AIGC专栏12——EasyAnimateV3发布详解 支持图&文生视频 最大支持960x960x144帧视频生成
学习前言
研究了好长时间的文生视频,EasyAnimate到了V3版本,我们将vae修改从MagVIT替换成了Slice VAE,同时支持图生视频,扩大了生成的分辨率。
现在EasyAnimate支持 图 和 文 生视频 同时最大支持960x960 144帧的视频生成,FPS为24,另外通过图生视频的能力,我们还可以进行视频续写,生成无限长视频。
本文主要进行EasyAnimateV3的算法详解,并且介绍一下EasyAnimateV3的使用。

项目特点
- 支持 图 和 文 生视频;
- 支持 首尾图 生成视频
- 最大支持720p 144帧视频生成;
- 最低支持12G显存使用(3060 12G可用);
- 无限长视频生成;
- 数据处理到训练完整pipeline代码开源。
生成效果
EasyAnimateV3的生成效果如下,分别支持图生视频和文生视频。
通过图生视频的能力,我们还可以进行视频续写,生成无限长视频。

下面是一些比较好,有意思的生成结果,通过图生视频实现。
人像:





动物:





火焰:



水:




名画:




其它:




相关地址汇总
项目主页
https://easyanimate.github.io/
Huggingface体验地址
https://modelscope.cn/studios/PAI/EasyAnimate/summary
Modelscope体验地址
https://huggingface.co/spaces/alibaba-pai/EasyAnimate
源码下载地址
https://github.com/aigc-apps/EasyAnimate
感谢大家的关注。
EasyAnimate V3详解
技术储备
Diffusion Transformer (DiT)
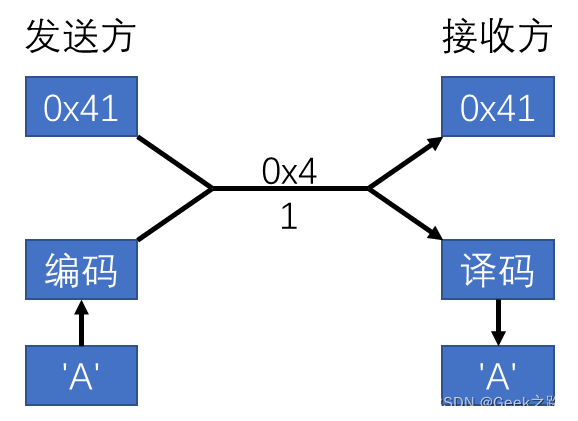
DiT基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
