作为一名大数据开发者,加入新公司后快速熟悉技术环境是一项重要而又具有挑战性的任务。本文将分享我个人的经验,介绍三个关键步骤,帮助你迅速适应新的工作环境。
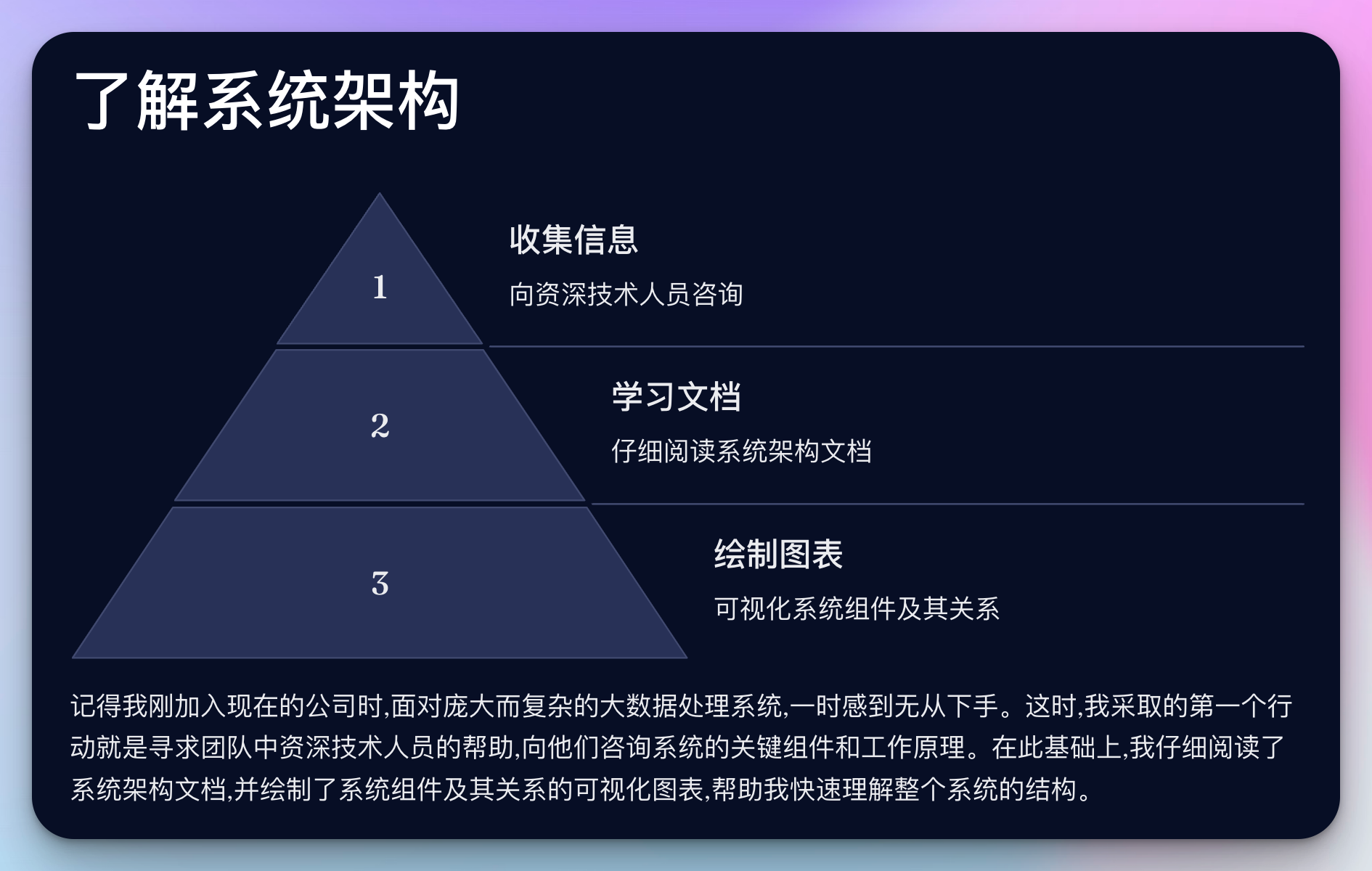
1. 了解系统架构
记得我刚加入现在的公司时,面对庞大而复杂的大数据处理系统,一时感到无从下手。这时,我采取的第一个行动就是寻求团队中资深技术人员的帮助。
实践建议:
- 安排与系统架构师或技术负责人的一对一会议
- 请他们介绍系统设计的初衷和演进历程
- 关注关键的技术选型及其背后的考量

