PySpark 中 RDD 与 DataFrame 的不同应用场景
在大数据处理领域,Apache Spark 是一个广泛使用的分布式计算框架。Spark 提供了两种核心数据抽象:RDD(Resilient Distributed Dataset)和 DataFrame。尽管 DataFrame 提供了更高级别的 API 和优化,但 RDD 仍然在某些场景中占有一席之地。本博客将详细介绍 PySpark 中 RDD 与 DataFrame 的不同应用场景,并探讨它们各自的优缺点。
什么是 RDD?
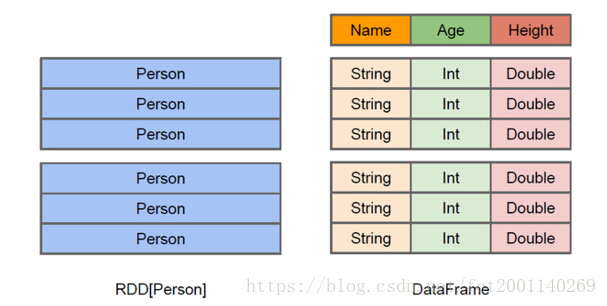
RDD 是 Spark 的核心抽象,它代表一个不可变的分布式对象集合。RDD 提供了对分布式数据集合的容错和并行操作,允许用户对数据进行细粒度的控制。
什么是 DataFrame?
DataFrame 是一种基于 RDD 的高级抽象,它是一个分布式的行和列的数据集合,类似于关系数据库中的表。DataFrame 提供了更丰富的 API,并能利用 Spark SQL 引擎进行优化。
RDD 与 DataFrame 的对比
| 特性 | RDD | DataFrame |
|---|---|---|
| 类型安全 | 支持强类型 | Python 动态类型 |
| 性能优化 | 无查询优化 | 支持 Catalyst 查询优化 |
| 数据处理灵活性 | 提供低级别操作和控制 | 提供高级别操作 |
| 适用数据类型 | 无结构和半结构化数据 | 结构化数据 |
| 数据源支持 | 任意数据源 | 主要支持结构化数据源 |
RDD 的应用场景
1. 需要复杂的低级别数据操作
当你需要执行复杂的底层数据操作,而这些操作无法通过 DataFrame 的 API 实现时,RDD 提供了更大的灵活性。例如,自定义的 map、filter、flatMap 等操作。
from pyspark import SparkContext
sc = SparkContext.getOrCreate()
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 使用 flatMap 执行复杂的低级别数据操作
rdd_flatmap = rdd.flatMap(lambda x: (x, x * 2))
print(rdd_flatmap.collect())
2. 类型安全
对于需要强类型检查的场景,虽然 PySpark 本身是动态类型的,但通过 RDD 可以在代码中更明确地处理类型。
3. 无结构数据处理
当处理的数据是无结构的或者不适合 DataFrame 的行列格式时,RDD 是更好的选择。例如,处理文本文件或日志文件。
# 从文本文件创建 RDD
rdd_text = sc.textFile("path/to/log/file")
# 处理每行文本
errors = rdd_text.filter(lambda line: "ERROR" in line)
print(errors.collect())
4. 需要直接控制数据分区
RDD 提供了对数据分区的直接控制,允许你对数据进行更细粒度的控制和优化。例如,自定义的分区策略。
# 自定义分区
rdd_custom_partition = rdd.partitionBy(2, lambda x: x % 2)
print(rdd_custom_partition.glom().collect())
5. 在现有的 Spark 代码中继续使用 RDD
对于已有的大量基于 RDD 的 Spark 代码,继续使用 RDD 进行开发和维护是更好的选择。重写为 DataFrame 或 Dataset 可能需要大量工作,且可能无法直接映射所有逻辑。
6. 与非结构化数据源集成
当需要与非结构化数据源(如 Hadoop HDFS 上的二进制文件、复杂的自定义数据格式等)集成时,RDD 可以提供更大的灵活性。
# 读取二进制文件
binary_rdd = sc.binaryFiles("path/to/binary/files")
# 处理二进制数据
def process_binary_data(data):
# 自定义处理逻辑
return len(data)
rdd_processed = binary_rdd.map(lambda x: process_binary_data(x[1]))
print(rdd_processed.collect())
DataFrame 的应用场景
1. 需要结构化数据处理
DataFrame 非常适合处理结构化数据,如 SQL 表、CSV 文件、Parquet 文件等。
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("DataFrame Example").getOrCreate()
# 从 CSV 文件创建 DataFrame
df = spark.read.csv("path/to/csv/file", header=True, inferSchema=True)
df.show()
2. 性能优化
DataFrame 能利用 Spark SQL 引擎进行优化,包括查询计划优化、谓词下推、列剪裁等。
# 筛选和聚合操作
df_filtered = df.filter(df["age"] > 30)
df_grouped = df_filtered.groupBy("occupation").count()
df_grouped.show()
3. 需要丰富的 API 操作
DataFrame 提供了更高级别的 API,支持复杂的查询和操作。
# 使用 SQL 查询
df.createOrReplaceTempView("people")
sql_df = spark.sql("SELECT name FROM people WHERE age > 30")
sql_df.show()
4. 机器学习和图计算
DataFrame 与 Spark MLlib 和 GraphX 集成,可以方便地进行机器学习和图计算。
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
# 准备数据
assembler = VectorAssembler(inputCols=["age", "income"], outputCol="features")
df_features = assembler.transform(df)
# KMeans 聚类
kmeans = KMeans(k=3, seed=1)
model = kmeans.fit(df_features)
predictions = model.transform(df_features)
predictions.show()
结论
RDD 和 DataFrame 各有优缺点,适用于不同的应用场景。RDD 提供了更灵活和底层的数据操作接口,适用于复杂的数据处理任务和无结构数据。DataFrame 提供了更高级别的 API 和优化,适用于结构化数据处理和性能要求较高的场景。选择使用哪种数据抽象取决于具体的需求和应用场景。
无论是使用 RDD 还是 DataFrame,Apache Spark 都能为大数据处理提供强大的支持。了解它们各自的优势和应用场景,能够更好地发挥 Spark 的性能和功能,解决实际业务中的数据处理问题。
通过对比 PySpark 中 RDD 和 DataFrame 的不同应用场景,希望能够帮助你在实际开发中做出更好的选择。
以上就是 PySpark 中 RDD 与 DataFrame 的不同应用场景的详细介绍。如果你有任何问题或建议,欢迎留言讨论。希望这篇博客对你有所帮助!
参考资料
Happy Coding!