1、安装opencv
1.1 弯路
opencv安装 先看百度怎么安装,然后有问题看官网
sudo apt update更新ubuntu的源
用python安装方式 就安装人家编译好的东西
安装最新的就要 源码安装,遇到问题就百度,源码安装需要 一系列构建工具和依赖软件包
选择的是 源码安装
find命令可以在指定目录及其子目录下搜索文件。如果你不确定文件位于哪个目录,可以从根目录开始搜索
sudo find / -name OpenCVConfig.cmake
这个命令会从根目录/开始搜索名为OpenCVConfig.cmake的文件。-name参数指明了要搜索的文件名
或者使用locate命令:
locate命令使用预先构建的数据库快速定位文件的路径。在首次使用之前,你可能需要更新或初始化这个数据库
sudo updatedb
更新数据库后,你可以使用locate命令来搜索OpenCVConfig.cmake文件
locate OpenCVConfig.cmake
完成之后发现安装的是cpp的
要确保在当前激活的Python环境中安装OpenCV
1.2 解决
最后python还是找不到,最后安装opencv-python解决
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
验证是否成功
import cv2
print(cv2.__version__)
直接就安上4.9.0了
2、显示 存储 缩放图像
2.1 显示图像
import cv2
import numpy as np
img = cv2.imread('image.jpg') # 读取图像
cv2.imshow('src',img) # 显示图像,图像显式名字src
cv2.waitKey(2000) # 等待按键按下,等待2秒( 2000: 等待2秒(2000ms) 0:一直等待
2.2 存储图像
# 读取灰色图像(默认彩色图,cv2.IMREAD_GRAYSCALE 灰度图,cv2.IMREAD_UNCHANGED 包含alpha通道)
img = cv2.imread('image.jpg',cv2.IMREAD_GRAYSCALE)
cv2.imwrite('grayImage.png',img) # 存储图像(会根据后缀,自动转换为对应格式)
2.3 图像缩放
img = cv2.resize(img,(160,120)) #//更改宽(列)=160 ,高(行)=120
3、读取图像数据
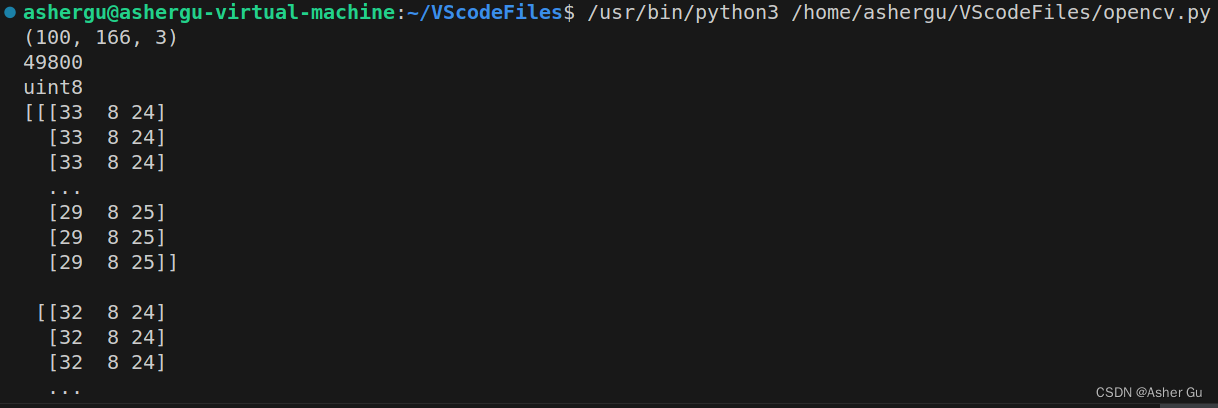
img = cv2.imread('image.jpg') # 读取图像(返回的是numpy,方便后续数据处理)
print(img.shape) # 图像的高(行数)h, 宽(列数)w, 通道数c -- 如(240,320,3)
print(img.size) # 图像大小(总像素数目) -- 如230400
print(img.dtype) # 数据类型 -- 如 uint8
print(img) # 输出图像的数据
运行结果:
4、更改图像数据
通过 改像素点 或者 切片的区域
import cv2
import numpy as np
img = cv2.imread("image.jpg")
print(img[3,5]) # 显示某位置(行3列5)的像素值( 如 [53 34 29] 它是有三通道 B G R 组成)
img[3,5] = (0,0,255) # 更改该位置的像素
img[0:100,100:200,0] = 255 # 更改区域(0~100行 100~200列) B通道的值为255
img[100:200,200:300,1] = 255
img[200:300,300:400,2] = 255
cv2.imshow('changeData',img) # 显示可看到图像有 蓝色 绿色 红色的方块区域
cv2.waitKey(2000)
5、图像通道分离
#---方式一(opencv自带的函数)
import cv2
import numpy as np
img = cv2.imread("image.jpg")
b, g, r = cv2.split(img) # 分离为blue,green ,red 三色通道(注:opencv 通道顺序是BGR,而不是主流的RGB)
# img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) 调整通道顺序为RGB
# 只分离一个 b = cv2.split(img)[0] 0:b 1:g 2:r
cv2.imshow("Blue", r)
print(r.shape) # (240,320)
cv2.imshow("Red", g)
cv2.imshow("Green", b)
cv2.waitKey(0)
#---方式二(numpy的函数)
import cv2
import numpy as np
img = cv2.imread("image.jpg")
print(img.shape)
r = np.zeros((img.shape[0],img.shape[1]), dtype=img.dtype) #//创建numpy空间
r[:,:] = img[:,:,2] #//拷贝r通道的数据
cv2.imshow("Red", r)
cv2.waitKey(0)
6、图像通道合并
import cv2
import numpy as np
img = cv2.imread("image.jpg")
