作者:来自 Elastic Amy Ghate, Rishikesh Radhakrishnan, Hemant Malik

使用非结构化和 Elasticsearch 向量数据库为 RAG 应用程序提取和搜索复杂的专有文档
在使信息可搜索之前解析文档是构建实际 RAG 应用程序的重要步骤。Unstructured.io 和 Elasticsearch 在此场景中有效地协同工作,为开发人员提供构建 RAG 应用程序的互补工具。
Unstructured.io 提供了一个工具库,用于提取、清理和转换不同格式和不同内容源的文档。将文档添加到 Elasticsearch 索引后,开发人员可以从许多 Elastic 功能中进行选择,包括聚合、过滤器、RBAC 工具和 BM25 或向量搜索功能 - 将复杂的业务逻辑实现到 RAG 应用程序中。
在本博客中,我们将研究一个相当常见的用例,即解析和提取包含文本、表格和图像的 PDF 文档。我们将使用 Elastic 的 ELSER 模型创建稀疏向量嵌入,然后使用 Elastisearch 作为向量数据库存储和搜索嵌入。
Unstructured 的强大之处在于模型可以识别文档的独特组件并将其提取到 “document elements - 文档元素” 中。非结构化数据还可以使用不同的策略(而不仅仅是字符数)对分区进行分块。这些 “智能分区和分块” 策略可以提高搜索相关性并减少 RAG 应用程序中的幻觉。
解析数据后,我们将其作为向量嵌入存储在 Elasticsearch 向量数据库中并运行搜索操作。我们使用 Elasticsearch 向量数据库连接器将这些数据发送到 Elastic。我们还将管道连接到流程,以便在摄取时创建 ELSER(一种用于语义搜索的开箱即用的稀疏编码器模型)嵌入。
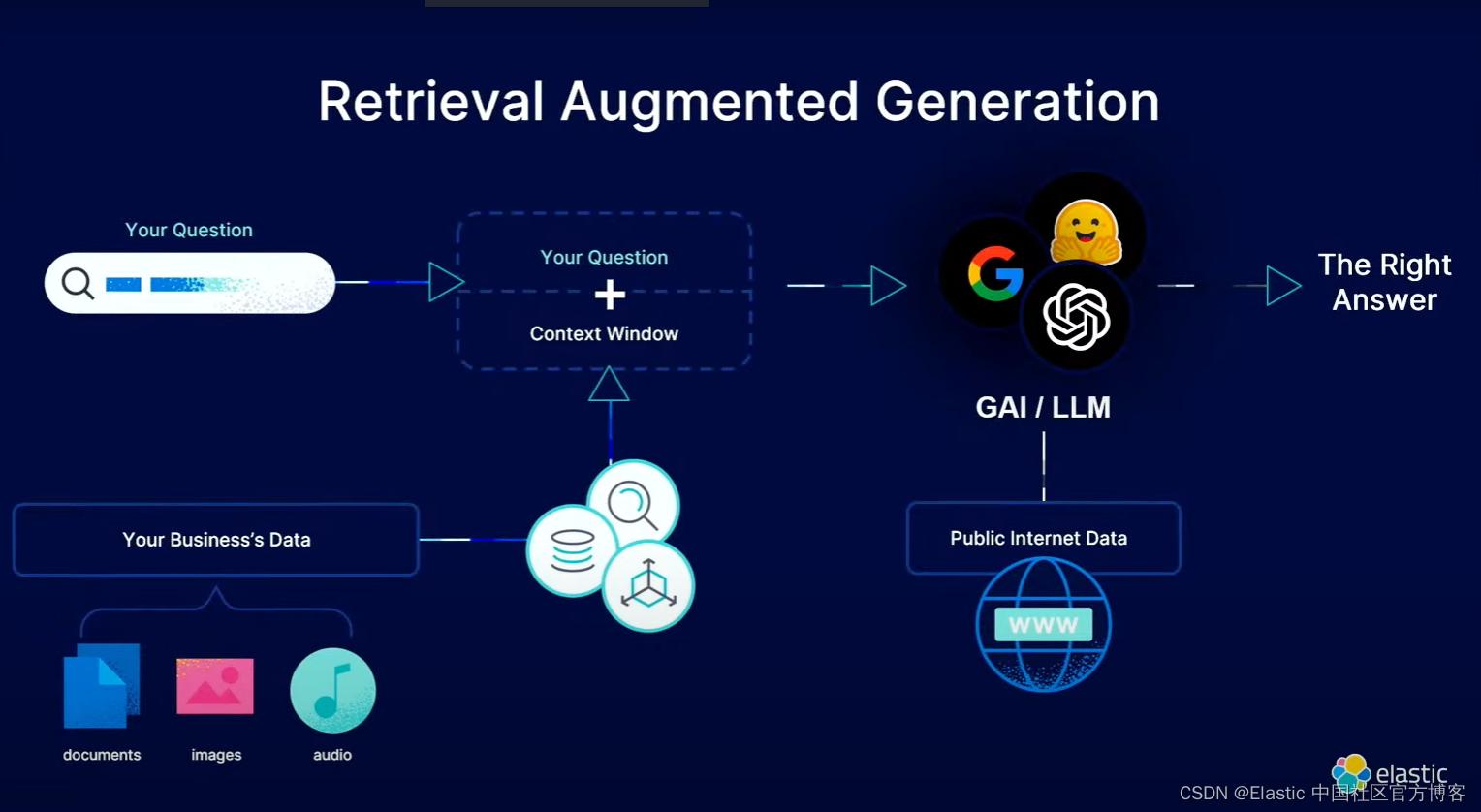
总体流程
1)在 Elastic 平台中部署 ELSER 模型,
3)创建一个摄取管道,该管道将为摄取的块创建嵌入。字段文本将存储分块文本,而 text_embeddings 将存储嵌入。我们将使用 ELSER v2 模型。
PUT _ingest/pipeline/chunks-to-elser
{
"processors": [
{
"inference": {
"model_id": ".elser_model_2_linux-x86_64",
"input_output": [
{
"input_field": "text",
"output_field": "text_embedding"
}
]
}
}
]
}
3)下一步是创建一个索引 unstructured-demo,其中包含 ELSER 嵌入的必要映射。我们还将把上一步中创建的管道附加到此索引。我们将允许所有其他字段进行动态映射。
PUT unstructured-demo
{
"settings": {
"default_pipeline": "chunks-to-elser"
},
"mappings": {
"properties": {
"text_embedding": {
"type": "sparse_vector"
},
"text": {
"type": "text"
}
}
}
}
4)最后一步是使用 Elasticsearch 连接器运行 Unstructured 的代码示例来创建分区和块。按照说明安装依赖项。
import os
from unstructured.ingest.connector.elasticsearch import (
ElasticsearchAccessConfig,
ElasticsearchWriteConfig,
SimpleElasticsearchConfig,
)
from unstructured.ingest.connector.local import SimpleLocalConfig
from unstructured.ingest.interfaces import (
ChunkingConfig,
PartitionConfig,
ProcessorConfig,
ReadConfig,
)
from unstructured.ingest.runner import LocalRunner
from unstructured.ingest.runner.writers.base_writer import Writer
from unstructured.ingest.runner.writers.elasticsearch import (
ElasticsearchWriter,
)
我们将主机设置为 Elastic Cloud(Elasticsearch 服务)。我们设置用户名和密码,并设置要写入的索引:
def get_writer() -> Writer:
return ElasticsearchWriter(
connector_config=SimpleElasticsearchConfig(
access_config=ElasticsearchAccessConfig(
