目录
- 1、前言
- 2、相关方案推荐
- 3、详细设计方案
- 4、工程源码1详解-->PHY芯片以太网输出方案
- 5、工程源码2详解-->1G/2.5G Ethernet PCS/PMA or SGMII以太网输出方案
- 6、工程源码3详解-->AXI 1G/2.5G Ethernet Subsystem以太网输出方案
- 7、工程移植说明
- 8、上板调试验证
- 9、福利:工程代码的获取
Zynq系列FPGA实现SDI视频编解码+UDP以太网传输,基于GTX高速接口,提供3套工程源码和技术支持
1、前言
目前FPGA实现SDI视频编解码有两种方案:一是使用专用编解码芯片,比如典型的接收器GS2971,发送器GS2972,优点是简单,比如GS2971接收器直接将SDI解码为并行的YCrCb422,GS2972发送器直接将并行的YCrCb422编码为SDI视频,缺点是成本较高,可以百度一下GS2971和GS2972的价格;另一种方案是使用FPGA逻辑资源部实现SDI编解码,利用Xilinx系列FPGA的GTP/GTX资源实现解串,利用Xilinx系列FPGA的SMPTE SDI资源实现SDI编解码,优点是合理利用了FPGA资源,GTP/GTX资源不用白不用,缺点是操作难度大一些,对FPGA开发者的技术水平要求较高。有意思的是,这两种方案在本博这里都有对应的解决方案,包括硬件的FPGA开发板、工程源码等等。
工程概述
本设计基于Zynq系列的Zynq7100 FPGA开发板实现SDI视频编解码+图像缩放+UDP以太网传输,输入源为一个3G-SDI相机或者HDMI转3G-SDI盒子,也可以使用HD-SDI或者SD-SDI相机,因为本设计是三种SDI视频自适应的;同轴的SDI视频通过同轴线连接到FPGA开发板的BNC座子,然后同轴视频经过板载的Gv8601a芯片实现单端转差分和均衡EQ的功能;然后差分SDI视频信号进入FPGA内部的GTX高速资源,实现数据高速串行到并行的转换,本博称之为解串;解串后的并行视频再送入Xilinx系列FPGA特有的SMPTE SD/HD/3G SDI IP核,进行SDI视频解码操作并输出BT1120视频,至此,SDI视频解码操作已经完成,可以进行常规的图像处理操作了;
本设计的目的是做图像缩放后再以UDP以太网输出解码的SDI视频,针对目前市面上的主流项目需求,本博设计了三种以太网输出方式,第一种是基于传统PHY芯片(RTL8211E)输出,第一种是基于Xilinx官方的1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC架构输出,第一种是基于Xilinx官方的AXI 1G/2.5G Ethernet Subsystem架构输出;首先对解码BT1120视频进行转RGB和图像缓存操作和图像缩放操作;图像缩放方案采用纯verilog方案将输入的1920x1080视频缩放为1280x720;再使用BT1120转RGB模块实现视频格式转换;再使用本博常用的FDMA图像缓存架构实现图像3帧缓存,缓存介质为板载的PS端DDR3;图像从DDR3读出后,进入UDP视频发送模块,对视频进行自定义协议编码;然后送入UDP协议栈进行UDP以太网帧格式编码;然后输出给MAC层,再输出给物理层,最后通过网线输出给PC上位机;PC端上位机(QT)接收网络视频并显示图像;本博客提供3套工程源码,具体如下:
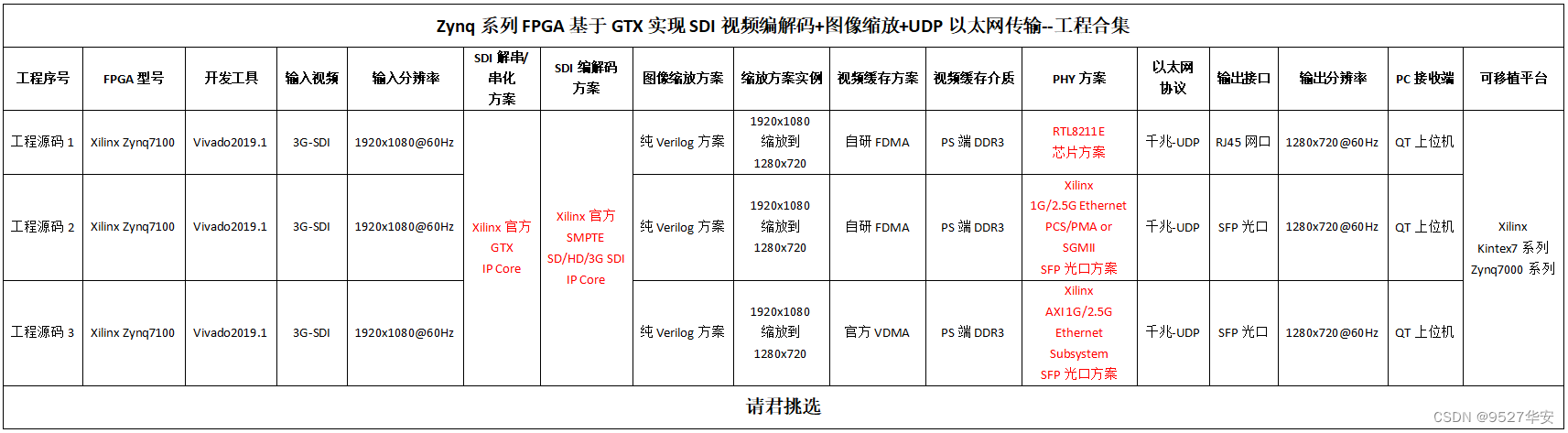
现对上述3套工程源码做如下解释,方便读者理解:
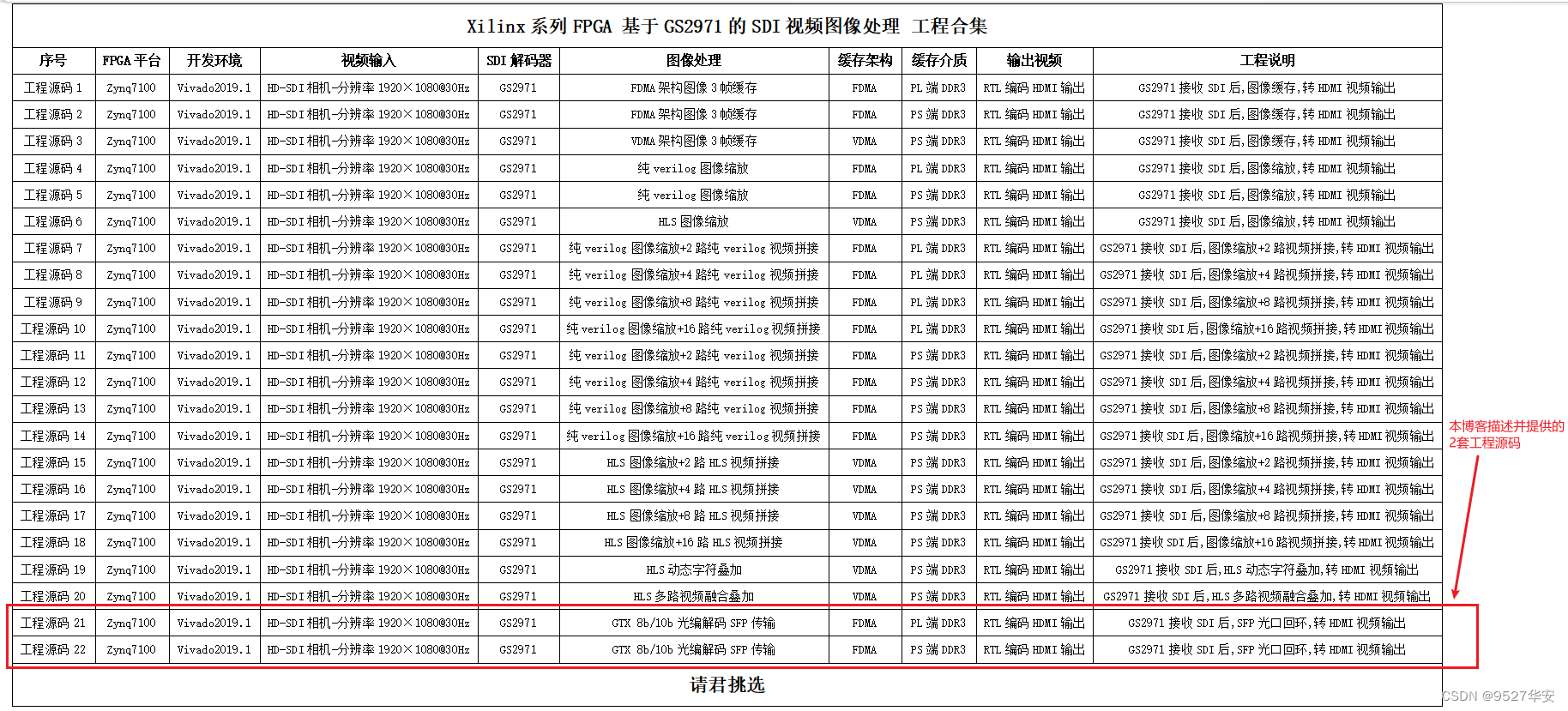
工程源码1
开发板FPGA型号为Xilinx–>Xilinx-Zynq7100–xc7z100ffg900-2;输入视频为3G-SDI相机或者HDMI转3G-SDI盒子,输入分辨率为1920x1080@60Hz,输入视频经过板载的Gv8601a芯片实现单端转差分和均衡EQ后送入FPGA;再经过GTX将SDI视频解串为并行数据;再经过SMPTE SDI IP核将SDI解码BT1120数据;再经过BT1120转RGB模块将BT1120转换为RGB888视频;再经过自研的纯verilog实现的、支持任意比例缩放的图像缩放模块,将输入视频由1920x1080缩放为1280x720;再经过自研的FDMA图像缓存方案将视频写入PS侧DDR3做三帧缓存;再经过UDP视频发送模块,对视频进行自定义协议编码;再经过UDP协议栈进行UDP以太网帧格式编码;再经过Xilinx官方的Tri Mode Ethernet MAC实现MAC数据发送,输出RGMII接口数据;再经过板载的RTL8211E芯片后以RJ45网口输出;PC端运行QT上位机实时接收视频数据并显示出来;该工程运行Zynq软核;适用于SDI转网络(PHY芯片方案)输出场景;
工程源码2
开发板FPGA型号为Xilinx–>Xilinx-Zynq7100–xc7z100ffg900-2;输入视频为3G-SDI相机或者HDMI转3G-SDI盒子,输入分辨率为1920x1080@60Hz,输入视频经过板载的Gv8601a芯片实现单端转差分和均衡EQ后送入FPGA;经过GTX将SDI视频解串为并行数据;再经过SMPTE SDI IP核将SDI解码BT1120数据;再经过BT1120转RGB模块将BT1120转换为RGB888视频;再经过自研的纯verilog实现的、支持任意比例缩放的图像缩放模块,将输入视频由1920x1080缩放为1280x720;再经过自研的FDMA图像缓存方案将视频写入PS侧DDR3做三帧缓存;再经过UDP视频发送模块,对视频进行自定义协议编码;再经过UDP协议栈进行UDP以太网帧格式编码;再经过Xilinx官方的1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC架构实现MAC数据发送,输出到板载的SFP光口;再经过SFP光口转网口(电口)后以网线输出;PC端运行QT上位机实时接收视频数据并显示出来;该工程运行Zynq软核;适用于SDI转网络(光口方案)输出场景;
工程源码3
