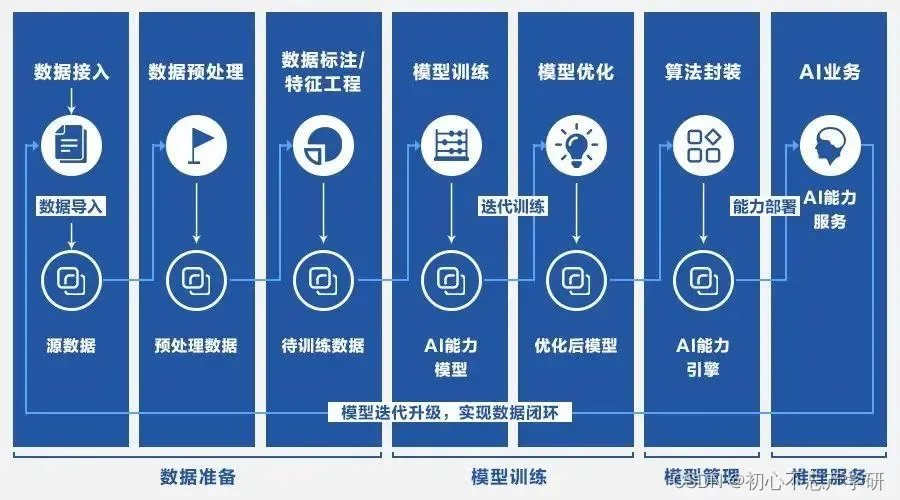
步骤4的采样过程是JEST算法的核心部分,具体描述如何从一个大的超级batch中选择最有价值的子batch。以下是详细的解释:
采样过程细化
JEST算法使用block Gibbs采样的灵感来进行采样。block Gibbs采样是一种马尔可夫链蒙特卡罗(MCMC)方法,主要用于从高维概率分布中进行采样。在JEST算法中,我们通过逐步采样的方式,构建出最终的子batch。
采样步骤
假设我们有一个超级batch (\mathcal{B}_{super}) ,其中包含大量的样本,我们希望从中选择一个子batch (\mathcal{B}) 。下面是具体的采样步骤:
初始化:设定需要的子batch大小 (b) 和超级batch大小 (B) ,以及迭代次数 (N) 。初始化一个空的子batch (\mathcal{B})。
迭代采样:
第 (n) 次迭代:
a. 从超级batch (\mathcal{B}_{super}) 中随机选择一个batch (B_n) 。假设我们将超级batch划分为多个块,每次迭代选择其中一个块进行处理。
b. 对于所选择的batch (B_n) ,根据可学习性评分 (\text{learn}(\mathcal{B}|\theta, \theta^*)) 进行无替换采样。即,根据每个样本的评分,按概率进行采样,确保选出的样本对当前模型训练最有价值。
c. 将选出的样本块 (X_k) 添加到当前的子batch (\mathcal{B}_n) 中,更新子batch的内容。
d. 重复上述步骤,直至完成所有迭代 (n = N) 。
终止条件:迭代结束时,得到的子batch (\mathcal{B}) 应包含 (b) 个样本,这些样本是从超级batch中筛选出的最有价值的样本。
具体举例
假设我们有一个超级batch (\mathcal{B}_{super}) ,其中包含10000张图像,我们希望筛选出1000张最有价值的图像。设定迭代次数 (N = 16) 。
初始化一个空的子batch (\mathcal{B})。
第1次迭代:
a. 从超级batch (\mathcal{B}_{super}) 中随机选择一个batch (B_1) ,例如包含625张图像。
b. 计算每个图像的可学习性评分,根据评分进行无替换采样,选出例如200张图像 (X_1) 。
c. 将选出的200张图像添加到子batch (\mathcal{B}_1) 中。
第2次迭代:
a. 从超级batch (\mathcal{B}_{super}) 中再选择一个batch (B_2) ,例如包含625张图像。
b. 计算可学习性评分,进行无替换采样,选出200张图像 (X_2) 。
c. 将选出的200张图像添加到当前子batch (\mathcal{B}_2) 中。
重复以上步骤,直至迭代次数达到16次。每次迭代都在更新子batch,最终得到包含1000张图像的子batch (\mathcal{B})。
总结
通过逐步迭代和根据可学习性评分的无替换采样,JEST算法能够有效地从一个大规模的超级batch中筛选出最有价值的子batch。这样不仅提高了训练效率,还能显著提升模型的性能。
无替换采样(without replacement sampling)是一种抽样方法,指在抽取样本时,抽取后的样本不会被放回到原来的集合中。因此,在每次抽取时,样本集合的大小会逐渐减少。
在JEST算法中,根据评分进行无替换采样意味着从一个batch中按评分的高低概率依次抽取样本,抽取后不再放回,以确保每次抽取都是从剩余的未被选中的样本中进行。这样可以避免重复选择同一数据点。
具体步骤
假设我们有一个batch ( B ) ,其中包含 ( n ) 个样本 ({x_1, x_2, …, x_n}),并且每个样本 ( x_i ) 都有一个可学习性评分 ( \text{score}(x_i) )。我们需要从这个batch中无替换地采样出一个子集。
步骤
计算概率分布:根据每个样本的可学习性评分计算它被选中的概率。假设我们使用一个简单的归一化方法来将评分转换为概率:
[
p(x_i) = \frac{\text{score}(x_i)}{\sum_{j=1}^n \text{score}(x_j)}
]无替换采样:按照计算出来的概率分布进行采样。采样时,每次从剩余的样本中按概率选择一个样本,然后将其从集合中移除。
重复采样:继续从剩余样本中采样,直到达到所需的子集大小。
举例说明
假设我们有一个batch ( B ) ,其中包含5个样本,每个样本的评分如下:
[
{x_1: 2.0, x_2: 1.5, x_3: 1.0, x_4: 3.0, x_5: 2.5}
]
计算总评分:总评分为 ( 2.0 + 1.5 + 1.0 + 3.0 + 2.5 = 10.0 )。
计算每个样本的选中概率:
[
p(x_1) = \frac{2.0}{10.0} = 0.2
]
[
p(x_2) = \frac{1.5}{10.0} = 0.15
]
[
p(x_3) = \frac{1.0}{10.0} = 0.1
]
[
p(x_4) = \frac{3.0}{10.0} = 0.3
]
[
p(x_5) = \frac{2.5}{10.0} = 0.25
]无替换采样:假设我们要从中采样3个样本:
第一次采样:根据概率分布 ( {0.2, 0.15, 0.1, 0.3, 0.25} ) 选择一个样本,假设选中了 ( x_4 ) ,然后将 ( x_4 ) 从集合中移除。
第二次采样:更新后的样本集合为 ( {x_1, x_2, x_3, x_5} ),概率分布重新归一化为 ( { \frac{2.0}{7.0}, \frac{1.5}{7.0}, \frac{1.0}{7.0}, \frac{2.5}{7.0} } ),然后再进行一次采样,假设选中了 ( x_5 ) ,将 ( x_5 ) 移除。
第三次采样:更新后的样本集合为 ( {x_1, x_2, x_3} ),概率分布重新归一化为 ( { \frac{2.0}{4.5}, \frac{1.5}{4.5}, \frac{1.0}{4.5} } ),然后再进行一次采样,假设选中了 ( x_1 ) 。
最终得到的子集为 ( {x_4, x_5, x_1} ),且每个样本只被选中一次。
总结
无替换采样确保了每次抽取样本时,都只从剩余未被选中的样本中进行选择,避免重复选择同一数据点。这种方法有助于在JEST算法中高效地选择出最有价值的子batch,用于模型的训练。