单台机器GPU资源不足以执行推理任务时,一个方法是模型蒸馏量化,结果就是会牺牲些效果。另一种方式是采用多台机器多个GPU进行推理,资源不足就堆机器虽然暴力但也是个不错的解决方法。值得注意的是多机多卡部署的推理框架,也适用于单机多卡,单机单卡,这里不过多赘述。
1、vLLM分布式部署
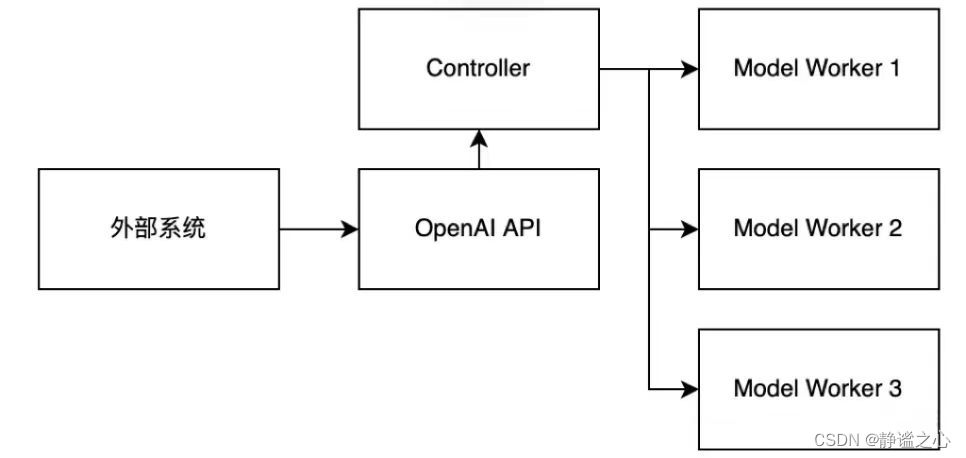
给到我的需求是Ubuntu中部署Meta-Llama3-70B未量化大模型,两台工作站,每台仅4张4090 24G显卡,并采用docker环境,在稍微调研了一些支持多级多卡、支持serving部署的工具后,最终选择vllm部署,主要原因是看着简单,主流的开源LLM都支持且提供OpenAI接口访问。
docker镜像构建
🐲 docker镜像构建基本上就是参照一位博主的文章vLLM分布式多GPU Docker部署踩坑记来构建的镜像,区别就是去掉了里面的ENTRYPOINT以及添加node的entrypoint,仅在执行命令docker run时加上了使容器不退出的一行代码:tail -f /dev/null。
去掉的主要原因是作为新手小白,部署环境在频繁的踩坑,需要随时stop/start ray集群。
docker run -d \
--runtime=nvidia \
--network=host \
--ipc=host \
-v ${volume_user}:/user_data \
--gpus $gpus \
--name $container_name \
vllm:v5 \
tail -f /dev/null
注意: dockerfile里面不要使用命令EXPOSE暴露任何端口, vllm:v5是我自己构建的docker image.
通信环境配置
🐲 我是一台机器启动了一个docker,将docker当作一个节点,在docker里面执行ray start --head --port=6379,将另一台机器的docker作为worker节点,并加入到ray cluster中,如果机器间的通信没有问题,worker节点在几秒内就能加入集群。
docker run启动
ray集群的构建,涉及到很多端口,且有些是在某个范围内随机分配端口,如果采用docker和容器间的端口一一映射形式启动docker,docker run命令会执行相当久且不利于firewall规则的配置,因此建议选用network=host ipc=host形式的docker启动方式。firewall规则的配置
在work节点执行ray start --address==xxx命令后,work节点加入了ray cluster,短暂时间后执行ray status命令,work节点掉线了,多半是机器间的通信问题,如果是同一网段的两台机器,可以采用以下命令设置同一网段内的机器互相访问无限制firewall-cmd --permanent --zone=trusted --add-source=192.168.0.0/16 #允许该网段所有访问所有端口不建议直接关闭掉防火墙,容易产生更大的安全问题。更多信息参考该博文。
环境变量配置
vllm多节点多GPU部署LLM,节点间的通信涉及到GOO、TCP、NCCL等,下面是一些配置信息(docker内编辑/etc/profile文件,并source /etc/profile,或者写入~/.bashrc,同样需要source ~/.bashrc)# 指定通信网卡 export GLOO_SOCKET_IFNAME=eno16np0 export TP_SOCKET_IFNAME=eno16np0 # NCCL配置 # export NCCL_SOCKET_NTHREADS=10 export NCCL_SOCKET_IFNAME=eno16np0 export NCCL_DEBUG=info export NCCL_NET=Socket export NCCL_IB_DISABLE=0eno16np0是容器中的网卡名称,指定采用哪个网卡进行通信。下面的CUDA_HOME替换为你的cuda的实际路径。
# 环境变量 export CUDA_HOME="/usr/local/cuda-12.1" export PATH="${CUDA_HOME}/bin${PATH:+:"${PATH}"}" export LD_LIBRARY_PATH="${CUDA_HOME}/lib64:${CUDA_HOME}/extras/CUPTI/lib64${LD_LIBRARY_PATH:+:"${LD_LIBRARY_PATH}"}" export LD_LIBRARY_PATH=/usr/lib/x86_64-linux-gnu:$LD_LIBRARY_PATH export LD_LIBRARY_PATH+=:/usr/local/libdocker里面的主机设置
确保head节点的IP与指定的通信网卡的IP一致,同时,检查/etc/hosts里面的IP对应的主机名与docker的主机名是一致的。
2、其他大模型部署工具
- 推理工具
- Deepspeed-inference& Deepspeed-fastgen
- Accelerate
- TensorRT-LLM
- ollama
- llama.cpp
- FastChat
- serving部署工具
- Triton inferece server(仅FasterTransformer后端支持多节点多卡部署)
- LMdeploy
- vllm
3、问题记录
- vllm启动时出现 WARNING[XFORMERS]: xFormers can’t load C++/CUDA extensions. xFormers was built for 问题
- 现象1:PyTorch 2.3.0+cu121 with CUDA 1201 (you have 2.3.0+cu118)
- 现象2:Python 3.10.14 (you have 3.10.12)
- 原因: xFormers与pytorch、cuda、python版本不一致,解决办法就是找到相应的包重新安装,conda-xFormers版本列表、Github-xFormers,或者更新你得pytorch版本,选择torch2.3.0+cu12
- vllm启动时出现 NameError: name ‘vllm_ops’ is not defined 问题
- 为保持整篇文章的整洁,原因分析和解决办法我放另一篇文章了
- vLLM执行推理时出现:ValueError: Total number of attention heads (32) must be divisible by tensor parallel size (6).
- 更改vLLM的tensor_parallel_size参数,使其可以被被部署的大模型的注意力头数整除即可,头数可以查看大模型config.json中的参数:num_attention_heads。




































![[leetcode hot 150]第一百一十七题,填充每个节点的下一个右侧节点](https://i-blog.csdnimg.cn/direct/12b6fab522e64026b253f2dd9fd1f6cc.png)
