大模型日报
2024-07-09
大模型资讯
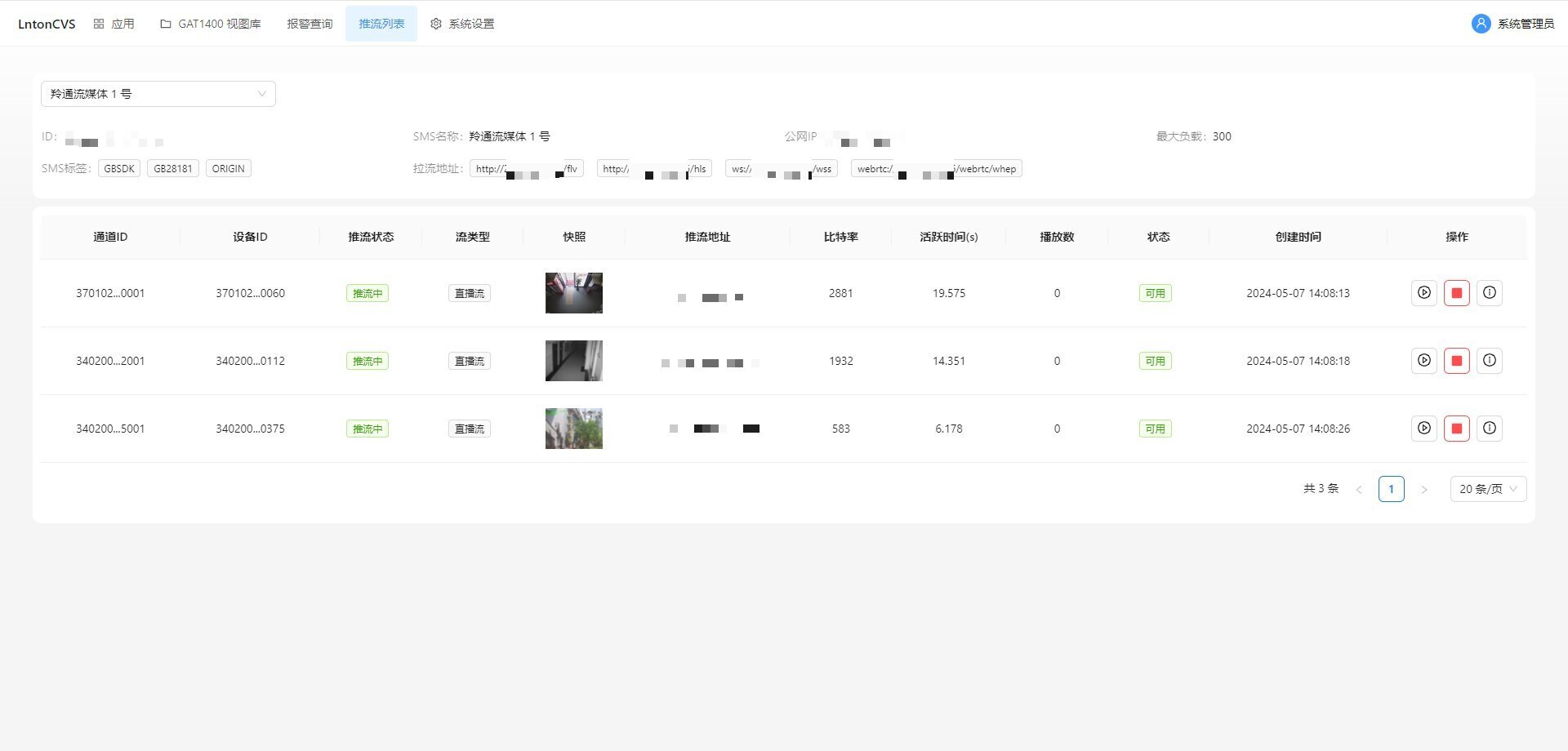
大模型最强架构TTT问世!斯坦福UCSD等5年磨一剑,一夜推翻Transformer
斯坦福UCSD等机构研究者提出的TTT方法,直接替代了注意力机制,语言模型方法从此或将彻底改变。这个模型通过对输入token进行梯度下降来压缩上下文,这种方法被称为「测试时间训练层(Test-Time-Training layers,TTT)」。TTT层直接替代了注意力机制,解锁了具有表现力记忆的线性复杂度架构,使我们能够在上下文中训练包含数百万(未来可能是数十亿)个token的LLM。作者相信,这个研究了一年多的项目,将从根本上改变我们的语言模型方法。而结果证明,TTT-Linear和TTT-MLP直接赶超或击败了最强的Transformer和Mamba!
大模型产品
70万人争先体验!视频生成新王者「可灵AI」又双叒升级了
可灵AI在视频生成方面有了新的升级,拥有七大能力亮点,包括高画质的电影级画面生成、领先的图生视频能力、优秀的视频生成可控性、大幅度且合理的运动生成能力、分钟级的长视频生成能力、模拟复杂的物理世界特性以及概念组合和指令响应能力。快手的全套自行研发体系和技术积累使其在生成式AI领域具备先进且靠谱的技术能力。
大模型论文
RAG微调Llama 3竟超越GPT-4!英伟达GaTech华人学者提出RankRAG框架
这篇文章介绍了来自佐治亚理工学院和英伟达的两名华人学者提出的名为RankRAG的微调框架,用于简化RAG流水线并提高模型性能。他们通过微调的方法将原本需要多个模型的复杂任务交给同一个LLM完成,实现了模型在RAG任务上的性能提升。RankRAG在多个基准测试上超过了同样基座上的其他微调模型,具有较高的实用性和新颖性。
本文由 mdnice 多平台发布