深入探索大语言模型
引言
大语言模型(LLM)是现代人工智能领域中最为重要的突破之一。这些模型在自然语言处理(NLP)任务中展示了惊人的能力,从文本生成到问答系统,无所不包。本文将从多个角度全面介绍大语言模型的基础知识、发展历程、技术特点、评估方法以及实际应用示例,为读者提供深入了解LLM的全景视图。
1. 大语言模型(LLM)背景
1.1 定义
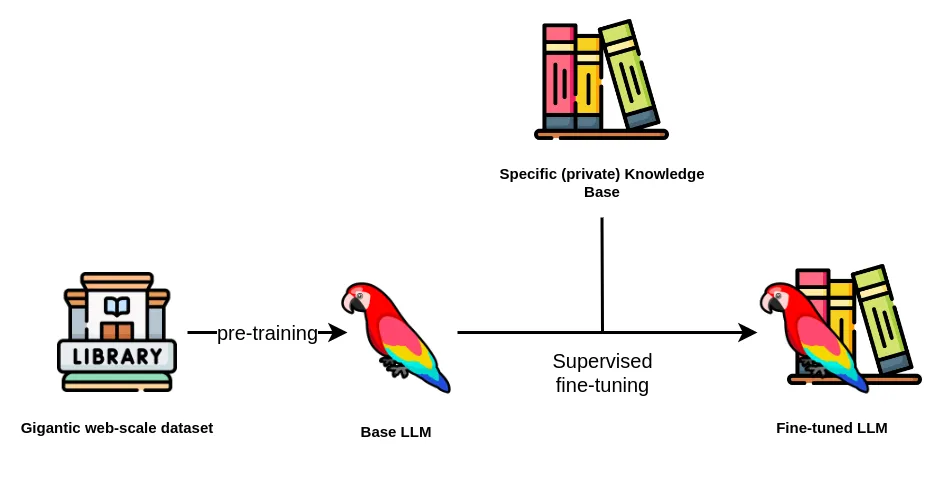
大语言模型(Large Language Model, LLM)是包含数千亿参数的人工智能模型,设计用于理解和生成自然语言文本。通过大量数据的训练,LLM能够捕捉语言的复杂结构和语义关系,使其在多种NLP任务中表现优异。
1.2 功能
大语言模型具备广泛的功能,包括但不限于:
- 文本分类:自动将文本归类到预定义的类别中。
- 问答系统:基于输入的问题生成准确的答案。
- 翻译:在不同语言之间进行文本翻译。
- 对话:与用户进行自然语言对话,模拟人类交流。
1.3 代表模型
目前,几种具有代表性的大语言模型包括:
- GPT-3:由OpenAI开发,拥有1750亿参数,能够生成高质量的文本。
- ChatGPT:基于GPT-3进行优化,专注于对话生成任务。
- GLM:由Tsinghua University开发,提供中文和英文支持。
- BLOOM:开源的大型多语言模型。
- LLaMA:Meta发布的轻量级大语言模型。
2. 语言模型发展阶段
2.1 第一阶段:自监督训练和新颖模型架构
在这一阶段,语言模型的研究重点是引入自监督训练目标和创新的模型架构,如Transformer。这些模型遵循预训练和微调范式,即首先在大规模无标签数据上进行预训练,然后在特定任务上进行微调。代表模型包括:
- BERT(Bidirectional Encoder Representations from Transformers):通过双向训练方法捕捉上下文信息。
- GPT(Generative Pre-trained Transformer):使用自回归方法进行文本生成。
- XLNet:融合自回归和自编码器优点,提高了语言模型的表现。
2.2 第二阶段:扩大模型参数和训练语料规模
这一阶段的主要特征是显著扩大模型参数和训练语料的规模,探索不同的模型架构以提升性能。代表模型有:
- BART(Bidirectional and Auto-Regressive Transformers):结合了BERT和GPT的优点,用于生成和理解任务。
- T5(Text-To-Text Transfer Transformer):将所有NLP任务统一为文本到文本的框架。
- GPT-3:通过超大规模参数和训练数据,实现了前所未有的文本生成能力。
2.3 第三阶段:AIGC时代与自回归架构
进入AIGC(AI Generated Content)时代,模型参数规模进一步扩大,达到千万亿级别,模型架构为自回归,注重与人类交互对齐。代表模型包括:
- InstructionGPT:专注于理解和执行自然语言指令。
- ChatGPT:优化用于对话生成,提供更自然和连贯的交互体验。
- Bard:Google推出的对话模型,专注于信息检索和对话。
- GPT-4:最新一代的大语言模型,进一步提升了模型的智能水平和应用广度。
3. 语言模型的通俗理解与标准定义
3.1 通俗理解
通俗地讲,语言模型是一个能够计算句子概率的模型,用于判断句子是否符合人类的语言习惯。例如,句子“猫在桌子上”比“桌子在猫上”更符合语言习惯,语言模型会给前者更高的概率。
3.2 标准定义
从技术角度定义,语言模型通过计算给定词序列( S = {w_1, w_2, \ldots, w_n} )发生的概率( P(S) )来进行工作。该概率可以分解为条件概率的乘积:
[ P(S) = P(w_1, w_2, \ldots, w_n) = \prod_{i=1}^{n} P(w_i \mid w_1, w_2, \ldots, w_{i-1}) ]
这种分解方法称为链式法则(chain rule),它允许模型逐词预测下一个词的概率,从而生成符合语言习惯的句子。
4. 语言模型技术发展
4.1 基于规则和统计的语言模型
最早的语言模型基于规则和统计方法,如N-gram模型。N-gram模型通过计算固定长度的词序列(如二元词组或三元词组)的概率来进行工作。然而,这些模型存在数据稀疏和泛化能力差的问题,难以应对大规模语料和复杂语言现象。
4.2 神经网络语言模型
随着计算能力的提升,神经网络语言模型逐渐成为主流。相比N-gram模型,神经网络能够更好地捕捉语言的上下文关系和语义信息,显著提高了模型的泛化能力和表现。然而,早期的神经网络语言模型在处理长序列时仍存在挑战。
4.3 基于Transformer的预训练语言模型
