提出了一种双支路Transformer来组合不同大小的图像补丁(即变压器中的令牌)以产生更强的图像特征。方法处理具有不同计算复杂度的两个独立分支的小补丁和大补丁令牌,然后这些令牌纯粹通过注意多次融合以相互补充。此外,为了减少计算量,开发了一个简单而有效的基于交叉关注的令牌融合模块,该模块使用每个分支的单个令牌作为查询来与其他分支交换信息。提出的交叉注意只需要计算和记忆复杂度的线性时间,而不是二次时间。大量的实验表明,除了高效的CNN模型外,CrossViT在Vision Transformer上的表现优于或等同于一些并行工作。
1. 引言
视觉变压器(Vision Transformer, ViT)使用一系列嵌入图像补丁作为标准变压器的输入,是第一种与CNN模型性能相当的无卷积变压器。然而,ViT需要非常大的数据集,如ImageNet21K和JFT300M进行训练。DeiT[35]随后表明,数据增强和模型正则化可以用更少的数据训练高性能的ViT模型。
研究了如何学习Transformer模型中的多尺度特征表示用于图像识别。多尺度特征表示已被证明对许多视觉任务是有益的。受Big-Little Net[5]和Octave convolutions[6]等多分支CNN架构有效性的启发,提出了一种双分支Transformer,将不同大小的图像patch(即Transformer中的token)组合在一起,产生更强的视觉特征用于图像分类。使用不同计算复杂度的两个独立分支处理大小补丁令牌,并将这些令牌多次融合在一起以相互补充。
工作的主要重点是开发适合视觉变压器的特征融合方法。通过一个高效的交叉关注模块来实现这一点,其中每个Transformer分支创建一个非补丁令牌作为代理,通过注意力与其他分支交换信息。这允许在融合中线性时间内生成注意力图,而不是二次时间。通过对每个分支的计算负载进行适当的体系结构调整,提出的方法比DeiT[35]的性能高出2%,而FLOPs和模型参数的增加幅度很小(见图)。
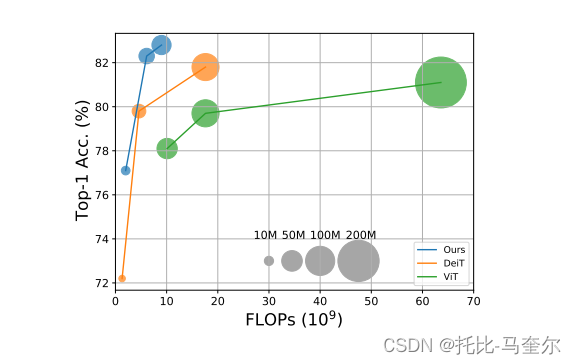
1.1 主要工作贡献
提出了一种新的双分支Vision Transformer来提取多尺度特征表示用于图像分类。此外,开发了一种简单而有效的基于交叉注意的令牌融合方案,该方案在计算和内存上都是线性的,可以将不同尺度的特征组合在一起。
2. 相关工作
三个主要的研究方向:带注意力的卷积神经网络、Vision Transformer和多尺度CNN。
2.1 带注意力的卷积神经网络
注意力以多种不同的形式被广泛用于增强特征表示,例如,SENet[18]使用通道注意,CBAM[41]增加了空间注意,ECANet[37]提出了一种有效的通道注意来进一步改进SENet。将CNN与不同形式的自我关注结合起来[2,32,48,31,3,17,39]。SASA[31]和SAN[48]使用local-attention层代替卷积层。尽管已有的方法取得了良好的结果,但由于其复杂性,将关注范围限制在局部区域。LambdaNetwork[2]引入了一种高效的全局关注模型,用于内容和基于位置的交互,大大提高了图像分类模型的速度-精度权衡。BoTNet[32]在ResNet的最后三个瓶颈块中用全局自关注取代了空间卷积,从而使模型在ImageNet基准上实现了较强的图像分类性能。
2.2 Vision Transformer
许多Vision Transformer的变体,使用蒸馏进行Vision Transformer的数据高效训练[35],金字塔结构(如CNN[38])或自注意,通过学习抽象表示来提高效率,而不是执行所有到所有的自注意[42]。Perceiver[19]利用不对称注意机制迭代地将输入提炼成一个紧密的潜在瓶颈,使其能够扩展到处理非常大的输入。T2T-ViT[45]引入了分层token -to - token (T2T)转换,为每个token编码重要的局部结构,而不是ViT[11]中使用的幼稚的token化。与这些方法不同,本文提出了一种双路径架构来提取多尺度特征,以便使用Vision Transformer更好地进行视觉表示。
2.3 多尺度CNNs
多尺度特征表示在计算机视觉中有着悠久的历史(例如,图像金字塔[1],尺度空间表示[29]和粗到精方法[28])。在CNN的背景下,多尺度特征表示已被用于多尺度物体的检测和识别[4,22,44,26],并用于加速Big-Little Net[5]和OctNet[6]中的神经网络。bLVNet-TAM[12]使用两分支多分辨率架构,同时学习跨帧的时间依赖性。慢速网络[13]依赖于类似的两分支模型,但每个分支编码不同的帧速率,而不是具有不同空间分辨率的帧。
3. 方法
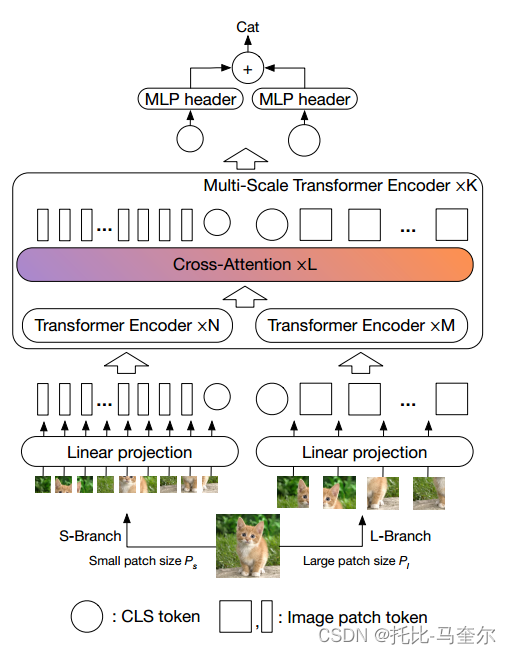
交叉注意(crosssvit)学习多尺度特征的Transformer架构
架构由K个多尺度Transformer Encoder组成。每个多尺度Transformer Encoder使用两个不同的分支来处理不同大小的图像令牌(





















![[解决] chrome/edge浏览器打开F12开发者模式,点击应用标签崩溃](https://img-blog.csdnimg.cn/img_convert/226dc99c2a699b9efe9363ff758cb14d.png)





![[学习笔记]SQL学习笔记(连载中。。。)](https://i-blog.csdnimg.cn/direct/975a8deaec5243e5bc6e243520f5ee1b.png)