示例对话:
“嗨,张工,能否给我介绍一下我们的实时数据处理pipeline是如何设计的?为什么选择了Kafka和Flink的组合?”
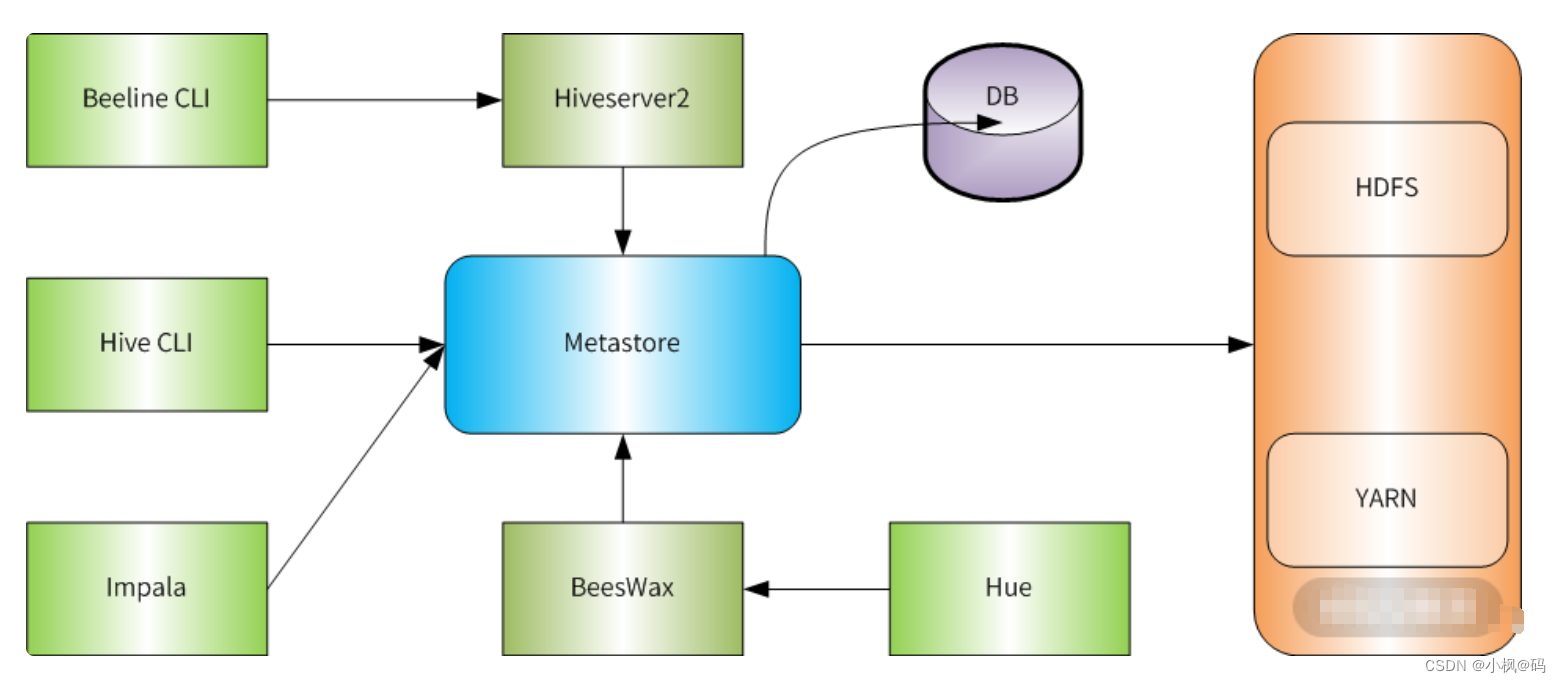
通过这样的交流,我快速了解到公司的实时数据处理方案是基于Kafka进行消息队列管理,而Flink则负责复杂的流处理任务。这个组合既保证了数据的实时性,又提供了强大的计算能力。
在了解系统架构的过程中,我还特别关注了公司的数据仓库架构。通过与数据架构师的交流,我了解到公司采用了Lambda架构:
- 批处理层:使用Hadoop HDFS存储原始数据,Hive进行批量ETL处理。
- 速度层:使用Kafka接收实时数据流,Spark Streaming进行实时处理。
- 服务层:使用HBase作为数据服务层,为上层应用提供低延迟的查询服务。
这种架构既满足了大规模数据的批处理需求,又能够处理实时数据流,是一个非常典型的大数据解决方案。

