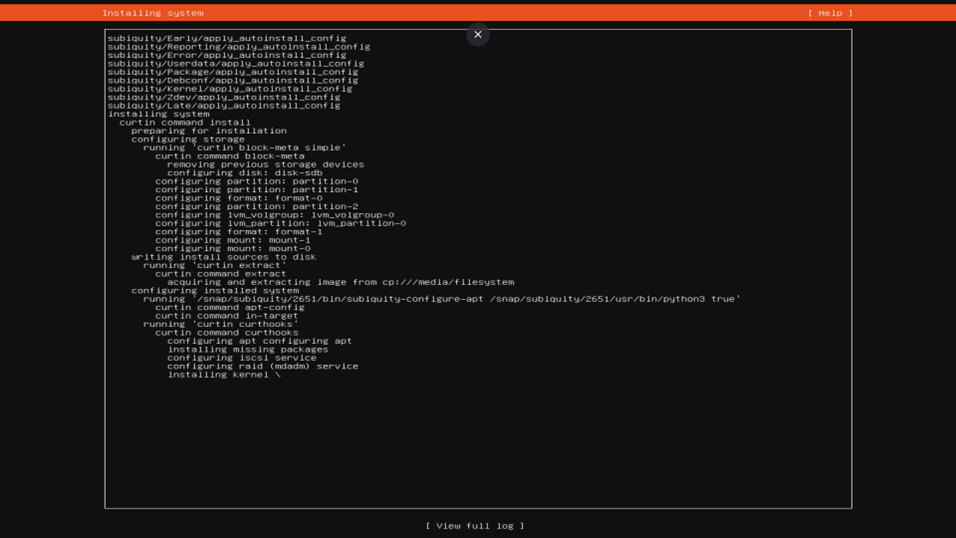
NVIDIA H100 Tensor Core GPU的特性概括如下:
先进的制造工艺与规模:H100基于NVIDIA Hopper架构,采用台积电定制的4N工艺,集成高达800亿个晶体管,是目前世界上最为先进的芯片。
性能飞跃:针对大规模人工智能(AI)和高性能计算(HPC)应用,H100相较于上一代A100 Tensor Core GPU实现了数量级的性能提升。在主流AI和HPC模型中,配合InfiniBand互连技术,H100可提供最高达A100 30倍的性能。
新一代流式多处理器(SM):H100包含全新设计的SM,带来众多性能和效率改进。第四代Tensor Cores相比A100在芯片间通信速度上快至6倍,每个SM的基础矩阵乘积累(MMA)运算速率在相同数据类型下是A100的两倍,并且通过支持新的FP8数据类型,其速率是A100的四倍,同时利用细粒度结构稀疏性进一步提升深度学习网络的性能。
高效的数据传输:H100配备了增强的NVLink Switch System互连技术,针对需要跨多个GPU加速节点的模型并行性的大型和复杂计算工作负载,可以实现再次的性能飞跃,在某些情况下性能提升可达三倍。
Grace Hopper Superchip集成:H100将作为NVIDIA Grace Hopper Superchip的一部分,与NVIDIA Grace CPU搭配,专为太字节级别的加速计算设计,针对大型模型的AI和HPC提供比现有系统高10倍的性能。Grace与H100之间通过超高速的片间互连,提供900GB/s的带宽,比PCIe Gen5快7倍,为处理大规模数据的应用程序提供最高30倍的聚合带宽提升和最高10倍的性能提升。
综上所述,NVIDIA H100不仅在硬件架构上实现了显著优化和创新,还在数据传输速度、计算效率以及与下一代CPU集成方面展现了革命性的进步,特别适合于驱动要求极高的AI训练、推理、HPC以及数据分析应用。
H100 GPU的特性包括:
DPX指令集:加速动态规划算法,相比A100 GPU在某些应用中(如基因组处理的Smith-Waterman算法和动态仓库环境中寻找最优机器人路径的Floyd-Warshall算法)速度提升至多7倍。
更高的FP64与FP32处理性能:相比A100,H100提供了2倍的每流处理器时钟频率性能、更多的流处理器数量以及更高的时钟频率,使得芯片间的数据处理速率快3倍。
线程块集群功能:扩展了CUDA编程模型,允许在单个流式多处理器上对局部性进行比单个线程块更粗粒度的程序控制,新增了线程块集群这一编程层级。
异步执行特性:引入了Tensor Memory Accelerator (TMA)单元,高效地在全局内存和共享内存之间传输大量数据,并支持线程块集群内的异步数据复制。还新增了异步事务屏障以实现原子数据移动和同步。
Transformer Engine:结合软件和定制的Hopper张量核心技术,专门加速Transformer模型的训练和推理。自动管理FP8和16位计算的选择与转换,提供至多9倍的AI训练加速和30倍的大型语言模型推理速度提升。
HBM3内存子系统:相比前代,带宽接近翻倍,H100 SXM5是全球首款配备HBM3内存的GPU,提供3TB/秒的顶级内存带宽。
50MB二级缓存:缓存大量模型和数据集以减少对HBM3的访问,提高重复访问效率。
第二代多实例GPU (MIG):相比A100,提供约3倍的计算容量和近2倍的每GPU实例内存带宽。首次提供MIG级别的可信执行环境(TEE)以支持保密计算,最多支持7个独立GPU实例,每个实例配备NVDEC和NVJPG单元及性能监控工具。
