背景
垃圾回收器主要做的事情
- 自动跟踪和管理程序中创建的对象,确定哪些对象仍在使用,哪些对象已经不再使用。
- 回收那些不再使用的对象所占用的内存空间,使得这部分内存可以被重新使用。
1.1 传统垃圾回收器
| 垃圾回收器 | 简述 | 优缺点 | 应用场景 | 备注 | |
|---|---|---|---|---|---|
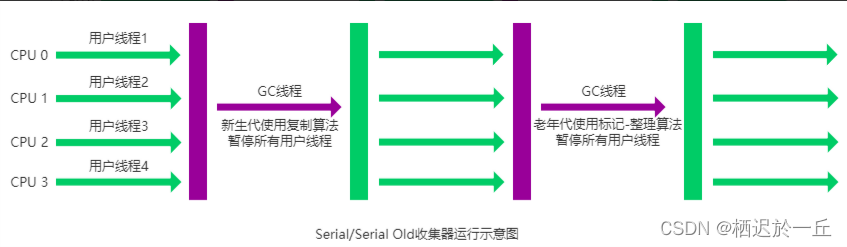
| Serial GC | 这是最基本、最古老的GC,它使用单线程进行垃圾回收,不能进行并行处理。因此,当它在进行垃圾回收时,用户线程必须暂停,等待垃圾回收完成。这种方式称为"Stop-The-World"。 | 优点:简单高效,对于限制了CPU资源的环境,能提供很高的单线程垃圾回收效率。 | 适用于单核处理器环境,或者小型应用。 | ||
Parallel GC |
也称为吞吐量收集器,它是Serial GC的多线程版本。它在垃圾回收时也会暂停用户线程,但由于使用了多线程,所以垃圾回收的速度更快。 | 优点:多线程并行垃圾回收,提高了垃圾回收的效率。 缺点:在垃圾回收过程中,所有CPU资源都会被用于垃圾回收,可能导致应用程序的性能下降 |
适用于多核处理器环境,以及对吞吐量要求较高的大型应用。 | ||
| CMS(Concurrent Mark Sweep) GC | 这是一种以获取最短回收停顿时间为目标的收集器。它大部分工作都可以和用户线程并发执行,只有在初始标记和重新标记阶段需要"Stop-The-World"。 |
|
|
||
G1 GC: |
全称"Garbage-First",是一种面向服务器的垃圾收集器,主要用于多核处理器和大内存环境。G1 GC通过划分多个小块区域的方式,尽可能地减少"Stop-The-World"的时间。 |
|
使用场景:适用于多核处理器和大内存环境,以及对系统停顿时间有严格要求的大型应用。 |
1.2 传统垃圾回收器痛点
GC停顿
停顿指垃圾回收期间STW(Stop The World),当STW时,所有应用线程停止活动,等待GC停顿结束。
CMS以及G1的GC停顿
CMS新生代的Young GC、G1Young GC以及混合回收的和ZGC都基于标记-复制算法
Yong GC和G1标记复制算法的实现
标记阶段,即从GC Roots集合开始,标记活跃对象;
转移阶段,即把活跃对象复制到新的内存地址上;
重定位阶段,因为转移导致对象的地址发生了变化,在重定位阶段,所有指向对象旧地址的指针都要调整到对象新的地址上。
停顿分析:
CMS以及G1的的yonug GC回收:
- 初始标记(Initial Mark):这是一个"Stop-The-World"(STW)阶段,即在这个阶段,所有的应用线程都会被暂停。垃圾回收器会标记出Eden区和一个Survivor区(假设是From)中所有存活的对象。
- 对存活对象进行复制:将所有存活的对象复制到另一个Survivor区(To)或者老年代(Old Generation)。同时,这些对象的年龄会加1。如果某个对象的年龄达到了一定的阈值(默认15),就会被晋升到老年代。
- 清空Eden区和From区:完成复制后,垃圾回收器会清空Eden区和From区。
- Survivor区交换:交换两个Survivor区的角色,即原来的To区变为From区,原来的From区变为To区。上述过程是STW的,触发频繁,耗时短;

