1.决策树是一种归纳学习算法,从一些没有规则、没有顺序、杂乱无章的数据中,推理出决 策模型。不管是什么算法的决策树,都是一种对实例进行分类的树形结构。决策树有三个要素:节点(Node)、分支(Branches)和结果(Leaf)。
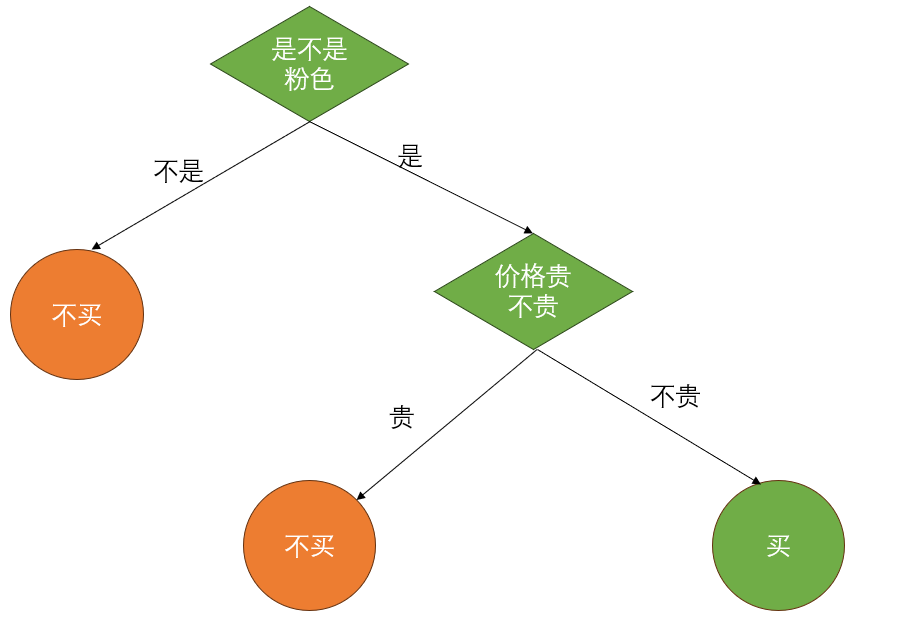
训练决策树,其实就是对训练样本的分析,把样本通过某个边界划分成不同的结果。如 图3.2所示,王华想玩游戏,但是他妈妈要求他写完作业才能玩。