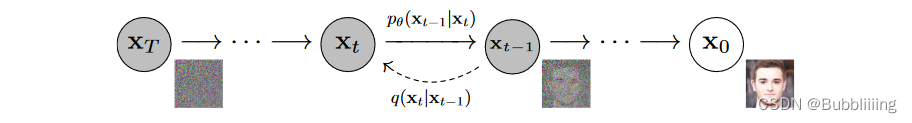
DiT相比于DDPM,使用了更快的采样器,也使用了更大的分辨率,与Stable Diffusion一样使用了隐空间的扩散,但可能更偏研究性质一些,没有使用非常大的数据集进行预训练,只使用了imagenet进行预训练。
与Stable Diffusion不同的是,DiT的网络结构完全由Transformer组成,没有Unet中大量的上下采样,结构更为简单清晰。
在EasyAnimateV3中,我们设计了一个独特的混合Motion Module加入到DiT中,在Motion Module中引入了全局信息,借助DIT的强大生成能力进行视频生成。
Hybrid Motion Module
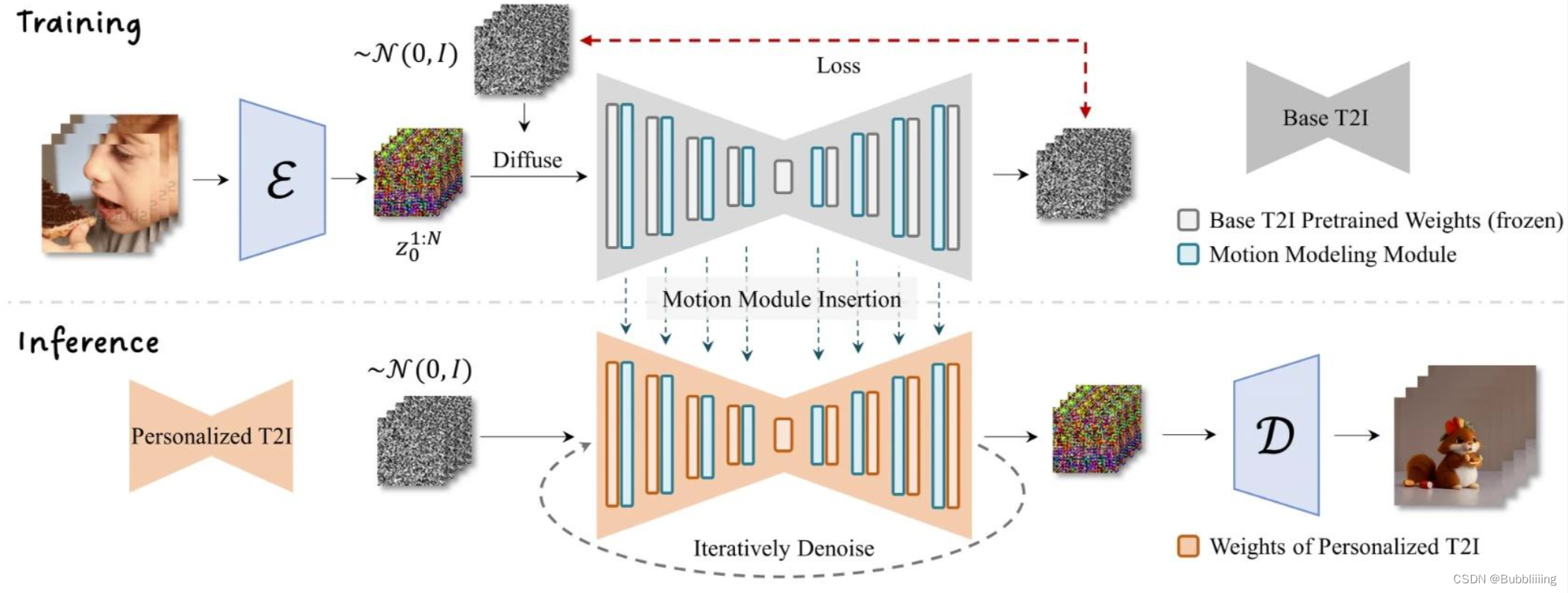
AnimateDiff是一个可以对文生图模型进行动画处理的实用框架,其内部设计的Motion Module无需进行特定模型调整,即可一次性为大多数现有的个性化文本转图像模型提供动画化能力。
EasyAnimate参考AnimateDiff使用Motion Module保证视频的连续性。原始的Motion Module只关注特征点在时间轴上的特征信息,以提炼出合理的运动先验,在AnimateDiff中只更新了运动模块的参数,所以Motion Module是一个可插入的结构,可以用在不同的微调backbone中。
相比于原始的Motion Module,我们引入了全局Attention信息,提出了Hybrid Motion Module,Hybrid Motion Module在偶数层上只关注时间轴上的特征信息,在奇数层上关注全局信息。通过奇偶不同的处理方法,既实现了计算量的缩减,也提高了全局的信息感受能力。
在EasyAnimate中,为了更好的生成效果,我们将Backbone连同Motion Module一起Finetune,同时联合图片和视频一起Finetune。在一个Pipeline中即实现了图片的生成,也实现了视频的生成。
U-VIT

