- UPDATED:2023 年 1 月 27 日,本文登上 ATA 头条。(注:ATA 全称 Alibaba Technology Associate,是阿里集团最大的技术社区)
- UPDATED:2023 年 2 月 2 日,本文在 ATA 获得鲁肃点赞。(注:鲁肃,本名程立,是阿里合伙人、阿里集团上一任 CTO)
大家好!我是麦克船长,目前就职于阿里巴巴集团,任总监/资深综合运营专家,先后负责过淘宝行业产品团队、天天特卖、大聚划算运营中心。网名一直用「麦克船长」,中科大计算机本科毕业后先是做的音视频流媒体技术、分布式系统等等,干过 Full Stack,后来创业在技术、产品、运营、营销、供应链等等方面多年后来到阿里,在淘系带过不同业务的产品、运营团队。文本来自我的个人博客:
MikeCaptain - 麦克船长的技术、产品与商业博客
,梳理了自己在春节期间对 NLP 基础模型的技术演变学习笔记记录,写就于大年初一在香港过春节时。本文包含 3 个章节:
- 第一章,主要介绍 Transformer 出现之前的几个主流语言模型
,包括 N 元文法(n-gram)、多层感知器(MLP)、卷积神经网络(CNN)、循环神经网络(RNN)。其中 CNN 主要应用领域在计算机视觉,因此没有更详细展开。其他模型也未面面俱到,主要考虑还是一个领域学习者的角度来了解和应用,而非研究。 - 第二章,是本文的核心
,先介绍了注意力机制(Attention Mechanism),然后基于第一章对此前几大语言模型了解后,我们能更好地理解 Transformer 为什么会带来革命性的影响。 - 第三章,是一个 Transformer 的实现版本
,基于 Tensorflow。
春节期间,除了本文,我还梳理了一篇关于「大型语言模型(LLM)在 Transformer 之后的演化综述」和一篇关于「LLM 引领生产力革命,带来的未来几年科技脉搏把控」
,但没有时间整理排版,待日后有空再归拢后发出,这些权当是在春节期间消磨时间的技术爱好,因为是偏向学习的技术笔记,所以
非常欢迎大家批评、指正、交流
。
- 作者:钟超(麦克船长)
- 邮箱:zhongchao.ustc#gmail.com (#->@)
- 微信:sinosuperman(请注明「公司/机构、职位」便于我备注,谢谢)
- 时间:2023 年 1 月 22 日
前言
本文试图从技术角度搞清楚一个问题:
过去一年 AIGC 爆火、过去五年 NLP(自然语言处理)领域突飞猛进的缘起是什么?
这个问题被解答后,将还有两个问题,但暂时本文没有作答:1)如果认为通过图灵测试代表着 AGI(Artificial General Intelligence,通用人工智能)的话,当下 NLP,乃至 AGI 发展到什么程度了?2)未来一些年内,AGI 的发展路线可能会是怎样的?
利用春节时间,写了这么一篇数万字的长文笔记,希望共同爱好的朋友能读完多多指正。
1、我来阿里之后第一个新增爱好是「变形金刚模型」,第二个新增爱好是「变形金刚模型」
写了个这么冷的梗,其实想说的是,前者指的是著名 IP「变形金刚」相关的手办玩具模型,后者指的是这个引领革命的人工智能语言模型 Transformer。这两个爱好,都与目前从事的电商工作本职没有表面上的直接联系,权当爱好了。
2022 年「生成式 AI」应用取得了突飞猛进的发展,作为一个「古典互联网」从业者,深切地感到这一次 AI 技术可能会带来的颠覆式变革,这让我兴奋又焦虑。2022 年上半年,我从天天特卖业务负责人到大聚划算运营中心负责人,在去年相当长一段时间里在关注直播带货在营销平台的模式命题,一直在思考一个问题:直播电商的高效(更适合的商品演绎方式 + 私域权益 + 冲动购买等」vs. 直播电商的低效(直播分发无人货匹配 + 直播间内千人一面 + 货品状态未知 + 主播不可控等),能否推动一个保留直播的高效,同时解决直播的低效的模式呢?
这里面有大量的内容值得探讨,不过这不是麦克船长该系列文章的初衷,但这是我为什么开始非常关注 AI 的引子。直播电商的数字人技术基础,有动作捕捉、面部表情模拟、视觉渲染、直播话术生成、语音合成等等。依据第一性原理抽丝剥茧后,我发现尽管动作捕捉、视觉渲染等等很多技术仍有很大挑战,但是从商业视角看真正最影响用户心智的,是直播话术生成和演绎,除了头部主播,绝大多数直播带货在这方面都做的很糟糕,那么这里面就有巨大的「机器学习」生成内容超越非头部的大多数从业者的市场空间,而这完全依赖自然语言处理(NLP)。
这个问题就属于「生成式 AI」的范畴了,国外科技圈叫它「Gen-AI」,即 Generative AI,中国科技圈都叫它「AIGC」,即 AI Generated Content,与 UGC、PGC 相对应。Gen-AI 的叫法更关注主体,具体地说是「生成式 AI 模型」,它是个「内容引擎」。而中国的叫法更关注「内容应用」。
讲到 AIGC 这里,大家熟悉的 ChatGPT 就在 2022 年年底登场了。也是因为 ChatGPT 的破圈,带来了 AIGC 在国内科技圈的关注度暴涨。我从去年年中开始关注「文生图,text2image」领域的明星 Stable Diffusion 开源,进而关注到了 text2image 应用的爆发,包括 Disco Diffusion、MidJourney、DALL·E 2 等等,这些都源于 CV(计算机视觉)领域因为 Diffusion 模型发展带来的技术突破。
AI 生成图片确实非常惊人。我酷爱变形金刚模玩,进而对机甲类都非常喜欢,所以随手生成了几张图,这里贴一下大家看看,分钟级的创作速度。(注意:当下 AI 生成图片主要是基于 Diffusion 的应用发展,AI 生成文本的核心驱动才是 Transformer 模型,此处只是展示)
但是从第一性原理角度讲,生成图片的应用广度,远远小于生成文本。文本内容的本质是语言文字的理解与生成,人类历史有 600 万年,但是人类文明历史大概就 6000 年,文明的大发展出现在近 2000 多年的原因,主要来自 3500 多年前人类发明了文字。所以 AI 生成文本,意味着 AI 可以用人类熟悉的方式(语言文字)与人类高效协作,这必将引爆生产力革命。而这必将深入影响电商、内容、游戏、云计算、企业服务等众多领域。
2、掌握技术基础,是当下读懂 AI 脉搏的基本功,而这个脉搏将带动各行各业
一旦深入关注 AI、关注 NLP 领域,你就会发现当下仍然处于一个技术发展突破的阶段,不关注技术的情况下来聊 AI、聊 NLP、聊 AIGC,那就只能是一个「爱好者」,而无法深入与这个行业内的弄潮儿对话,更不要提参与其中了。所以这个春节,麦克船长回归了当年做技术时的初心,翻了一些材料,学习了 NLP 语言模型的关键技术,在此作为技术学习笔记,与大家分享。尽管担心班门弄斧,但是本着费曼老师提倡的输出学习法,我把自己学习梳理的内容抛出来,除了会更帮助到我自己,也能结交一些对此同样在关注的同学们,欢迎感兴趣的同学加我的微信(微信号 sinosuperman)在业余时间和我交流。
阅读本文,先对你过往的基础知识做了一些假设,如果你暂未了解,可能在阅读时遇到以下内容做一些简单地查询即可:
- Word Presentation:自然语言处理中的词表示法,主要涉及 embedding。
- 张量:需要一点基础,比如了解张量的形状、升降维度等。但不会涉及到复杂问题,对一阶张量(向量)、二阶张量(矩阵)的简单运算有数学基础即可。对三阶张量,大概能想象出其空间含义即可。语言模型里理解词之间的距离,是有其空间几何意义的。
- 技术框架:PyTorch 或 TensorFlow 框架。由于时间和篇幅关系,春节期间梳理这些时,对于框架基础,我主要是 Google 现用现查,询问 ChatGPT 以及在微信读书里直接搜索全文。
作为技术笔记难免有纰漏或理解错误,欢迎指正。文中自绘图片用的是 Graphviz,公式生成用的是 KaTeX,贴到 ATA 后难免有一些没有兼容的部分(发现的已做了 fix),望见谅。
第一章 · 2017 年之前的几个关键 NLP 语言模型
NLP 的技术基础方面,我认为主要是这两部分:词表示法(Word Presentation)、语言模型(Language Model)。对于词表示法,这里不做详细介绍,基本的思路就是把词表示为向量(一维张量),最基本的 One-Hot、Word2Vec、GloVe、fastText 等。这部分的技术演进也在不断前进,比如本文将要重点介绍的 Transformer 模型里,用到的词表示法是「引入上下文感知的词向量」。
语言模型从早期的 N 元文法(N-Gram,本文要介绍的),到神经网络被提出后最早期的感知器(Perceptron),再到后来席卷计算机视觉(CV)领域的卷积神经网络(CNN),然后出现考虑序列特征的循环神经网络(RNN,包括 Encoder-Decoder 模型),直到 2017 年横空出世的 Transformer,大概分这五个主要阶段。因为本文的重点是 Transformer,所以前面四个模型我会快速概览一下,然后介绍下最朴素的注意力(Attention)机制,基于此再详细介绍下 Transformer,并对一个完整的、精炼实现的代码实例进行精讲。
第 1 节 · N 元文法语言模型
1.1、马尔科夫假设(Markov Assumption)与 N 元文法语言模型(N-gram Language Model)
下一个词出现的概率只依赖于它前面 n-1 个词,这种假设被称为「马尔科夫假设(Markov Assumption」。N 元文法,也称为 N-1 阶马尔科夫链。
- 一元文法(1-gram),unigram,零阶马尔科夫链,不依赖前面任何词;
- 二元文法(2-gram),bigram,一阶马尔科夫链,只依赖于前 1 个词;
- 三元文法(3-gram),trigram,二阶马尔科夫链,只依赖于前 2 个词;
- ……
通过前 t-1 个词预测时刻 t 出现某词的概率,用最大似然估计:
P
(
w
t
∣
w
1
,
w
2
.
.
.
w
t
−
1
)
=
C
(
w
1
,
w
2
,
.
.
.
w
t
)
C
(
w
1
,
w
2
,
.
.
.
w
t
−
1
)
P(w_t | w_1,w_2…w_{t-1}) = \frac{C(w_1,w_2,…w_t)}{C(w_1,w_2,…w_{t-1})}
P
(
w
t
∣
w
1
,
w
2
…
w
t
−
1
)
=
C
(
w
1
,
w
2
,
…
w
t
−
1
)
C
(
w
1
,
w
2
,
…
w
t
)
进一步地,一组词(也就是一个句子)出现的概率就是:
P
(
w
1
,
w
2
,
.
.
.
w
t
)
=
P
(
w
t
∣
w
1
,
w
2
,
.
.
.
w
t
−
1
)
⋅
P
(
w
t
−
1
∣
w
1
,
w
2
,
.
.
.
w
t
−
2
)
⋅
.
.
.
⋅
P
(
w
1
)
=
∏
i
=
1
t
−
1
P
(
w
i
∣
w
1
:
i
−
1
)
\begin{aligned} P(w_1,w_2,…w_t) &= P(w_t | w_1,w_2,…w_{t-1}) \cdot P(w_{t-1} | w_1,w_2,…w_{t-2}) \cdot … \cdot P(w_1) \ &= \displaystyle\prod_{i=1}^{t-1}P(w_i | w_{1:i-1}) \end{aligned}
P
(
w
1
,
w
2
,
…
w
t
)
=
P
(
w
t
∣
w
1
,
w
2
,
…
w
t
−
1
)
⋅
P
(
w
t
−
1
∣
w
1
,
w
2
,
…
w
t
−
2
)
⋅
…
⋅
P
(
w
1
)
=
i
=
1
∏
t
−
1
P
(
w
i
∣
w
1
:
i
−
1
)
为了解决句头、尾逇概率计算问题,我们再引入两个标记 和 分别表示 beginning of sentence 和 end of sentence,所以
w
0
=
w_0 =
w
0
=
、
w
l
e
n
g
t
h
1
=
w_{length + 1} =
w
l
e
n
g
t
h
1
=
,其中 length 是词的数量。
具体地,比如对于 bigram,该模型表示如下:
P
(
w
1
,
w
2
,
.
.
.
w
t
)
=
∏
i
=
1
t
−
1
P
(
w
i
∣
w
i
−
1
)
P
(
w
t
∣
w
t
−
1
)
=
C
(
w
t
−
1
,
w
t
)
C
(
w
t
−
1
)
\begin{aligned} P(w_1,w_2,…w_t) &= \displaystyle\prod_{i=1}^{t-1}P(w_i | w_{i-1}) \ P(w_t | w_{t-1}) &= \frac{C(w_{t-1}, w_t)}{C(w_{t-1})} \end{aligned}
P
(
w
1
,
w
2
,
…
w
t
)
P
(
w
t
∣
w
t
−
1
)
=
i
=
1
∏
t
−
1
P
(
w
i
∣
w
i
−
1
)
=
C
(
w
t
−
1
)
C
(
w
t
−
1
,
w
t
)
- 如果有词出现次数为了 0,这一串乘出来就是 0 了,咋办?
- 因为基于马尔科夫假设,所以 N 固定窗口取值,对长距离词依赖的情况会表现很差。
- 如果把 N 值取很大来解决长距离词依赖,则会导致严重的数据稀疏(零频太多了),参数规模也会急速爆炸(高维张量计算)。
上面的第一个问题,我们引入平滑 / 回退 / 差值等方法来解决,而后面两个问题则是在神经网络模型出现后才更好解决的。
1.2、平滑(Smoothing)/ 折扣(Discounting)
虽然限定了窗口 n 大小降低了词概率为 0 的可能性,但当 n-gram 的 n 比较大的时候会有的未登录词问题(Out Of Vocabulary,OOV)。另一方面,训练数据很可能也不是 100% 完备覆盖实际中可能遇到的词的。所以为了避免 0 概率出现,就有了让零平滑过渡为非零的补丁式技术出现。
最简单的平滑技术,就是折扣法(Discounting)。这是一个非常容易想到的办法,就是把整体 100% 的概率腾出一小部分来,给这些零频词(也常把低频词一起考虑)。常见的平滑方法有:加 1 平滑、加 K 平滑、Good-Turing 平滑、Katz 平滑等。
1.2.1、加 1 平滑 / 拉普拉斯平滑(Add-One Discounting / Laplace Smoothing)
加 1 平滑,就是直接将所有词汇的出现次数都 +1,不止针对零频词、低频词。如果继续拿 bigram 举例来说,模型就会变成:
P
(
w
i
∣
w
i
−
1
)
=
C
(
w
i
−
1
,
w
i
)
1
∑
j
=
1
n
(
C
(
w
i
−
1
,
w
j
)
1
)
=
C
(
w
i
−
1
,
w
i
)
1
C
(
w
i
−
1
)
∣
V
∣
P(w_i | w_{i-1}) = \frac{C_(w_{i-1},w_i) + 1}{\displaystyle\sum_{j=1}^n(C_(w_{i-1},w_j) + 1)} = \frac{C(w_{i-1}, w_i) + 1}{C(w_{i-1}) + |\mathbb{V}|}
P
(
w
i
∣
w
i
−
1
)
=
j
=
1
∑
n
(
C
(
w
i
−
1
,
w
j
)
1
)
C
(
w
i
−
1
,
w
i
)
1
=
C
(
w
i
−
1
)
∣
V
∣
C
(
w
i
−
1
,
w
i
)
1
其中
N
N
N
表示所有词的词频之和,
∣
V
∣
|\mathbb{V}|
∣
V
∣
表示词汇表的大小。
如果当词汇表中的词,很多出现次数都很小,这样对每个词的词频都 +1,结果的偏差影响其实挺大的。换句话说,+1 对于低频词很多的场景,加的太多了,应该加一个更小的数( 1 < δ < 1)。所以有了下面的「δ 平滑」技术。
1.2.2、加 K 平滑 / δ 平滑(Add-K Discounting / Delta Smoothing)
把 +1 换成 δ,我们看下上面 bigram 模型应该变成上面样子:
P
(
w
i
∣
w
i
−
1
)
=
C
(
w
i
−
1
,
w
i
)
δ
∑
j
=
1
n
(
C
(
w
i
−
1
,
w
j
)
δ
)
=
C
(
w
i
−
1
,
w
i
)
δ
C
(
w
i
−
1
)
δ
∣
V
∣
P(w_i | w{i-1}) = \frac{C_(w_{i-1},w_i) + \delta}{\displaystyle\sum_{j=1}^n(C_(w_{i-1},w_j) + \delta)} = \frac{C(w_{i-1}, w_i) + \delta}{C(w_{i-1}) + \delta|\mathbb{V}|}
P
(
w
i
∣
w
i
−
1
)
=
j
=
1
∑
n
(
C
(
w
i
−
1
,
w
j
)
δ
)
C
(
w
i
−
1
,
w
i
)
δ
=
C
(
w
i
−
1
)
δ
∣
V
∣
C
(
w
i
−
1
,
w
i
)
δ
δ 是一个超参数,确定它的值需要用到困惑度(Perplexity,一般用缩写 PPL)。另外,有些文章里也会把这个方法叫做「加 K 平滑,Add-K Smoothing」。
1.2.3、困惑度(Perplexity)
对于指定的测试集,困惑度定义为测试集中每一个词概率的几何平均数的倒数,公式如下:
PPL
(
D
t
e
s
t
)
=
1
P
(
w
1
,
w
2
.
.
.
w
n
)
n
\operatorname{PPL}(\mathbb{D}_{test}) = \frac{1}{\sqrt[n]{P(w_1,w_2…w_n)}}
PPL
(
D
t
es
t
)
=
n
P
(
w
1
,
w
2
…
w
n
)
1
把
P
(
w
1
,
w
2
,
.
.
.
w
t
)
=
∏
i
=
1
t
−
1
P
(
w
i
∣
w
i
−
1
)
P(w_1,w_2,…w_t) = \displaystyle\prod_{i=1}^{t-1}P(w_i|w_{i-1})
P
(
w
1
,
w
2
,
…
w
t
)
=
i
=
1
∏
t
−
1
P
(
w
i
∣
w
i
−
1
)
带入上述公式,就得到了 PPL 的计算公式:
PPL
(
D
t
e
s
t
)
=
(
∏
i
=
1
n
P
(
w
i
∣
w
1
:
i
−
1
)
)
−
1
n
\operatorname{PPL}(\mathbb{D}_{test}) = (\displaystyle\prod_{i=1}nP(w_i|w_{1:i-1})){-\frac{1}{n}}
PPL
(
D
t
es
t
)
=
(
i
=
1
∏
n
P
(
w
i
∣
w
1
:
i
−
1
)
)
−
n
1
1.3、回退(Back-off)
在多元文法模型中,比如以 3-gram 为例,如果出现某些三元语法概率为零,则不使用零来表示概率,而回退到 2-gram,如下。
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
=
{
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
C
(
w
i
−
2
w
i
−
1
w
i
)
0
P
(
w
i
∣
w
i
−
1
)
C
(
w
i
−
2
w
i
−
1
w
i
)
=
0
a
n
d
C
(
w
i
−
1
w
i
)
0
P(w_i|w_{i-2}w_{i-1}) = \begin{cases} P(w_i|w_{i-2}w_{i-1}) & C(w_{i-2}w_{i-1}w_i) > 0 \ P(w_i|w_{i-1}) & C(w_{i-2}w_{i-1}w_i) = 0 \enspace and \enspace C(w_{i-1}w_i) > 0 \end{cases}
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
=
{
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
P
(
w
i
∣
w
i
−
1
)
C
(
w
i
−
2
w
i
−
1
w
i
)
0
C
(
w
i
−
2
w
i
−
1
w
i
)
=
0
an
d
C
(
w
i
−
1
w
i
)
0
1.4、差值(Interpolation)
N 元文法模型如果用回退法,则只考虑了 n-gram 概率为 0 时回退为 n-1 gram,那么自然要问:n-gram 不为零时,是不是也可以按一定权重来考虑 n-1 gram?于是有了插值法。以 3-gram 为例,把 2-gram、1-gram 都考虑进来:
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
=
λ
1
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
λ
2
P
(
w
i
∣
w
i
−
1
)
λ
3
P
(
w
i
)
P(w_i|w_{i-2}w_{i-1}) = \lambda_1 P(w_i|w_{i-2}w_{i-1}) + \lambda_2 P(w_i|w_{i-1}) + \lambda_3 P(w_i)
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
=
λ
1
P
(
w
i
∣
w
i
−
2
w
i
−
1
)
λ
2
P
(
w
i
∣
w
i
−
1
)
λ
3
P
(
w
i
)
第 2 节 · 感知器(Perceptron)
N 元文法模型的显著问题,在「马尔科夫假设与 N 元文法语言模型」小节已经提到了。这些问题基本在神经网络模型中被解决,而要了解神经网络模型,就要从感知器(Perceptron)开始。1957 年感知机模型被提出,1959 年多层感知机(MLP)模型被提出。MLP 有时候也被称为 ANN,即 Artificial Neural Network,接下来我们来深入浅出地了解一下,并有一些动手的练习。
2.1、感知器(Perceptron):解决二元分类任务的前馈神经网络
x 是一个输入向量,w 是一个权重向量(对输入向量里的而每个值分配一个权重值所组成的向量)。举一个具体任务例子,比如如果这两个向量的内积超过某个值,则判断为 1,否则为 0,这其实就是一个分类任务。那么这个最终输出值可以如下表示:
y
=
{
1
(
ω
⋅
x
≥
0
)
0
(
ω
⋅
x
<
0
)
y = \begin{cases} 1 & (\omega \cdot x \geq 0) \ 0 & (\omega \cdot x \lt 0) \end{cases}
y
=
{
1
0
(
ω
⋅
x
≥
0
)
(
ω
⋅
x
<
0
)
这就是一个典型的感知器(Perceptron),一般用来解决分类问题。还可以再增加一个偏差项(bias),如下:
y
=
{
1
(
ω
⋅
x
b
≥
0
)
0
(
ω
⋅
x
b
<
0
)
y = \begin{cases} 1 & (\omega \cdot x + b \geq 0) \ 0 & (\omega \cdot x + b \lt 0) \end{cases}
y
=
{
1
0
(
ω
⋅
x
b
≥
0
)
(
ω
⋅
x
b
<
0
)
感知器其实就是一个前馈神经网络,由输入层、输出层组成,没有隐藏层。而且输出是一个二元函数,用于解决二元分类问题。
2.2、线性回归(Linear Regression):从离散值的感知器(解决类问题),到连续值的线性回归(解决回归问题)
一般来说,我们认为感知器的输出结果,是离散值。一般来说,我们认为离散值作为输出解决的问题,是分类问题;相应地,连续值解决的问题是回归(Regression)。比如对于上面的感知器,如果我们直接将
ω
⋅
x
b
\omega \cdot x + b
ω
⋅
x
b
作为输出值,则就变成了一个线性回归问题的模型了。
下面我们用 PyTorch 来实现一个线性回归的代码示例,首先我们要了解在 PyTorch 库里有一个非常常用的函数:
nn.Linear(in_features, out_features)
这个函数在创建时会自动初始化权值和偏置,并且可以通过调用它的
forward
函数来计算输入数据的线性变换。具体来说,当输入为
x
时,
forward
函数会计算
y
=
ω
⋅
x
b
y = \omega \cdot x + b
y
=
ω
⋅
x
b
,其中
W
W
W
和
b
b
b
分别是
nn.Linear
图层的权值和偏置。
我们来一个完整的代码示例:
import torch
import torch.nn as nn
# 定义模型
class LinearRegression(nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(input_size, output_size)
def forward(self, x):
return self.linear(x)
# 初始化模型
model = LinearRegression(input_size=1, output_size=1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 创建输入特征 X 和标签 y
X = torch.Tensor([[1], [2], [3], [4]])
y = torch.Tensor([[2], [4], [6], [8]])
# 训练模型
for epoch in range(100):
# 前向传播,在本文 2.7 节有详细介绍
predictions = model(X)
loss = criterion(predictions, y)
# 反向传播,在本文 2.7 节有详细介绍
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 创建测试数据 X_test 和标签 y_test
X_test = torch.Tensor([[5], [6], [7], [8]])
y_test = torch.Tensor([[10], [12], [14], [16]])
# 测试模型
with torch.no_grad():
predictions = model(X_test)
loss = criterion(predictions, y_test)
print(f'Test loss: {loss:.4f}')
上述代码,一开始先创建一个
LinearRegression
线性回归模型的类,其中有一个
forward
前向传播函数,调用时其实就是计算一下输出值
y
。
主程序,一开始创建一个线性回归模型实例,然后定义一个用于评价模型效果的损失函数评价器,和用随机梯度下降(Stochastic Gradient Descent)作为优化器。
然后创建一个输入特征张量,和标签张量。用这组特征和标签进行训练,训练的过程就是根据
X
计算与测试
predictions
向量,再把它和
y
一起给评价器算出损失
loss
,然后进行反向传播(在本文 2.7 节有介绍)。注意反向传播的三行代码:
optimizer.zero_grad()
loss.backward()
optimizer.step()
如此训练 100 次(每一次都会黑盒化地更新模型的参数,一个
epoch
就是一次训练过程,有时也称为
iteration
或者
step
,不断根据
loss
训练优化模型参数。
然后我们创建了一组测试特征值张量
X_test
,和测试标签张量
y_test
,然后用它们测试模型性能,把测试特征得到的
predictions
与
y_test
共同传给评价器,得到
loss
。在这个例子中我们会得到如下结果:
Test loss: 0.0034
2.3、逻辑回归(Logistic Regression):没有值域约束的线性回归,到限定在一个范围内的逻辑回归(常用于分类问题)
可以看到线性回归问题,输出值是没有范围限定的。如果限定(limit)在特定的
(
0
,
L
)
(0, L)
(
0
,
L
)
范围内,则就叫做逻辑回归了。那么如何将一个线性回归变成逻辑回归呢?一般通过如下公式变换:
y
=
L
1
e
−
k
(
z
−
z
0
)
y = \frac{L}{1 + e^{-k(z-z_0)}}
y
=
1
e
−
k
(
z
−
z
0
)
L
这样原来的
z
∈
(
−
∞
,
∞
)
z \in (-\infty, +\infty)
z
∈
(
−
∞
,
∞
)
就被变换成了
y
∈
(
0
,
L
)
y \in (0, L)
y
∈
(
0
,
L
)
了。
- 激活函数
:这种把输出值限定在一个目标范围内的函数,被叫做
激活函数(Activation Function)
。 - 函数的陡峭程度
由
k
k
k
控制,越大越陡。
- 当
z
=
z
0
z = z_0
z
=
z
0
时,
y
=
L
2
y = \frac{L}{2}
y
=
2
L
。
下面给出一个基于 Python 的 scikit-learn 库的示例代码:
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 这是 scikit-learn 库里的一个简单的数据集
iris = load_iris()
# 把 iris 数据集拆分成训练集和测试集两部分
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.25, random_state=42)
# 用 scikit-learn 库创建一个逻辑回归模型的实例
lr = LogisticRegression()
# 用上边 split 出来的训练集数据,训练 lr 模型实例
lr.fit(X_train, y_train)
# 用训练过的模型,拿测试集的输入数据做测试
predictions = lr.predict(X_test)
# 用测试集的数据验证精确性
accuracy = lr.score(X_test, predictions)
print(accuracy)
2.4、Sigmoid 回归(Sigmoid Regression):归一化的逻辑回归,一般用于二元分类任务
当
L
=
1
,
k
=
1
,
z
0
=
0
L = 1, k = 1, z_0 = 0
L
=
1
,
k
=
1
,
z
0
=
0
,此时的激活函数就是
S
i
g
m
o
i
d
Sigmoid
S
i
g
m
o
i
d
函数,也常表示为
σ
\sigma
σ
函数,如下:
y
=
1
1
e
−
z
y = \frac{1}{1 + e^{-z}}
y
=
1
e
−
z
1
Sigmoid 回归的值域,恰好在 (0, 1) 之间,所以常备作为用来归一化的激活函数。而一个线性回归模型,再用 sigmoid 函数归一化,这种也常被称为「Sigmoid 回归」。Sigmoid 这个单词的意思也就是 S 形,我们可以看下它的函数图像如下:

因为归一化,所以也可以把输出值理解为一个概率。比如我们面对一个二元分类问题,那么输出结果就对应属于这个类别的概率。
这样一个 sigmoid 模型可以表示为:
y
=
S
i
g
m
o
i
d
(
W
⋅
x
b
)
y = Sigmoid(W \cdot x + b)
y
=
S
i
g
m
o
i
d
(
W
⋅
x
b
)
另外
s
i
g
m
o
i
d
sigmoid
s
i
g
m
o
i
d
函数的导数(即梯度)是很好算的:
y
′
=
y
⋅
(
1
−
y
)
y’ = y \cdot (1-y)
y
′
=
y
⋅
(
1
−
y
)
。这非常方便用于「梯度下降算法」根据 loss 对模型参数进行优化。Sigmoid 回归,一般用于二元分类任务。那么对于超过二元的情况怎么办呢?这就引出了下面的 Softmax 回归。
2.5、Softmax 回归(Softmax Regression):从解决二元任务的 sigmoid,到解决多元分类任务的 Softmax
相对逻辑回归,Softmax 也称为多项逻辑回归。上面说 Sigmoid 一般用于解决二元分类问题,那么多元问题就要用 Softmax 回归了。我们来拿一个具体问题来解释,比如问题是对于任意输入的一个电商商品的图片,来判断这个图片所代表的的商品,属于哪个商品类目。假设我们一共有 100 个类目。那么一个图片比如说其所有像素值作为输入特征值,输出就是一个 100 维的向量
**z
z
z**
,输出向量中的每个值
z
i
z_i
z
i
表示属于相对应类目的概率
y
i
y_i
y
i
:
y
i
=
S
o
f
t
m
a
x
(
z
)
i
=
e
z
i
e
z
1
e
z
2
.
.
.
e
z
1
00
y_i = Softmax(z)_i = \frac{e{z_i}}{e{z_1} + e^{z_2} + … + e^{z_100}}
y
i
=
S
o
f
t
ma
x
(
z
)
i
=
e
z
1
e
z
2
…
e
z
1
00
e
z
i
那么最后得到的
y
y
y
向量中的每一项就对应这个输入
z
z
z
属于这 100 个类目的各自概率了。所以如果回归到一般问题,这个 Softmax 回归的模型就如下:
y
=
S
o
f
t
m
a
x
(
W
⋅
x
b
)
y = Softmax(W \cdot x + b)
y
=
S
o
f
t
ma
x
(
W
⋅
x
b
)
对于上面电商商品图片的例子,假设每个图片的尺寸是 512x512,这个模型展开式如下:
[
y
1
y
2
.
.
.
y
100
]
=
S
o
f
t
m
a
x
(
[
w
1
,
1
,
w
1
,
2
,
.
.
.
w
1
,
512
w
2
,
1
,
w
2
,
2
,
.
.
.
w
2
,
512
.
.
.
.
.
.
.
.
.
.
.
.
w
100
,
1
,
w
100
,
2
,
.
.
.
w
100
,
512
]
⋅
[
x
1
x
2
.
.
.
x
512
]
[
b
1
b
2
.
.
.
b
512
]
)
\begin{bmatrix} y_1 \ y_2 \ … \ y_{100} \end{bmatrix} = Softmax(\begin{bmatrix} w_{1,1}, & w_{1,2}, & … & w_{1, 512} \ w_{2,1}, & w_{2,2}, & … & w_{2, 512} \ … & … & … & … \ w_{100,1}, & w_{100,2}, & … & w_{100, 512} \end{bmatrix} \cdot \begin{bmatrix} x_1 \ x_2 \ … \ x_{512} \end{bmatrix} + \begin{bmatrix} b_1 \ b_2 \ … \ b_{512} \end{bmatrix})
y
1
y
2
…
y
100
=
S
o
f
t
ma
x
(
w
1
,
1
,
w
2
,
1
,
…
w
100
,
1
,
w
1
,
2
,
w
2
,
2
,
…
w
100
,
2
,
…
…
…
…
w
1
,
512
w
2
,
512
…
w
100
,
512
⋅
x
1
x
2
…
x
512
b
1
b
2
…
b
512
)
这个对输入向量
x
x
x
执行
w
⋅
x
b
w \cdot x + b
w
⋅
x
b
运算,一般也常称为「线性映射/线性变化」。
2.6、多层感知器(Multi-Layer Perceptron)
上面我们遇到的所有任务,都是用线性模型(Linear Models)解决的。有时候问题复杂起来,我们就要引入非线性模型了。
这里我们要介绍一个新的激活函数 ——
R
e
L
U
ReLU
R
e
LU
(Rectified Linear Unit)—— 一个非线性激活函数,其定义如下:
R
e
L
U
(
z
)
=
m
a
x
(
0
,
z
)
ReLU(z) = max(0, z)
R
e
LU
(
z
)
=
ma
x
(
0
,
z
)
比如对于 MNIST 数据集的手写数字分类问题,就是一个典型的非线性的分类任务,下面给出一个示例代码:
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# 定义多层感知器模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 超参数
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 5
batch_size = 100
learning_rate = 0.001
# 加载 MNIST 数据集
train_dataset = datasets.MNIST(root='../../data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='../../data',
train=False,
transform=transforms.ToTensor())
# 数据加载器
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
model = MLP(input_size, hidden_size, num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
for epoch in range(num_epochs):
for images, labels in train_loader:
# 前向传播
outputs = model(images)
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 输出训练损失
print(f'Epoch {epoch + 1}, Training Loss: {loss.item():.4f}')
这段代码里,我们能看到 MLP 的模型定义是:
nn.Linear(input_size, hidden_size)
nn.ReLU()
nn.Linear(hidden_size, num_classes)
与前面的模型示例代码类似,也都用到了本文 2.7 节我会介绍的反向传播、损失函数评价器、优化器。如果用公式表示的话,就是如下的模型定义:
z
=
W
1
⋅
x
b
1
h
=
R
e
L
U
(
z
)
y
=
W
2
⋅
h
b
2
\begin{aligned} &z = W_1 \cdot x + b_1 \ &h = ReLU(z) \ &y = W_2 \cdot h + b_2 \end{aligned}
z
=
W
1
⋅
x
b
1
h
=
R
e
LU
(
z
)
y
=
W
2
⋅
h
b
2
我们知道 MLP 通常是一个输入和输出长度相同的模型,但少数情况下也可以构建输入和输出长度不同的 MLP 模型,比如输入一组序列后,输出是一个离散的分类结果。
2.7、简述如何训练一个模型:前向传播与反向传播
这是个很重要的议题。但是春节时间有限,这部分只能简写了,我们更多聚焦在语言模型本身。这里简述一下,后续可能会再补全。
- 训练神经网络,主要包括前向传播、反向传播这两步。
- 前向传播,就是将数据输入给模型,基于已确定的一组参数(比如 MLP 中的权重 W、偏置 b 等),得到输出结果。根据输出结果计算损失函数,衡量当前参数下的模型性能。
- 反向传播最常用到的是梯度下降法(这里不讨论其他方法),依托损失函数,将其中的参数当做变量来求偏导(计算梯度),沿着梯度下降的方向求解损失函数的极小值,此时的参数可替代此前的参数。这就是对模型优化训练的一个典型过程。
引申问题 —— 梯度消失、梯度爆炸问题:因为对损失函数的求偏导,是从输出层向输入层反向基于「数学上的链式法则」计算的,数学上这是个连乘计算,层数越多越容易出现这个问题。这个求导过程可能会出现梯度为零的情况,即梯度消失。也有可能出现梯度值特别大的情况。
解决梯度消失、梯度爆炸问题,又是一个重要议题,这里篇幅所限也难以展开做技术笔记。粗暴的方式比如梯度剪切,Hinton 提出的逐层预训练后再整体精调理论上也 work,本文后续提到的 LSTM、ResNet 等也可以解决问题,我们也还能了解到业界各种解决手段,有机会再与朋友们交流学习。
2.8、MLP 的一个显著问题,帮我们引出 CNN 模型
我们可以看到,在 MLP 中,不论有多少层,某一层的输出向量
h
n
h_n
h
n
中的每个值,都会在下一层计算输出向量
h
n
1
h_{n+1}
h
n
1
的每个值时用到。具体来说,如果对于某一层的输出值如下:
h
n
1
=
S
o
f
t
m
a
x
(
W
n
1
⋅
h
n
b
n
1
)
h_{n+1} = Softmax(W_{n+1} \cdot h_n + b_{n+1})
h
n
1
=
S
o
f
t
ma
x
(
W
n
1
⋅
h
n
b
n
1
)
上一段话里所谓的「用到」,其实就是要针对
h
n
h_n
h
n
生成相应的特征值
W
n
1
W_{n+1}
W
n
1
权重矩阵中的每个行列里的数值和
b
n
1
b_{n+1}
b
n
1
偏差向量里的每个值。如果用图画出来,就是:

可以看到,输入的所有元素都被连接,即被分配权重 w 和偏差项 b,所以这被称为一个「全连接层(
Fully Connected Layer
)」或者「
稠密层(Dense Layer)
」。但是对于一些任务这样做是很蠢的,会付出大量无效的计算。
因此我们需要 focus 在更少量计算成本的模型,于是有了卷积神经网络(CNN)。
第 3 节 · 卷积神经网络(CNN)
MLP 里每一层的每个元素,都要乘以一个独立参数的权重 W,再加上一个偏执 b,这样的神经网络层常被我们叫做「全连接层(Fully Connected Layer)或稠密层(Dence Layer)。但是这样有个显著问题:如果输入内容的局部重要信息只是发生轻微移动并没有丢失,在全连接层处理后,整个输出结果都会发生很大变化 —— 这不合理。
于是我们会想到,如果我们用一个小一些的全连接层,只对重要的局部输入进行处理呢?其实这个思路和 n-gram 是类似的,都是用一个窗口来扫描局部。卷积神经网络(Convolutional Neural Network,CNN)就是基于此诞生的。
- 卷积核:卷积核是一个小的稠密层,用于提取局部特征,又称其为卷积核(kernel)/ 滤波器(filter)/ 感受野(receptive field / field of view)。
- 池化层(Pooling,或称汇聚层):经过卷积核处理的结果,进一步聚合的过程。对于输入大小不一样的样本,池化后将有相同个数的特征输出。
- 提取多个局部特征:一个卷积核只能提取单一类型的局部特征,需要提取多种局部特征则需要多个卷积核。有些文章里你看提到「多个模式」、「多个通道」,其实指的就是多个 kernel 识别多个特征。
- 全连接分类层:多个卷积核得到的多个特征,需经过一个全连接的分类层用于最终决策。
这样做有几个特性:
- 本地性(Locality):输出结果只由一个特定窗口大小区域内的数据决定。
- 平移不变性(Translation Invariant):对同一个特征,扫描不同区域时只用一个 kernel 来计算。
- 卷积层的参数规模,与输入输出数据大小无关。
CNN 主要的适用领域是计算机视觉。而在 NLP 中,文本数据的维度很高,并且语言的结构比图像更复杂。因此,CNN 一般不适用于处理 NLP 问题。
第 4 节 · 循环神经网络(RNN)
RNN(循环神经网络),这是一种强大的神经网络模型,能够预测序列数据,例如文本、语音和时间序列。我们将通过生动的代码示例和实际案例来演示如何使用 RNN,并在日常生活中真实地体验它的功能。您将学习到如何使用 RNN 解决各种机器学习问题,并动手尝试运用 RNN 解决实际问题。这篇文章将为您提供一个完整的 RNN 入门指南,并使您对 RNN 有更深入的了解。
RNN(Recurrent Neural Network)的 R 是 Recurrent 的意思,所以这是一个贷循环的神经网络。首先要明白一点,你并不需要搞懂 CNN 后才能学习 RNN 模型。你只要了解了 MLP 就可以学习 RNN 了。
4.1、经典结构的 RNN

上图这是一个经典结构的 RNN 示意图,Unfold 箭头右侧是展开示意。输入序列(这里用
x
x
x
表示)传递给隐藏层(hidden layer,这里用
h
h
h
表示),处理完生成输出序列(这里用
o
o
o
表示)。序列的下一个词输入时的、上一步隐藏层会一起影响这一步的输出。
U
U
U
、
V
V
V
、
W
W
W
都表示权重。在这个经典结构理,你可以看到非常重要的一点,就是输入序列长度与输出序列长度是相同的。
这种经典结构的应用场景,比如对一段普通话输入它的四川话版本,比如对视频的每一帧进行处理并输出,等等。
我们知道 RNN 是一个一个序列处理的,每个序列中的数据项都是有序的,所以对于计算一个序列内的所有数据项是无法并行的。但是计算不同序列时,不同序列各自的计算则是可以并行的。如果我们把上一个时刻 t 隐藏层输出的结果
h
t
−
1
h_{t-1}
h
t
−
1
传给一个激活函数(比如说用正切函数
tanh
函数),然后和当下时刻 t 的这个输入
x
t
x_{t}
x
t
一起,处理后产生一个时刻
t
t
t
的输出
h
t
h_t
h
t
。然后把隐藏层的输出通过多项逻辑回归(Softmax)生成最终的输出值
y
y
y
,我们可以如下表示这个模型:
h
t
=
t
a
n
h
(
W
x
h
⋅
x
t
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
y
t
=
S
o
f
t
m
a
x
(
W
h
y
⋅
h
t
b
h
y
)
\begin{aligned} &h_t = tanh(W^{xh} \cdot x_t + b^{xh} + W^{hh} \cdot h_{t-1} + b^{hh}) \ &y_t = Softmax(W^{hy} \cdot h_t + b^{hy}) \end{aligned}
h
t
=
t
anh
(
W
x
h
⋅
x
t
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
y
t
=
S
o
f
t
ma
x
(
W
h
y
⋅
h
t
b
h
y
)
对应的示意图如下:

这种输入和输出数据项数一致的 RNN,一般叫做 N vs. N 的 RNN。如果我们用 PyTorch 来实现一个非常简单的经典 RNN 则如下:
import torch
import torch.nn as nn
# 创建一个 RNN 实例
# 第一个参数
rnn = nn.RNN(10, 20, 1, batch_first=True) # 实例化一个单向单层RNN
# 输入是一个形状为 (5, 3, 10) 的张量
# 5 个输入数据项(也可以说是样本)
# 3 个数据项是一个序列,有 3 个 steps
# 每个 step 有 10 个特征
input = torch.randn(5, 3, 10)
# 隐藏层是一个 (1, 5, 20) 的张量
h0 = torch.randn(1, 5, 20)
# 调用 rnn 函数后,返回输出、最终的隐藏状态
output, hn = rnn(input, h0)
print(output)
print(hn)
我们来解读一下这段代码:
- 这段代码实例化了一个带有 1 个隐藏层的 RNN 网络。
- 它的输入是一个形状为 (5, 3, 10) 的张量,表示有 5 个样本,每个样本有 3 个时间步,每个时间步的特征维度是 10。
- 初始隐藏状态是一个形状为 (1, 5, 20) 的张量。
- 调用 rnn 函数后,会返回输出和最终的隐藏状态。
- 输出的形状是 (5, 3, 20),表示有 5 个样本,每个样本有 3 个时间步,每个时间步的输出维度是 20。
- 最终的隐藏状态的形状是 (1, 5, 20),表示最后的隐藏状态是 5
但是上面的代码示例,并没有自己编写一个具体的 RNN,而是用了默认的 PyTorch 的 RNN,那么下面我们就自己编写一个:
class MikeCaptainRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
# 对于 RNN,输入维度就是序列数
self.input_size = input_size
# 隐藏层有多少个节点/神经元,经常将 hidden_size 设置为与序列长度相同
self.hidden_size = hidden_size
# 输入层到隐藏层的 W^{xh} 权重、bias^{xh} 偏置项
self.weight_xh = torch.randn(self.hidden_size, self.input_size) * 0.01
self.bias_xh = torch.randn(self.hidden_size)
# 隐藏层到隐藏层的 W^{hh} 权重、bias^{hh} 偏置项
self.weight_hh = torch.randn(self.hidden_size, self.hidden_size) * 0.01
self.bias_hh = torch.randn(self.hidden_size)
# 前向传播
def forward(self, input, h0):
# 取出这个张量的形状
N, L, input_size = input.shape
# 初始化一个全零张量
output = torch.zeros(N, L, self.hidden_size)
# 处理每个时刻的输入特征
for t in range(L):
# 获得当前时刻的输入特征,[N, input_size, 1]。unsqueeze(n),在第 n 维上增加一维
x = input[:, t, :].unsqueeze(2)
w_xh_batch = self.weight_xh.unsqueeze(0).tile(N, 1, 1) # [N, hidden_size, input_size]
w_hh_batch = self.weight_hh.unsqueeze(0).tile(N, 1, 1) # [N, hidden_size, hidden_size]
# bmm 是矩阵乘法函数
w_times_x = torch.bmm(w_xh_batch, x).squeeze(-1) # [N, hidden_size]。squeeze(n),在第n维上减小一维
w_times_h = torch.bmm(w_hh_batch, h0.unsqueeze(2)).squeeze(-1) # [N, hidden_size]
h0 = torch.tanh(w_times_x + self.bias_ih + w_times_h + self.bias_hh)
output[:, t, :] = h0
return output, h0.unsqueeze(0)
源码解读都在注释中。
4.2、N vs.1 的 RNN
上面那个图里,如果只保留最后一个输出,那就是一个 N vs. 1 的 RNN 了。这种的应用场景,比如说判断一个文本序列是英语还是德语,比如根据一个输入序列来判断是一个正向情绪内容还是负向或者中性,或者比如根据一段语音输入序列来判断是哪一首曲子(听歌识曲)。
h
t
=
t
a
n
h
(
W
x
h
⋅
x
t
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
y
=
S
o
f
t
m
a
x
(
W
h
y
⋅
h
n
b
h
y
)
\begin{aligned} &h_t = tanh({W^{xh}} \cdot x_t + {b^{xh}} + {W^{hh}} \cdot h_{t-1} + {b^{hh}}) \ &y = Softmax({W^{hy}} \cdot h_n + {b^{hy}}) \end{aligned}
h
t
=
t
anh
(
W
x
h
⋅
x
t
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
y
=
S
o
f
t
ma
x
(
W
h
y
⋅
h
n
b
h
y
)
即这个模型里,每个序列只有隐藏层对最后一个数据项进行处理时才产生输出
h
n
h_n
h
n
如果用示意图表示,则是如下结构:

4.3、1 vs. N 的 RNN
反过来,上面那个图里,如果只保留一个 x,那么就是一个 1 vs. N 的 RNN 了。这种场景的应用,比如 AI 创作音乐,还有通过一个 image 提炼或识别某些文本内容输出。
h
t
=
{
t
a
n
h
(
W
x
h
⋅
x
b
x
h
0
b
h
h
)
(
t
=
1
)
t
a
n
h
(
0
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
(
t
1
)
y
t
=
S
o
f
t
m
a
x
(
W
h
y
⋅
h
t
b
h
y
)
\begin{aligned} &h_t = \begin{cases} tanh(W^{xh} \cdot x + b^{xh} + 0 + b^{hh}) & (t=1) \ tanh(0 + b^{xh} + W^{hh} \cdot h_{t-1} + b^{hh}) & (t>1) \end{cases} \ &y_t = Softmax(W^{hy} \cdot h_t + b^{hy}) \end{aligned}
h
t
=
{
t
anh
(
W
x
h
⋅
x
b
x
h
0
b
hh
)
t
anh
(
0
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
(
t
=
1
)
(
t
1
)
y
t
=
S
o
f
t
ma
x
(
W
h
y
⋅
h
t
b
h
y
)
示意图如下:

到这里我们可以看到,在 RNN 的隐藏层是能够存储一些有关于输入数据的一些相关内容的,所以也常把 RNN 的隐藏层叫做记忆单元。
4.4、LSTM(Long Short-Term Memory)长短时记忆网络
4.4.1、如何理解这个 Short-Term 呢?
1997 年论文《Long Short-Term Memory》中提出 LSTM 模型。我们先从模型的定义,精确地来理解一下:
h
t
=
h
t
−
1
t
a
n
h
(
W
x
h
⋅
x
t
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
y
t
=
S
o
f
t
m
a
x
(
W
h
y
⋅
h
t
b
h
y
)
\begin{aligned} &h_t = h_{t-1} + tanh(W^{xh} \cdot x_t + b^{xh} + W^{hh} \cdot h_{t-1} + b^{hh}) \ &y_t = Softmax(W^{hy} \cdot h_t + b^{hy}) \end{aligned}
h
t
=
h
t
−
1
t
anh
(
W
x
h
⋅
x
t
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
y
t
=
S
o
f
t
ma
x
(
W
h
y
⋅
h
t
b
h
y
)
上式中与经典结构的 RNN(输入与输出是 N vs. N)相比,唯一的区别是第一个式子中多了一个「
h
t
−
1
h_{t-1}
h
t
−
1
」。如果我们把第一个式子的
t
a
n
h
tanh
t
anh
部分记作
u
t
u_t
u
t
:
u
t
=
t
a
n
h
(
W
x
h
⋅
x
t
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
u_t = tanh(W^{xh} \cdot x_t + b^{xh} + W^{hh} \cdot h_{t-1} + b^{hh})
u
t
=
t
anh
(
W
x
h
⋅
x
t
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
所以:
h
t
=
h
t
−
1
u
t
h_t = h_{t-1} + u_t
h
t
=
h
t
−
1
u
t
那么可以展开出如下一组式子:
h
k
1
=
h
k
u
k
1
h
k
2
=
h
k
1
u
k
2
.
.
.
.
.
.
h
t
−
1
=
h
t
−
2
u
t
−
1
h
t
=
h
t
−
1
u
t
\begin{aligned} h_{k+1} &= h_k + u_{k+1} \ h_{k+2} &= h_{k+1} + u_{k+2} \ &… \ h_{t-1} &= h_{t-2} + u_{t-1} \ h_t &= h_{t-1} + u_t \end{aligned}
h
k
1
h
k
2
h
t
−
1
h
t
=
h
k
u
k
1
=
h
k
1
u
k
2
…
=
h
t
−
2
u
t
−
1
=
h
t
−
1
u
t
如果我们从
h
k
1
h_{k+1}
h
k
1
到
h
n
h_n
h
n
的所有式子左侧相加、右侧相加,我们就得到如下式子:
h
k
1
.
.
.
h
t
−
1
h
t
=
h
k
h
k
1
.
.
.
h
t
−
2
h
t
−
1
u
k
1
u
k
2
.
.
.
u
t
−
1
u
t
\begin{aligned} &h_{k+1} + … + h_{t-1} + h_t \ = &h_k + h_{k+1} + … + h_{t-2} + h_{t-1} \+ &u_{k+1} + u_{k+2} + … + u_{t-1} + u_t \end{aligned}
=
h
k
1
…
h
t
−
1
h
t
h
k
h
k
1
…
h
t
−
2
h
t
−
1
u
k
1
u
k
2
…
u
t
−
1
u
t
进而推导出:
h
t
=
h
k
u
k
1
u
k
2
.
.
.
u
t
−
1
u
t
h_t = h_k + u_{k+1} + u_{k+2} + … + u_{t-1} + u_t
h
t
=
h
k
u
k
1
u
k
2
…
u
t
−
1
u
t
从这里我们就可以看到,第 t 时刻的隐藏层输出,直接关联到第 k 时刻的输出,t 到 k 时刻的相关性则用
u
k
1
u_{k+1}
u
k
1
到
u
t
u_t
u
t
相加表示。也就是有 t-k 的短期(Short Term)记忆。
4.4.2、引入遗忘门 f、输入门 i、输出门 o、记忆细胞 c
如果我们为式子
h
t
=
h
t
−
1
u
t
h_t = h_{t-1} + u_t
h
t
=
h
t
−
1
u
t
右侧两项分配一个权重呢?就是隐藏层对上一个数据项本身被上一个数据项经过隐藏层计算的结果,这两者做一对权重考虑配比,如下:
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
h
h
⋅
x
t
−
1
b
f
,
h
h
)
h
t
=
f
t
⊙
h
t
−
1
(
1
−
f
t
)
⊙
u
t
\begin{aligned} &f_t = sigmoid(W^{f,xh} \cdot x_t + b^{f,xh} + W^{f,hh} \cdot x_{t-1} + b^{f,hh}) \ &h_t = f_t \odot h_{t-1} + (1 - f_t) \odot u_t \end{aligned}
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
hh
⋅
x
t
−
1
b
f
,
hh
)
h
t
=
f
t
⊙
h
t
−
1
(
1
−
f
t
)
⊙
u
t
其中:
- ⊙
\odot
⊙
是 Hardamard 乘积,即张量的对应元素相乘。
- f
t
f_t
f
t
是「遗忘门(Forget Gate)」,该值很小时 t-1 时刻的权重就很小,也就是「此刻遗忘上一刻」。该值应根据 t 时刻的输入数据、t-1 时刻数据在隐藏层的输出计算,而且其每个元素必须是 (0, 1) 之间的值,所以可以用 sigmoid 函数来得到该值:
但这种方式,对于过去
h
t
−
1
h_{t-1}
h
t
−
1
和当下
u
t
u_t
u
t
形成了互斥,只能此消彼长。但其实过去和当下可能都很重要,有可能都恨不重要,所以我们对过去继续采用
f
t
f_t
f
t
遗忘门,对当下采用
i
t
i_t
i
t
输入门(Input Gate):
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
h
h
⋅
x
t
−
1
b
f
,
h
h
)
i
t
=
s
i
g
m
o
i
d
(
W
i
,
x
h
⋅
x
t
b
i
,
x
h
W
i
,
h
h
⋅
h
t
−
1
b
i
,
h
h
)
h
t
=
f
t
⊙
h
t
−
1
i
t
⊙
u
t
\begin{aligned} &f_t = sigmoid(W^{f,xh} \cdot x_t + b^{f,xh} + W^{f,hh} \cdot x_{t-1} + b^{f,hh}) \ &i_t = sigmoid(W^{i,xh} \cdot x_t + b^{i,xh} + W^{i,hh} \cdot h_{t-1} + b^{i,hh}) \ &h_t = f_t \odot h_{t-1} + i_t \odot u_t \end{aligned}
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
hh
⋅
x
t
−
1
b
f
,
hh
)
i
t
=
s
i
g
m
o
i
d
(
W
i
,
x
h
⋅
x
t
b
i
,
x
h
W
i
,
hh
⋅
h
t
−
1
b
i
,
hh
)
h
t
=
f
t
⊙
h
t
−
1
i
t
⊙
u
t
其中:
- 与
f
t
f_t
f
t
类似地,定义输入门
i
t
i_t
i
t
,但是注意
f
t
f_t
f
t
与
h
t
−
1
h_{t-1}
h
t
−
1
而非
x
t
−
1
x_{t-1}
x
t
−
1
有关。
再引入一个输出门:
o
t
=
s
i
g
m
o
i
d
(
W
o
,
x
h
⋅
x
t
b
o
,
x
h
W
o
,
h
h
⋅
x
t
−
1
b
o
,
h
h
)
o_t = sigmoid(W^{o,xh} \cdot x_t + b^{o,xh} + W^{o,hh} \cdot x_{t-1} + b^{o,hh})
o
t
=
s
i
g
m
o
i
d
(
W
o
,
x
h
⋅
x
t
b
o
,
x
h
W
o
,
hh
⋅
x
t
−
1
b
o
,
hh
)
再引入记忆细胞
c
t
c_t
c
t
,它是原来
h
t
h_t
h
t
的变体,与 t-1 时刻的记忆细胞有遗忘关系(通过遗忘门),与当下时刻有输入门的关系:
c
t
=
f
t
⊙
c
t
−
1
i
t
⊙
u
t
c_t = f_t \odot c_{t-1} + i_t \odot u_t
c
t
=
f
t
⊙
c
t
−
1
i
t
⊙
u
t
那么此时
h
t
h_t
h
t
,我们可以把
h
t
h_t
h
t
变成:
h
t
=
o
t
⊙
t
a
n
h
(
c
t
)
h_t = o_t \odot tanh(c_t)
h
t
=
o
t
⊙
t
anh
(
c
t
)
记忆细胞这个概念还有有一点点形象的,它存储了过去的一些信息。OK,到此我们整体的 LSTM 模型就变成了这个样子:
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
h
h
⋅
x
t
−
1
b
f
,
h
h
)
i
t
=
s
i
g
m
o
i
d
(
W
i
,
x
h
⋅
x
t
b
i
,
x
h
W
i
,
h
h
⋅
h
t
−
1
b
i
,
h
h
)
o
t
=
s
i
g
m
o
i
d
(
W
o
,
x
h
⋅
x
t
b
o
,
x
h
W
o
,
h
h
⋅
x
t
−
1
b
o
,
h
h
)
u
t
=
t
a
n
h
(
W
x
h
⋅
x
t
b
x
h
W
h
h
⋅
h
t
−
1
b
h
h
)
c
t
=
f
t
⊙
c
t
−
1
i
t
⊙
u
t
h
t
=
o
t
⊙
t
a
n
h
(
c
t
)
y
t
=
S
o
f
t
m
a
x
(
W
h
y
⋅
h
t
b
h
y
)
\begin{aligned} &f_t = sigmoid(W^{f,xh} \cdot x_t + b^{f,xh} + W^{f,hh} \cdot x_{t-1} + b^{f,hh}) \ &i_t = sigmoid(W^{i,xh} \cdot x_t + b^{i,xh} + W^{i,hh} \cdot h_{t-1} + b^{i,hh}) \ &o_t = sigmoid(W^{o,xh} \cdot x_t + b^{o,xh} + W^{o,hh} \cdot x_{t-1} + b^{o,hh}) \ &u_t = tanh(W^{xh} \cdot x_t + b^{xh} + W^{hh} \cdot h_{t-1} + b^{hh}) \ &c_t = f_t \odot c_{t-1} + i_t \odot u_t \ &h_t = o_t \odot tanh(c_t) \ &y_t = Softmax(W^{hy} \cdot h_t + b^{hy}) \end{aligned}
f
t
=
s
i
g
m
o
i
d
(
W
f
,
x
h
⋅
x
t
b
f
,
x
h
W
f
,
hh
⋅
x
t
−
1
b
f
,
hh
)
i
t
=
s
i
g
m
o
i
d
(
W
i
,
x
h
⋅
x
t
b
i
,
x
h
W
i
,
hh
⋅
h
t
−
1
b
i
,
hh
)
o
t
=
s
i
g
m
o
i
d
(
W
o
,
x
h
⋅
x
t
b
o
,
x
h
W
o
,
hh
⋅
x
t
−
1
b
o
,
hh
)
u
t
=
t
anh
(
W
x
h
⋅
x
t
b
x
h
W
hh
⋅
h
t
−
1
b
hh
)
c
t
=
f
t
⊙
c
t
−
1
i
t
⊙
u
t
h
t
=
o
t
⊙
t
anh
(
c
t
)
y
t
=
S
o
f
t
ma
x
(
W
h
y
⋅
h
t
b
h
y
)
4.5、双向循环神经网络、双向 LSTM
双向循环神经网络很好理解,就是两个方向都有,例如下图:

在 PyTorch 中使用
nn.RNN
就有参数表示双向:
bidirectional
– If True, becomes a bidirectional RNN. Default: False
bidirectional
:默认设置为
False
。若为
True
,即为双向 RNN。
4.6、堆叠循环神经网络(Stacked RNN)、堆叠长短时记忆网络(Stacked LSTM)

在 PyTorch 中使用
nn.RNN
就有参数表示双向:
num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1
num_layers
:隐藏层层数,默认设置为 1 层。当
num_layers
= 2 时,就是一个 stacked RNN 了。
4.7、N vs. M 的 RNN
对于输入序列长度(长度 N)和输出序列长度(长度 M)不一样的 RNN 模型结构,也可以叫做 Encoder-Decoder 模型,也可以叫 Seq2Seq 模型。首先接收输入序列的 Encoder 先将输入序列转成一个隐藏态的上下文表示 C。C 可以只与最后一个隐藏层有关,甚至可以是最后一个隐藏层生成的隐藏态直接设置为 C,C 还可以与所有隐藏层有关。
有了这个 C 之后,再用 Decoder 进行解码,也就是从把 C 作为输入状态开始,生成输出序列。

具体地,可以如下表示:
C
=
E
n
c
o
d
e
r
(
X
)
Y
=
D
e
c
o
d
e
r
(
C
)
\begin{aligned} &C = Encoder(X) \ &Y = Decoder© \ \end{aligned}
C
=
E
n
co
d
er
(
X
)
Y
=
Deco
d
er
(
C
)
进一步展开:
e
t
=
E
n
c
o
d
e
r
L
S
T
M
/
G
R
U
(
x
t
,
e
t
−
1
)
C
=
f
1
(
e
n
)
d
t
=
f
2
(
d
t
−
1
,
C
)
y
t
=
D
e
c
o
d
e
r
L
S
T
M
/
G
R
U
(
y
t
−
1
,
d
t
−
1
,
C
)
\begin{aligned} e_t &= Encoder_{LSTM/GRU}(x_t, e_{t-1}) \ C &= f_1(e_n) \ d_t &= f_2(d_{t-1}, C) \ y_t &= Decoder_{LSTM/GRU}(y_{t-1}, d_{t-1}, C) \end{aligned}
e
t
C
d
t
y
t
=
E
n
co
d
e
r
L
STM
/
GR
U
(
x
t
,
e
t
−
1
)
=
f
1
(
e
n
)
=
f
2
(
d
t
−
1
,
C
)
=
Deco
d
e
r
L
STM
/
GR
U
(
y
t
−
1
,
d
t
−
1
,
C
)
这种的应用就非常广了,因为大多数时候输入序列与输出序列的长度都是不同的,比如最常见的应用「翻译」,从一个语言翻译成另一个语言;再比如 AI 的一个领域「语音识别」,将语音序列输入后生成所识别的文本内容;还有比如 ChatGPT 这种问答应用等等。
Seq2Seq 模型非常出色,一直到 2018 年之前 NLP 领域里该模型已成为主流。但是它有很显著的问题:
- 当输入序列很长时,Encoder 生成的 Context 可能就会出现所捕捉的信息不充分的情况,导致 Decoder 最终的输出是不尽如人意的。具体地,毕竟还是 RNN 模型,其词间距过长时还是会有梯度消失问题,根本原因在于用到了「递归」。当递归作用在同一个 weight matrix 上时,使得如果这个矩阵满足条件的话,其最大的特征值要是小于 1 的话,就一定出现梯度消失问题。后来的 LSTM 和 GRU 也仅仅能缓解问题,并不能根本解决。
- 并行效果差:每个时刻的结果依赖前一时刻。
第 5 节 · 为什么说 RNN 模型没有体现「注意力」?
Encoder-Decoder 的一个非常严重的问题,是依赖中间那个 context 向量,则无法处理特别长的输入序列 —— 记忆力不足,会忘事儿。而忘事儿的根本原因,是没有「注意力」。
对于一般的 RNN 模型,Encoder-Decoder 结构并没有体现「注意力」—— 这句话怎么理解?当输入序列经过 Encoder 生成的中间结果(上下文 C),被喂给 Decoder 时,这些中间结果对所生成序列里的哪个词,都没有区别(没有特别关照谁)。这相当于在说:输入序列里的每个词,对于生成任何一个输出的词的影响,是一样的,而不是输出某个词时是聚焦特定的一些输入词。这就是模型没有注意力机制。
人脑的注意力模型,其实是资源分配模型。NLP 领域的注意力模型,是在 2014 年被提出的,后来逐渐成为 NLP 领域的一个广泛应用的机制。可以应用的场景,比如对于一个电商平台中很常见的白底图,其边缘的白色区域都是无用的,那么就不应该被关注(关注权重为 0)。比如机器翻译中,翻译词都是对局部输入重点关注的。
所以 Attention 机制,就是在 Decoder 时,不是所有输出都依赖相同的「上下文
C
t
C_t
C
t
」,而是时刻 t 的输出,使用
C
t
C_t
C
t
,而这个
C
t
C_t
C
t
来自对每个输入数据项根据「注意力」进行的加权。
第 6 节 · 基于 Attention 机制的 Encoder-Decoder 模型
2015 年 Dzmitry Bahdanau 等人在论文
《Neural Machine Translation by Jointly Learning to Align and Translate》
中提出了「Attention」机制,下面请跟着船长,麦克船长会深入浅出地为你解释清楚。
下图中
e
i
e_i
e
i
表示编码器的隐藏层输出,
d
i
d_i
d
i
表示解码器的隐藏层输出

更进一步细化关于
C
t
C_t
C
t
部分,船长在此引用《基于深度学习的道路短期交通状态时空序列预测》一书中的图:

这个图里的
h
~
i
\widetilde{h}_i
h
i
与上一个图里的
d
i
d_i
d
i
对应,
h
i
h_i
h
i
与上一个图里的
e
i
e_i
e
i
对应。
针对时刻
t
t
t
要产出的输出,隐藏层每一个隐藏细胞都与
C
t
C_t
C
t
有一个权重关系
α
t
,
i
\alpha_{t,i}
α
t
,
i
其中
1
≤
i
≤
n
1\le i\le n
1
≤
i
≤
n
,这个权重值与「输入项经过编码器后隐藏层后的输出
e
i
(
1
≤
i
≤
n
)
e_i(1\le i\le n)
e
i
(
1
≤
i
≤
n
)
、解码器的前一时刻隐藏层输出
d
t
−
1
d_{t-1}
d
t
−
1
」两者有关:
s
i
,
t
=
s
c
o
r
e
(
e
i
,
d
t
−
1
)
α
i
,
t
=
e
x
p
(
s
i
,
t
)
∑
j
=
1
n
e
x
p
(
s
j
,
t
)
\begin{aligned} &s_{i,t} = score(e_i,d_{t-1}) \ &\alpha_{i,t} = \frac{exp(s_{i,t})}{\textstyle\sum_{j=1}^n exp(s_{j,t})} \end{aligned}
s
i
,
t
=
score
(
e
i
,
d
t
−
1
)
α
i
,
t
=
∑
j
=
1
n
e
x
p
(
s
j
,
t
)
e
x
p
(
s
i
,
t
)
常用的
s
c
o
r
e
score
score
函数有:
- 点积(Dot Product)模型:
s
i
,
t
=
d
t
−
1
T
⋅
e
i
s_{i,t} = {d_{t-1}}^T \cdot e_i
s
i
,
t
=
d
t
−
1
T
⋅
e
i
- 缩放点积(Scaled Dot-Product)模型:
s
i
,
t
=
d
t
−
1
T
⋅
e
i
d
i
m
e
n
s
i
o
n
s
o
f
d
t
−
1
o
r
e
i
s_{i,t} = \frac{
{d_{t-1}}^T \cdot e_i}{\sqrt{\smash[b]{dimensions:of:d_{t-1}:or:e_i}}}
s
i
,
t
=
d
im
e
n
s
i
o
n
s
o
f
d
t
−
1
or
e
i
d
t
−
1
T
⋅
e
i
,可避免因为向量维度过大导致点积结果太大
然后上下文向量就表示成:
C
t
=
∑
i
=
1
n
α
i
,
t
e
i
\begin{aligned} &C_t = \displaystyle\sum_{i=1}^n \alpha_{i,t} e_i \end{aligned}
C
t
=
i
=
1
∑
n
α
i
,
t
e
i
还记得 RNN 那部分里船长讲到的 Encoder-Decoder 模型的公式表示吗?
e
t
=
E
n
c
o
d
e
r
L
S
T
M
/
G
R
U
(
x
t
,
e
t
−
1
)
C
=
f
1
(
e
n
)
d
t
=
f
2
(
d
t
−
1
,
C
)
y
t
=
D
e
c
o
d
e
r
L
S
T
M
/
G
R
U
(
y
t
−
1
,
d
t
−
1
,
C
)
\begin{aligned} e_t &= Encoder_{LSTM/GRU}(x_t, e_{t-1}) \ C &= f_1(e_n) \ d_t &= f_2(d_{t-1}, C) \ y_t &= Decoder_{LSTM/GRU}(y_{t-1}, d_{t-1}, C) \end{aligned}
e
t
C
d
t
y
t
=
E
n
co
d
e
r
L
STM
/
GR
U
(
x
t
,
e
t
−
1
)
=
f
1
(
e
n
)
=
f
2
(
d
t
−
1
,
C
)
=
Deco
d
e
r
L
STM
/
GR
U
(
y
t
−
1
,
d
t
−
1
,
C
)
加入 Attention 机制的 Encoder-Decoder 模型如下。
e
t
=
E
n
c
o
d
e
r
L
S
T
M
/
G
R
U
(
x
t
,
e
t
−
1
)
C
t
=
f
1
(
e
1
,
e
2
.
.
.
e
n
,
d
t
−
1
)
d
t
=
f
2
(
d
t
−
1
,
C
t
)
y
t
=
D
e
c
o
d
e
r
L
S
T
M
/
G
R
U
(
y
t
−
1
,
d
t
−
1
,
C
t
)
\begin{aligned} e_t &= Encoder_{LSTM/GRU}(x_t, e_{t-1}) \ C_t &= f_1(e_1,e_2…e_n,d_{t-1}) \ d_t &= f_2(d_{t-1}, C_t) \ y_t &= Decoder_{LSTM/GRU}(y_{t-1}, d_{t-1}, C_t) \end{aligned}
e
t
C
t
d
t
y
t
=
E
n
co
d
e
r
L
STM
/
GR
U
(
x
t
,
e
t
−
1
)
=
f
1
(
e
1
,
e
2
…
e
n
,
d
t
−
1
)
=
f
2
(
d
t
−
1
,
C
t
)
=
Deco
d
e
r
L
STM
/
GR
U
(
y
t
−
1
,
d
t
−
1
,
C
t
)
这种同时考虑 Encoder、Decoder 的 Attention,就叫做「Encoder-Decoder Attention」,也常被叫做「Vanilla Attention」。可以看到上面最核心的区别是第二个公式
C
t
C_t
C
t
。加入 Attention 后,对所有数据给予不同的注意力分布。具体地,比如我们用如下的函数来定义这个模型:
e
=
t
a
n
h
(
W
x
e
⋅
x
b
x
e
)
s
i
,
t
=
s
c
o
r
e
(
e
i
,
d
t
−
1
)
α
i
,
t
=
e
s
i
,
t
∑
j
=
1
n
e
s
j
,
t
C
t
=
∑
i
=
1
n
α
i
,
t
e
i
d
t
=
t
a
n
h
(
W
d
d
⋅
d
t
−
1
b
d
d
W
y
d
⋅
y
t
−
1
b
y
d
W
c
d
⋅
C
t
b
c
d
)
y
=
S
o
f
t
m
a
x
(
W
d
y
⋅
d
b
d
y
)
\begin{aligned} e &= tanh(W^{xe} \cdot x + b^{xe}) \ s_{i,t} &= score(e_i,d_{t-1}) \ \alpha_{i,t} &= \frac{e{s_{i,t}}}{\textstyle\sum_{j=1}n e^{s_{j,t}}} \ C_t &= \displaystyle\sum_{i=1}^n \alpha_{i,t} e_i \ d_t &= tanh(W^{dd} \cdot d_{t-1} + b^{dd} + W^{yd} \cdot y_{t-1} + b^{yd} + W^{cd} \cdot C_t + b^{cd}) \ y &= Softmax(W^{dy} \cdot d + b^{dy}) \end{aligned}
e
s
i
,
t
α
i
,
t
C
t
d
t
y
=
t
anh
(
W
x
e
⋅
x
b
x
e
)
=
score
(
e
i
,
d
t
−
1
)
=
∑
j
=
1
n
e
s
j
,
t
e
s
i
,
t
=
i
=
1
∑
n
α
i
,
t
e
i
=
t
anh
(
W
dd
⋅
d
t
−
1
b
dd
W
y
d
⋅
y
t
−
1
b
y
d
W
c
d
⋅
C
t
b
c
d
)
=
S
o
f
t
ma
x
(
W
d
y
⋅
d
b
d
y
)
到这里你能发现注意力机制的什么问题不?
这个注意力机制忽略了位置信息
。比如 Tigers love rabbits 和 Rabbits love tigers 会产生一样的注意力分数。
第二章 · Transformer 在 2017 年横空出世
麦克船长先通过一个动画来看下 Transformer 是举例示意,该图来自 Google 的博客文章
《Transformer: A Novel Neural Network Architecture for Language Understanding》
:

中文网络里找到的解释得比较好的 blogs、answers,几乎都指向了同一篇博客:Jay Alammar 的
《The Illustrated Transformer》
,所以建议读者搭配该篇文章阅读。
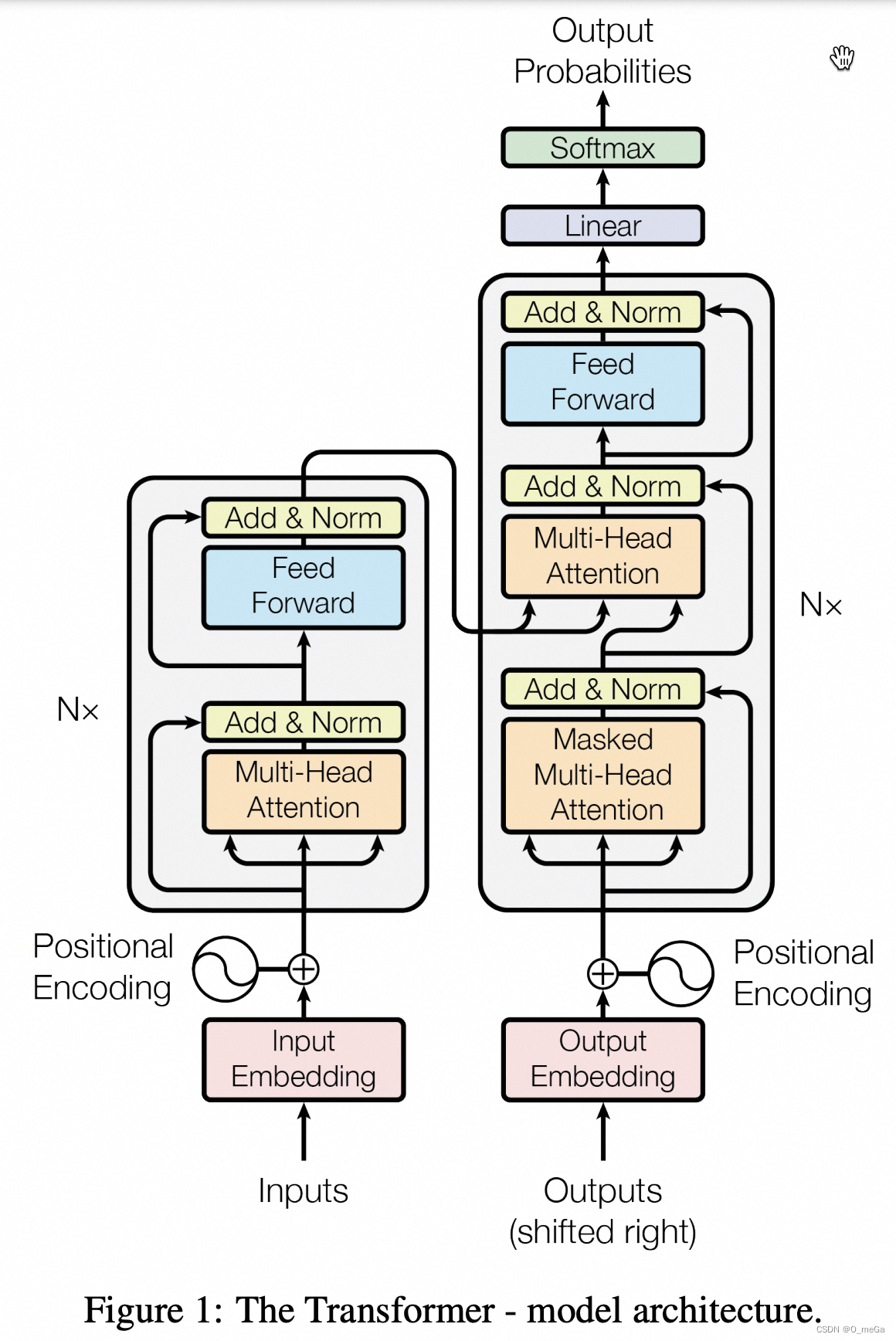
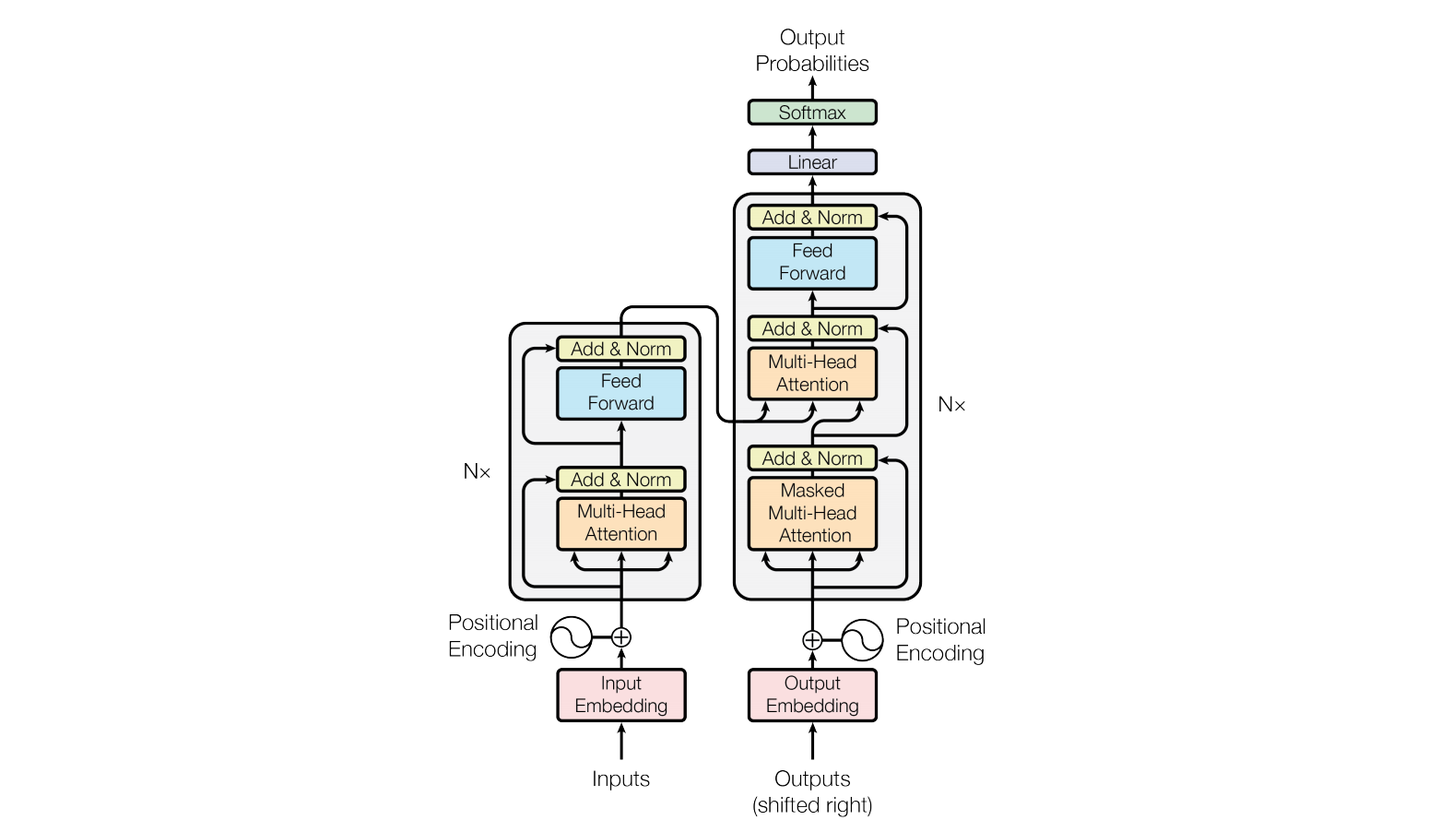
Transformer 模型中用到了自注意力(Self-Attention)、多头注意力(Multiple-Head Attention)、残差网络(ResNet)与捷径(Short-Cut)。下面我们先通过第 1 到第 4 小节把几个基本概念讲清楚,然后在第 5 小节讲解整体 Transformer 模型就会好理解很多了。最后第 6 小节我们来一段动手实践。
第 7 节 · 自注意力机制(Self-Attention)
自注意力是理解 Transformer 的关键,原作者在论文中限于篇幅,没有给出过多的解释。以下是我自己的理解,能够比较通透、符合常识地去理解 Transformer 中的一些神来之笔的概念。
7.1、一段自然语言内容,其自身就「暗含」很多内部关联信息
在加入了 Attention 的 Encoder-Decoder 模型中,对输出序列 Y 中的一个词的注意力来自于输入序列 X,那么如果 X 和 Y 相等呢?什么场景会有这个需求?因为我们认为一段文字里某些词就是由于另外某些词而决定的,可以粗暴地理解为「完形填空」的原理。那么这样一段文字,其实就存在其中每个词的自注意力,举个例子:
老王是我的主管,我很喜欢他的平易近人。
对这句话里的「他」,如果基于这句话计算自注意力的话,显然应该给予「老王」最多的注意力。受此启发,我们认为:
一段自然语言中,其实暗含了:为了得到关于某方面信息 Q,可以通过关注某些信息 K,进而得到某些信息(V)作为结果。
Q
Q
Q
就是 query 检索/查询,
K
K
K
、
V
V
V
分别是 key、value。所以类似于我们在图书检索系统里搜索「NLP书籍」(这是
Q
Q
Q
),得到了一本叫《自然语言处理实战》的电子书,书名就是 key,这本电子书就是 value。只是对于自然语言的理解,我们认为任何一段内容里,都自身暗含了很多潜在
Q
Q
Q
K
K
K
V
V
V
的关联。这是整体受到信息检索领域里 query-key-value 的启发的。
基于这个启发,我们将自注意力的公式表示为:
Z
=
S
e
l
f
A
t
t
e
n
t
i
o
n
(
X
)
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
\begin{aligned} Z = SelfAttention(X) = Attention(Q,K,V) \end{aligned}
Z
=
S
e
l
f
A
tt
e
n
t
i
o
n
(
X
)
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
X
X
X
经过自注意力计算后,得到的「暗含」了大量原数据内部信息的
Z
Z
Z
。然后我们拿着这个带有自注意力信息的
Z
Z
Z
进行后续的操作。这里要强调的是,
Z
Z
Z
向量中的每个元素
z
i
z_i
z
i
都与 X 的所有元素有某种关联,而不是只与
x
i
x_i
x
i
有关联。
7.2、如何计算 Q、K、V
Q、K、V 全部来自输入 X 的线性变换:
Q
=
W
Q
⋅
X
K
=
W
K
⋅
X
V
=
W
V
⋅
X
\begin{aligned} Q &= W^Q \cdot X \ K &= W^K \cdot X \ V &= W^V \cdot X \end{aligned}
Q
K
V
=
W
Q
⋅
X
=
W
K
⋅
X
=
W
V
⋅
X
W
Q
、
W
K
、
W
V
WQ、WK、W^V
W
Q
、
W
K
、
W
V
以随机初始化开始,经过训练就会得到非常好的表现。对于
X
X
X
中的每一个词向量
x
i
x_i
x
i
,经过这个变换后得到了:
q
i
=
W
Q
⋅
x
i
k
i
=
W
K
⋅
x
i
v
i
=
W
V
⋅
x
i
\begin{aligned} q_i &= W^Q \cdot x_i \ k_i &= W^K \cdot x_i \ v_i &= W^V \cdot x_i \end{aligned}
q
i
k
i
v
i
=
W
Q
⋅
x
i
=
W
K
⋅
x
i
=
W
V
⋅
x
i
7.3、注意力函数:如何通过 Q、V 得到 Z
基于上面的启发,我们认为
X
X
X
经过自注意力的挖掘后,得到了:
- 暗含信息 1:一组 query 与一组 key 之间的关联,记作 qk(想一下信息检索系统要用 query 先招到 key)
- 暗含信息 2:一组 value
- 暗含信息 3:qk 与 value 的某种关联
这三组信息,分别如何表示呢?这里又需要一些启发了,因为计算机科学其实是在「模拟还原」现实世界,在 AI 的领域目前的研究方向就是模拟还原人脑的思考。所以这种「模拟还原」都是寻找某一种近似方法,因此不能按照数学、物理的逻辑推理来理解,而应该按照「工程」或者「计算科学」来理解,想想我们大学时学的「计算方法」这门课,因此常需要一些启发来找到某种「表示」。
这里 Transformer 的作者,认为
Q
Q
Q
和
K
K
K
两个向量之间的关联,是我们在用
Q
Q
Q
找其在
K
K
K
上的投影,如果
Q
Q
Q
、
K
K
K
是单位长度的向量,那么这个投影其实可以理解为找「
Q
Q
Q
和
K
K
K
向量之间的相似度」:
- 如果
Q
Q
Q
和
K
K
K
垂直,那么两个向量正交,其点积(Dot Product)为 0;
- 如果
Q
Q
Q
和
K
K
K
平行,那么两个向量点积为两者模积
∥
Q
∥
∥
K
∥
|Q||K|
∥
Q
∥∥
K
∥
;
- 如果
Q
Q
Q
和
K
K
K
呈某个夹角,则点积就是
Q
Q
Q
在
K
K
K
上的投影的模。
因此「暗含信息 1」就可以用「
Q
⋅
K
Q\cdot K
Q
⋅
K
」再经过 Softmax 归一化来表示。这个表示,是一个所有元素都是 0~1 的矩阵,可以理解成对应注意力机制里的「注意力分数」,也就是一个「注意力分数矩阵(Attention Score Matrix)」。
而「暗含信息 2」则是输入
X
X
X
经过的线性变换后的特征,看做
X
X
X
的另一种表示。然后我们用这个「注意力分数矩阵」来加持一下
V
V
V
,这个点积过程就表示了「暗含信息 3」了。所以我们有了如下公式:
Z
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
⋅
K
T
)
⋅
V
\begin{aligned} Z = Attention(Q,K,V) = Softmax(Q \cdot K^T) \cdot V \end{aligned}
Z
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
ma
x
(
Q
⋅
K
T
)
⋅
V
其实到这里,这个注意力函数已经可以用了。有时候,为了避免因为向量维度过大,导致
Q
⋅
K
T
Q \cdot K^T
Q
⋅
K
T
点积结果过大,我们再加一步处理:
Z
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
m
a
x
(
Q
⋅
K
T
d
k
)
⋅
V
\begin{aligned} Z = Attention(Q,K,V) = Softmax(\frac{Q \cdot K^T}{\sqrt{\smash[b]{d_k}}}) \cdot V \end{aligned}
Z
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
S
o
f
t
ma
x
(
d
k
Q
⋅
K
T
)
⋅
V
这里
d
k
d_k
d
k
是 K 矩阵中向量
k
i
k_i
k
i
的维度。这一步修正还有进一步的解释,即如果经过 Softmax 归一化后模型稳定性存在问题。怎么理解?如果假设
Q
Q
Q
和
K
K
K
中的每个向量的每一维数据都具有零均值、单位方差,这样输入数据是具有稳定性的,那么如何让「暗含信息 1」计算后仍然具有稳定性呢?即运算结果依然保持零均值、单位方差,就是除以「
d
k
\sqrt{\smash[b]{d_k}}
d
k
」。
7.4、其他注意力函数
为了提醒大家这种暗含信息的表示,都只是计算方法上的一种选择,好坏全靠结果评定,所以包括上面的在内,常见的注意力函数有(甚至你也可以自己定义):
Z
=
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
{
=
S
o
f
t
m
a
x
(
Q
T
K
)
V
=
S
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
=
S
o
f
t
m
a
x
(
ω
T
t
a
n
h
(
W
[
q
;
k
]
)
)
V
=
S
o
f
t
m
a
x
(
Q
T
W
K
)
V
=
c
o
s
i
n
e
[
Q
T
K
]
V
Z = Attention(Q,K,V) = \begin{cases} \begin{aligned} &= Softmax(Q^T K) V \ &= Softmax(\frac{Q K^T}{\sqrt{\smash[b]{d_k}}}) V \ &= Softmax(\omega^T tanh(W[q;k])) V \ &= Softmax(Q^T W K) V \ &= cosine[Q^T K] V \end{aligned} \end{cases}
Z
=
A
tt
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
⎩
⎨
⎧
=
S
o
f
t
ma
x
(
Q
T
K
)
V
=
S
o
f
t
ma
x
(
d
k
Q
K
T
)
V
=
S
o
f
t
ma
x
(
ω
T
t
anh
(
W
[
q
;
k
]))
V
=
S
o
f
t
ma
x
(
Q
T
W
K
)
V
=
cos
in
e
[
Q
T
K
]
V
到这里,我们就从原始的输入
X
X
X
得到了一个包含自注意力信息的
Z
Z
Z
了,后续就可以用
Z
Z
Z
了。
第 8 节 · 多头注意力
到这里我们理解了「自注意力」,而 Transformer 这篇论文通过添加「多头」注意力的机制进一步提升了注意力层。我们先看下它是什么,然后看下它的优点。从本小节开始,本文大量插图引用自
《The Illustrated Transformer》
,作者 Jay Alammar 写出一篇非常深入浅出的图解文章,被大量引用,非常出色,再次建议大家去阅读。
Transformer 中用了 8 个头,也就是 8 组不同的
Q
Q
Q
K
K
K
V
V
V
:
Q
0
=
W
0
Q
⋅
X
;
K
0
=
W
0
K
⋅
X
;
V
0
=
W
0
V
⋅
X
Q
1
=
W
1
Q
⋅
X
;
K
1
=
W
0
K
⋅
X
;
V
1
=
W
1
V
⋅
X
.
.
.
.
Q
7
=
W
7
Q
⋅
X
;
K
7
=
W
0
K
⋅
X
;
V
7
=
W
7
V
⋅
X
\begin{aligned} Q_0 = W_0^Q \cdot X ;\enspace K_0 = &W_0^K \cdot X ;\enspace V_0 = W_0^V \cdot X \ Q_1 = W_1^Q \cdot X ;\enspace K_1 = &W_0^K \cdot X ;\enspace V_1 = W_1^V \cdot X \ &… \ Q_7 = W_7^Q \cdot X ;\enspace K_7 = &W_0^K \cdot X ;\enspace V_7 = W_7^V \cdot X \end{aligned}
Q
0
=
W
0
Q
⋅
X
;
K
0
=
Q
1
=
W
1
Q
⋅
X
;
K
1
=
Q
7
=
W
7
Q
⋅
X
;
K
7
=
W
0
K
⋅
X
;
V
0
=
W
0
V
⋅
X
W
0
K
⋅
X
;
V
1
=
W
1
V
⋅
X
…
W
0
K
⋅
X
;
V
7
=
W
7
V
⋅
X
这样我们就能得到 8 个
Z
Z
Z
:
Z
0
=
A
t
t
e
n
t
i
o
n
(
Q
0
,
K
0
,
V
0
)
=
S
o
f
t
m
a
x
(
Q
0
⋅
K
0
T
d
k
)
⋅
V
0
Z
1
=
A
t
t
e
n
t
i
o
n
(
Q
1
,
K
1
,
V
1
)
=
S
o
f
t
m
a
x
(
Q
1
⋅
K
1
T
d
k
)
⋅
V
1
.
.
.
Z
7
=
A
t
t
e
n
t
i
o
n
(
Q
7
,
K
7
,
V
7
)
=
S
o
f
t
m
a
x
(
Q
7
⋅
K
7
T
d
k
)
⋅
V
7
\begin{aligned} &Z_0 = Attention(Q_0,K_0,V_0) = Softmax(\frac{Q_0 \cdot K_0^T}{\sqrt{\smash[b]{d_k}}}) \cdot V_0 \ &Z_1 = Attention(Q_1,K_1,V_1) = Softmax(\frac{Q_1 \cdot K_1^T}{\sqrt{\smash[b]{d_k}}}) \cdot V_1 \ &… \ &Z_7 = Attention(Q_7,K_7,V_7) = Softmax(\frac{Q_7 \cdot K_7^T}{\sqrt{\smash[b]{d_k}}}) \cdot V_7 \ \end{aligned}
Z
0
=
A
tt
e
n
t
i
o
n
(
Q
0
,
K
0
,
V
0
)
=
S
o
f
t
ma
x
(
d
k
Q
0
⋅
K
0
T
)
⋅
V
0
Z
1
=
A
tt
e
n
t
i
o
n
(
Q
1
,
K
1
,
V
1
)
=
S
o
f
t
ma
x
(
d
k
Q
1
⋅
K
1
T
)
⋅
V
1
…
Z
7
=
A
tt
e
n
t
i
o
n
(
Q
7
,
K
7
,
V
7
)
=
S
o
f
t
ma
x
(
d
k
Q
7
⋅
K
7
T
)
⋅
V
7
然后我们把
Z
0
Z_0
Z
0
到
Z
7
Z_7
Z
7
沿着行数不变的方向全部连接起来,如下图所示:

我们再训练一个权重矩阵
W
O
W^O
W
O
,然后用上面拼接的
Z
0
−
7
Z_{0-7}
Z
0
−
7
乘以这个权重矩阵:

于是我们会得到一个 Z 矩阵:

到这里就是多头注意力机制的全部内容,与单头注意力相比,都是为了得到一个
Z
Z
Z
矩阵,但是多头用了多组
Q
Q
Q
K
K
K
V
V
V
,然后经过拼接、乘以权重矩阵得到最后的
Z
Z
Z
。我们总览一下整个过程:

通过多头注意力,每个头都会关注到不同的信息,可以如下类似表示:

这通过两种方式提高了注意力层的性能:
- 多头注意力机制,扩展了模型关注不同位置的能力。
Z
Z
Z
矩阵中的每个向量
z
i
z_i
z
i
包含了与
X
X
X
中所有向量
x
i
x_i
x
i
有关的一点编码信息。反过来说,不要认为
z
i
z_i
z
i
只与
x
i
x_i
x
i
有关。
- 多头注意力机制,为注意力层提供了多个「表示子空间
Q
Q
Q
K
K
K
V
V
V
」,以及
Z
Z
Z
。这样一个输入矩阵
X
X
X
,就会被表示成 8 种不同的矩阵
Z
Z
Z
,都包含了原始数据信息的某种解读暗含其中。
第 9 节 · 退化现象、残差网络与 Short-Cut
9.1、退化现象
对于一个 56 层的神经网路,我们很自然地会觉得应该比 20 层的神经网络的效果要好,比如说从误差率(error)的量化角度看。但是华人学者何凯明等人的论文
《Deep Residual Learning for Image Recognition》
中给我们呈现了相反的结果,而这个问题的原因并不是因为层数多带来的梯度爆炸/梯度消失(毕竟已经用了归一化解决了这个问题),而是因为一种反常的现象,这种现象我们称之为「退化现象」。何凯明等人认为这是因为存在「难以优化好的网络层」。
9.2、恒等映射
如果这 36 层还帮了倒忙,那还不如没有,是不是?所以这多出来的 36 个网络层,如果对于提升性能(例如误差率)毫无影响,甚至更进一步,这 36 层前的输入数据,和经过这 36 层后的输出数据,完全相同,那么如果将这 36 层抽象成一个函数
f
36
f_{36}
f
36
,这就是一个恒等映射的函数:
f
36
(
x
)
=
x
f_{36}(x) = x
f
36
(
x
)
=
x
回到实际应用中。如果我们对于一个神经网络中的连续 N 层是提升性能,还是降低性能,是未知的,那么则可以建立一个跳过这些层的连接,实现:
如果这 N 层可以提升性能,则采用这 N 层;否则就跳过。
这就像给了这 N 层神经网络一个试错的空间,待我们确认它们的性能后再决定是否采用它们。同时也可以理解成,这些层可以去单独优化,如果性能提升,则不被跳过。
9.3、残差网络(Residual Network)与捷径(Short-Cut)
如果前面 20 层已经可以实现 99% 的准确率,那么引入了这 36 层能否再提升「残差剩余那 1%」的准确率从而达到 100% 呢?所以这 36 层的网络,就被称为「残差网络(Residual Network,常简称为 ResNet)」,这个叫法非常形象。
而那个可以跳过 N 层残差网络的捷径,则常被称为 Short-Cut,也会被叫做跳跃链接(Skip Conntection),这就解决了上述深度学习中的「退化现象」。
第 10 节 · Transformer 的位置编码(Positional Embedding)
还记得我在第二部分最后提到的吗:
这个注意力机制忽略了位置信息。比如 Tigers love rabbits 和 Rabbits love tigers 会产生一样的注意力分数。
10.1、Transformer 论文中的三角式位置编码(Sinusoidal Positional Encoding)
现在我们来解决这个问题,为每一个输入向量
x
i
x_i
x
i
生成一个位置编码向量
t
i
t_i
t
i
,这个位置编码向量的维度,与输入向量(词的嵌入式向量表示)的维度是相同的:

Transformer 论文中给出了如下的公式,来计算位置编码向量的每一位的值:
P
p
o
s
,
2
i
=
s
i
n
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
P
p
o
s
,
2
i
1
=
c
o
s
(
p
o
s
1000
0
2
i
d
m
o
d
e
l
)
\begin{aligned} P_{pos,2i} &= sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \ P_{pos,2i+1} &= cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \end{aligned}
P
p
os
,
2
i
P
p
os
,
2
i
1
=
s
in
(
1000
0
d
m
o
d
e
l
2
i
p
os
)
=
cos
(
1000
0
d
m
o
d
e
l
2
i
p
os
)
这样对于一个 embedding,如果它在输入内容中的位置是 pos,那么其编码向量就表示为:
[
P
p
o
s
,
0
,
P
p
o
s
,
1
,
.
.
.
,
P
p
o
s
,
d
x
−
1
]
\begin{aligned} [P_{pos,0}, P_{pos,1}, … , P_{pos,d_x-1}] \end{aligned}
[
P
p
os
,
0
,
P
p
os
,
1
,
…
,
P
p
os
,
d
x
−
1
]
延展开的话,位置编码其实还分为绝对位置编码(Absolute Positional Encoding)、相对位置编码(Relative Positional Encoding)。前者是专门生成位置编码,并想办法融入到输入中,我们上面看到的就是一种。后者是微调 Attention 结构,使得它可以分辨不同位置的数据。另外其实还有一些无法分类到这两种的位置编码方法。
10.2、绝对位置编码
绝对位置编码,如上面提到的,就是定义一个位置编码向量
t
i
t_i
t
i
,通过
x
i
t
i
x_i + t_i
x
i
t
i
就得到了一个含有位置信息的向量。
- 习得式位置编码(Learned Positional Encoding):将位置编码当做训练参数,生成一个「最大长度 x 编码维度」的位置编码矩阵,随着训练进行更新。目前 Google BERT、OpenAI GPT 模型都是用的这种位置编码。缺点是「外推性」差,如果文本长度超过之前训练时用的「最大长度」则无法处理。目前有一些给出优化方案的论文,比如「
层次分解位置编码
」。 - 三角式位置编码(Sinusoidal Positional Encodign):上面提过了。
- 循环式位置编码(Recurrent Positional Encoding):通过一个 RNN 再接一个 Transformer,那么 RNN 暗含的「顺序」就导致不再需要额外编码了。但这样牺牲了并行性,毕竟 RNN 的两大缺点之一就有这个。
- 相乘式位置编码(Product Positional Encoding):用「
x
i
⊙
t
i
x_i \odot t_i
x
i
⊙
t
i
」代替「
x
i
t
i
x_i + t_i
x
i
t
i
」。
10.3、相对位置编码和其他位置编码
最早来自于 Google 的论文
《Self-Attention with Relative Position Representations》
相对位置编码,考虑的是当前 position 与被 attention 的 position 之前的相对位置。
- 常见相对位置编码:经典式、XLNET 式、T5 式、DeBERTa 式等。
- 其他位置编码:CNN 式、复数式、融合式等。
到此我们都是在讲 Encoder,目前我们知道一个 Encoder 可以用如下的示意图表示:

第 11 节 · Transformer 的编码器 Encoder 和解码器 Decoder
11.1、Encoder 和 Decoder 的图示结构

- 第一层是多头注意力层(Multi-Head Attention Layer)。
- 第二层是经过一个前馈神经网络(Feed Forward Neural Network,简称 FFNN)。
- 这两层,每一层都有「Add & Normalization」和 ResNet。

- 解码器有两个多头注意力层。第一个多头注意力层是 Masked Multi-Head Attention 层,即在自注意力计算的过程中只有前面位置上的内容。第二个多头注意力层买有被 Masked,是个正常多头注意力层。
- 可以看出来,第一个注意力层是一个自注意力层(Self Attention Layer),第二个是 Encoder-Decoder Attention 层(它的
K
K
K
、
V
V
V
来自 Encoder,
Q
Q
Q
来自自注意力层),有些文章里会用这个角度来指代。
- FNN、Add & Norm、ResNet 都与 Encoder 类似。
11.2、Decoder 的第一个输出结果
产出第一个最终输出结果的过程:
- 不需要经过 Masked Multi-Head Attention Layer(自注意力层)。
- 只经过 Encoder-Decoder Attention Layer。

这样我们就像前面的 Encoder-Decoder Attention 模型一样,得到第一个输出。但是最终的输出结果,还会经过一层「Linear + Softmax」。
11.3、Decoder 后续的所有输出
从产出第二个输出结果开始:
- Decoder 的自注意力层,会用到前面的输出结果。
- 可以看到,这是一个串行过程。
11.4、Decoder 之后的 Linear 和 Softmax
经过所有 Decoder 之后,我们得到了一大堆浮点数的结果。最后的 Linear & Softmax 就是来解决「怎么把它变成文本」的问题的。
- Linear 是一个全连接神经网络,把 Decoders 输出的结果投影到一个超大的向量上,我们称之为 logits 向量。
- 如果我们的输出词汇表有 1 万个词,那么 logits 向量的每一个维度就有 1 万个单元,每个单元都对应输出词汇表的一个词的概率。
- Softmax 将 logits 向量中的每一个维度都做归一化,这样每个维度都能从 1 万个单元对应的词概率中选出最大的,对应的词汇表里的词,就是输出词。最终得到一个输出字符串。
第 12 节 · Transformer 模型整体

最后我们再来整体看一下 Transformer:
- 首先输入数据生成词的嵌入式向量表示(Embedding),生成位置编码(Positional Encoding,简称 PE)。
- 进入 Encoders 部分。先进入多头注意力层(Multi-Head Attention),是自注意力处理,然后进入全连接层(又叫前馈神经网络层),每层都有 ResNet、Add & Norm。
- 每一个 Encoder 的输入,都来自前一个 Encoder 的输出,但是第一个 Encoder 的输入就是 Embedding + PE。
- 进入 Decoders 部分。先进入第一个多头注意力层(是 Masked 自注意力层),再进入第二个多头注意力层(是 Encoder-Decoder 注意力层),每层都有 ResNet、Add & Norm。
- 每一个 Decoder 都有两部分输入。
- Decoder 的第一层(Maksed 多头自注意力层)的输入,都来自前一个 Decoder 的输出,但是第一个 Decoder 是不经过第一层的(因为经过算出来也是 0)。
- Decoder 的第二层(Encoder-Decoder 注意力层)的输入,Q 都来自该 Decoder 的第一层,且每个 Decoder 的这一层的 K、V 都是一样的,均来自最后一个 Encoder。
- 最后经过 Linear、Softmax 归一化。
第 13 节 · Transformer 的性能
Google 在其博客于 2017.08.31 发布如下测试数据:
第三章 · 一个基于 TensorFlow 架构的 Transformer 实现
我们来看看一个简单的 Transformer 模型,就是比较早出现的 Kyubyong 实现的 Transformer 模型:
GitHub - Kyubyong Transformer - tf1.2 legacy
第 14 节 · 先训练和测试一下 Kyubyong Transformer
下载一个「德语-英语翻译」的数据集:https://drive.google.com/uc?id=1l5y6Giag9aRPwGtuZHswh3w5v3qEz8D8
把
de-en
下面的
tgz
解压后放在
corpora/
目录下。如果需要先修改超参数,需要修改
hyperparams.py
。然后运行如下命令,生成词汇文件(vocabulary files),默认到
preprocessed
目录下:
mikecaptain@local $ python prepro.py
然后开始训练:
mikecaptain@local $ python train.py
也可以跳过训练,直接
下载预训练过的文件
,是一个
logdir/
目录,把它放到项目根目录下。然后可以对训练出来的结果,运行评价程序啦:
mikecaptain@local $ python eval.py
会生成「德语-英语」测试结果文件在
results/
目录下,内容如下:
- source: Sie war eine jährige Frau namens Alex
- expected: She was a yearold woman named Alex
- got: She was a <UNK> of vote called <UNK>
- source: Und als ich das hörte war ich erleichtert
- expected: Now when I heard this I was so relieved
- got: And when I was I <UNK> 's
- source: Meine Kommilitonin bekam nämlich einen Brandstifter als ersten Patienten
- expected: My classmate got an arsonist for her first client
- got: Because my first eye was a first show
- source: Das kriege ich hin dachte ich mir
- expected: This I thought I could handle
- got: I would give it to me a day
- source: Aber ich habe es nicht hingekriegt
- expected: But I didn't handle it
- got: But I didn't <UNK> <UNK>
- source: Ich hielt dagegen
- expected: I pushed back
- got: I <UNK>
...
Bleu Score = 6.598452846670836
评估结果文件的最后一行是 Bleu Score:
- 这是用来评估机器翻译质量的一种度量方式。它是由几个不同的 BLEU 分数组成的,每个 BLEU 分数都表示翻译结果中与参考翻译的重叠程度。
- 一个常用的 BLEU 分数是 BLEU-4,它计算翻译结果中与参考翻译的 N 元文法语言模型 n-gram(n 为 4)的重叠程度。分数越高表示翻译结果越接近参考翻译。
第 15 节 · Kyubyong Transformer 源码分析
hparams.py
:超参数都在这里,仅 30 行。将在下面
2.1
部分解读。data_load.py
:装载、批处理数据的相关函数,代码仅 92 行。主要在下面
2.2
部分解读。prepro.py
:为 source 和 target 创建词汇文件(vocabulary file),代码仅 39 行。下面
2.3
部分会为大家解读。train.py
:代码仅 184 行。在下面
2.4
部分解读。modules.py
:Encoding / Decoding 网络的构建模块,代码仅 329 行。与
modules.py
一起会在
2.4
部分解读。eval.py
:评估效果,代码仅 82 行。将在
2.5
部分解读
总计 700 多行代码。
15.1、超参数
hyperparams.py
文件中定义了
Hyperparams
超参数类,其中包含的参数我们逐一来解释一下:
source_train
:训练数据集的源输入文件,默认是
'corpora/train.tags.de-en.de'target_train
:训练数据集的目标输出文件,默认是
'corpora/train.tags.de-en.en'source_test
:测试数据集的源输入文件,默认是
'corpora/IWSLT16.TED.tst2014.de-en.de.xml'target_test
:测试数据集的目标输出文件,默认是
'corpora/IWSLT16.TED.tst2014.de-en.en.xml'batch_size
:设置每批数据的大小。lr
:设置学习率 learning rate。logdir
:设置日志文件保存的目录。maxlenmin_cnthidden_units
:设置编码器和解码器中隐藏层单元的数量。num_blocks
:编码器(encoder block)、解码器(decoder block)的数量num_epochs
:训练过程中迭代的次数。num_heads
:还记得上面文章里我们提到的 Transformer 中用到了多头注意力吧,这里就是多头注意力的头数。droupout_rate
:设置 dropout 层的 dropout rate,具体 dropout 请看 2.4.1 部分。sinusoid
:设置为
True
时表示使用正弦函数计算位置编码,否则为
False
时表示直接用
position
做位置编码。
15.2、预处理
文件
prepro.py
实现了预处理的过程,根据
hp.source_train
和
hp.target_train
分别创建
"de.vocab.tsv"
和
"en.vocab.tsv"
两个词汇表。
def make_vocab(fpath, fname):
# 使用 codecs.open 函数读取指定文件路径(fpath)的文本内容,并将其存储在 text 变量中
text = codecs.open(fpath, 'r', 'utf-8').read()
# 将 text 中的非字母和空格的字符去掉
text = regex.sub("[^\s\p{Latin}']", "", text)
# 将 text 中的文本按照空格分割,并将每个单词存储在 words 变量中
words = text.split()
# words 中每个单词的词频
word2cnt = Counter(words)
# 检查是否存在 preprocessed 文件夹,如果不存在就创建
if not os.path.exists('preprocessed'): os.mkdir('preprocessed')
with codecs.open('preprocessed/{}'.format(fname), 'w', 'utf-8') as fout:
# 按出现次数从多到少的顺序写入每个单词和它的出现次数
# 在文件最前面写入四个特殊字符 <PAD>, <UNK>, <S>, </S> 分别用于填充,未知单词,句子开始和句子结束
fout.write("{}\t1000000000\n{}\t1000000000\n{}\t1000000000\n{}\t1000000000\n".format("<PAD>", "<UNK>", "<S>", "</S>"))
for word, cnt in word2cnt.most_common(len(word2cnt)):
fout.write(u"{}\t{}\n".format(word, cnt))
if __name__ == '__main__':
make_vocab(hp.source_train, "de.vocab.tsv")
make_vocab(hp.target_train, "en.vocab.tsv")
print("Done")
- 在主函数中调用 make_vocab 函数,在目录
preprocessed
生成
de.vocab.tsv
和
en.vocab.tsv
两个词汇表文件。 - 在函数
make_vocab
中,先使用
codecs.open
函数读取指定文件路径
fpath
的文本内容,并将其存储在
text
变量中,再使用正则表达式
regex
将
text
中的非字母和空格的字符去掉,接着将
text
中的文本按照空格分割,并将每个单词存储在
words
变量中。 - 接下来,使用
Counter
函数统计
words
中每个单词的出现次数,并将统计结果存储在
word2cnt
变量中。 - 最后所有词与词频,存储在
de.vocab.tsv
和
en.vocab.tsv
两个文件中。
15.3、训练/测试数据集的加载
我们先看下
train.py
、
data_load.py
、
eval.py
三个文件:
train.py
:该文件包含了
Graph
类的定义,并在其构造函数中调用
load_data.py
文件中的
get_batch_data
函数加载训练数据。data_load.py
:定义了加载训练数据、加载测试数据的函数。eval.py
:测试结果的评价函数定义在这个文件里。
下面是函数调用的流程:

def load_de_vocab():
vocab = [line.split()[0] for line in codecs.open('preprocessed/de.vocab.tsv', 'r', 'utf-8').read().splitlines() if int(line.split()[1])>=hp.min_cnt]
word2idx = {word: idx for idx, word in enumerate(vocab)}
idx2word = {idx: word for idx, word in enumerate(vocab)}
return word2idx, idx2word
def load_en_vocab():
vocab = [line.split()[0] for line in codecs.open('preprocessed/en.vocab.tsv', 'r', 'utf-8').read().splitlines() if int(line.split()[1])>=hp.min_cnt]
word2idx = {word: idx for idx, word in enumerate(vocab)}
idx2word = {idx: word for idx, word in enumerate(vocab)}
return word2idx, idx2word
将
preprocessed/de.vocab.tsv
和
preprocessed/en.vocab.tsv
中储存的德语、英语的词汇、词频,载入成
word2idx
和
idx2word
。前者是通过词查询词向量,后者通过词向量查询词。
load_de_vocab
和
load_en_vocab
函数被
create_data
函数引用,该函数将输入的源语言和目标语言句子转换为索引表示,并对过长的句子进行截断或填充。详细的解释看下面代码里的注释。
# 输入参数是翻译模型的源语言语句、目标语言语句
def create_data(source_sents, target_sents):
de2idx, idx2de = load_de_vocab()
en2idx, idx2en = load_en_vocab()
# 用 zip 函数将源语言和目标语言句子对应起来,并对句子进行截断或填充
x_list, y_list, Sources, Targets = [], [], [], []
for source_sent, target_sent in zip(source_sents, target_sents):
x = [de2idx.get(word, 1) for word in (source_sent + u" </S>").split()] # 1: OOV, </S>: End of Text
y = [en2idx.get(word, 1) for word in (target_sent + u" </S>").split()]
# 将句子的词的编号,原句以及编号后的句子存储下来,以供之后使用
if max(len(x), len(y)) <=hp.maxlen:
# 将 x 和 y 转换成 numpy 数组并加入 x_list 和 y_list 中
x_list.append(np.array(x))
y_list.append(np.array(y))
# 将原始的 source_sent 和 target_sent 加入 Sources 和 Targets 列表中
Sources.append(source_sent)
Targets.append(target_sent)
# 对于每个 (x, y) 对,使用 np.lib.pad 函数将 x 和 y 分别用 0 进行填充,直到长度为 hp.maxlen
# 这样做的目的是使得每个句子长度都相等,方便后续的训练
X = np.zeros([len(x_list), hp.maxlen], np.int32)
Y = np.zeros([len(y_list), hp.maxlen], np.int32)
for i, (x, y) in enumerate(zip(x_list, y_list)):
X[i] = np.lib.pad(x, [0, hp.maxlen-len(x)], 'constant', constant_values=(0, 0))
Y[i] = np.lib.pad(y, [0, hp.maxlen-len(y)], 'constant', constant_values=(0, 0))
# 返回转换后的索引表示,以及未经处理的源语言和目标语言句子
# X 是原始句子中德语的索引
# Y 是原始句子中英语的索引
# Sources 是源原始句子列表,并与 X 一一对应
# Targets 是目标原始句子列表,并与 Y 一一对应
return X, Y, Sources, Targets
# 返回原始句子中德语、英语的索引
def load_train_data():
de_sents = [regex.sub("[^\s\p{Latin}']", "", line) for line in codecs.open(hp.source_train, 'r', 'utf-8').read().split("\n") if line and line[0] != "<"]
en_sents = [regex.sub("[^\s\p{Latin}']", "", line) for line in codecs.open(hp.target_train, 'r', 'utf-8').read().split("\n") if line and line[0] != "<"]
X, Y, Sources, Targets = create_data(de_sents, en_sents)
return X, Y
下面的
get_batch_data
则从文本数据中读取并生成 batch:
def get_batch_data():
# 加载数据
X, Y = load_train_data()
# calc total batch count
num_batch = len(X) // hp.batch_size
# 将 X 和 Y 转换成张量
X = tf.convert_to_tensor(X, tf.int32)
Y = tf.convert_to_tensor(Y, tf.int32)
# 创建输入队列
input_queues = tf.train.slice_input_producer([X, Y])
# 创建 batch 队列,利用 shuffle_batch 将一组 tensor 随机打乱,并将它们分为多个 batch
# 使用 shuffle_batch 是为了防止模型过拟合
x, y = tf.train.shuffle_batch(input_queues,
num_threads=8,
batch_size=hp.batch_size,
capacity=hp.batch_size*64,
min_after_dequeue=hp.batch_size*32,
allow_smaller_final_batch=False)
return x, y, num_batch # (N, T), (N, T), ()
15.4、构建模型并训练
Graph 的构造函数流程,就是模型的构建流程,下面船长来分析这部分代码。

整体这个流程,主要涉及
train.py
文件和
modules.py
文件。所有模型所需的主要函数定义,都是在
modules.py
中实现的。我们先看下编码器(Encoder)的流程:

下面是
train.py
中实现的 Transformer 流程,其中的每一段代码,船长都会做详细解释,先不用急。这个流程里,首先定义了编码器,先使用了 Embedding 层将输入数据转换为词向量,使用 Positional Encoding 层对词向量进行位置编码,使用 Dropout 层进行 dropout 操作,然后进行多层 Multihead Attention 和 Feed Forward 操作。
在构建模型前,先执行
train.py
的主程序段,首先
if __name__ == '__main__'
这句代码是在 Python 中常用的一种编写方式,它的意思是当一个文件被直接运行时,
if
语句下面的代码会被执行。请看下面代码的注释。
if __name__ == '__main__':
# 加载词汇表
de2idx, idx2de = load_de_vocab()
en2idx, idx2en = load_en_vocab()
# 构建模型并训练
g = Graph("train"); print("Graph loaded")
# 创建了一个 Supervisor 对象来管理训练过程
sv = tf.train.Supervisor(graph=g.graph,
logdir=hp.logdir,
save_model_secs=0)
# 使用 with 语句打开一个会话
with sv.managed_session() as sess:
# 训练迭代 hp.num_epochs 次
for epoch in range(1, hp.num_epochs+1):
if sv.should_stop(): break
# tqdm 是一个 Python 库,用来在循环执行训练操作时在命令行中显示进度条
for step in tqdm(range(g.num_batch), total=g.num_batch, ncols=70, leave=False, unit='b'):
# 每次迭代都会运行训练操作 g.train_op
sess.run(g.train_op)
# 获取训练的步数,通过 sess.run() 函数获取 global_step 的当前值并赋值给 gs。这样可在后面使用 gs 保存模型时用这个值命名模型
gs = sess.run(g.global_step)
# 每个 epoch 结束时,它使用 saver.save() 函数保存当前模型的状态
sv.saver.save(sess, hp.logdir + '/model_epoch_%02d_gs_%d' % (epoch, gs))
print("Done")
num_epochs
是训练过程中迭代的次数,它表示训练模型需要在训练数据上跑多少遍。每一次迭代都会在训练数据集上进行训练,通常来说,训练数据集会被重复多次迭代,直到达到
num_epochs
次。这样可以确保模型能够充分地学习数据的特征。设置
num_epochs
的值过大或过小都会导致模型性能下降。
15.4.1、编码过程
Embedding
embedding
用来把输入生成词嵌入向量:
# 词语转换为对应的词向量表示
self.enc = embedding(self.x,
vocab_size=len(de2idx),
num_units=hp.hidden_units,
scale=True,
scope="enc_embed")
vocab_size
是词汇表的大小。num_units
是词向量的维度。scale
是一个布尔值,用来确定是否对词向量进行标准化。scope
是变量作用域的名称。
Key Masks
接着生成一个
key_masks
用于在之后的计算中屏蔽掉某些位置的信息,以便模型只关注有效的信息。
key_masks = tf.expand_dims(tf.sign(tf.reduce_sum(tf.abs(self.enc), axis=-1)), -1)
- 先对
self.enc
张量进行对每个元素求绝对值的操作 - 沿着最后一阶作为轴,进行
reduce_sum
操作,得到一个
(batch, sequence_length)
形状的张量。 - 再进行
tf.sign
操作,对刚得到的每个元素进行符号函数的变换。 - 最后再扩展阶数,变成形状
(batch, sequence_length, 1)
的张量。
Positional Encoding
下面生成 Transformer 的位置编码:
# 位置编码
if hp.sinusoid:
self.enc += positional_encoding(self.x,
num_units=hp.hidden_units,
zero_pad=False,
scale=False,
scope="enc_pe")
else:
self.enc += embedding(tf.tile(tf.expand_dims(tf.range(tf.shape(self.x)[1]), 0),
[tf.shape(self.x)[0], 1]),
vocab_size=hp.maxlen,
num_units=hp.hidden_units,
zero_pad=False,
scale=False,
scope="enc_pe")
如果超参数
hp.sinusoid=True
,使用
positional_encoding
函数,通过使用正弦和余弦函数来生成位置编码,可以为输入序列添加位置信息。如果
hp.sinusoid=False
,使用
embedding
函数,通过学习的词嵌入来生成位置编码。
位置编码生成后,用
key_masks
处理一下。注意
key_masks
的生成一定要用最初的
self.enc
,所以在前面执行而不是这里:
self.enc *= key_masks
这个不是矩阵乘法,而是对应元素相乘。这里乘上
key_masks
的目的是将
key_masks
中值为 0 的位置对应的
self.enc
中的元素置为 0,这样就可以排除这些位置对计算的影响。
Drop out
下面调用了 TensorFlow 的 drop out 操作:
self.enc = tf.layers.dropout(self.enc,
rate=hp.dropout_rate,
training=tf.convert_to_tensor(is_training))
drop out 是一种在深度学习中常用的正则化技巧。它通过在训练过程中随机地「关闭」一些神经元来减少
过拟合
。这样做是为了防止模型过于依赖于某些特定的特征,而导致在新数据上的表现不佳。
在这个函数中,
dropout
层通过在训练过程中随机地将一些神经元的输出值设置为 0,来减少模型的过拟合。这个函数中使用了一个参数
rate
,表示每个神经元被「关闭」的概率。这样做是为了防止模型过于依赖于某些特定的特征,而导致在新数据上的表现不佳。
Encoder Blocks: Multi-Head Attention & Feed Forward
然后看下 encoder blocks 代码:
## Blocks
for i in range(hp.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i)):
# 多头注意力
self.enc = multihead_attention(queries=self.enc,
keys=self.enc,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=False)
# 前馈神经网络
self.enc = feedforward(self.enc, num_units=[4*hp.hidden_units, hp.hidden_units])
上述代码是编码器(Encoder)的实现函数调用的流程,也是与麦克船长上面的模型原理介绍一致的,在定义时同样使用了 Embedding 层、Positional Encoding 层、Dropout 层、Multihead Attention 和 Feed Forward 操作。其中 Multihead Attention 在编码、解码中是不一样的,待会儿我们会在 Decoder 部分再提到,有自注意力层和 Encoder-Decoder 层。
- 超参数 hp.num_blocks 表示 Encoder Blocks 的层数,每一层都有一个 Multi-Head Attention 和一个 Feed Forward。
- 这个 Encoder 中的 Multi-Head Attention 是基于自注意力的(注意与后面的 Decoder 部分有区别)
causality
参数的意思是否使用 Causal Attention,它是 Self-Attention 的一种,但是只使用过去的信息,防止模型获取未来信息的干扰。一般对于预测序列中的某个时间步来说,只关注之前的信息,而不是整个序列的信息。这段代码中
causality
设置为了
False
,即会关注整个序列的信息。
15.4.2、解码过程
再看一下解码的流程:

Embedding
下面我们逐一看每段代码,主要关注与编码阶段的区别即可:
self.dec = embedding(self.decoder_inputs,
vocab_size=len(en2idx),
num_units=hp.hidden_units,
scale=True,
scope="dec_embed")
embedding
输入用的是
self.decoder_inputs- 词汇表尺寸用翻译后的输出语言英语词汇表长度
len(en2idx)
Key Masks
key_masks = tf.expand_dims(tf.sign(tf.reduce_sum(tf.abs(self.dec), axis=-1)), -1)
key_masks
输入变量用
self.dec
。
Positional Encoding & Drop out
# 位置编码
if hp.sinusoid:
self.dec += positional_encoding(self.decoder_inputs,
vocab_size=hp.maxlen,
num_units=hp.hidden_units,
zero_pad=False,
scale=False,
scope="dec_pe")
else:
self.dec += embedding(tf.tile(tf.expand_dims(tf.range(tf.shape(self.decoder_inputs)[1]), 0),
[tf.shape(self.decoder_inputs)[0], 1]),
vocab_size=hp.maxlen,
num_units=hp.hidden_units,
zero_pad=False,
scale=False,
scope="dec_pe")
self.dec *= key_masks
self.dec = tf.layers.dropout(self.dec,
rate=hp.dropout_rate,
training=tf.convert_to_tensor(is_training))
- 输入
self.decoder_inputs - 指定
vocab_size
参数
hp.maxlen
Decoder Blocks: Multi-Head Attention & Feed Forward
## 解码器模块
for i in range(hp.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i)):
# 多头注意力(自注意力)
self.dec = multihead_attention(queries=self.dec,
keys=self.dec,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=True,
scope="self_attention")
# 多头注意力(Encoder-Decoder 注意力)
self.dec = multihead_attention(queries=self.dec,
keys=self.enc,
num_units=hp.hidden_units,
num_heads=hp.num_heads,
dropout_rate=hp.dropout_rate,
is_training=is_training,
causality=False,
scope="vanilla_attention")
# 前馈神经网络
self.dec = feedforward(self.dec, num_units=[4*hp.hidden_units, hp.hidden_units])
- 在用
multihead_attention
函数解码器模块时,注意传入的参数
scope
区别,先是自注意力层,用参数
self_attention
,对应的
queries
是
self.dec
,
keys
也是
self.dec
。再是「Encoder-Decder Attention」用的是参数
vanilla_attention
,对应的
queries
来自解码器是
self.dec
,但
keys
来自编码器是是
self.enc
。
15.4.3、Embedding、Positional Encoding、Multi-Head Attention、Feed Forward
Embedding 函数实现
def embedding(inputs,
vocab_size,
num_units,
zero_pad=True,
scale=True,
scope="embedding",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# 创建一个名为 `lookup_table`、形状为 (vocab_size, num_units) 的矩阵
lookup_table = tf.get_variable('lookup_table',
dtype=tf.float32,
shape=[vocab_size, num_units],
initializer=tf.contrib.layers.xavier_initializer())
# lookup_table 的第一行插入一个全零行,作为 PAD 的词向量
if zero_pad:
lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),
lookup_table[1:, :]), 0)
# 在词向量矩阵 lookup_table 中查找 inputs
outputs = tf.nn.embedding_lookup(lookup_table, inputs)
# 对输出的词向量进行除以根号 num_units 的操作,可以控制词向量的统计稳定性。
if scale:
outputs = outputs * (num_units ** 0.5)
return outputs
Positional Encoding 函数实现
def positional_encoding(inputs,
num_units,
zero_pad=True,
scale=True,
scope="positional_encoding",
reuse=None):
N, T = inputs.get_shape().as_list()
with tf.variable_scope(scope, reuse=reuse):
# tf.range(T) 生成一个 0~T-1 的数组
# tf.tile() 将其扩展成 N*T 的矩阵,表示每个词的位置
position_ind = tf.tile(tf.expand_dims(tf.range(T), 0), [N, 1])
# First part of the PE function: sin and cos argument
position_enc = np.array([
[pos / np.power(10000, 2.*i/num_units) for i in range(num_units)]
for pos in range(T)])
# 用 numpy 的 sin 和 cos 函数对每个位置进行编码
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2]) # dim 2i
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2]) # dim 2i+1
# 将编码结果转为张量
lookup_table = tf.convert_to_tensor(position_enc)
# 将编码的结果与位置索引相关联,得到最终的位置编码
if zero_pad:
# 如果 zero_pad 参数为 True,则在编码结果的开头添加一个全 0 的向量
lookup_table = tf.concat((tf.zeros(shape=[1, num_units]),
lookup_table[1:, :]), 0)
outputs = tf.nn.embedding_lookup(lookup_table, position_ind)
# scale 参数为 True,则将编码结果乘上 num_units 的平方根
if scale:
outputs = outputs * num_units**0.5
return outputs
Multi-Head Attention 函数实现
def multihead_attention(queries,
keys,
num_units=None,
num_heads=8,
dropout_rate=0,
is_training=True,
causality=False,
scope="multihead_attention",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# Set the fall back option for num_units
if num_units is None:
num_units = queries.get_shape().as_list()[-1]
# Linear Projections
# 使用三个全连接层对输入的 queries、keys 分别进行线性变换,将其转换为三个维度相同的张量 Q/K/V
Q = tf.layers.dense(queries, num_units, activation=tf.nn.relu) # (N, T_q, C)
K = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
V = tf.layers.dense(keys, num_units, activation=tf.nn.relu) # (N, T_k, C)
# Split and concat
# 按头数 split Q/K/V,再各自连接起来
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, C/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, C/h)
# Multiplication
# 计算 Q_, K_, V_ 的点积来获得注意力权重
# 其中 Q_ 的维度为 (hN, T_q, C/h)
# K_ 的维度为 (hN, T_k, C/h)
# 计算出来的结果 outputs 的维度为 (h*N, T_q, T_k)
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1])) # (h*N, T_q, T_k)
# Scale
# 对权重进行 scale,这里除以了 K_ 的第三维的平方根,用于缩放权重
outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)
# Key Masking
# 这里需要将 keys 的有效部分标记出来,将无效部分设置为极小值,以便在之后的 softmax 中被忽略
key_masks = tf.sign(tf.reduce_sum(tf.abs(keys), axis=-1)) # (N, T_k)
key_masks = tf.tile(key_masks, [num_heads, 1]) # (h*N, T_k)
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1]) # (h*N, T_q, T_k)
paddings = tf.ones_like(outputs)*(-2**32+1)
outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# Causality = Future blinding
if causality:
# 创建一个与 outputs[0, :, :] 相同形状的全 1 矩阵
diag_vals = tf.ones_like(outputs[0, :, :]) # (T_q, T_k)
# 对 diag_vals 进行处理,返回一个下三角线矩阵
tril = tf.linalg.LinearOperatorLowerTriangular(diag_vals).to_dense() # (T_q, T_k)
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1]) # (h*N, T_q, T_k)
# 将 masks 为 0 的位置的 outputs 值设置为一个非常小的数
# 这样会导致这些位置在之后的计算中对结果产生非常小的影响,从而实现了遮盖未来信息的功能
paddings = tf.ones_like(masks)*(-2**32+1)
outputs = tf.where(tf.equal(masks, 0), paddings, outputs) # (h*N, T_q, T_k)
# 对于每个头的输出,应用 softmax 激活函数,这样可以得到一个概率分布
outputs = tf.nn.softmax(outputs) # (h*N, T_q, T_k)
# Query Masking
# 对于查询(queries)进行 masking,这样可以避免输入序列后面的词对之前词的影响
query_masks = tf.sign(tf.reduce_sum(tf.abs(queries), axis=-1)) # (N, T_q)
query_masks = tf.tile(query_masks, [num_heads, 1]) # (h*N, T_q)
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]]) # (h*N, T_q, T_k)
outputs *= query_masks # broadcasting. (N, T_q, C)
# Dropouts & Weighted Sum
# 对于每个头的输出,应用 dropout 以及进行残差连接
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=tf.convert_to_tensor(is_training))
outputs = tf.matmul(outputs, V_) # ( h*N, T_q, C/h)
# Restore shape
# 将每个头的输出拼接起来,使用 tf.concat 函数,将不同头的结果按照第二维拼接起来
# 得到最终的输出结果,即经过多头注意力计算后的结果
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, C)
# Residual connection
outputs += queries
# Normalize
outputs = normalize(outputs) # (N, T_q, C)
return outputs
Feed Forward 函数实现
下面是
前馈神经网络层
的定义,这是一个非线性变换,这里用到了一些卷积神经网络(CNN)的知识,我们来看下代码再解释:
def feedforward(inputs,
num_units=[2048, 512],
scope="multihead_attention",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# Inner layer
params = {"inputs": inputs, "filters": num_units[0], "kernel_size": 1,
"activation": tf.nn.relu, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# Readout layer
params = {"inputs": outputs, "filters": num_units[1], "kernel_size": 1,
"activation": None, "use_bias": True}
outputs = tf.layers.conv1d(**params)
# 连接一个残差网络 ResNet
outputs += inputs
# 归一化后输出
outputs = normalize(outputs)
return outputs
- 先是使用了一个卷积层(conv1d)作为 inner layer、一个卷积层作为 readout layer,卷积核大小都为 1。
filters
参数用来控制卷积层中输出通道数量,inner layer 的输出通道数设置为
num_units[0]
,readout layer 的设置为
num_units[1]
。有时也会把这个解释为神经元数量。这两个的默认分别为 2048、512,调用时传入的是超参数的
[4 * hidden_units, hidden_units]
。- 其中 inner layer 用
ReLU
作为激活函数,然后连接一个残差网络 RedNet,把 readout layer 的输出加上原始的输入。 - 最后使用
normalize
归一化处理输出,再返回。下面来看下
normalize
函数。
def normalize(inputs,
epsilon = 1e-8,
scope="ln",
reuse=None):
with tf.variable_scope(scope, reuse=reuse):
# 输入数据的形状
inputs_shape = inputs.get_shape()
params_shape = inputs_shape[-1:]
# 平均数、方差
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True)
# 拉伸因子 beta
beta= tf.Variable(tf.zeros(params_shape))
# 缩放因子 gamma
gamma = tf.Variable(tf.ones(params_shape))
# 归一化:加上一个非常小的 epsilon,是为了防止除以 0
normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )
outputs = gamma * normalized + beta
return outputs
- 该函数实现了 Layer Normalization,用于在深度神经网络中解决数据的不稳定性问题。
15.4.4、编码和解码完成后的操作
解码器后的
Linear & Softmax
:
# 全连接层得到的未经过归一化的概率值
self.logits = tf.layers.dense(self.dec, len(en2idx))
# 预测的英文单词 idx
self.preds = tf.to_int32(tf.arg_max(self.logits, dimension=-1))
self.istarget = tf.to_float(tf.not_equal(self.y, 0))
# 正确预测数量,除以所有样本数,得到准确率
self.acc = tf.reduce_sum(tf.to_float(tf.equal(self.preds, self.y))*self.istarget)/ (tf.reduce_sum(self.istarget))
# 记录了模型的准确率的值,用于 tensorboard 可视化
tf.summary.scalar('acc', self.acc)
训练集数据处理时,经过
Linear & Softmax
之后的最后处理如下。这里用到了
tf.nn.softmax_cross_entropy_with_logits
交叉熵损失,来计算模型的错误率
mean_loss
,并使用 Adam 优化器
AdamOptimizer
来优化模型参数。
# 使用 label_smoothing 函数对真实标签进行标签平滑,得到 self.y_smoothed
self.y_smoothed = label_smoothing(tf.one_hot(self.y, depth=len(en2idx)))
下面这段代码实现了一种叫做「label Smoothing」的技巧。
def label_smoothing(inputs, epsilon=0.1):
# 获取输入的类别数,并将其赋值给变量 K
K = inputs.get_shape().as_list()[-1] # number of channels
return ((1-epsilon) * inputs) + (epsilon / K)
在训练过程中,样本的标签被表示为一个二维矩阵,其中第一维表示样本的编号,第二维表示样本的标签。这个矩阵的形状就是 (样本数, 类别数),所以类别数对应的就是最后一维。具体到这个模型用例里,第一个维度是德语样本句子数,最后一维就是英语词汇量的大小。
用于解决在训练模型时出现的过拟合问题。在标签平滑中,我们给每个样本的标签加上一些噪声,使得模型不能完全依赖于样本的标签来进行训练,从而减少过拟合的可能性。具体来说,这段代码将输入的标签
inputs
乘上
1-epsilon
,再加上
epsilon / K
,其中
epsilon
是平滑因子,
K
是标签类别数(英语词汇量大小)。这样就可以在训练过程中让模型对标签的预测更加平稳,并且降低过拟合的风险。
然后我们看后续的操作。
# 对于分类问题来说,常用的损失函数是交叉熵损失
self.loss = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.y_smoothed)
self.mean_loss = tf.reduce_sum(self.loss * self.istarget) / (tf.reduce_sum(self.istarget))
# Training Scheme
self.global_step = tf.Variable(0, name='global_step', trainable=False)
# Adam 优化器 self.optimizer,用于优化损失函数
self.optimizer = tf.train.AdamOptimizer(learning_rate=hp.lr, beta1=0.9, beta2=0.98, epsilon=1e-8)
# 使用优化器的 minimize() 函数创建一个训练操作 self.train_op,用于更新模型参数。这个函数会自动计算梯度并应用更新
self.train_op = self.optimizer.minimize(self.mean_loss, global_step=self.global_step)
# 将平均损失写入 TensorFlow 的 Summary 中,用于 tensorboard 可视化
tf.summary.scalar('mean_loss', self.mean_loss)
# 将所有的 summary 合并到一起,方便在训练过程中写入事件文件
self.merged = tf.summary.merge_all()
15.5、效果评价
def eval():
# 创建一个处理测试数据集的 Graph 实例
g = Graph(is_training=False)
print("Graph loaded")
# 加载测试数据
X, Sources, Targets = load_test_data()
de2idx, idx2de = load_de_vocab()
en2idx, idx2en = load_en_vocab()
# Start session
with g.graph.as_default():
# TensorFlow 中用于管理训练的一个类
# 它可以帮助你轻松地管理训练过程中的各种资源,如模型参数、检查点和日志
sv = tf.train.Supervisor()
# 创建一个会话
with sv.managed_session(config=tf.ConfigProto(allow_soft_placement=True)) as sess:
# 恢复模型参数
sv.saver.restore(sess, tf.train.latest_checkpoint(hp.logdir))
print("Restored!")
# 获取模型名称
mname = open(hp.logdir + '/checkpoint', 'r').read().split('"')[1] # model name
## Inference
if not os.path.exists('results'): os.mkdir('results')
# 初始化结果文件
with codecs.open("results/" + mname, "w", "utf-8") as fout:
list_of_refs, hypotheses = [], []
# 循环处理数据
for i in range(len(X) // hp.batch_size):
# 获取小批量数据
x = X[i*hp.batch_size: (i+1)*hp.batch_size]
sources = Sources[i*hp.batch_size: (i+1)*hp.batch_size]
targets = Targets[i*hp.batch_size: (i+1)*hp.batch_size]
# 使用自回归推理(Autoregressive inference)得到预测结果
preds = np.zeros((hp.batch_size, hp.maxlen), np.int32)
for j in range(hp.maxlen):
_preds = sess.run(g.preds, {g.x: x, g.y: preds})
preds[:, j] = _preds[:, j]
# 将预测结果写入文件
for source, target, pred in zip(sources, targets, preds): # sentence-wise
got = " ".join(idx2en[idx] for idx in pred).split("</S>")[0].strip()
fout.write("- source: " + source +"\n")
fout.write("- expected: " + target + "\n")
fout.write("- got: " + got + "\n\n")
fout.flush()
# bleu score
ref = target.split()
hypothesis = got.split()
if len(ref) > 3 and len(hypothesis) > 3:
list_of_refs.append([ref])
hypotheses.append(hypothesis)
# 计算 BLEU 分数,并将其写入文件
score = corpus_bleu(list_of_refs, hypotheses)
fout.write("Bleu Score = " + str(100*score))
if __name__ == '__main__':
eval()
print("Done")
第 16 节 · Kyubyong Transformer 的性能表现和一些问题
评估结果文件的最后一行有
Bleu Score = 6.598452846670836
表示这个翻译模型的翻译结果与参考翻译重叠程度比较高,翻译质量较好。不过需要注意的是,BLEU 分数不能完全反映翻译质量,因为它不能评估语法,语义,语调等方面的问题。
另外前面我们在代码中已经将过程数据保存在 logdir 下了,就是为了后续方便可视化,我们可以用 TensorBoard 来可视化,具体使用方法如下:
mikecaptain@local $ tensorboard --logdir logdir
然后在浏览器里查看
http://localhost:6006
,示例如下:
回顾整个模型的代码实现,我们可以更直观地看到这个 Transformer 能够较好地捕捉长距离依赖关系,提高翻译质量。然而,Kyubyong Transformer 的实现存在一些问题。该 Transformer 模型在训练过程中还需要调整许多超参数,如学习率(learning rate)、batch size 等,不同的任务可能需要不同的超参数调整。
结尾 · Transformer 问世后的这些年
Transformer 的优势显而易见:
- 更快 —— 并行性好:在 Transformer 诞生之前,RNN 是 NLP 领域的主流模型,但是 RNN 并行性差(序列串行处理)。
- 不健忘 —— 词距离缩短为 1:RNN 模型处理长文本内容已丢失(在 RNN 模型中意味着词的空间距离长)。
- 处理不同长度序列:不需要输入数据的序列是固定长度的。
- 易于转移学习。
因此基于 Transformer 原理的模型,在众多 NLP 任务中都取得了卓越的表现。
说到底机器学习(Machine Learning)领域还是一个实验科学,并且是离工业界极近的实验科学。机器学习看待实验结果的角度,不是为了拿实验结果总结抽象后推动理论科学发展。机器学习的实验结果是要被评价的,其效果有客观量化评估标准。所以机器学习,一切以结果说话。基于 Transformer 架构 Decoder 部分诞生了 OpenAI 的 GPT 大模型,基于其架构的 Encoder 部分诞生了 Google 的 BERT 大模型,他们两个都诞生于 2018 年。这几年基于 Transformer 的各种优化思想不断出现,其集大成者便是 2022 年年底基于 GPT-3.5 或者说基于 InstructGPT 的 ChatGPT。
感谢你有耐心看完本篇近 8 万字长文,因为是船长的技术笔记,所以对于关键点梳理得细致了些。后续,我讲和大家一起聊聊 AIGC 的当下,如果说本篇内容更像一个教程(对缘起技术的深入),那么后续我们的探讨则可能更像一篇报告了(对眼前学界与业界发展现状的综述),我们将更关注文章「前言」部分的两个议题:1)如果认为通过图灵测试代表着 AGI(Artificial General Intelligence,通用人工智能)的话,当下 NLP,乃至 AGI 发展到什么程度了?2)未来一些年内,AGI 的发展路线可能会是怎样的?
AI 终将颠覆各行各业,阿里人有责任花些时间关注前沿的发展脉搏,欢迎大家在钉钉或
微信(id:sinosuperman)
上与我交流。
最后,麦克船长给大家拜个晚年,祝大家兔年里健康快乐。
参考
- https://web.stanford.edu/~jurafsky/slp3/3.pdf
- https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
- 《自然语言处理:基于预训练模型的方法》车万翔 等著
- https://cs.stanford.edu/people/karpathy/convnetjs/
- https://arxiv.org/abs/1706.03762
- https://arxiv.org/abs/1512.03385
- https://github.com/Kyubyong/transformer/
- http://jalammar.github.io/illustrated-transformer/
- https://towardsdatascience.com/this-is-how-to-train-better-transformer-models-d54191299978
- 《自然语言处理实战:预训练模型应用及其产品化》安库·A·帕特尔 等著
- https://lilianweng.github.io/posts/2018-06-24-attention/
- https://github.com/lilianweng/transformer-tensorflow/
- 《基于深度学习的道路短期交通状态时空序列预测》崔建勋 著
- https://www.zhihu.com/question/325839123
- https://luweikxy.gitbook.io/machine-learning-notes/self-attention-and-transformer
- 《Python 深度学习(第 2 版)》弗朗索瓦·肖莱 著
- https://en.wikipedia.org/wiki/Attention_(machine_learning)
- https://zhuanlan.zhihu.com/p/410776234
- https://www.tensorflow.org/tensorboard/get_started
- https://paperswithcode.com/method/multi-head-attention
- https://zhuanlan.zhihu.com/p/48508221
- https://www.joshbelanich.com/self-attention-layer/
- https://learning.rasa.com/transformers/kvq/
- http://deeplearning.stanford.edu/tutorial/supervised/ConvolutionalNeuralNetwork/
- https://zhuanlan.zhihu.com/p/352898810
- https://towardsdatascience.com/beautifully-illustrated-nlp-models-from-rnn-to-transformer-80d69faf2109
- https://medium.com/analytics-vidhya/understanding-q-k-v-in-transformer-self-attention-9a5eddaa5960