2. 了解领域模型
在初步理解系统架构后,下一步就是深入了解系统的核心业务逻辑和数据模型。
实践建议:
- 查阅数据库schema文档,重点关注核心业务表
- 阅读API文档,了解系统对外提供的服务
- 绘制简单的ER图,帮助理解实体之间的关系

示例:
在我们的电商大数据平台中,order表是核心业务表之一。通过分析其结构,我们可以了解订单的生命周期:
CREATE TABLE `order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`status` enum('created','paid','shipped','completed','cancelled') NOT NULL,
`total_amount` decimal(10,2) NOT NULL,
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
通过这个表结构,我们可以看出订单状态的流转,以及系统对订单查询的优化(通过用户ID和状态的索引)。
在了解领域模型时,我还特别关注了用户行为分析相关的数据模型。以下是一个简化的用户行为日志表结构:
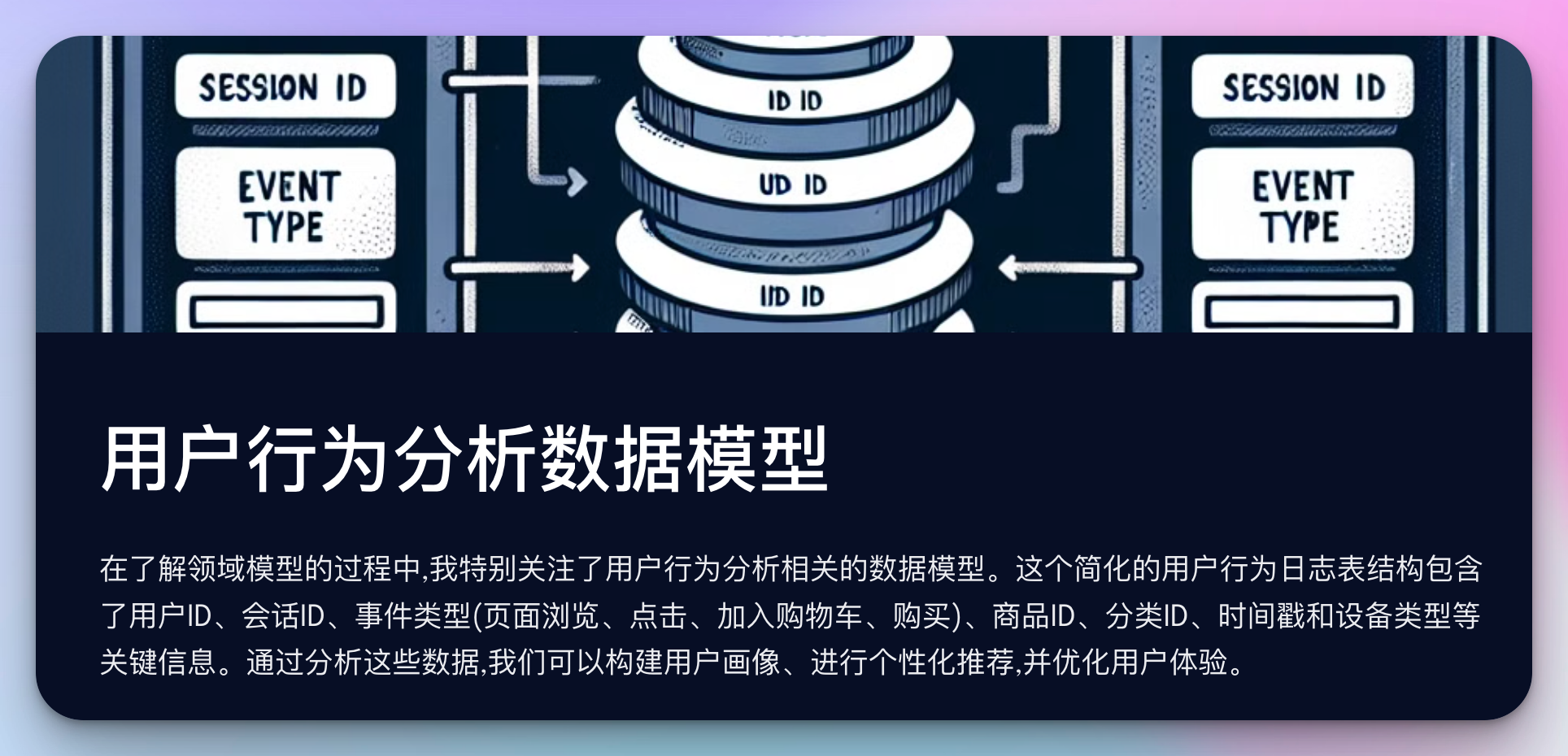
CREATE TABLE `user_behavior_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) NOT NULL,
`session_id` varchar(50) NOT NULL,
`event_type` enum('page_view','click','add_to_cart','purchase') NOT NULL,
`item_id` bigint(20),
`category_id` int(11),
`timestamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`device_type` enum('pc','mobile','tablet') NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`user_id`),
KEY `idx_event_type` (`event_type`),
KEY `idx_timestamp` (`timestamp`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
这个表结构让我们能够跟踪用户的各种行为,包括页面浏览、点击、加入购物车和购买等。通过分析这些数据,我们可以构建用户画像、进行个性化推荐,以及优化用户体验。
3. 了解代码结构
最后,也是最重要的一步,就是深入代码层面,了解系统的具体实现。