Transformer模型的引入是语言模型技术发展的重要里程碑。Transformer通过自注意力机制(self-attention)实现了对长序列的高效建模,使得模型能够捕捉远距离的依赖关系。基于Transformer的预训练语言模型,如GPT、BERT、T5等,进一步提升了NLP任务的表现,成为现代语言模型的基石。
5. 大语言模型的特点
5.1 优点
- 智能:大语言模型能够理解和生成复杂的自然语言文本,展现出接近人类的语言能力。
- 能与人类沟通:这些模型可以进行自然语言对话,与用户进行高效、自然的交流。
- 使用插件自动信息检索:通过集成信息检索插件,大语言模型能够实时获取和处理信息,提高了回答问题的准确性和时效性。
5.2 缺点
- 参数量大:大语言模型通常包含数百亿到数千亿的参数,导致模型非常庞大。
- 算力要求高:训练和推理过程需要大量的计算资源,成本高昂。
- 训练时间长:由于模型规模庞大,训练过程通常需要数周甚至数月的时间。
- 可能生成有害或有偏见内容:模型可能会生成不准确、有害或有偏见的内容,需要进行严格的监控和调整。
6. 语言模型的评估指标
6.1 常用指标
- 准确率(Accuracy):用于评估分类任务,表示模型预测正确的样本比例。
- 精确率(Precision):在分类任务中,表示模型预测为正例的样本中实际为正例的比例。
- 召回率(Recall):在分类任务中,表示实际为正例的样本中被模型正确预测为正例的比例。
6.2 特定领域指标
- BLEU分数(Bilingual Evaluation Understudy):用于评估机器翻译质量,衡量生成文本与参考译文的相似度。
- ROUGE指标(Recall-Oriented Understudy for Gisting Evaluation):用于评估生成文本与参考答案的匹配度,广泛应用于摘要生成和文本生成任务。
- 困惑度(Perplexity, PPL):衡量语言模型的好坏程度,数值越低表示模型对数据的拟合越好。
7. 代码练习
以下是用于计算BLEU、ROUGE和PPL指标的Python代码示例:
from nltk.translate.bleu_score import sentence_bleu
from rouge import Rouge
from math import exp, log
# 计算BLEU分数
def calculate_bleu(reference, candidate):
reference = [reference.split()]
candidate = candidate.split()
score = sentence_bleu(reference, candidate)
return score
# 计算ROUGE分数
def calculate_rouge(reference, candidate):
rouge = Rouge()
scores = rouge.get_scores(candidate, reference)
return scores
# 计算困惑度PPL
def calculate_perplexity(probabilities):
N = len(probabilities)
perplexity = exp(-sum(log(p) for p in probabilities) / N)
return perplexity
# 示例
reference
_text = "This is a test sentence."
candidate_text = "This is a test sentence."
bleu_score = calculate_bleu(reference_text, candidate_text)
rouge_score = calculate_rouge(reference_text, candidate_text)
perplexity = calculate_perplexity([0.1, 0.2, 0.3, 0.4])
print(f"BLEU Score: {bleu_score}")
print(f"ROUGE Score: {rouge_score}")
print(f"Perplexity: {perplexity}")8. 思考总结
本文详细介绍了大语言模型的背景、发展阶段、技术特点、评估方法和实际应用示例。大语言模型在NLP领域取得了显著进展,但也面临着诸如高计算成本和潜在偏见等挑战。未来,随着技术的不断发展,我们可以期待大语言模型在更多应用场景中发挥重要作用。
大语言模型的发展离不开全球科研人员的共同努力,其广泛应用将进一步推动人工智能技术的进步和社会的进步。在未来的研究和应用中,我们需要持续关注模型的公平性、安全性和可解释性,以确保大语言模型能够以负责任的方式应用于各个领域。