开发板FPGA型号为Xilinx–>Xilinx-Zynq7100–xc7z100ffg900-2;输入视频为3G-SDI相机或者HDMI转3G-SDI盒子,输入分辨率为1920x1080@60Hz,输入视频经过板载的Gv8601a芯片实现单端转差分和均衡EQ后送入FPGA;经过GTX将SDI视频解串为并行数据;再经过SMPTE SDI IP核将SDI解码BT1120数据;再经过BT1120转RGB模块将BT1120转换为RGB888视频;再经过自研的纯verilog实现的、支持任意比例缩放的图像缩放模块,将输入视频由1920x1080缩放为1280x720;再经过自研的FDMA图像缓存方案将视频写入PS侧DDR3做三帧缓存;再经过UDP视频发送模块,对视频进行自定义协议编码;再经过UDP协议栈进行UDP以太网帧格式编码;再经过Xilinx官方的AXI 1G/2.5G Ethernet Subsystem架构实现MAC数据发送,输出到板载的SFP光口;再经过SFP光口转网口(电口)后以网线输出;PC端运行QT上位机实时接收视频数据并显示出来;该工程运行Zynq软核;适用于SDI转网络(光口方案)输出场景;
免责声明
本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。。。
2、相关方案推荐
本博已有的 SDI 编解码方案
我的博客主页开设有SDI视频专栏,里面全是FPGA编解码SDI的工程源码及博客介绍;既有基于GS2971/GS2972的SDI编解码,也有基于GTP/GTX资源的SDI编解码;既有HD-SDI、3G-SDI,也有6G-SDI、12G-SDI等;专栏地址链接如下:
点击直接前往
本博已有的以太网方案
目前我这里有大量UDP协议的工程源码,包括UDP数据回环,视频传输,AD采集传输等,也有TCP协议的工程,对网络通信有需求的兄弟可以去看看,以下是专栏地址:
直接点击前往
本博已有的FPGA图像缩放方案
我的主页目前有FPGA图像缩放专栏,改专栏收录了我目前手里已有的FPGA图像缩放方案,从实现方式分类有基于HSL实现的图像缩放、基于纯verilog代码实现的图像缩放;从应用上分为单路视频图像缩放、多路视频图像缩放、多路视频图像缩放拼接;从输入视频分类可分为OV5640摄像头视频缩放、SDI视频缩放、MIPI视频缩放等等;以下是专栏地址:
点击直接前往
1G/2.5G Ethernet PCS/PMA or SGMII架构以太网通信方案
1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC架构以太网通信方案可实现无PHY芯片的以太网通信,之前专门写过一篇博客,博客地址链接如下:
点击直接前往
AXI 1G/2.5G Ethernet Subsystem架构以太网通信方案
AXI 1G/2.5G Ethernet Subsystem架构以太网通信方案可实现无PHY芯片的以太网通信,之前专门写过一篇博客,博客地址链接如下:
点击直接前往
本方案的缩放应用
本方案有缩放版本的应用,只做SDI视频编解码,之前专门写过一篇博客,博客地址链接如下:
点击直接前往
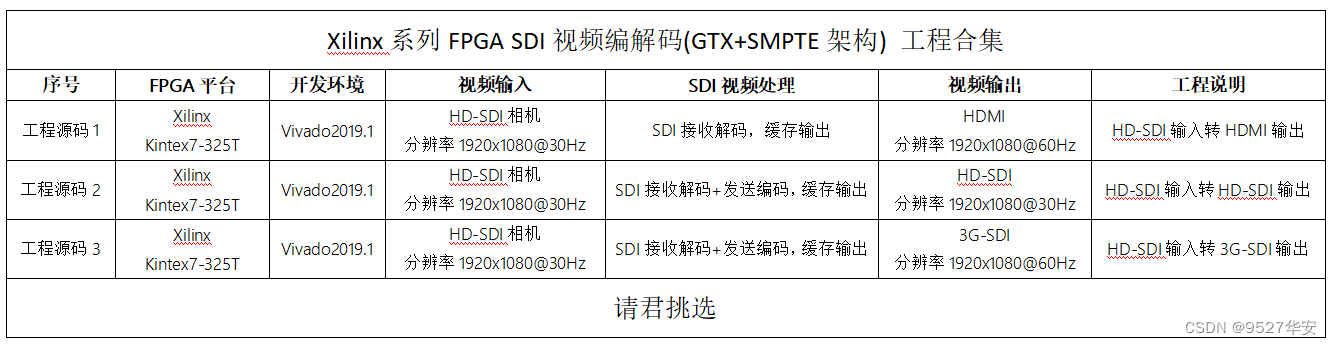
本方案在Xilinx–Kintex系列FPGA上的应用
本方案在Xilinx–Kintex系列FPGA上的也有应用,之前专门写过一篇博客,博客地址链接如下:
点击直接前往
3、详细设计方案
设计原理框图
设计原理框图如下:
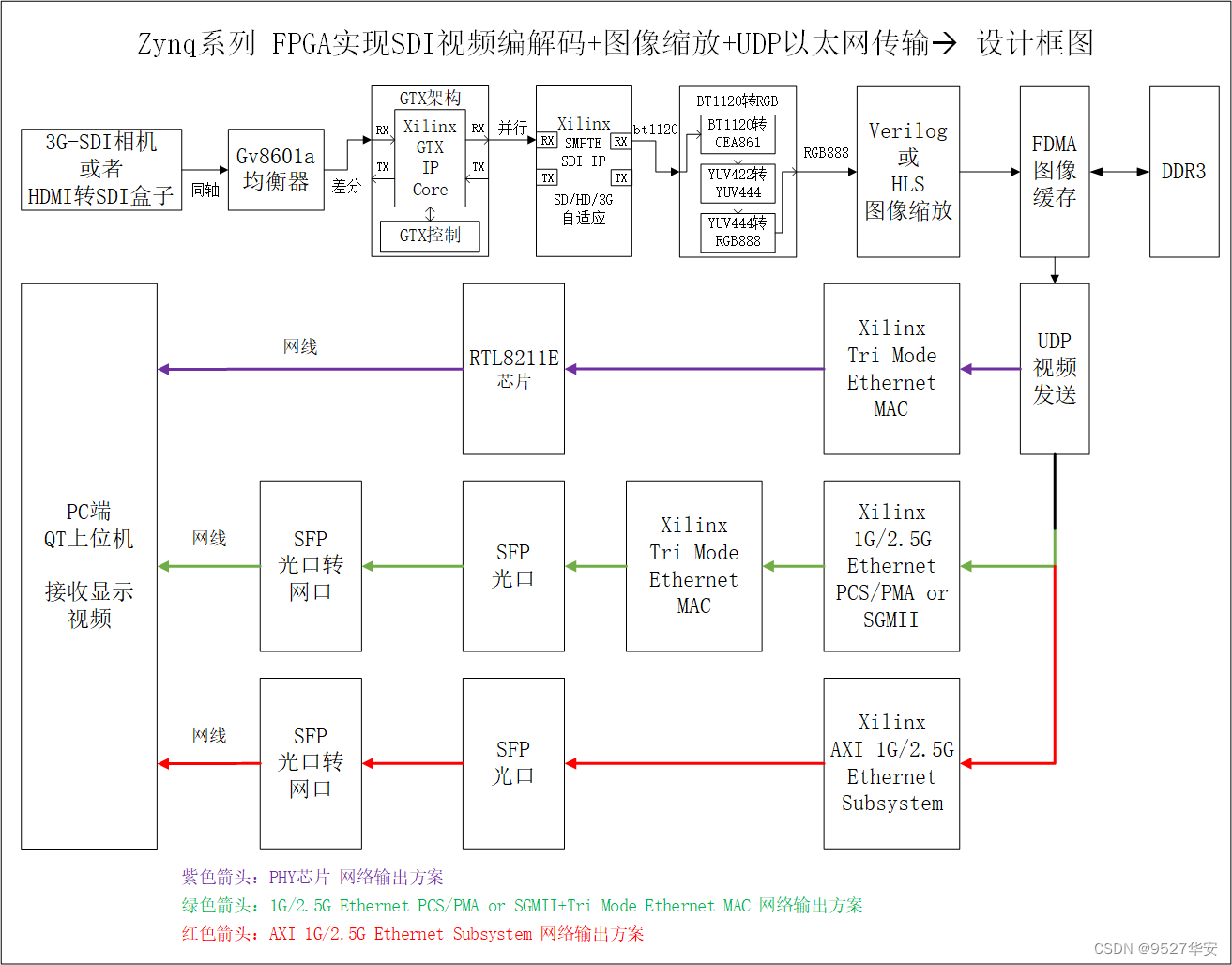
注意!!!!
