场景
之前尝试用knn算法尝试一个图像识别(给苹果,香蕉分类)的案例,很吃性能且准确率不佳。支持向量机(SVM)是一种广泛应用于分类和回归问题的强大监督学习算法。就很适用于这种场景。
概念
支持向量(Support Vectors)
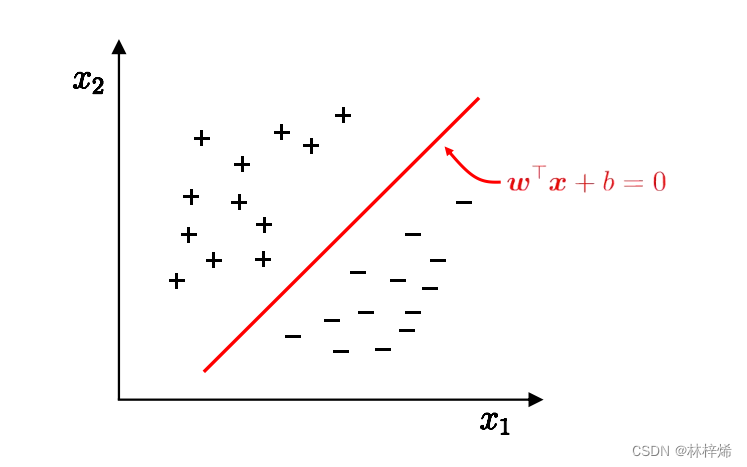
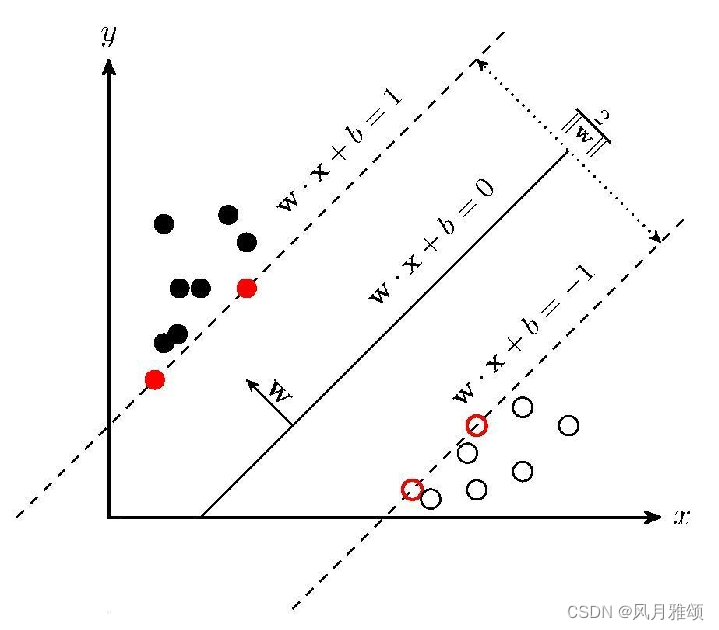
在支持向量机(SVM)中,支持向量是非常核心的概念。它们是离分隔超平面最近的那些数据点。这些点实际上支撑着或定义了超平面的位置和方向。在SVM模型中,只有支持向量才会影响最终决策边界的位置;其他的数据点并不会对其产生影响。
支持向量的重要性
定义边界:支持向量是最优超平面的关键组成部分,因为它们直接定义了分类间隔的边界。
模型简洁性:在SVM中,只有支持向量对模型的建立是重要的。这意味着,尽管训练数据可能非常庞大,但最终模型的复杂度却由较少数目的支持向量决定,从而提高了模型的计算效率。
鲁棒性:由于只有支持向量影响决策边界,因此SVM对于数据中的噪声和非支持向量点的变化相对不敏感,增强了模型的泛化能力。
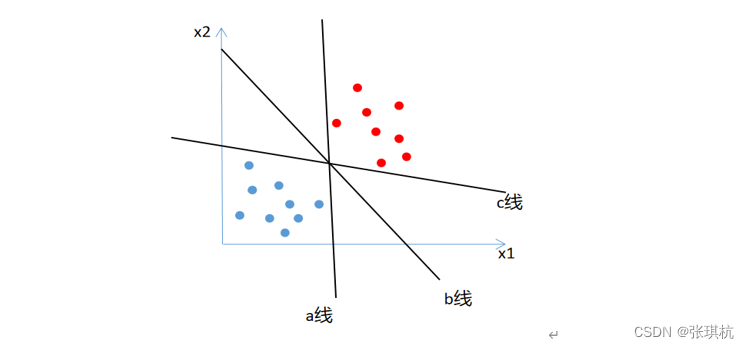
假设我们在二维空间中有两类数据点,一类为正类,另一类为负类。SVM的目标是找到一条直线(即超平面)来尽可能完美地分隔这两类点。这条直线的位置由离它最近的几个点(即支持向量)决定。这些点的位置决定了直线的方向和位置,从而确定了分类的最佳边界。
鲁棒性(Robustness)
处理现实世界数据:现实世界的数据往往包含噪声、缺失值或异常值。鲁棒性强的模型能够有效处理这些不完美的数据,提供可靠的输出。这和之前的Knn算法,还有香农熵算法、概率论算法对数据的比较严格的要求不同。
提高泛化能力:鲁棒的模型在面对新的、未见过的数据时表现更好,具有更强的泛化能力。
减少对数据预处理的依赖:如果一个模型足够鲁棒,它可以减少对数据清洗和预处理的需求,从而简化模型的应用过程。
鲁棒性在SVM中的体现
在支持向量机(SVM)中,鲁棒性体现在其对于支持向量以外的数据点不敏感的特性。SVM的决策边界(超平面)主要由支持向量决定,这意味着非支持向量的数据点,即使包含噪声或异常值,也不会显著影响模型的决策边界。这使得SVM在处理包含一些噪声或异常值的数据时,仍能保持较好的性能,显示出较强的鲁棒性。
回到案例
假设我们在二维空间中有两类数据点,一类为正类,另一类为负类。SVM的目标是找到一条直线(即超平面)来尽可能完美地分隔这两类点。这条直线的位置由离它最近的几个点(即支持向量)决定。这些点的位置决定了直线的方向和位置,从而确定了分类的最佳边界。 这个过程是怎样的呢?
初始化模型:在开始时,我们可能会随机选择一个超平面(或者基于一些启发式方法选择),但这个初步选择的超平面并不是最终的模型。