实践建议:
- 克隆项目代码库,熟悉工程结构和各模块职责
- 选择一个核心业务流程,如"用户下单",跟踪其完整执行路径
- 主动承担一个小型需求,实践中学习

示例:
假设我们要跟踪"用户下单"的流程,可能会涉及以下几个关键步骤:
- 用户提交订单(Web/App层)
- 订单信息写入Kafka(消息队列层)
- Flink作业消费Kafka消息,进行实时计算(流处理层)
- 更新订单状态,写入数据库(存储层)
- 触发后续业务流程,如库存更新、物流通知等(业务处理层)
通过跟踪这个流程,我不仅了解了代码的结构,还深入理解了系统的数据流转和业务逻辑。

在熟悉代码结构的过程中,我还深入研究了公司的实时推荐系统。这个系统的主要组件和流程如下:
数据收集层:
- 使用Flume收集用户行为日志
- 将收集到的数据实时写入Kafka
特征工程层:
- Flink作业从Kafka读取实时数据
- 进行特征提取和转换
- 将处理后的特征数据写入Redis,用于实时查询
模型服务层:
- 使用TensorFlow Serving部署训练好的推荐模型
- 提供gRPC接口,接收特征输入,返回推荐结果
API服务层:
- Spring Boot应用作为对外API服务
- 接收推荐请求,从Redis获取用户特征
- 调用模型服务获取推荐结果
- 返回个性化推荐内容给客户端
通过分析这个实时推荐系统的代码结构,我不仅了解了各个组件的职责,还学习了如何将机器学习模型集成到大数据处理流程中,这对我后续的工作有很大帮助。
结语
作为一名大数据开发者,快速熟悉新的技术环境是至关重要的。通过了解系统架构、领域模型和代码结构,我们可以在短时间内对系统有全面的认识。记住,主动学习和沟通是关键。不要害怕提问,每一个问题都是深入了解系统的机会。

希望这篇文章能够帮助你在新的工作环境中迅速找到方向。记住,每个系统都有其独特之处,保持开放和好奇的心态,你一定能在大数据开发的道路上越走越远!