目录
1. M-P 神经元
M-P 神经元,全称为 McCulloch-Pitts 神经元,是一种用于模拟生物神经元功能的数学模型。该模型由 Warren McCulloch 和 Walter Pitts 于 1943 年提出,是人工智能和计算神经科学领域的重要早期模型。
M-P 神经元接收 n 个输入(通常来自其他神经元),并对各个输入赋予权重,计算加权和,然后与神经元特有的阈值 θ 进行比较(作减法)。最后,经过激活函数(模拟“抑制”和“激活”)处理得到输出(通常传递给下一个神经元):
单个 M-P 神经元可以构成感知机(使用 sgn 作为激活函数)或对数几率回归(使用 sigmoid 作为激活函数),多个 M-P 神经元可以构成神经网络。
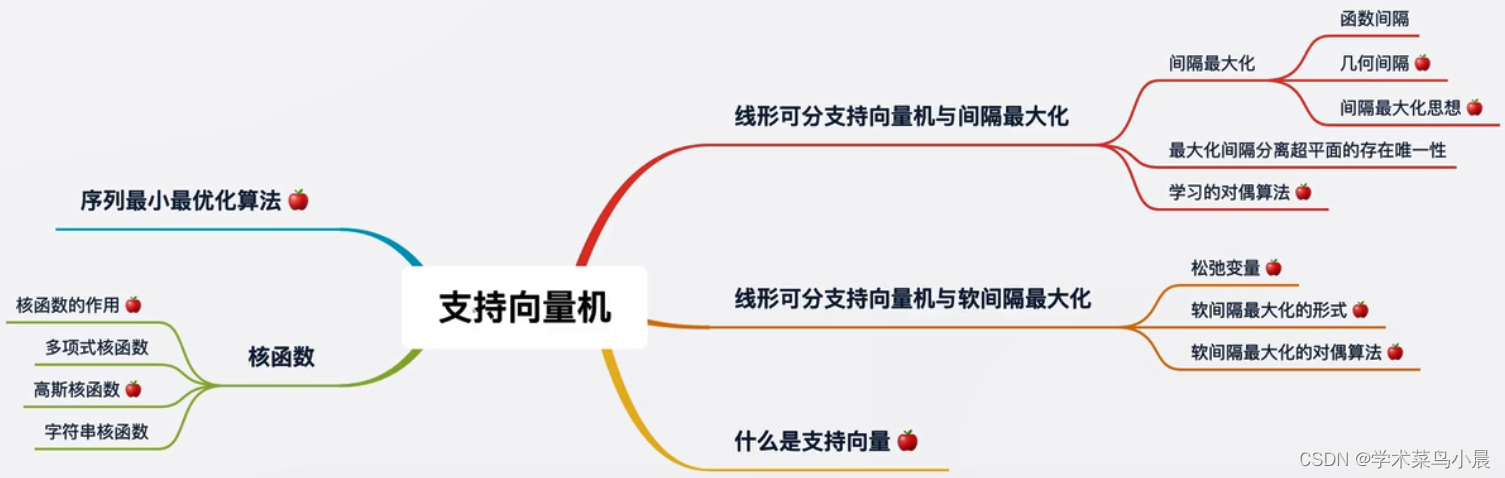
2. 感知机(分类模型)
2.1 sgn 函数
sgn 函数,或称为符号函数(sign function),是一个用于确定实数符号的数学函数。sgn 函数的定义如下:
- 当 x>0x > 0x>0 时,sgn(x) = 1
- 当 x=0x = 0x=0 时,sgn(x) = 0
- 当 x<0x < 0x<0 时,sgn(x) = -1
2.2 感知机
1)模型
感知机的具体公式如下:
其中, 为样本的特征向量,是感知机模型的输入;
和
\是感知机模型的参数,分别为权重和阈值。
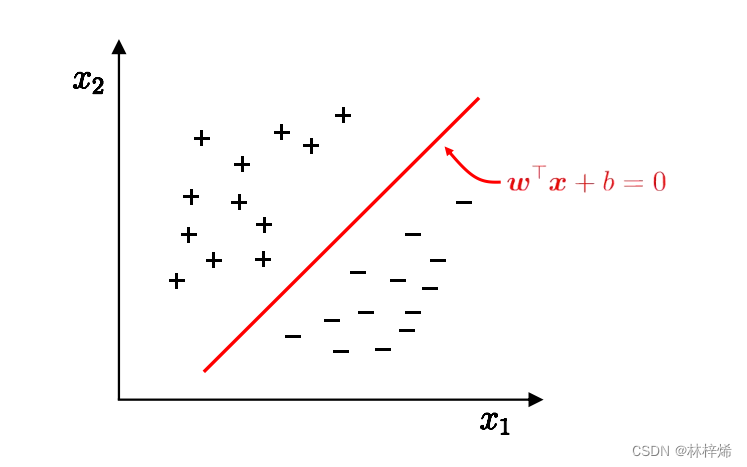
从几何角度来看,给定一个线性可分的数据集 ,感知机的学习目标是找到能将数据集
中的正负样本完全正确划分的超平面,
即为超平面方程。 n 维空间中的超平面
具有以下特点:
1. 超平面方程不唯一 ;
2. 法向量 垂直于超平面 - 法向量
和位移项
确定一个唯一的超平面 ;
3. 法向量 指向的那一半空间为正空间,另一半为负空间。
缺点:感知机只能解决线性可分的问题。
模型图如下所示,只包含一个输入层和一个输出层。
2)策略
感知机的学习策略是随机初始化和
,将所有训练样本带入模型找出误分类样本。假设误分类样本的集合为
,对任意一个误分类样本
来说:
当 时,模型输出
\,但真实标记为
当 时,模型输出
,但真实标记为
综合两种情况可知,以下公式恒成立:
所以,给定数据集 ,损失函数可以定义为:
如果没有误分类点,损失函数值为 0。当误分类点越少且离超平面越近,损失函数值越小。 损失函数还可以进一步优化,将 并入
向量中成为第 n+1 维,其中
的第 n+1 维恒为 -1。简化后的损失函数为:
3)算法
当误分类样本集合 固定时,可以求得损失函数
的梯度:
学习算法具体采用随机梯度下降法,即每次随机选取一个误分类点进行梯度下降。权重 的更新公式为:
其中为学习率。最终解出来的
通常不唯一。
3. 神经网络
为了解决线性不可分的数据集问题(感知机无法解决,但其他单个神经元模型可以),提出了由多个神经元构成的神经网络。根据通用近似定理,只需一个包含足够多神经元的隐层,多层前馈网络(最经典的神经网络之一)就能以任意精度逼近任意复杂度的连续函数。
3.1 优点
- 广泛的应用能力:神经网络既能用于回归问题,也能用于分类问题,显示出很强的通用性。
- 减少特征工程:神经网络能够自动提取特征,减少了复杂的人工特征工程工作量。
3.2 缺点
- 架构设计依赖经验:在具体应用场景中,如何选择神经网络的深度和宽度没有明确的理论指导,通常依赖于经验和实验。
- 结构设计缺乏理论支撑:在设计神经网络的结构时,没有强有力的理论指导,设计最合理的网络结构需要反复尝试和优化。
- 可解释性差:神经网络的输出结果通常难以解释,模型的决策过程不透明,这在需要高可解释性的应用中是一个挑战。模型的可解释性对于指导特征调整非常重要。
3.3 经典神经网络——多层前馈网络