hosts="https://unstructured-demo.es.us-central1.gcp.cloud.es.io",
username="elastic",
password=<insert password>
),
index_name="unstructured-demo",
),
write_config=ElasticsearchWriteConfig(
batch_size_bytes=15_000_000,
num_processes=2,
),
)
对于下一步,请注册一个 Unstructured API 端点和密钥。Unstructured 中的分区函数(partitioning functions)从非结构化文档中提取结构化内容。partition 函数检测文档类型并自动确定适当的 partition 函数。如果用户知道他们的文件类型,他们也可以指定特定的分区函数。在分区步骤中,我们指示 Unstructured 通过传入 pdf_infer_table_structure=True 并将分区策略(partition strategy)设置为 hi_res 来推断表结构,从而自动识别文档的布局。你可以在此处了解各种非结构化分区策略。我们将 chunking strategy 设置为 by_title,它 “preserves section and page boundaries - 保留了章节和页面边界”。分块策略对 RAG 应用程序的性能和质量有重大影响。你可以在他们的论文《Chunking for Effective Retrieval Augmented Generation》中了解有关 Unstructured 在这方面的工作的更多信息。
writer = get_writer()
runner = LocalRunner(
processor_config=ProcessorConfig(
verbose=True,
output_dir="local-output-to-elasticsearch",
num_processes=2,
),
connector_config=SimpleLocalConfig(
input_path=<path to PDF>,
),
read_config=ReadConfig(),
partition_config=PartitionConfig(pdf_infer_table_structure=True,strategy='hi_res',partition_by_api=True, partition_endpoint=<your partition endpoint>', api_key=<your api key>),
chunking_config=ChunkingConfig(chunk_elements=True, max_characters=500, chunking_strategy="by_title"),
writer=writer,
writer_kwargs={},
)
runner.run()
在 Elasticsearch 向量数据库中生成的文档中,你将看到 Unstructured API 生成的一些有趣的元数据。如果元素是表格,你将看到表格的 HTML 结构以及有关其外观的信息。如果它是一段文本和先前块的延续,你将看到 is_continuation,这在 RAG 场景中很有用,因为你想要将段落的整个上下文传递给 LLM。如果你想知道哪些单个分区组成了一个块,你可以在 base-64 编码的 orig_elements 字段中找到它。在上面的示例中,我们使用了 Unstructured 的 API 服务。这些 API 服务可以以三种不同的方式使用:
- Limited trial Unstructured API
- SaaS Unstructured API
- AWS/Azure Marketplace Unstructured API
试用版的处理能力上限为 1000 页,你的文档可用于专有模式培训和评估目的。为了快速进行原型设计,你还可以查看 Unstructured 的开源版本。非结构化库为你提供了使用其 Python 安装程序运行的选项。如果你想避免处理多个依赖项,可以使用与所有必需库捆绑在一起的 Docker 容器。与开源版本相比,Unstructured API 提供了以下附加功能:
- 通过高级分块和改进的转换管道,显着提高了文档和表格提取的性能
- 访问最新的视觉转换器模型和企业功能,例如安全性、SOC2 合规性、IAM(身份验证和身份管理)
结论
有效的文档解析是构建有效 RAG 解决方案的重要步骤。Unstructured 将原始文档转换为 LLM 可以理解的数据的方法,再加上 Elastic 作为向量数据库和搜索平台的实力,将加速你使用 AI 进行构建的旅程。祝你搜索愉快!
准备好自己尝试一下了吗?开始免费试用。
希望将 RAG 构建到你的应用程序中?想要尝试使用向量数据库的不同 LLMs?
在 Github 上查看我们针对 LangChain、Cohere 等的示例笔记本,并立即加入 Elasticsearch Relevance Engine 培训。