保密计算支持:保护用户数据,防御硬件和软件攻击,增强虚拟化和MIG环境下VM之间的隔离与保护,实现世界上首个原生保密计算GPU。
第四代NVIDIA NVLink:所有reduce操作的带宽增加3倍,一般带宽相比上一代提升50%,总带宽达到900GB/秒,是PCIe Gen 5的7倍。
第三代NVSwitch技术:内部和外部的交换机连接服务器、集群和数据中心环境中的多个GPU,提供更快的多GPU连接。单节点内NVSwitch提供的第四代NVLink链接端口增至64个,总吞吐量提升至13.6Tbits/sec。
NVLink交换系统:基于第三代NVSwitch技术的新第二层交换机引入地址空间隔离和保护,最多可连接32个节点或256个GPU,形成2:1锥形胖树拓扑,提供57TB/秒的全互联带宽,实现1艾(Exa)FLOP的FP8稀疏AI计算。
PCIe Gen 5:提供128GB/秒的总带宽(每方向64GB/秒),相比Gen 4的64GB/秒总带宽(每方向32GB/秒),使H100能够与高性能x86 CPU和SmartNIC/DPU高效接口。
其他新特性:优化强扩展性、降低延迟和开销,简化GPU编程。
H100 GPU在深度学习、数据分析、高性能计算等多个领域显著提升数据中心的性能,支持现代工作负载的端到端加速,为企业的基础设施提供强大支持。
H100 相关特性概括如下:
H100 SXM5 GPU:
- 使用定制的 SXM5 板,集成 H100 GPU 和 HBM3 内存。
- 支持第四代 NVLink 和 PCIe Gen 连接,提供最高应用性能。
- 适用于多GPU服务器扩展,可通过4-GPU或8-GPU配置的HGX H100服务器板获取。
- 4-GPU配置有点对点NVLink连接,提高CPU到GPU的比例;8-GPU配置使用NVSwitch实现SHARP网络缩减和每对GPU间900GB/s的全NVLink带宽。
- 应用于强大的新DGX H100服务器和DG SuperPOD系统。
H100 PCIe Gen 5:
- 在350瓦的热设计功率(TDP)下提供与H100 SXM5相同的性能。
- 可选配NVLink桥接器,连接两块GPU,带宽达600GB/s,接近PCIe Gen5的五倍。
- 适合主流加速服务器,单个H100 PCIe GPU在消耗较少功率的情况下,为AI推理和某些HPC应用提供高性能。
DGX H100和DGX SuperPOD:
- 高性能AI系统,适用于训练、推理和数据分析。
- 配备Bluefield-3、NDR InfiniBand和第二代MIG技术,单系统提供16 petaFLOPS的FP16稀疏AI计算性能。
- 可通过连接多个DGX H100系统形成DGX POD或DGX SuperPOD集群,后者起始规模为32个系统(“可扩展单元”),集成256个H100 GPU,通过第二代NVSwitch技术实现一exaFLOP的FP8稀疏A计算性能。
- 支持InfiniBand和NVLink交换网络选项。
HGX H100:
- 结合多个H100 GPU和高速NVLink/NVSwitch互连,创建世界上最强的扩展服务器。
- 提供4-GPU或8-GPU配置,四GPU配置有全互联点对点NVLink;八GPU配置通过NVSwitch实现全GPU至GPU带宽。
- 8路HGX H100利用多精度Tensor Core,提供超过32 petaFLOPS的深度学习计算性能,使用稀疏FP8操作。
H100 CNX融合加速器:
- 结合H100 GPU与ConnectX-7 SmartNIC,提供高达400Gb/s带宽,支持ASAP2加速交换和数据包处理,以及TLS/IPsec/MACsec加解密硬件加速。
- 适用于企业数据中心的分布式AI训练或边缘5G信号处理等I/O密集型工作负载。