b, g, r = cv2.split(img)
merged = cv2.merge([b,g,r]) # 合并通道,如果换成 [r, g, b]就和原图像不一样了
print(merged.shape) # (240, 320, 3) 合并后顺序是(高度 宽度 通道数)
cv2.imshow("Merged", merged)
cv2.waitKey(0)
7、图像拼接
import os
import cv2
import numpy as np
def mergePic(files):
baseimg= cv2.imread(files[0])
for file in files[1:]: # 遍历除第一个外的numpy
img=cv2.imread(file)
baseimg=np.append(baseimg,img,axis=1) # 横向追加图像(axis=0时为纵向)
cv2.imwrite('mergeCv2.png',baseimg)
path = "./pic/" # 注:该路径下的图像,必须是相同格式,尺寸的图像
images = [] #先存储所有的图像的名称
for root, dirs, files in os.walk(path):
for f in files :
images.append(path+f)
print(images,len(images))
mergePic(images)
8、图像混合(虚化后混合)
import cv2
import numpy as np
img1=cv2.imread('image.jpg')
img2=cv2.imread('opencv_logo.jpg')
img2 = cv2.resize(img2,(img1.shape[1],img1.shape[0])) # 注意opencv的resize和shape是反的
print(img1.shape,img1.size,img1.dtype)
print(img2.shape,img2.size,img2.dtype)
dst=cv2.addWeighted(img1,0.7,img2,0.3,0) # 注:不同尺寸会报错,可采用resize或roi方式处理
# 0.7/0.3为图像混合占的比重,在0通道
cv2.imshow('dst',dst)
cv2.waitKey(0)
9、图像融合 (局部区域控制 ROI操作 Region Of Interest)
阈值 //选择合适阈值 与图像中像素比较 -> 分离出需要的图像
融合原理 //像素值 0 ~255 ,用阈值区分出logo,再用位与运算,用logo前景与原图roi背景相加方式。
{//抠图
import cv2
import numpy as np
img = cv2.imread('original.jpg')
rect = (275, 120, 170, 320) # 抠图的矩形区域(x,y,w,h) -> 区域设置 将影响抠图效果
mask = np.zeros(img.shape[:2], np.uint8)
bgModel = np.zeros((1,65), np.float64) # 背景
fgModel = np.zeros((1,65), np.float64) # 前景
cv2.grabCut(img, mask, rect, bgModel, fgModel, 5, cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype(np.uint8)
out = img * mask2[:, :, np.newaxis]
cv2.imshow('output', out)
cv2.imwrite('koutu.png',out)
cv2.waitKey(3000)
# 注:抠图后的背景,全为0,黑色
}
{//图像的裁剪
import cv2
import numpy as np
logo = cv2.imread('koutu.png')
logo = logo[130:435,280:420] #//裁剪矩形区域 ( 行从130到435,列从280到420 )
logo = cv2.resize(logo,(int(logo.shape[1]/2),int(logo.shape[0]/2))) #//调整大小
print(logo.shape,logo.size)
cv2.imshow('logo',logo)
cv2.waitKey(3000)
cv2.imwrite('logo.png',logo)
}
{# 图像融合(添加logo)
import cv2
import numpy as np
thresh = 2 # 阈值设为2,因logo是处理过的,背景全为0,故2能很好得区分
pic = cv2.imread('image.jpg') # 原始图像
logo = cv2.imread('logo.png') # logo图像(是用grabCut抠图后所得,背景全为0,黑色)
rows,cols,channels = logo.shape # 得到logo的尺寸
roi = pic[0:rows,0:cols] # 在原始图像中截取logo图像大小的部分
logoGray = cv2.cvtColor(logo,cv2.COLOR_BGR2GRAY) # 将logo图像灰度化
ret,mask = cv2.threshold(logoGray,thresh,255,cv2.THRESH_BINARY) # 将logo灰度图固定阈值二值化后赋给mask (logo部分全为255白色,背景为0)