注意!!!!
紫色箭头:PHY芯片的网络输出方案,需要外接PHY芯片;
绿色箭头:1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC架构的网络输出方案,不需要外接PHY芯片,由SFP光口输出;
红色箭头:AXI 1G/2.5G Ethernet Subsystem架构的网络输出方案,不需要外接PHY芯片,由SFP光口输出;
SDI 输入设备
SDI 输入设备可以是SDI相机,代码兼容HD/SD/3G-SDI三种模式;SDI相机相对比较贵,预算有限的朋友可以考虑用HDMI转SDI盒子模拟SDI相机,这种盒子某宝一百块左右;当使用HDMI转SDI盒子时,输入源可以用笔记本电脑,即用笔记本电脑通过HDMI线连接到HDMI转SDI盒子的HDMI输入接口,再用SDI线连接HDMI转SDI盒子的SDI输出接口到FPGA开发板,如下:
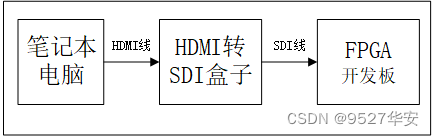
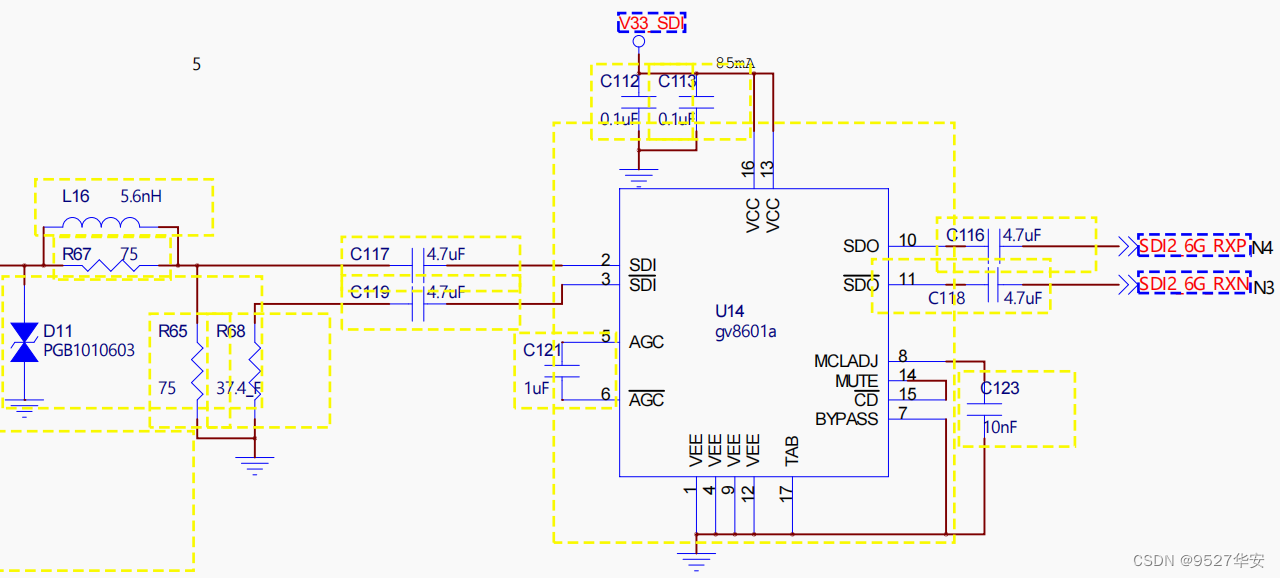
Gv8601a 均衡器
Gv8601a芯片实现单端转差分和均衡EQ的功能,这里选用Gv8601a是因为借鉴了了Xilinx官方的方案,当然也可以用其他型号器件。Gv8601a均衡器原理图如下:
GTX 解串与串化
本设计使用Xilinx特有的GTX高速信号处理资源实现SDI差分视频信号的解串与串化,对于SDI视频接收而言,GTX起到解串的作用,即将输入的高速串行的差分信号解为并行的数字信号;对于SDI视频发送而言,GTX起到串化的作用,即将输入的并行的数字信号串化为高速串行的差分信号;GTX的使用一般需要例化GTX IP核,通过vivado的UI界面进行配置,但本设计需要对SD-SDI、HD-SDI、3G-SDI视频进行自动识别和自适应处理,所以需要使得GTX具有动态改变线速率的功能,该功能可通过DRP接口配置,也可通过GTX的rate接口配置,所以不能使用vivado的UI界面进行配置,而是直接例化GTX的GTXE2_CHANNEL和GTXE2_COMMON源语直接使用GTX资源;此外,为了动态配置GTX线速率,还需要GTX控制模块,该模块参考了Xilinx的官方设计方案,具有动态监测SDI模式,动态配置DRP等功能;该方案参考了Xilinx官方的设计;GTX 解串与串化模块代码架构如下:

SMPTE SD/HD/3G SDI IP核
SMPTE SD/HD/3G SDI IP核是Xilinx系列FPGA特有的用于SDI视频编解码的IP,该IP配置使用非常简单,vivado的UI界面如下:
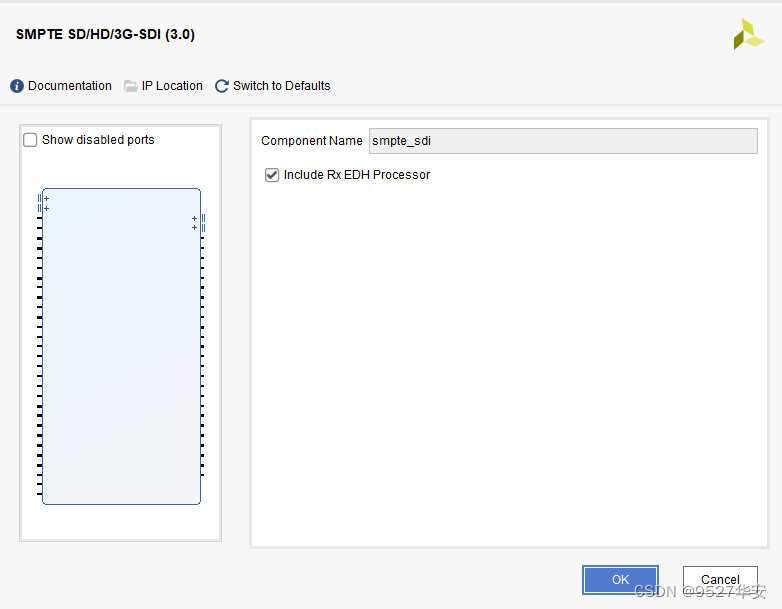
