到聚类中心不再发生变化或达到其他终止条件(如迭代次数限制、误差平方和局部最小等)。
优点:
- 实现简单,收敛速度快。
- 聚类效果通常较好,特别是当簇的形状接近球形时。
缺点:
- 需要事先指定聚类数目K。
- 对初始聚类中心的选择敏感,可能导致不同的聚类结果。
- 对噪声和异常值敏感。
clc;
clear;
% 假设data已经被加载,并且是一个二维数组(N x M),其中N是样本数,M是特征数
% 聚类中心的数量
k = 3;
% 显示原始数据的一部分(可选)
figure;
subplot(1,2,1);
plot(data(:,1), data(:,2), 'o'); % 假设我们有两个特征来可视化
xlabel('Feature 1');
ylabel('Feature 2');
title('Original Data Points');
grid on;
% 初始化聚类中心(随机选择)
indices = randperm(size(data, 1), k);
CC = data(indices, :);
% 初始化距离矩阵和聚类分配矩阵
D = zeros(size(data, 1), k);
C = cell(1, k);
for i = 1:k
C{i} = [];
end
% 迭代过程
while true
% 计算每个点到每个聚类中心的距离
for i = 1:size(data, 1)
for j = 1:k
D(i, j) = sqrt(sum((data(i, :) - CC(j, :)) .^ 2, 2)); % 计算欧氏距离
end
[~, minIndex] = min(D(i, :)); % 找到最近的聚类中心索引
% 更新聚类分配
if ~isempty(C{minIndex})
C{minIndex} = [C{minIndex}, i];
else
C{minIndex} = i;
end
end
% 重新计算聚类中心
newCC = zeros(k, size(data, 2));
for j = 1:k
if ~isempty(C{j})
newCC(j, :) = mean(data(C{j}, :), 1); % 计算新的聚类中心
end
end
% 检查聚类中心是否收敛
if all(newCC == CC, 'all')
break;
end
CC = newCC; % 更新聚类中心
end
% 绘制聚类结果
figure;
subplot(1,2,2);
colors = ['r', 'g', 'b'];
for j = 1:k
if ~isempty(C{j})
plot(data(C{j}, 1), data(C{j}, 2), '.', 'Color', colors(j));
hold on;
plot(newCC(j, 1), newCC(j, 2), 'kx', 'MarkerSize', 15, 'LineWidth', 3, 'Color', colors(j));
end
end
xlabel('Feature 1');
ylabel('Feature 2');
title('K-means Clustering Results');
grid on;
legend(arrayfun(@(j) sprintf('Cluster %d', j), 1:k, 'UniformOutput', false));2. DBSCAN聚类算法
概述:
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法。该算法将簇定义为密度相连的点的最大集合,能够发现任意形状的簇,并处理噪声点。
核心概念:
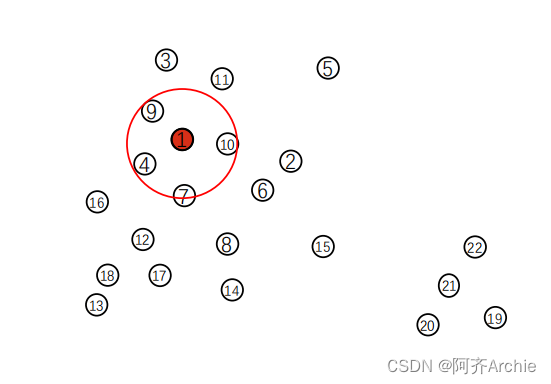
- ε邻域:给定对象半径为ε内的区域称为该对象的ε邻域。
- 核心对象:如果给定对象ε邻域内的样本点数大于等于MinPts(最小点数),则称该对象为核心对象。
- 密度可达和密度相连:基于核心对象和ε邻域的概念,定义了密度可达和密度相连的关系,用于描述簇内数据点之间的连接性。
步骤:
- 从数据集中随机选择一个未处理的数据点p。
- 如果p是核心对象,则找出所有从p密度可达的数据点,形成一个簇。
- 递归地对簇内的每个未处理的数据点执行步骤2,直到簇内的所有点都被处理。
- 重复步骤1-3,直到数据集中的所有点都被处理完毕。
优点:
- 不需要事先指定聚类数目。
- 能够发现任意形状的簇。
- 对噪声和异常值具有鲁棒性。
缺点:
- 对参数ε和MinPts的选择敏感。
