1.副本:为了系统容错,文件系统会对所有的数据块进行副本复制
1.副本生成和数量
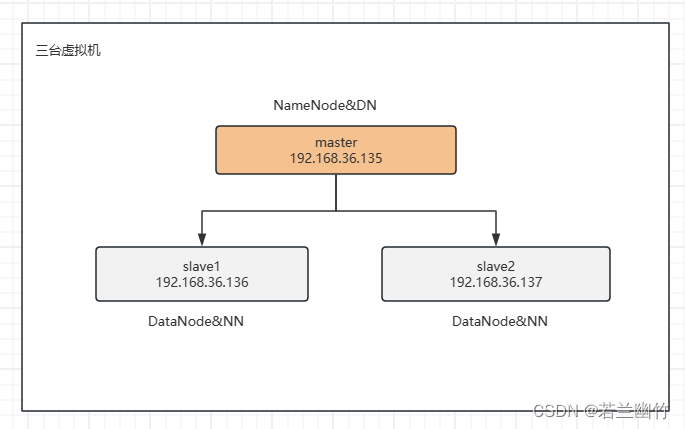
在数据块被写入HDFS的过程中,NameNode会根据副本策略决定每个数据块的副本数量和存储位置,Hadoop默认副本数量是3,每个数据块的副本会被存放在不同的DataNode节点上,以确保数据的高可用和容错性。
第一个副本,如果客户端是集群外的一台机器,就会随机存放在一个DataNode节点上(系统会避免存放在太忙碌的节点)
第二个副本,存放在不同机架上的随机DataNode节点
第三个副本,存放在与第二个副本相同的机架但是不同的DataNode节点上
2.校验和(Checksum)
在数据块被写入HDFS的过程中,客户端会将输入的文件按照block块的大小切分为多个数据块,对于每个数据块,客户端会计算其校验和,并将这些校验和一起存储在一个单独的校验和文件中,这些校验和文件和实际的数据块被一起存放在DataNode中,用于后续的数据完整性的校验。
当客户端从HDFS中下载数据时,NameNode会提供数据块的位置(包括副本的位置),客户端会根据这些位置从DataNode中下载数据块和校验和文件
客户端逐个读取数据块,并计算每个数据块的校验和,将计算得到的校验和与从校验和文件中读取的校验和进行比较,如果校验和匹配,说明这个数据快是完整且未被篡改的
如果校验和不匹配,客户端会从其他的DataNode中下载该数据块的副本,并重新进行校验。
3.block块
数据块,磁盘读写的基本单位,hadoop2.0默认大小是128M
块增大可以减少寻址时间,但是也不宜过大,块过大会导致整体任务数量过小,降低作业处理速度