SMPTE SD/HD/3G SDI IP核必须与GTX配合才能使用,对于SDI视频接收而言,该IP接收来自于GTX的数据,然后将SDI视频解码为BT1120视频输出,对于SDI视频发送而言,该IP接收来自于用户侧的的BT1120视频数据,然后将BT1120视频编码为SDI视频输出;该方案参考了Xilinx官方的设计;SMPTE SD/HD/3G SDI IP核代码架构如下:

BT1120转RGB
BT1120转RGB模块的作用是将SMPTE SD/HD/3G SDI IP核解码输出的BT1120视频转换为RGB888视频,它由BT1120转CEA861模块、YUV422转YUV444模块、YUV444转RGB888三个模块组成,该方案参考了Xilinx官方的设计;BT1120转RGB模块代码架构如下:

纯Verilog图像缩放模块详解
工程源码1、2的图像缩放模块使用纯Verilog方案,功能框图如下,由跨时钟FIFO、插值+RAM阵列构成,跨时钟FIFO的目的是解决跨时钟域的问题,比如从低分辨率视频放大到高分辨率视频时,像素时钟必然需要变大,这是就需要异步FIFO了,插值算法和RAM阵列具体负责图像缩放算法层面的实现;
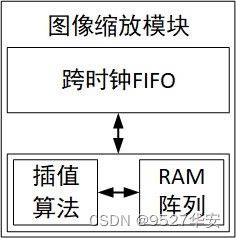
插值算法和RAM阵列以ram和fifo为核心进行数据缓存和插值实现,设计架构如下:
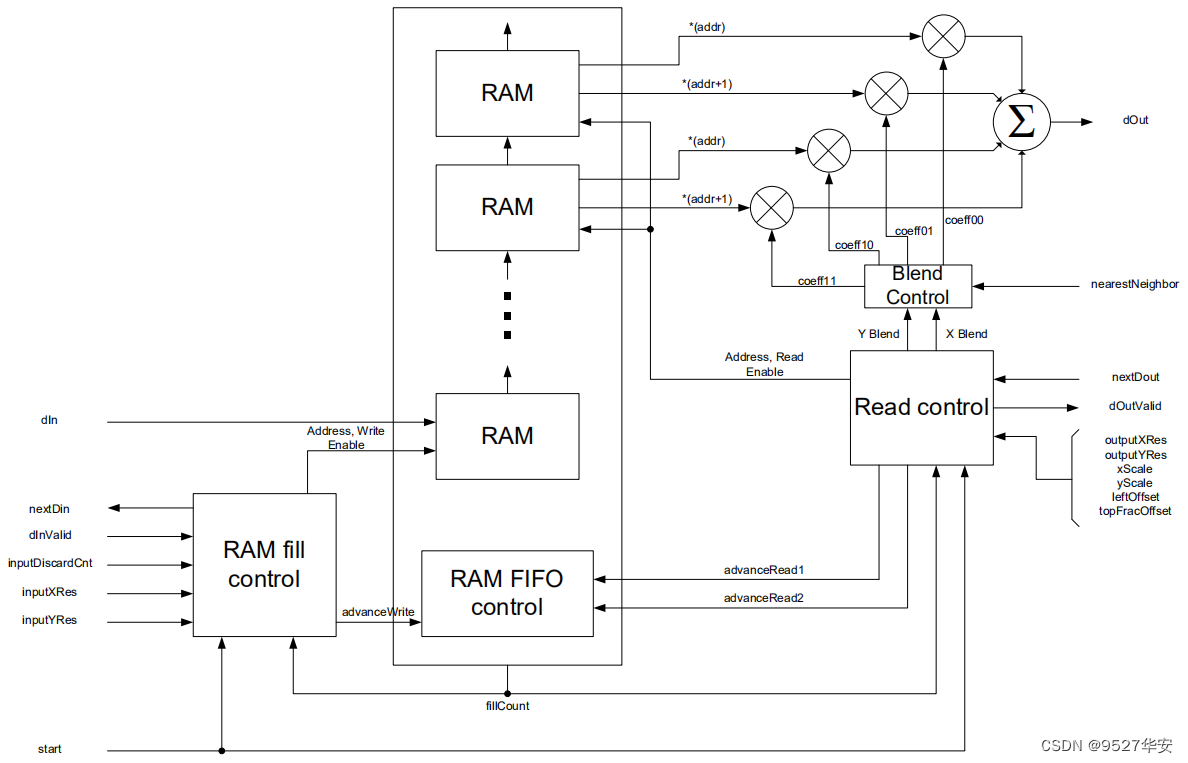
图像缩放模块代码架构如下:模块的例化请参考工程源码的顶层代码;
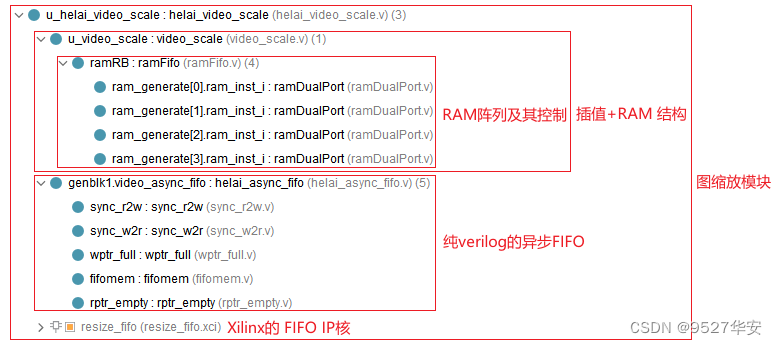
图像缩放模块FIFO的选择可以调用工程对应的vivado工具自带的FIFO IP核,也可以使用纯verilog实现的FIFO,可通过接口参数选择,图像缩放模块顶层接口如下:
module helai_video_scale #(
//---------------------------Parameters----------------------------------------
parameter FIFO_TYPE = "xilinx", // "xilinx" for xilinx-fifo ; "verilog" for verilog-fifo
parameter DATA_WIDTH = 8 , //Width of input/output data
parameter CHANNELS = 1 , //Number of channels of DATA_WIDTH, for color images
parameter INPUT_X_RES_WIDTH = 11 //Widths of input/output resolution control signals