H100 GPU架构创新:
- 第四代Tensor Core,矩阵运算速度更快,适用更广泛的AI和HPC任务。
- 新的Transformer Engine,相比上一代A100,提供最多9倍的AI训练加速和最多30倍的大型语言模型推理速度提升。
- 新的NVLink网络互连,允许最多256个GPU跨多计算节点通信。
- 安全MIG技术,将GPU分割成隔离的、适合大小的实例,优化小负载的工作服务质量。
- 首款真正异步GPU,具有全局共享异步传输、张量内存访问模式支持,以及完全重叠数据移动和计算的能力。
- 引入Thread Block Cluster层级,提升多SM间线程合作和数据共享效率,有效协调异步单元和通用计算线程,确保GPU资源的充分利用。
NVIDIA H100 GPU 的特性总结如下:
架构设计:
- H100 GPU 提供了多种配置,包括 GH100 全尺寸版本、SXM5板型以及PCIe板型。
- 全尺寸GH100包含8个GPCs、72个TPCs和144个SMs,而SXM5和PCIe板型分别拥有132和114个SMs。
- 每个SM配备128个FP32 CUDA核心,全尺寸GH100总计有18432个,SXM5和PCIe版则分别为16896和14592个。
张量核心:
- 第四代张量核心,每个SM包含4个,全尺寸GH100总计576个,SXM5和PCIe版分别有528和456个。
- 引入FP8数据类型,使得每时钟周期的浮点运算能力相比A100翻倍,且在特定情况下可提升至4倍。
- 支持稀疏性特性,利用深度学习网络中的细粒度结构稀疏性,使标准张量核心操作性能翻倍。
内存与缓存:
- HBM3或HBM2e存储技术,SXM5版配备80GB HBM3和5个堆栈,PCIe版为80GB HBM2e和5个堆栈。
- 配备60MB(全尺寸GH100)或50MB(SXM5和PCIe)的L2缓存。
- 采用10个512位内存控制器,提供高带宽访问。
互连与接口:
- 第四代NVLink和PCIe Gen 5,增强多GPU间通信速度和系统连接性。
- 仅有的两个TPC在SXM5和PCIe版H100上支持图形处理,包括顶点、几何和像素着色器。
性能提升:
- 使用台积电4N工艺制造,提高了GPU核心频率和每瓦性能。
- 新的Transformer Engine与FP8张量核心结合,使得AI训练速度最多快9倍,大型语言模型推理速度快30倍。
- DPX指令集加速动态规划算法,如基因组处理中的Smith-Waterman算法,加速可达7倍。
HPC与AI性能:
- 第四代张量核心、张量内存加速器和其他新SM架构改进,共同实现了某些情况下高达3倍的HPC和AI性能提升。
数据类型与吞吐量:
- 支持FP8、FP16、BF16、TF32、FP64和INT8等数据类型,FP8张量核心提供相比FP16或BF16两倍的吞吐量和一半的存储需求。
- 在不同数据类型的峰值性能上,如FP64、FP32、TF32、FP16、BF16和INT8,H100相比前代A100实现了显著的性能提升,部分达到3倍甚至更高。
综上所述,NVIDIA H100 GPU通过其高度优化的架构设计、第四代张量核心、增强的内存配置、高效的互连技术以及对多种数据类型的支持,特别针对数据中心、边缘计算、人工智能、高性能计算和数据分析工作负载进行了优化。
H100 相关特性概括如下:
性能加速:相比于 A100,H100 在多种计算任务上实现了显著的性能提升。例如,在 FP8 张量运算上达到 1978.9 TFLOPS,相较于 A10 核心有 6.3 倍的提升;在 FP16 张量运算上,从 312 TFLOPS 提升至 989.4 TFLOPS,实现 3.2 倍加速;BF16 和 TF32 的张量运算同样实现了 3.2 倍的性能提升;同时,对于 INT8、FP64 以及 FP32 也都有不同程度的性能增长。