每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。
可以将神经网络(NN)看作一个特征加工函数:
回归:后面接一个的神经元,形式为
分类:后面接一个 的神经元,例如激活函数为 sigmoid 的神经元,形式为:
神经网络可以自动提取特征,不用人为的手工设计特征。
3.4 神经网络训练方法——BP 算法
在20世纪80年代之前,尽管神经网络已经存在一段时间,但其实际应用受到了限制,主要原因在于无法有效地训练多层神经网络。在此背景下,1986年,David E. Rumelhart、Geoffrey E. Hinton 和 Ronald J. Williams 在他们的论文《Learning Representations by Back-Propagating Errors》中提出了反向传播算法。这一算法为多层前馈神经网络的训练提供了有效的方法,使得神经网络可以在更复杂的问题上展现出强大的表现力。
3.5 反向传播算法
反向传播算法(Backpropagation,简称BP)是一种基于随机梯度下降(SGD)的参数更新算法。在处理多层神经网络时,反向传播通过链式法则有效地计算每个参数的梯度,而随机梯度下降则利用这些梯度来更新权重,从而实现网络的高效训练。
反向传播算法与随机梯度下降相辅相成,共同实现了多层神经网络的高效训练。以下是以输入层第 i个神经元与隐层第 h 个神经元之间的连接权重为例的推导:
损失函数:
权重的更新量:
通过链式求导得到:
反向传播的关键步骤
- 前向传播:计算每一层的输出,直到得到网络的最终输出。
- 计算损失:根据输出和目标值,计算损失函数 EEE。
- 反向传播:通过链式法则计算损失函数关于每个权重的梯度。
- 更新权重:使用梯度下降法更新权重。
4. 总结
- M-P 神经元 是一种早期重要的数学模型,用于模拟生物神经元的功能。
- 感知机 是基于 M-P 神经元的分类模型,适用于线性可分的数据。
- 神经网络 由多个神经元构成,能够解决线性不可分的问题,并且具有很强的函数逼近能力。
- 反向传播算法(BP算法) 是训练神经网络的核心方法,通过梯度下降法实现高效训练。
参考文献
[1] 【吃瓜教程】《机器学习公式详解》(南瓜书)与西瓜书公式推导
[2] 周志华.机器学习[M].清华大学出版社,2016.
[3] 谢文睿 秦州 贾彬彬.机器学习公式详解第2版[M].人民邮电出版社,2023.
![[<span style='color:red;'>吃</span><span style='color:red;'>瓜</span>教程]南瓜书<span style='color:red;'>第</span>6<span style='color:red;'>章</span><span style='color:red;'>支持</span><span style='color:red;'>向量</span><span style='color:red;'>机</span>](https://i-blog.csdnimg.cn/direct/fd9e6f80d10e42d0b3465334dd9bd5f7.png)
![[<span style='color:red;'>吃</span><span style='color:red;'>瓜</span>教程]南瓜书<span style='color:red;'>第</span>6<span style='color:red;'>章</span>软间隔与<span style='color:red;'>支持</span><span style='color:red;'>向量</span>回归](https://i-blog.csdnimg.cn/direct/d5e2dfb8b1ed469193b6cc40b5fb9c59.png)