优化过程:通过优化算法(如SMO算法),SVM开始调整超平面的位置和方向,以便最大化两类数据点间的间隔。这个过程涉及到调整超平面的参数(比如在二维空间中的直线方程参数)。
在支持向量机(SVM)中,优化算法用于寻找最优的超平面,即那个能够最大化正负类别间隔的超平面。常见的几种优化算法包括:1. 序列最小优化(SMO)算法
案例:假设有一个中等规模的文本分类问题,我们需要将一组文档分类为正面或负面评价。
数学原理:SMO算法的核心是将SVM的优化问题分解为一系列最小化问题。它通过每次选择两个拉格朗日乘数进行优化,并固定其他的乘数。这样,每次迭代只需要解决一个简单的二次规划问题,从而加速整个训练过程。
解释:在文本分类案例中,SMO算法通过迭代地优化这些乘数来调整超平面的位置,直到找到能够最大化间隔的最优解。2.梯度下降(Gradient Descent)
案例:考虑一个大规模的图像识别任务,目标是将图像分类为包含特定物体的类别。
数学原理:梯度下降通过计算损失函数(如SVM的铰链损失)关于模型参数(超平面的法向量和偏置项)的梯度,并沿着梯度的反方向更新参数,以逐步减少分类错误。
解释:在图像识别案例中,梯度下降会根据成千上万个图像的损失来更新超平面的位置,从而提高分类的准确性。3.内点方法(Interior Point Method)
案例:设想一个用于金融欺诈检测的大型数据集,目的是识别欺诈和非欺诈交易。
数学原理:内点方法专门解决线性和非线性优化问题,通过在约束的内部寻找解,避免在可行域的边界上进行复杂的搜索。
解释:在金融欺诈检测案例中,内点方法可以有效处理成千上万的交易数据,快速找到将欺诈交易和正常交易分开的超平面。4.切平面方法(Cutting Plane Method)
案例:假设有一个用于大规模文本分析的数据集,需要对大量的文档进行分类。
数学原理:切平面方法通过逐步添加线性不等式约束来改进解的下界,不断缩小搜索空间,逐步逼近最优解。
解释:在文本分析案例中,切平面方法能有效处理海量的文本数据,通过不断细化模型的约束条件,找到最佳的文档分类超平面。
确定支持向量
在优化过程中,会确定哪些数据点是支持向量。支持向量是距离当前超平面最近的数据点,它们实际上定义了间隔的边界。
迭代优化
SVM通过不断迭代优化过程来调整超平面,以确保支持向量确实是最接近超平面的点,即这些支持向量确实提供了最大间隔。
最终模型
当算法收敛时,最终的超平面位置会被确定下来,这时的支持向量也就确定了。这些支持向量恰好位于由超平面确定的最大间隔的边界上。
结束
这一把只是我的简单理论。上次正式开始。
























](https://img-blog.csdnimg.cn/direct/b66ab2c76dd94eaba95362b880f3209d.png)