DPX 指令集:H100 引入了 DPX 指令,专门用于加速动态规划算法,与安培架构的 GPU 相比,性能最高可提升 7 倍。这些指令支持许多动态规划算法内部循环中的高级融合操作数,将大幅缩短疾病诊断、物流路线优化和图分析等应用的解决方案时间。
L1 数据缓存与共享内存整合:H100 继承并增强了自 Volta V100 开始的 L1 数据缓存和共享内存整合架构,每 SM 的整合容量提升至 256 KB(A100 为 192 KB),并且 SM 共享内存大小可配置到最多 228 KB。这种设计简化编程的同时减少了达到峰值性能所需的调优工作,并为不同类型的数据访问提供了最优性能。
计算性能总览:综合考虑所有新计算技术进步,H100 相较于 A100 提供了约 6 倍的计算性能提升。这一提升来源于多个方面,包括更多的流处理器(SM)数量、每 SM 更快的第四代张量核心、新的 FP8 格式与 Transformer 引擎,以及更高的时钟频率。
线程块集群(Thread Block Cluster):H100 引入了一种新的架构概念——线程块集群,它扩展了 CUDA 编程模型,增加了程序层级的局部性控制,使得跨多个 SM 的线程能够高效协作。集群内包含的线程块在一组 SM 上并发调度,通过硬件加速的障碍同步和新的内存访问协作能力,以及专用的 SM-to-SM 网络,显著提高了数据交换效率,特别是在使用分布式共享内存(DSMEM)时,相比使用全局内存的数据交换速度提升了约 7 倍。
这些特性共同展示了 H100 在高性能计算领域的重大进步,特别适合处理世界上对计算能力要求最严苛的工作负载。
H100 相关特性概括如下:
异步执行能力提升:H100架构在异步执行方面进行了改进,允许更深度的数据移动、计算和同步的重叠,同时尽量减少同步点,从而提高性能和GPU利用率。
Tensor Memory Accelerator (TMA):为高效供给强大的H100 Tensor Cores,引入了新的TMA单元。TMA能够传输大块数据和多维张量,从全局内存到共享内存或反之。通过使用复制描述符而非逐元素寻址,减少了地址计算开销,并支持多种张量布局、内存访问模式、归约等特性,提高了数据传输效率。
异步内存拷贝操作优化:TMA操作是异步的,并利用基于共享内存的异步屏障(最初在A100上引入)。H100进一步增加了硬件加速这些异步屏障等待操作,以提高性能。
异步事务屏障:Hopper架构新增了异步事务屏障,这是一种新型的屏障形式,不仅跟踪线程到达,还跟踪事务计数,使得等待线程可以在所有生产者线程完成其“到达”并达到预期的事务计数之前进入休眠状态,从而更高效地利用等待时间进行其他独立工作。
HBM3和L2缓存内存架构:H100采用高性能的HBM3(SXM5版本)和HBM2e(PCIe版本)DRAM技术,显著提高了内存容量和带宽。SXM5版本提供80GB HBM3内存,内存带宽超过3TB/s,相比A100几乎翻倍;而PCIe版本则提供80GB HBM2e内存,带宽超过2TB/s。HBM内存设计减少了功耗和空间占用,使得系统能够安装更多GPU。
内存层次结构优化:全球和局部内存区域位于HBM内存空间内,对CUDA程序可访问,且通过L2缓存服务于GPU内部各种子系统的内存请求。这有助于提升整体应用性能和编程灵活性。
综上所述,H100 GPU通过异步执行优化、TMA的引入、异步事务屏障的创新以及HBM3/HBM2e内存技术的应用,实现了性能、效率和可编程性的显著提升,特别适合于高性能计算、人工智能和大数据分析等领域的复杂应用需求。
H100 相关特性包括:
全球首款HBM3 GPU内存架构:H100采用HBM3内存技术,提供比前代技术更高的带宽,具体为2倍于之前技术的带宽。
增强的L2缓存:拥有50MB的L2缓存,相比A100的40MB,增大了1.25倍。这使得更大模型和数据集的部分可以被缓存以供重复访问,减少了对HBM3或HBM2 DRAM的访问需求,从而提升性能。L2缓存使用分区交叉开关结构,直接为相连GPCs中的SM提供数据本地化和缓存。缓存驻留控制优化了容量利用,允许程序员选择性地管理应保留在缓存中或被替换的数据。
数据压缩与解压缩:HBM3和L2缓存子系统均支持数据压缩和解压缩技术,旨在优化内存和缓存使用及性能。
内存子系统RAS特性:
- ECC内存韧性:H100的HBM3/2e内存子系统支持单错误纠正双错误检测(SECDED)ECC,保护数据免受错误影响,特别适合大规模集群计算环境。
- Sideband ECC:H100的HBM3/2内存使用独立于主要HBM内存区域的小型内存区域来存储ECC位。
- 内存行重映射:H100能够无效化产生ECC错误的内存行,并在启动时使用保留的已知良好行进行替换,通过行重映射逻辑实现。
性能提升:H100相较于A100,在SM数量、TPC数量、FP32/FP64/INT32核心数以及Tensor核心数上均有显著增加,带来更强的计算能力。
内存接口和带宽:采用5120位HBM3内存接口,提供高达3352GB/s的内存带宽,远超A100的1555GB/s。
L2缓存大小:50MB的L2缓存,相比A100的40MB有所增加。
计算能力:H100支持新的计算能力9.0,较A100的8.0有所提升,意味着更先进的架构特性和指令集。
多实例GPU(MIG)技术改进:H100引入第二代MIG技术,相比A100,每个GPU实例提供近3倍的计算能力和几乎2倍的内存带宽。并且增强了云原生、多租户和多用户的隔离安全性,通过硬件和虚拟机监控程序级别的保密计算功能实现。
安全性与保密计算:Hopper架构通过硬件和虚拟化层面的增强,为多租户MIG配置提供全面的安全保障。####H100 GPU的特性包括:
安全多实例GPU (Secure MIG):H100能够被划分为四个安全MIG实例,每个实例都支持加密传输,并通过PCIe SR-IOV技术实现硬件虚拟化。这为多个用户提供独立的安全执行环境,同时保持内存隔离和数据完整性。
专用解码器:H100的每个MIG实例配备了专用于图像和视频解码的NVDEC和NVJPG单元,以支持在共享基础设施上进行安全、高吞吐量的智能视频分析(IVA)。
性能监控工具:H100 MIG实例包含了自身的一套性能监控器,与NVIDIA开发者工具协同工作,支持并发分析,帮助管理员监控并优化GPU资源分配,确保高效利用。
Transformer Engine:H100集成了一种定制的Tensor Core技术——Transformer Engine,专门用于加速Transformer模型的AI计算,这类模型广泛应用于语言处理到计算机视觉等众多领域。
混合精度计算:Transformer Engine运用智能管理精度的方法,在保持模型准确性的前提下,利用FP8等更小更快的数值格式提高性能。它动态地根据张量统计信息调整数据范围,以最优化的方式运行每一层。
第四代NVLink:H100搭载了第四代NVLink,相比A100中的第三代,提供了1.5倍的通信带宽,达到900 GB/s的总带宽,是PCIe Gen 5的7倍。每个GPU包含18个这样的链接,总共提供90 GB/s的带宽。
NVLink网络:H100引入了NVLink网络,这是一种可扩展的版本,允许最多256个GPU跨多个计算节点进行通信。它通过新的网络地址空间和地址翻译硬件来隔离各GPU的地址空间,实现更大规模的GPU间安全扩展。