)(
input i_reset_n , // 输入--低电平复位信号
input [INPUT_X_RES_WIDTH-1:0] i_src_video_width , // 输入视频--即缩放前视频的宽度
input [INPUT_X_RES_WIDTH-1:0] i_src_video_height, // 输入视频--即缩放前视频的高度
input [INPUT_X_RES_WIDTH-1:0] i_des_video_width , // 输出视频--即缩后前视频的宽度
input [INPUT_X_RES_WIDTH-1:0] i_des_video_height, // 输出视频--即缩后前视频的高度
input i_src_video_pclk , // 输入视频--即缩前视频的像素时钟
input i_src_video_vs , // 输入视频--即缩前视频的场同步信号,必须为高电平有效
input i_src_video_de , // 输入视频--即缩前视频的数据有效信号,必须为高电平有效
input [DATA_WIDTH*CHANNELS-1:0] i_src_video_pixel , // 输入视频--即缩前视频的像素数据
input i_des_video_pclk , // 输出视频--即缩后视频的像素时钟,一般为写入DDR缓存的时钟
output o_des_video_vs , // 输出视频--即缩后视频的场同步信号,高电平有效
output o_des_video_de , // 输出视频--即缩后视频的数据有效信号,高电平有效
output [DATA_WIDTH*CHANNELS-1:0] o_des_video_pixel // 输出视频--即缩后视频的像素数据
);
FIFO_TYPE选择原则如下:
1:总体原则,选择"xilinx"好处大于选择"verilog";
2:当你的FPGA逻辑资源不足时,请选"xilinx";
3:当你图像缩放的视频分辨率较大时,请选"xilinx";
4:当你的FPGA没有FIFO IP或者FIFO IP快用完了,请选"verilog";
5:当你向自学一下异步FIFO时,,请选"verilog";
6:不同FPGA型号对应的工程FIFO_TYPE参数不一样,但选择原则一样,具体参考代码;
2种插值算法的整合与选择
本设计将常用的双线性插值和邻域插值算法融合为一个代码中,通过输入参数选择某一种算法;
具体选择参数如下:
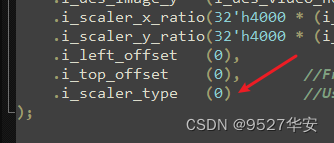
input wire i_scaler_type //0-->bilinear;1-->neighbor