标记阶段停顿分析
初始标记阶段:初始标记阶段是指从根节点(GC Roots)出发标记全部直接子节点的过程,该阶段是STW的。由于GC Roots数量不多,通常该阶段耗时非常短。
并发标记阶段:并发标记阶段是指从GC Roots开始对堆中对象进行可达性分析,找出存活对象。该阶段是并发的,即应用线程和GC线程可以同时活动。并发标记耗时相对长很多,但因为不是STW,所以我们不太关心该阶段耗时的长短。
再标记阶段:重新标记那些在并发标记阶段发生变化的对象。该阶段是STW的。
清理阶段停顿分析
清理阶段清点出有存活对象的分区和没有存活对象的分区,该阶段不会清理垃圾对象,也不会执行存活对象的复制。该阶段是STW的。
复制阶段停顿分析
复制算法中的转移阶段需要分配新内存和复制对象的成员变量。转移阶段是STW的,其中内存分配通常耗时非常短,但对象成员变量的复制耗时有可能较长,这是因为复制耗时与存活对象数量与对象复杂度成正比。对象越复杂,复制耗时越长。
暂停时间过长
2.ZGC原理
优点总结:
支持TB级别的堆;
不会随着堆的大小增加而增加
2.1 ZGC为什么这么快
ZGC采用标记-复制算法(也有说法说是根据页面的大小选择采用标记复制以及标记整理算法),不过ZGC对该算法做了重大改进:ZGC在标记、复制和重定位阶段几乎都是并发的,这是ZGC实现停顿时间小于10ms目标的最关键原因。
回收流程:
标记阶段:ZGC首先会标记出所有的存活对象。
复制阶段:ZGC会将所有存活的对象复制到新的内存区域。
重映射阶段:ZGC会更新所有指向被复制对象的引用。
清理阶段:ZGC会回收被复制对象所在的内存区域。

三个STW阶段:初始标记,再标记,初始转移。
在标记阶段用于处理并发标记中的漏标记
初始标记和初始转移分别都只需要扫描所有GC Roots,其处理时间和GC Roots的数量成正比,一般情况耗时非常短;再标记阶段STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。(G1的转移阶段是完全STW的)
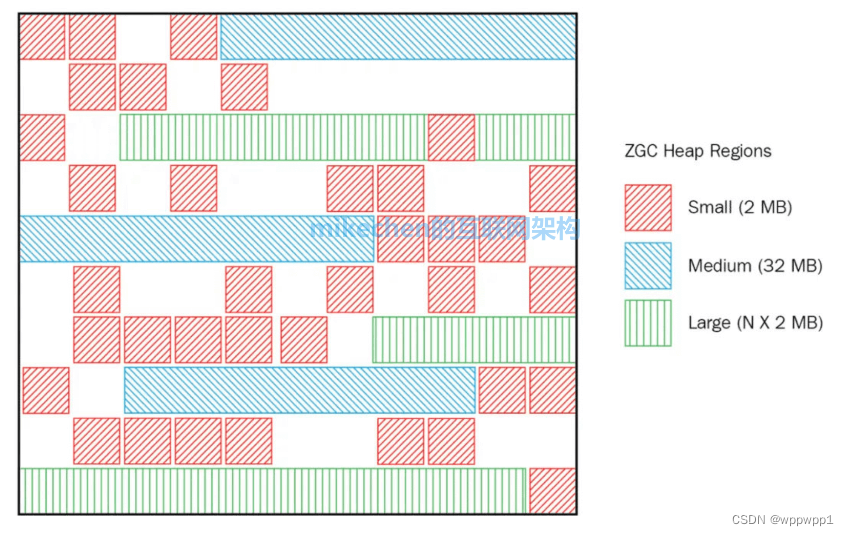
2.2 堆空间的分页模型
ZGC 的 Region可以具有如下图所示的大中下三类容量:
【1】小型 Region(Small Region):容量固定为2MB,用于放置小于 256KB的小对象。
【2】中型 Region(Medium Region):容量固定为 32MB,用于放置大于 256KB但是小于 4MB的对象。
【3】大型 Region(Large Region):容量不固定,可以动态变化,但必须为 2MB的整数倍,用于放置 4MB或以上的大对象。每个大型 Region中会存放一个大对象,这也预示着虽然名字叫“大型 Region”,但它的实际容量完全有可能小于中型Region,最小容量可低至4MB.大型 Region在ZGC的实现中是不会被重分配的。