在训练过程中,我们发现纯DIT结构在训练视频时不算稳定,经常存在损失突然上升的情况,并且由于视频的特征层较大,拟合速度较慢。
参考U-vit,我们将跳连接结构引入到EasyAnimate当中,通过引入浅层特征进一步优化深层特征,并且我们0初始化了一个全连接层给每一个跳连接结构,使其可以作为一个可插入模块应用到之前已经训练的还不错的DIT中。
Lora
由《LoRA: Low-Rank Adaptation of Large Language Models》 提出的一种基于低秩矩阵的对大参数模型进行少量参数微调训练的方法,广泛引用在各种大模型的下游使用中。
EasyAnimate有良好的拓展性,我们可以对文生图模型训练Lora后应用到文生视频模型中。
算法细节
算法组成
我们使用了PixArt-alpha作为基础模型,并在此基础上引入额外的混合运动模块(Hybrid Motion Module)结合时间轴信息和全局信息进行视频的生成。
EasyAnimateV3包括Text Encoder、Slice VAE(用于作为视频编码器和视频解码器)和 视频Diffusion Transformer(基于Hybrid Motion Module的DiT)。T5 Encoder用作文本编码器。整体架构图如下:

Slice VAE
在早期的研究中,基于图像的VAE已被广泛用于视频帧的编码和解码,如AnimateDiff、ModelScopeT2V和OpenSora。在Stable Dif fusion使用VAE实现将每个视频帧编码为单独的潜在特征,从而将帧的空间维度显著缩小到宽度和高度的八分之一。但这种编码技术忽略了时间信息,将视频降级为静态图像表示。
传统的基于图像的VAE的一个显著问题是它无法在时间维度上进行压缩,这不仅无法关注到细微的帧间信息,并且导致潜在的latent的shape很大,进一步导致GPU VRAM的激增。这些挑战严重阻碍了这种方法在长视频创作中的实用性。因此,视频VAE的挑战在于如何有效地压缩时间维度。
此外,我们的同时需要使用图像和视频对VAE进行训练。先前的研究表明,将图像集成到视频训练Pipeline中可以更有效地优化模型架构,从而改进其文本对齐并提高输出质量。
在EasyAnimateV2中,我们采取了MagViT作为视频VAE。它采用Casual 3D Conv。在使用普通3D Conv之前,该块在时间轴前引入填充,从而确保每一帧可以利用它先前的信息来增强因果关系,同时不考虑到后帧的影响。但由于GPU VRAM的限制。当视频增大时,MagViT所需的内存往往甚至超过A100 GPU的可用内存,这个问题突出了分批处理的必要性,它有助于增量解码,而不是试图一步解码整个序列**。分批处理两种方式如下:

但MagViT并不适合进行时间轴上的分批处理,因为MagViT的独特机制,3D Conv前需要进行前向填充,对应的潜在latent中,每个部分的第一个latent由于填充特征仅包含较少的信息。这种不均匀的信息分布是一个可能阻碍模型优化的方面。此外,MagViT使用这种批处理策略还影响处理过程中视频的压缩率。
这促使我们在EasyAnimateV3中引入Slice VAE,该VAE在面临不同输入时使用不同的处理策略,当输入的是视频帧时,则在高宽与时间轴上进行压缩,当输入为512x512x8的视频帧时,将其压缩为64x64x2的潜在latent;当输入的是图片时,则仅仅在高宽上进行压缩,当输入为512x512的图片时,将其压缩为64x64x1的潜在latent。

为了进一步提高解码的性能,我们在不同的时间轴批次之间实现特征共享,如图中所示。在解码过程中,特征与它们的前一个和后一个特征相连,从而产生更一致的特征并实现比MagViT更高的压缩率。通过这种方式,编码的特征封装了时间信息,这反过来又节省了计算资源,同时提高了生成结果的质量。
Hybrid Motion Module
我们设计了一个独特的运动模块,命名为Hybrid Motion Module,混合运动模块专门设计用于嵌入时间信息并引入全局信息。
通过我们在偶数层上,在时间维度上集成注意力机制,使得模型获得了时间轴上的先验知识,而在奇数层上,我们在全局序列中进行全局注意力,提高模型的全局感受野。如下图(b)所示。

图生视频技术路线

图生视频记录路线如上图所示,我们提供双流的信息注入:
- 需要重建的部分和重建的参考图分别通过VAE进行编码,上图黑色的部分代表需要重建的部分,白色的部分代表首图,然后和随机初始化的latent进行concat,假设我们期待生成一个384x672x144的视频,此时的初始latent就是4x36x48x84,需要重建的部分和重建的参考图编码后也是4x36x48x84,三个向量concat到一起后便是12x36x48x84,传入DiT模型中进行噪声预测。
- 在文本侧,我们使用CLIP Image对输入图片Encoder之后,使用一个Proj进行映射,然后将结果与T5编码后的文本进行concat,然后在DiT中进行Cross Attention。
通过图生视频的能力,我们还可以通过上一段视频的尾帧进行视频续写,生成无限长视频。
项目使用
项目启动
推荐在docker中使用EasyAnimateV3:
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
wget https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar -O models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512.tar
cd models/Diffusion_Transformer/
tar -xvf EasyAnimateV3-XL-2-InP-512x512.tar
cd ../../
python app.py
到这里已经可以打开gradio网站了。
文生视频
首先进入gradio网站:

选择对应的预训练模型,如"models/Diffusion_Transformer/EasyAnimateV3-XL-2-InP-512x512"。
然后在下方填写提示词。

然后调整视频高宽和生成帧数,最后进行生成;
- 512x512模型常用生成高宽为384x672。
- 768x768模型常用生成高宽为576x1008。
- 960x960模型常用生成高宽为720x1248。

图生视频
图生视频与文生视频有两个不同点:
- 1、需要指定参考图;
- 2、指定与参考图类似的高宽;
EasyAnimateV3的ui已经提供了自适应的按钮Resize to the Start Image,打开后可以自动根据输入的首图调整高宽。

超长视频生成
EasyAnimateV3支持超长视频生成,通过图生视频的能力,我们还可以进行视频尾帧续写,生成无限长视频。