第三代NVSwitch:H100使用的新一代NVSwitch技术不仅存在于服务器内部,也用于集群和数据中心环境,提高了多GPU连接速度,总交换带宽提升至13.6 Tbits/sec,并加速了集体通信操作,如全聚合、减少散列和广播原子操作。
NVLink交换系统:结合NVLink网络技术和第三代NVSwitch,可以构建大规模的NVLink交换系统网络,支持高达256个GPU的互联,提供57.6 TB/s的全互联带宽,支撑一亿亿次浮点运算的稀疏AI计算能力。
这些特性展示了H100在安全性、性能监控、AI计算加速、高速互连以及大规模扩展方面的能力,特别适合于要求严格的安全性、高性能计算和大规模机器学习任务的场景。
NVIDIA H100 GPU的特性包括:
NVLink Switch系统连接性:DGX H100 SuperPODs最多可扩展至256个GPU,通过基于第三代NVSwitch技术的新NVLink交换系统全连接。采用2:1锥形胖树拓扑的NVLink网络互连,实现了令人震惊的9倍于上一代InfiniBand系统的双工带宽增加,以及4.5倍的allreduce吞吐量提升。尽管目前H100系统不支持NVLink Switch System技术,但未来将宣布相关系统及可用性。
增强的电缆长度与连接器:最大交换机间电缆长度从5米增加到20米,并支持NVIDIA制造的OSFP(八小型可插拔)LinkX电缆,具有四端口光学收发器和8通道100G PAM4信号。这些创新使得单个1U、32槽的NVLink交换机能够拥有128个NVLink端口,每个端口数据传输速率为25 GB/s。
PCIe Gen 5接口:H100集成了PCI Express Gen 5 x16通道接口,提供总共128 GB/s的总带宽(每方向64 GB/s),相比A100中的Gen 4 PCIe的总带宽(每方向32 GB/s)翻倍。
CPU与SmartNIC/DPU的高效连接:通过其PCIe Gen 5接口,H100可以与高性能的x86 CPU和SmartNIC/DPU(数据处理单元)相连,特别设计用于与NVIDIA BlueField-3 DPU无缝连接,支持400 Gb/s以太网或NDR 400 Gb/s InfiniBand网络加速,以实现安全的HPC和AI工作负载。
原生PCIe原子操作支持:H100增加了对32位和64位数据类型原生PCIe原子操作的支持,如原子CAS、原子交换和原子fetch add,加速了CPU与GPU间的同步和原子操作。同时支持单根I/O虚拟化(SR-IOV)和跨NVLink的虚拟功能(VF)或物理功能(PF)访问,允许单个PCIe连接的GPU在多个进程或虚拟机(VM)间共享和虚拟化。
安全性和保密计算强化:H100引入多项安全特性,限制对GPU内容的访问,确保只有授权实体可以访问,提供安全启动和证明能力,并在系统运行时主动监控防范攻击。配备片上安全处理器、多种加密类型支持、硬件保护内存区域、特权访问控制寄存器、片上传感器等,为客户提供安全的GPU处理环境。
保密计算能力:H100是世界上首款具备保密计算能力的GPU,使用户能够在利用H100 GPU前所未有的加速能力的同时,保护其数据和应用程序的机密性和完整性。它还提供了一系列其他安全特性,以保护用户数据,防御软硬件攻击,并在虚拟化和MIG环境中更好地隔离和保护VM。
综上所述,NVIDIA H100 GPU不仅在性能和互连性方面实现了显著提升,还显著增强了安全性与保密计算能力,为处理敏感数据和执行要求严苛的工作负载提供了强大的基础设施支持。####NVIDIA H100 GPU的特性包括:
MIG技术支持的多租户隔离与安全计算:H100 GPU可被分区,并利用MIG(Multi-Instance GPU)技术支持多个虚拟机,实现多租户环境下的保密计算。这使得GPU加速的应用程序能在可信执行环境(TEE)内无需手动分区就能运行。