# cv2.threshold(src, thresh, maxval, type)
# 返回值: 输出图(如mask)
# 参1: 输入图 (只能输入单通道图像,通常来说为灰度图)
# 参2: 阈值
# 参3: 最大值(当像素值,大于阈值(或小于,由参4决定)时被改为该值)
# 参4: 阈值类型
# THRESH_BINARY 像素值大于阈值时,改为最大值.反之设为0.
# THRESH_BINARY_INV 像素值大于阈值时,设为0,反之改为最大值
# THRESH_TRUNC 大于阈值设为阈值,小于的保持不变
# THRESH_TOZERO 小于阈值设为0, 大于的保持不变
# THRESH_TOZERO_INV 大于阈值设为0, 小于的保持不变
mask_inv = cv2.bitwise_not(mask) # 将mask按位取反(即白变黑,黑变白)
log_fg = cv2.bitwise_and(logo,logo,mask = mask) # 保留logo 前景(和mask按位与运算,即保留255白色logo部分)
roi_bg = cv2.bitwise_and(roi,roi,mask = mask_inv) # 保留roi做背景(和mask_inv按位与运算,即保留255白色背景部分)
dst = cv2.add(log_fg,roi_bg) # 图像叠加(两图像矩阵,对应位置的像素值相加)
pic[0:rows,0:cols] = dst # 叠加到原图像上
cv2.imshow('pic_with_logo',pic)
cv2.imwrite('pic_with_logo.png',logo)
cv2.waitKey(4000)
}
{# 完整代码
# 注:有注释的地方 参数需更改
import cv2
import numpy as np
rect = (275, 120, 170, 320) # 抠图的矩形区域(x,y,w,h) -> 区域设置 将影响抠图效果
img = cv2.imread('original.jpg') # 待抠图的图像
pic = cv2.imread('image.jpg') # 叠加到的目标图像
mask = np.zeros(img.shape[:2], np.uint8)
bgModel = np.zeros((1,65), np.float64)
fgModel = np.zeros((1,65), np.float64)
cv2.grabCut(img, mask, rect, bgModel, fgModel, 5, cv2.GC_INIT_WITH_RECT)
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype(np.uint8)
out = img * mask2[:, :, np.newaxis]
logo = out[130:435,280:420] # 剪矩形区域 ( 行从130到435,列从280到420 )
logo = cv2.resize(logo,(int(logo.shape[1]/2),int(logo.shape[0]/2))) # 调整大小(2 表示缩写一半)
thresh = 2
rows,cols,channels = logo.shape
roi = pic[0:rows,0:cols ]
logoGray = cv2.cvtColor(logo,cv2.COLOR_BGR2GRAY)
ret,mask =cv2.threshold(logoGray,thresh,255,cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
log_fg = cv2.bitwise_and(logo,logo,mask = mask)
roi_bg = cv2.bitwise_and(roi,roi,mask = mask_inv)
dst = cv2.add(log_fg,roi_bg)
pic[0:rows,0:cols] = dst
cv2.imshow('pic_with_logo',pic)
cv2.imwrite('pic_with_logo.png',logo)
cv2.waitKey(4000)
}
10、金字塔融合(无缝连接) ->全景图
图像金字塔 https://blog.csdn.net/zaishuiyifangxym/article/details/90167880
import cv2
import numpy as np,sys
A = cv2.imread('apple.jpg')
B = cv2.imread('orange.jpg')
# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpA.append(G)
# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in range(6):
G = cv2.pyrDown(G)
gpB.append(G)
# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpA[i])
L = cv2.subtract(gpA[i-1],GE)
lpA.append(L)
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in range(5,0,-1):
GE = cv2.pyrUp(gpB[i])
L = cv2.subtract(gpB[i-1],GE)
lpB.append(L)
# Now add left and right halves of images in each level
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols//2], lb[:,cols//2:]))
LS.append(ls)
# now reconstruct
ls_ = LS[0]
for i in range(1,6):
ls_ = cv2.pyrUp(ls_)
ls_ = cv2.add(ls_, LS[i])
# image with direct connecting each half
real = np.hstack((A[:,:cols//2],B[:,cols//2:]))
cv2.imwrite('Pyramid_blending2.jpg',ls_)
cv2.imwrite('Direct_blending.jpg',real)
11、图像平移
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('image.jpg')
H = np.float32([[1,0,100], # 创建变换矩阵,100:沿x轴移动距离 50:沿y轴移动距离
[0,1,50]])
rows,cols = img.shape[:2] # 取图片的行数和列数(开始到2之间,即shape[0] shape[1])
newImg = cv2.warpAffine(img,H,(rows,cols)) # 仿射变换