- 当数据集的密度差异很大时,可能难以选择合适的参数。
function [IDX, isnoise]=DBSCAN(X,epsilon,MinPts) % DBSCAN聚类函数
C=0; % 统计簇类个数,初始化为0
n=size(X,1); % 把矩阵X的行数数赋值给n,即一共有n个点
IDX=zeros(n,1); % 定义一个n行1列的矩阵
D=pdist2(X,X); % 计算(X,X)的行的距离
visited=false(n,1); % 创建一维的标记数组,全部初始化为false,代表还未被访问
isnoise=false(n,1); % 创建一维的异常点数组,全部初始化为false,代表该点不是异常点
for i=1:n % 遍历1~n个所有的点
if ~visited(i) % 未被访问,则执行下列代码
visited(i)=true; % 标记为true,已经访问
Neighbors=RegionQuery(i); % 查询周围点中距离小于等于epsilon的个数
if numel(Neighbors)<MinPts % 如果小于MinPts
% X(i,:) is NOISE
isnoise(i)=true; % 该点是异常点
else % 如果大于MinPts,且距离大于epsilon
C=C+1; % 该点又是新的簇类中心点,簇类个数+1
ExpandCluster(i,Neighbors,C); % 如果是新的簇类中心,执行下面的函数
end
end
end % 循环完n个点,跳出循环
function ExpandCluster(i,Neighbors,C) % 判断该点周围的点是否直接密度可达
IDX(i)=C; % 将第i个C簇类记录到IDX(i)中
k = 1;
while true % 一直循环
j = Neighbors(k); % 找到距离小于epsilon的第一个直接密度可达点
if ~visited(j) % 如果没有被访问
visited(j)=true; % 标记为已访问
Neighbors2=RegionQuery(j); % 查询周围点中距离小于epsilon的个数
if numel(Neighbors2)>=MinPts % 如果周围点的个数大于等于Minpts,代表该点直接密度可达
Neighbors=[Neighbors Neighbors2]; %#ok % 将该点包含着同一个簇类当中
end
end % 退出循环
if IDX(j)==0 % 如果还没形成任何簇类
IDX(j)=C; % 将第j个簇类记录到IDX(j)中
end % 退出循坏
k = k + 1; % k+1,继续遍历下一个直接密度可达的点
if k > numel(Neighbors) % 如果已经遍历完所有直接密度可达的点,则退出循环
break;
end
end
end % 退出循环
function Neighbors=RegionQuery(i) % 该函数用来查询周围点中距离小于等于epsilon的个数
Neighbors=find(D(i,:)<=epsilon);
end
3. 层次聚类算法
概述:
层次聚类算法通过计算数据点之间的相似度或距离,将数据点组织成树状的层次结构。根据构建层次结构的方向,层次聚类可以分为凝聚的层次聚类(如AGNES)和分裂的层次聚类(如DIANA)。
AGNES(AGglomerative NESting):
- 概述:AGNES是一种凝聚的层次聚类方法,它最初将每个数据点视为一个单独的簇,然后逐步合并最相似的簇,直到达到指定的簇数目或满足其他终止条件。
- 步骤:包括初始化、合并簇、重复合并直到满足终止条件等。
DIANA(Divisive ANAlysis):
- 概述:DIANA是一种分裂的层次聚类方法,它首先将所有数据点视为一个簇,然后逐步分裂成更小的簇,直到每个簇只包含一个数据点或达到指定的簇数目。
- 步骤:包括初始化、选择分裂点、分裂簇、重复分裂直到满足终止条件等。
优点:
- 不需要事先指定聚类数目。
- 能够生成聚类的层次结构,便于分析不同层次的聚类结果。
缺点:
- 计算复杂度较高,特别是对于大数据集。
- 合并或分裂点的选择可能影响聚类结果的质量。
























![[Vulnhub] IMF File Upload Bypass&Buffer Overflow](https://img-blog.csdnimg.cn/img_convert/ed9fc6fd3d525cb592e2835d26d9a6cc.jpeg)