通过输入i_scaler_type 的值即可选择;
输入0选择双线性插值算法;
输入1选择邻域插值算法;
代码里的配置如下:
纯Verilog图像缩放模块使用
图像缩放模块使用非常简单,顶层代码里设置了四个参数,举例如下:

上图视频通过图像缩放模块但不进行缩放操作,旨在掌握图像缩放模块的用法;如果需要将图像放大到1080P,则修改为如下:

当然,需要修改的不仅仅这一个地方,FDMA的配置也需要相应修改,详情请参考代码,但我想要证明的是,图像缩放模块使用非常简单,你都不需要知道它内部具体怎么实现的,上手就能用;
图像缓存
使用本博常用的的FDMA图像缓存架构;缓存介质为PS端DDR3;FDMA图像缓存架构由FDMA、FDMA控制器、缓存帧选择器构成;图像缓存使用Xilinx vivado的Block Design设计,如下图:
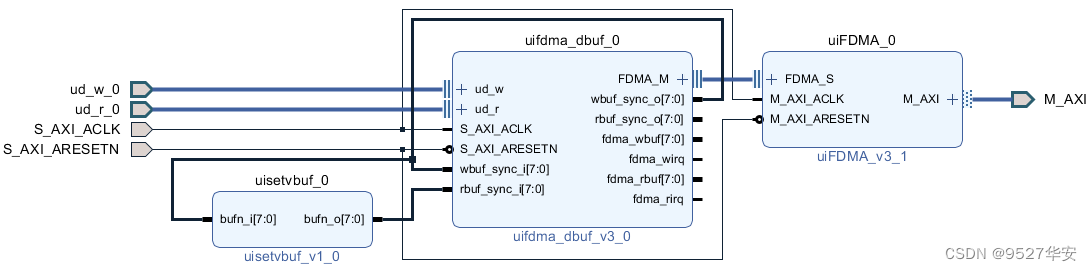
关于FDMA更详细的介绍,请参考我之前的博客,博文链接如下:
点击直接前往
需要注意的是,为了适应UDP视频传输,这里的FDMA已被我修改,和以往版本不同,具体参考代码;
UDP协议栈
本UDP协议栈使用UDP协议栈网表文件,该协议栈目前并不开源,只提供网表文件,虽看不见源码但可正常实现UDP通信,但不影响使用,该协议栈带有用户接口,使得用户无需关心复杂的UDP协议而只需关心简单的用户接口时序即可操作UDP收发,非常简单;协议栈架构如下:
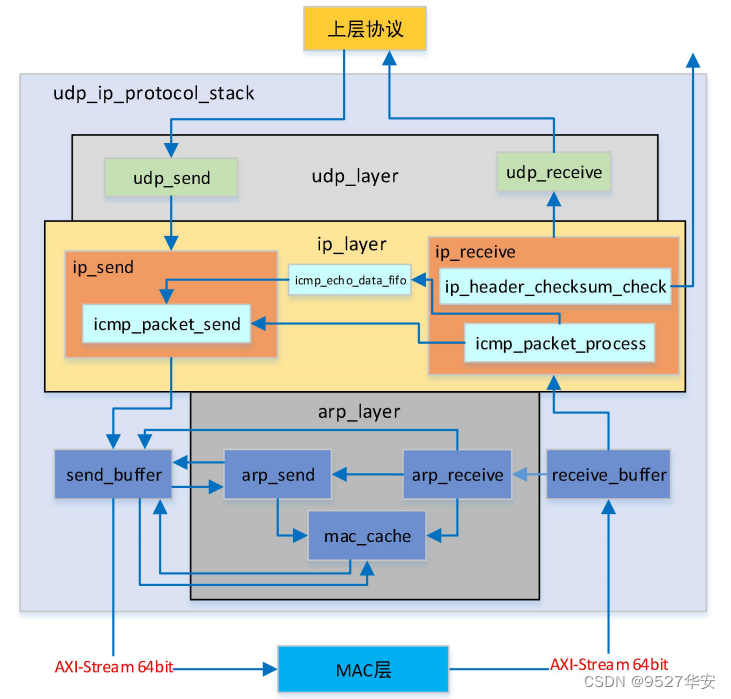
协议栈性能表现如下:
1:支持 UDP 接收校验和检验功能,暂不支持 UDP 发送校验和生成;
2:支持 IP 首部校验和的生成和校验,同时支持 ICMP 协议中的 PING 功能,可接收并响应同一个子网内部设备的 PING 请求;
3:可自动发起或响应同一个子网内设备的 ARP 请求,ARP 收发完全自适应。ARP 表可保存同一个子网内部256 个 IP 和 MAC 地址对;
4:支持 ARP 超时机制,可检测所需发送数据包的目的 IP 地址是否可达;
5:协议栈发送带宽利用率可达 93%,高发送带宽下,内部仲裁机制保证 PING 和 ARP 功能不受任何影响;
6:发送过程不会造成丢包;
7:提供64bit位宽AXI4-Stream形式的MAC接口,可与Xilinx官方的千兆以太网IP核Tri Mode Ethernet MAC,以及万兆以太网 IP 核 10 Gigabit Ethernet Subsystem、10 Gigabit Ethernet MAC 配合使用;
有了此协议栈,我们无需关心复杂的UDP协议的实现了,直接调用接口即可使用。。。
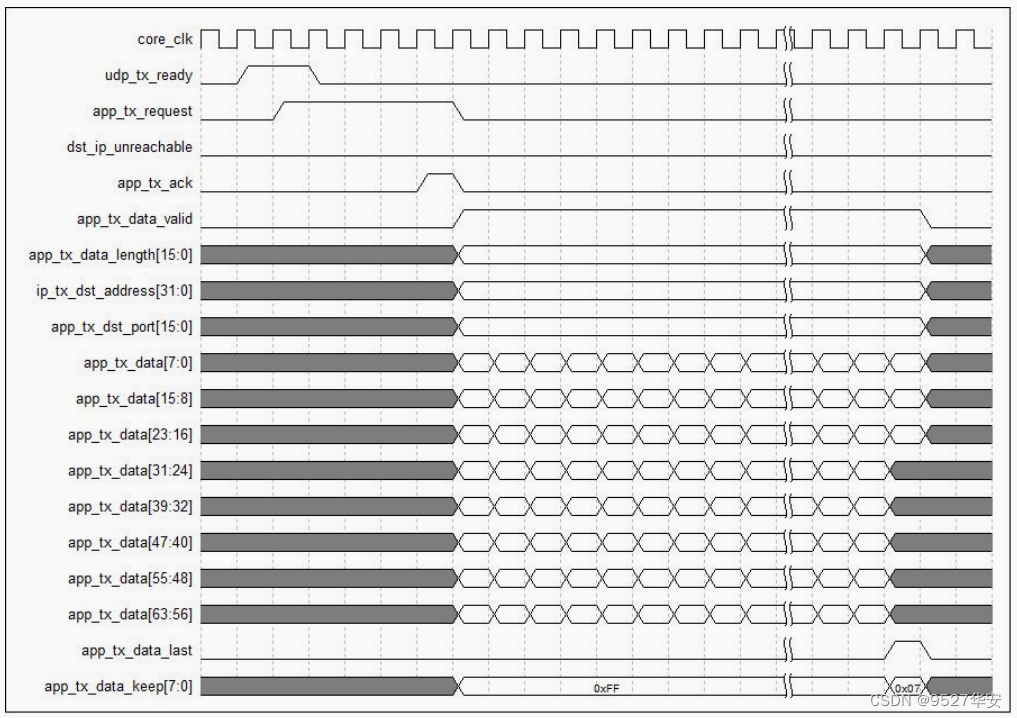