2.3 转移过程中访问对象问题的解决
2.3.1 色指针和读屏障技术;
大致工作原理:应用线程访问到对象时会触发读屏障,如果发现对象被移动了,读屏障”会把读出来的指针更新到对象的新地址上;而判断对象是否被移动过:利用对象引用的地址,即着色指针。
着色指针:在ZGC中,每个对象指针都被“着色”。每个指针都包含了关于该对象的一些信息(并发标记,转移,重定位等)。这样,ZGC就可以在并发的过程中,通过检查指针的颜色来知道该对象的状态,从而决定是否需要进行某些操作,如标记或复制该对象。
ZGC中低42位(第0 ~ 41位)用于描述真正的虚拟地址(这就是上面提到的应用程序可以使用的堆空间),接着的4位(第42 ~ 45位)用于描述元数据,其实就是大家所说的Color Pointers,还有1位(第46位)目前暂时没有使用,最高17位(第47~63位)固定为0(限于java11中 4TB的内存空间)

读屏障:读屏障是一种在读取对象指针时插入的检查操作。当应用线程试图读取一个对象指针时,读屏障会先检查该指针的颜色。如果指针指示该对象已经被移动,那么读屏障就会先将应用线程重定向到对象的新地址,然后再返回该指针。这样,就可以确保应用线程总是能看到正确的对象状态。
2.3.2 转移过程详解
准备阶段,所有对象都在小页面A中,指针为蓝色

初始标记,所有对象都在A中,GCroots可达的对象指针变为绿色

并发标记,业务线程和回收现场并发,标记其他对象,将其他使用对象的指针变为绿色

再标记;
标记在并发标记中漏标的对象
并发转移准备
选择清理哪些页面
初始转移,转移A对象(GC可达的),修改地址,改变指针颜色

并发转移

转移BC,并在转发表中记录转移地址,
此时业务指针从堆中取对象时,读屏障发现指针颜色为绿色,读屏障则会去读取转发表,返回新地址;
并在业务线程中更新指针颜色以及实际地址;
此时第一次垃圾回收结束,这个时候GC root直达对象指针颜色为蓝色,其余所有存活对象指针颜色为绿色;
此时开始第二次垃圾回收

初始标记阶段

将GCroots 可达对象标记为红色
并发标记阶段
如果扫描到指针颜色为绿色的对象,则根据转发表找到新地址,将该对象变为红色,并在业务线程中的对象实地址,清除转发表数据,蓝色的对象同第一次回收阶段