硬件根源信任与软件组合:用户能够结合NVIDIA强大的AI和高性能计算(HPC)软件套件,以及NVIDIA保密计算提供的硬件根源信任,确保在最低GPU架构级别上的安全性与数据保护。在共享或远程基础设施上运行并验证应用程序时,任何未经授权的实体,包括管理程序、主机操作系统、系统管理员、基础设施所有者或物理访问者,都无法查看或修改在TEE中使用中的应用程序代码和数据。
促进安全协作的保密联邦学习:H100的保密计算能力进一步加强了联邦学习等多方合作计算场景的安全性。联邦学习允许多个组织共同训练或评估AI模型,而无需分享各自的专有数据集。H100确保数据和AI模型受到内外部威胁的未经授权访问保护,每个参与站点都能验证其伙伴运行的软件,增强了安全协作的信心,推动医疗研究、药物开发、保险和金融欺诈预防等领域的发展,同时保持安全、隐私和法规遵从性。
安全与测量启动:H100实现了安全启动和测量启动机制,这是提供保密计算功能的关键之一。安全启动确保GPU从已知安全状态启动,仅运行经NVIDIA认证的固件和微码;测量启动则收集并报告启动过程的特征,以确定GPU的安全状态,并通过验证确保设备处于预期的安全状态。
全VM与GPU TEE隔离:通过强大的硬件安全措施,如片上根源信任(RoT)、设备验证及AES-GCM 256位加密,H100提供了全面的VM与GPU TEE隔离,形成一个保密计算环境。其中,AES-GCM 256保证了CPU与GPU间PCIe总线数据传输的机密性和完整性,且加密实施符合FIPS 140-3二级标准。
视频解码性能提升:相比A100,H100在视频解码能力上有显著提高,集成七个NVDEC单元(A100为五个),提升了高清视频流的解码吞吐量,有助于在深度学习平台中平衡视频解码性能与训练、推理性能。
硬件加速JPEG解码:H100包含七个单核NVJPG引擎,对比A100的一个五核引擎,大大提升了JPEG解码性能,简化了软件使用模型,并在不同分辨率图像批次处理中提高了吞吐量,尤其在MIG操作模式下,每个MIG分区至少分配到一个NVJPG引擎。
这些特性展示了H100 GPU在增强安全性、保密性、计算效率以及媒体处理能力方面的重大进步,特别适合于需要高度安全和高性能计算的场景。
NVIDIA DGX H100 是一款专为最大化人工智能(AI)吞吐量设计的高性能系统,旨在帮助企业实现从自然语言处理、推荐系统、数据分析等多个领域的突破。以下是H100相关的关键特性:
NVIDIA H100 Tensor Core GPU:DGX H100的核心是革命性的H100 Tensor Core GPU,提供了前所未有的计算能力,单个系统即可提供32 petaFLOP的性能。
第4代Tensor Core与NVLink技术:H100 GPU采用第四代Tensor Core和NVLink技术,相比上一代,通信带宽提升1.5倍,比PCIe Gen5快至多7倍,GPU间总吞吐量可达7.2 TB/秒,相比前代产品提高了近1.5倍。
第3代NVSwitch:通过四个第三代NVSwitch进行GPU间的高速互联,支持大规模并行计算和数据交换。
云原生就绪与Bluefield-3 DPU:DGX H100支持Bluefield-3数据处理单元(DPU),可加速存储、安全和网络管理功能,同时转换传统计算环境为安全且加速的虚拟私有云,实现多租户环境下的应用负载运行。
先进的网络连接:配备8个ConnectX-7适配器,每个提供400Gb/s的InfiniBand或以太网连接,以及两个BlueField-3 DPUs,确保了大规模AI工作负载所需的高速数据传输能力。