# img:变换前图像
# H:变换矩阵
# (rows,cols)):变换后的大小
plt.subplot(121) # 子图 1行2列1象限
plt.imshow(img)
plt.subplot(122) # 子图 1行2列2象限
plt.imshow(newImg)
plt.show() # 显示 matplotlib图

cv2.warpAffine() 是 OpenCV 中用于执行仿射变换的函数之一。它可以用来对图像进行平移、旋转、缩放等操作
import cv2
import numpy as np
# 读取图像
image = cv2.imread('input_image.jpg')
# 定义平移矩阵,这里将图像向右平移100像素,向下平移50像素
tx = 100
ty = 50
translation_matrix = np.float32([[1, 0, tx],
[0, 1, ty]])
# 执行仿射变换
translated_image = cv2.warpAffine(image, translation_matrix, (image.shape[1], image.shape[0]))
# 显示原始图像和平移后的图像
cv2.imshow('Original Image', image)
cv2.imshow('Translated Image', translated_image)
cv2.waitKey(0)
cv2.destroyAllWindows()

12、图像旋转
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('image.jpg')
rows,cols = img.shape[:2]
M = cv2.getRotationMatrix2D((cols/2,rows/2),45,1) # 2D矩阵旋转变换
# 参1:旋转中心 参2:旋转角度 参3:缩放比例
newImg = cv2.warpAffine(img,M,(rows,cols)) # 仿射变换
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(newImg)
plt.show()
13、图像翻转
import cv2
import numpy as np
img = cv2.imread('image.jpg') # 读取图像
flipped = cv2.flip(img, 1) # 翻转图像(1:横向 0:纵向 -1:横向和纵向)
cv2.imshow("Flipped Horizontally", flipped)
cv2.waitKey(2000)
14、图像拉伸
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('image.jpg')
rows,cols = img.shape[:2]
pts1 = np.float32([[50,50],[200,50],[50,200]]) # 变换前位置(通过三个点 来确定)
pts2 = np.float32([[10,100],[200,50],[100,250]]) # 变换后位置(通过三个点 来确定)
M = cv2.getAffineTransform(pts1, pts2) # 仿射变换(参1:变换前位置 参2:变换后位置)
res = cv2.warpAffine(img,M,(rows,cols))
plt.subplot(121)
plt.imshow(img)
plt.subplot(122)
plt.imshow(res)
plt.show()
15、绘制图形
# 直线
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = np.zeros((512,512,3),np.uint8) # 生成一个空彩色图像
cv2.line(img,(0,0),(511,511),(255,155,5),5) # 画线(参1:图像 参2:点1坐标 参3:点2坐标 参4:颜色 )
plt.imshow(img,'brg')
plt.show()
# 方形
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = np.zeros((512,512,3),np.uint8) # 生成一个空彩色图像
cv2.rectangle(img,(20,20),(411,411),(55,255,155),5) # 矩形的两个点(参2:左上角 与参3:右下角)
plt.imshow(img,'brg')
plt.show()
# 圆形
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = np.zeros((512,512,3),np.uint8) # 生成一个空彩色图像
cv2.circle(img,(200,200),50,(55,255,155),1) # 参2:圆心 参3:半径
plt.imshow(img,'brg')
plt.show()
16、摄像头显示
import cv2
img_path = 'camera.jpg' # 等待识别的图像
# 采样图片
def CatchUsbVideo(window_name):
cv2.namedWindow(window_name)
cap = cv2.VideoCapture(0) # 视频来源,从摄像头获得 (也可以来自一段已存好的视频)
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
# 每300ms刷新一次显示,输入‘q’退出程序
cv2.imwrite(img_path, frame)
cv2.putText(frame, " is what", (30, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0) , 4) #//添加文字显示
cv2.imshow(window_name, frame)
c = cv2.waitKey(10)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
CatchUsbVideo("get pic v1.0")
报错:
[ERROR:0@1.920] global obsensor_uvc_stream_channel.cpp:159 getStreamChannelGroup Camera index out of range
解决文章链接 https://blog.csdn.net/DSK_981029/article/details/111143231
1)ls /dev/ 查看有没有设备文件
发现以v字符开头的设备中并没有与摄像头有关的信息(应该有videoX设备)
任何设备 文件是Linux上的抽象
2)在虚拟机菜单下 选择 可移动设备,找到摄像头,连接


























![[计网初识1] TCP/UDP](https://i-blog.csdnimg.cn/direct/785dd1fb50fc46fb89e9cd57cd3a044b.png)