2. ID3 算法
ID3算法通过熵(Entropy) 来决定谁来做父节点,也就是“条件”。 一般来说,决策树就是不断地if…else,不断地做判断,每做一个判断就会产生新的分支,这个叫分裂。谁来分类,是根据Entropy 最小的原则来判断的。
(1)Entropy 衡量一个系统的混乱程度,例如,气体的 Entropy 会高于固体的Entropy。
(2)Entropy 可以表示一个随机变量的不确定性,例如,很多 低概率事件的 Entropy 就很高,很少 高概率事件的Entropy 会很低。
(3)Entropy也可以用来计算比特信息量。
Entropy不断最小化,其实就是提高分类 正确率的过程。
3.C4.5
通过对 ID3 的学习,可以发现一个问题:如果一个模型,无限地延长分类,越细小的分割错误率就会越小。继续猫狗分类的实验,假设把决策树延伸,最后有10种结果,每个结果 都只有1只猫或者1只狗,每个结果的Entropy 一定都是0。
但是,这样的分类是没有意义的,即过拟合、过度学习(Overfitting) 。 举一个简单的例 子来理解Overfitting, 像是私人定制的衣服非常适合某一个人穿,此时出现一个新人,就无 法用这些既定的胸围、腰围来定制衣服了,必须重新测量。
因此,为了避免分割太细,C4.5 的改进之处是提出了信息增益率。如果分割太细,会降低信息增益率。其他原理与 ID3 相差不多。
4.CART
CART 的结构非常简单, 一个父节点只能分为2个子节点,它使用的是GINI 指标来决 定怎么分类的。CART 之所以是回归树,是因为使用回归方法来决定分布是否终止。不管如何分割, 总会出现一些结果,仅有一点的不纯净。因此CART 对每一个结果(叶子节点)的数据分析均值方差,当方差小于一个给定值,就可以终止分裂。
CART 也有与ID3 类似的问题,就是分割过于细小,这里使用了一个技巧 剪枝,把 特别长的树枝直接剪掉。这个通过计算调整误差率(Adjusted Error Rate)实现。
5.随机森林
随机森林是一种集成学习的方法,是把多棵决策树集成在一起的一种算法,基本单元是决策树。其思想从一个直观的角度来解释,就是每一棵决策树,都是一个分类器,很多决策树必然会有很多不一样的结果。这个结果就是每一个决策树的投票,投票次数最多的类别 就是最终输出。
6.Boosting 家族
XGBoost 所应用的算法内核就是GBDT(Gradient Boosting Decision Tree),也就是梯度提升决策树。这里XGBoost 应用的算法严格来说是优化的GBDT。XGBoost 是一种集成学习。这种集成学习,与Random Forest的集成学习,两者是不 一 样的。XGBoost 的集成学习是相关联的集成学习,决策树联合决策;而Random Forest 算法中各个决策树是独立的。第二棵决策树的训练数据,会与前面决策树的训练效果有关,每棵树之间是相互关联的。而Random Forest算法中每棵树都是独立的,彼此之间什么关系都没有。
泛化能力是指一个模型在新数据上的表现能力,即它能够处理未见过的数据或情况的能力。如果一个模型具有强大的泛化能力,这意味着它不仅在训练数据上表现良好,而且在未见过的数据上也能保持较高的准确率和有效性。
7.LightGBM
XGBoost 在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练集都放在内存就需要大量内存,如果不装进内存,每次读写就需要大量时间。所以XGBoost 的缺点主要就是计算量巨大,内存占用巨大。因为 XGBoost 采用的贪婪算法,可以找到最精确的划分条件(就是节点的分裂条件),但是这也是一个会导致过拟合的因素。过拟合:模型在训练集上的表现非常好,但在新的、未见过的数据上表现很差。
而 LightGBM 采用直方图算法(Histogram Algorithm),思想很简单,就是把连续的浮点数据离散化,然后把原来的数据用离散之后的数据替代。换句话说,就是把连续数据变成了离散数据。例如,现在有几个数字[0,0.1,0.2,0.3,0.8,0.9,0.9],把这些分为两类,最后 离散结果就是:[0,0,0,0,1,1,1]。很多数据的细节被放弃了,相似的数据被划分到同一个bin中,数据差异消失了。① bin是指直方图中的一个柱子,直译过来是桶。②很多数据细节被放弃了,这 从另一个角度来看可以增加模型的泛化能力,防止过拟合。
除此之外,LightGBM 还支持类别特征。大多数机器学习工具无法支持类别特征,而需要把类别特征通过one-hot 编码。这里简单讲一下one-hot 编码,如图3.5所示(其中,“0”代表是,“1”代表是)。

这样的编码方式会降低时间和空间的效率。尤其是当原来的特征动物类别中有几百种时 ,one-hot 编码之后会多出几百列特征,效率非常低。此外,one-hot 编码会导致决策树分类时出现很多数据量很小的空间,容易导致过拟合问题。如图3.6(a) 所 示 ,XGBoost 会生 成一棵更长、泛化能力更弱的决策树,而图3.6(b) 的 LightGBM 可以生成一个泛化能力强 的模型。

8. CatBoost
CatBoost 的优势是可以很好地处理类别特征。CatBoost 提供了一种处理类别特征的方案:
(1)对所有的样本进行随机排序;
(2)把类别特征转化为数值型特征,每个数值型特征都是基于排在该样本之前的类别标签取均值,同时加入了优先级及权重系数。
总 结:
(1)介绍了决策树的发展史。基本上后续的算法都是优于先前的算法的。
(2)ID3 算法:输入只能是分类数据(这意味着ID3 只能处理分类问题,不能处理回归任务),分裂的标准是Entropy。
(3)CART 算法:输入可以是分类数据(categorical),也可以是连续数据(numerical)。 分裂标准是GINI 指标。
(4)Random Forest和 XGBoost 算法虽然都是集成学习,但是二者存在不同。
(5)XGBoost 虽然精准分裂,但是容易过拟合、耗时长、效率低; LightGBM 使用直方 图算法,速度快、泛化能力较强。
(6)XGBoost 使用one-hot 编码,LightGBM 可以直接对类别特征进行处理;CatBoost 在处理类别特征的时候,更胜 LightGBM 一筹。总之,对于大数据的竞赛,LightGBM 和 CatBoost是主力。