总结:利用空间(虚拟空间)去换取时间
3. JDK 11中的ZGC的坑
https://segmentfault.com/a/1190000023192220
简单梳理下就是:每次调用StackWalker遍历栈帧的时候,每个栈帧都会生成一个ResolvedMethodName对象放到jvm中的ResolvedMethodTable中,但jdk11的zgc不能有效清理其中不用的对象。因为ResolvedMethodTable是个定容的hashtable,随着其中的数据越来越多,每个bucket的单链表越来越长,查询效率会越来越慢。 所以最终导致CPU的使用率越来越高。
总结:由于没有讲logger写为static,所以logger频繁初始化调用StackWalker方法
jdk11+zgc+log4j+编码不规范
注:在jdk13中已修复
在zgc增加调用SymbolTable::unlink()方法
ResolvedMethodTable的实现,支持了动态扩缩容,可以避免单链表过长的问题
do_concurrent_work(JavaThread* jt)函数:这是处理并发工作的主要函数。首先,计算负载因子(load factor),这是一个衡量表的填充程度的指标。然后,根据负载因子的大小,决定是扩展方法表还是清理无用的条目。如果负载因子大于预设值(这里是2),并且方法表还没有达到最大大小,那么就调用grow(jt)函数来扩展方法表。否则,就调用clean_dead_entries(jt)函数来清理无用的条目。
grow(JavaThread* jt)函数:这是用于扩展方法表的函数。首先,创建了一个GrowTask对象,这是一个用于扩展表的任务。然后,在一个循环中执行这个任务,直到任务完成。在执行任务的过程中,如果需要,它会暂停任务并将线程切换到VM状态,然后再继续执行任务。任务完成后,它会更新当前的表大小,并打印出新的大小。
void ResolvedMethodTable::do_concurrent_work(JavaThread* jt) {
_has_work = false;
double load_factor = get_load_factor();
log_debug(membername, table)("Concurrent work, live factor: %g", load_factor);
// 人工load_factor大于2,并且没有达到最大限制,就执行bucket扩容,并且移除无用的entry
if (load_factor > PREF_AVG_LIST_LEN && !_local_table->is_max_size_reached()) {
grow(jt);
} else {
clean_dead_entries(jt);
}
}
void ResolvedMethodTable::grow(JavaThread* jt) {
ResolvedMethodTableHash::GrowTask gt(_local_table);
if (!gt.prepare(jt)) {
return;
}
log_trace(membername, table)("Started to grow");
{
TraceTime timer("Grow", TRACETIME_LOG(Debug, membername, table, perf));
while (gt.do_task(jt)) {
gt.pause(jt);
{
ThreadBlockInVM tbivm(jt);
}
gt.cont(jt);
}
}
gt.done(jt);
_current_size = table_size();
log_info(membername, table)("Grown to size:" SIZE_FORMAT, _current_size);
}4 ZGC在之后JDK版本迭代中的改进
4.0 ZGC在JDK11下的缺陷
ZGC时Java进程占用三倍内存问题:由于ZGC着色指针把内存空间映射了3个虚拟地址,使得TOP/PS等命令查看占用内存时看到Java进程占用内存过大。此问题不影响操作系统,但是会影响到监控运维工具。
吞吐量低于G1 GC。一般来说,可能会下降5%-15%。对于堆越小,这个效应越明显,堆非常大的时候,比如100G,其他GC可能一次Major或Full GC要几十秒以上,但是对于ZGC不需要那么大暂停。这种细粒度的优化带来的副作用就是,把很多环节其他GC里的STW整体处理,拆碎了,放到了更大时间范围内里去跟业务线程并发执行,甚至会直接让业务线程帮忙做一些GC的操作,从而降低了业务线程的处理能力。
对象分配卡顿,除了ZGC的暂停阶段之外,还受到下面的一些因素的影响:Page Cache Flush问题影响分配速度:ZGC把堆分为不同大小的page(对应G1的Region)——small/medium/large page(不同大小的object分配到不同类型的page中),如果各种大小对象分配速度不稳定(比如medium大小的object突然变多,那么就需要把large/small page转换成medium page,比较耗时),JDK15 production-ready之后有所缓解;
由于ZGC采用colored pointer技术,因此不支持压缩指针,一定程度上影响小堆(32GB以下)的性能(JDK15后可以支持UseCompressedOops关闭时依然开启UseCompressedClassPointers)
4.1 JDK17中LTS版本的改进
并发类卸载:在JDK 15中,ZGC增加了并发类卸载的功能,这使得ZGC可以在垃圾收集过程中并发地卸载不再使用的类。
并发预处理:在JDK 14中,ZGC增加了并发预处理的功能,这可以减少垃圾收集的暂停时间。
JFR事件:在JDK 14中,ZGC增加了对Java Flight Recorder (JFR)事件的支持,这使得开发者可以更好地监控和诊断ZGC的行为。
精简的锁:在JDK 15中,ZGC的内部锁机制被精简,这可以提高ZGC的性能。
支持更多的平台:在JDK 11中,ZGC只支持Linux/x64平台。在后续的版本中,ZGC增加了对更多平台的支持,包括macOS、Windows和Linux/Aarch64。
4.2 JDK21分代ZGC的不同
它在ZGC的基础上引入了分代概念。在分代ZGC中,堆被划分为多个代,通常包括新生代和老年代。新创建的对象首先放在新生代,当它们存活足够长的时间后,会被移动到老年代。
分代ZGC的主要优点是可以更有效地处理短生命周期的对象。由于大多数对象的生命周期都很短,所以通过在新生代中更频繁地进行垃圾收集,可以更快地回收这些对象,从而提高垃圾收集的效率。同时,由于老年代中的对象相对稳定,所以可以减少在老年代中的垃圾收集频率,从而减少了垃圾收集对应用的影响。
总的来说,分代ZGC和ZGC的主要区别在于是否使用了分代概念,以及如何处理不同生命周期的对象。