扩展性和灵活性:作为构建大型AI集群(如NVIDIA DGX SuperPOD)的基础模块,DGX H100可通过多系统集群轻松扩展,以应对最复杂的人工智能应用挑战。
系统配置:包括8个H100 GPU,每个配备80GB内存,以及1TB基础内存,可扩展至2TB;提供大容量的数据缓存驱动器,并支持高速OS驱动器。
全面的CUDA平台支持:NVIDIA CUDA平台为DGX H100提供了高性能库、框架及通信库,加速计算从系统软件到应用特定库和框架的所有层面,支持深度学习、机器学习、数据科学、高性能计算等众多领域,通过广泛的SDK帮助开发者在多个应用领域高效开发。
综上所述,NVIDIA DGX H100是一个高度集成、优化并面向未来的AI平台,凭借其强大的计算能力、高效的互联技术和全面的软件生态系统,为推动企业级AI创新与优化提供了坚实的基础。
NVIDIA H100显卡具备以下特性:
DPX指令集:H100引入了新的DPX指令,这是一组专门的硬件指令,用于加速动态规划算法,如在DNA基因测序中使用的Smith-Waterman算法,以及蛋白质分类和折叠。与上一代NVIDIA Ampere A100 GPU相比,H100在Smith-Waterman算法上的运行速度提高了7倍,从而在疾病诊断、病毒突变研究及疫苗开发等领域大大缩短了解决方案的时间。
加速基因组学应用:H100在加速基因组学分析方面表现出色,特别是在数据密集型步骤上,如将原始仪器数据转化为生物学洞察所需的各种复杂算法和应用,包括深度学习和自然语言处理。它支持大规模数据集的快速处理,使个体基因组的分析时间从数小时或数天缩短至几分钟。
支持高性能计算(HPC)和人工智能(AI)融合:虽然文章没有直接提及,但作为NVIDIA高端产品线的一员,H100显卡设计于支持高带宽、低延迟的计算环境,适合于要求极高的HPC和AI融合应用,这在基因组学数据分析等科学领域尤为重要。
与NVIDIA生态系统整合:H100能够与NVIDIA的软件栈紧密集成,包括CUDA平台、NVIDIA HPC SDK、NVIDIA Clara Parabricks等,这些工具和框架为用户提供了一个统一且优化的开发环境,便于利用GPU进行加速计算。
综上所述,NVIDIA H100显卡在基因组加速方面展现出了显著的性能提升,特别是在动态规划算法执行上,通过新引入的DPX指令集大幅提升了处理速度,对于推动医疗健康、农业及生命科学等领域的研究具有重要意义。同时,结合NVIDIA的软件生态系统,H100在促进数据密集型科学应用的加速发展方面发挥着关键作用。
H100 相关特性:
DPX指令集优化:H100引入了新的DPX指令,这些指令专门针对一系列计算进行了优化,包括动态规划(Dynamic Programming,DP)中的操作,如加法、减法以及寻找最大值等。这对于加速Smith-Waterman算法这类依赖于矩阵更新和最佳匹配搜索的基因组测序算法特别有效。
灵活的硬件架构:H100的硬件设计旨在支持模式匹配算法的灵活性需求,能够适应基因组拼接过程中的插入、编辑或删除序列操作,并且能够指定不同类型的错配成本。这种灵活性不仅适用于DNA测序,也适用于蛋白质测序等其他基因组学问题。
GPU加速计算框架集成:H100被集成到NVIDIA的CLARA Parabricks加速计算框架中,通过GPU加速的BWA-ME模块来运行Smith-Waterman算法,显著提高了DNA测序的效率和速度。这表明H100在生物信息学应用中,特别是大规模数据处理和分析方面,具有高性能和高吞吐量的优势。
综上所述,H100 GPU通过其优化的DPX指令集、灵活的硬件架构设计以及与高性能计算框架的深度集成,为基因组测序和其他生物信息学任务提供了强大的加速能力,特别是在处理复杂的序列比对和模式匹配算法时表现出色。