本UDP协议栈用户接口发送时序如下:
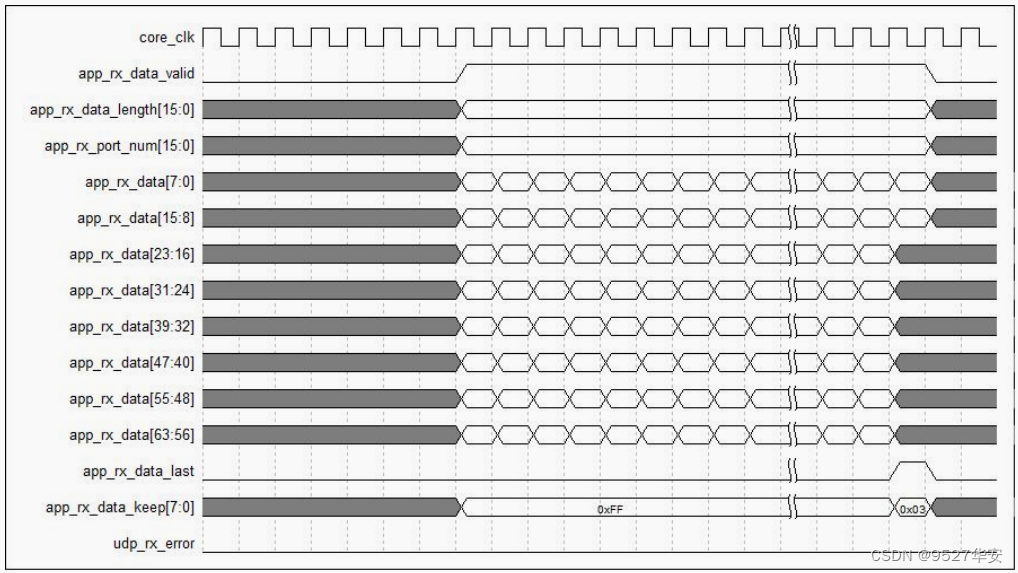
本UDP协议栈用户接口接收时序如下:
UDP视频发送
UDP视频发送实现UDP视频数据的组包,UDP数据发送必须与QT上位机的接受程序一致,上位机定义的UDP帧格式包括帧头个UDP数据,帧头定义如下:
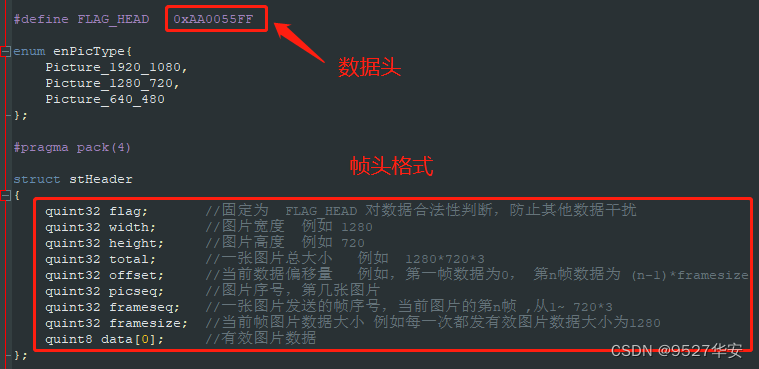
FPGA端的UDP数据组包代码必须与上图的数据帧格式对应,否则QT无法解析,代码中定义了数据组包状态机以及数据帧,如下:
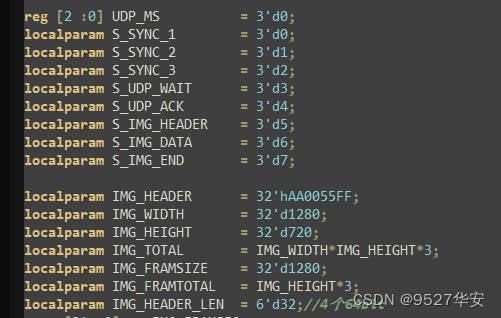
另外,由于UDP发送是64位数据位宽,而图像像素数据是24bit位宽,所以必须将UDP数据重新组合,以保证像素数据的对齐,这部分是整个工程的难点,也是所有FPGA做UDP数据传输的难点;
UDP协议栈数据发送
UDP协议栈具有发送和接收功能,但这里仅用到了发送,此部分代码架构如下:
UDP协议栈代码组我已经做好,用户可直接拿去使用;
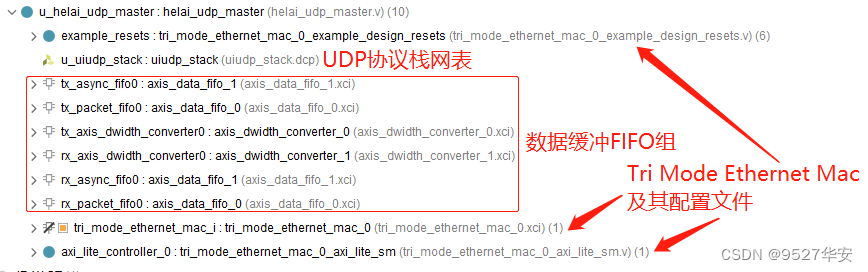
MAC数据缓冲FIFO组
这里对代码中用到的数据缓冲FIFO组做如下解释:
由于 UDP IP 协议栈的 AXI-Stream 数据接口位宽为 64bit,而 Tri Mode Ethernet MAC 的 AXI-Stream数据接口位宽为 8bit。因此,要将 UDP IP 协议栈与 Tri Mode Ethernet MAC 之间通过 AXI-Stream 接口互联,需要进行时钟域和数据位宽的转换。实现方案如下图所示:
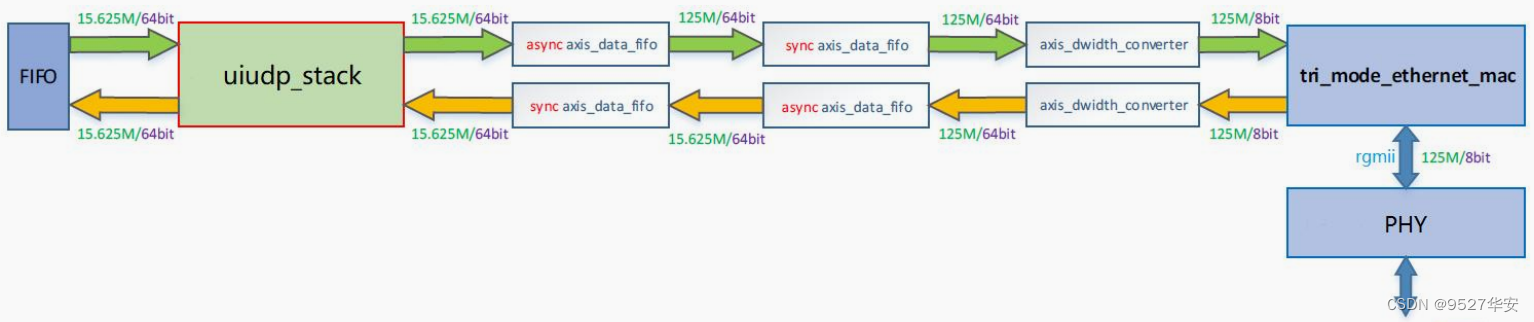
收发路径(本设计只用到了发送)都使用了2个AXI-Stream DATA FIFO,通过其中1个FIFO实现异步时钟域的转换,1个FIFO实
现数据缓冲和同步Packet mode功能;由于千兆速率下Tri Mode Ethernet MAC的AXI-Stream数据接口同步时钟信号为125MHz,此时,UDP协议栈64bit的AXI-Stream数据接口同步时钟信号应该为125MHz/(64/8)=15.625MHz,因此,异步
AXI-Stream DATA FIFO两端的时钟分别为125MHz(8bit),15.625MHz(64bit);UDP IP协议栈的AXI-Stream接口经过FIFO时钟域转换后,还需要进行数据数据位宽转换,数据位宽的转换通过AXI4-Stream Data Width Converter完成,在接收路径中,进行 8bit 到 64bit 的转换;在发送路径中,进行 64bit 到 8bit 的转换;
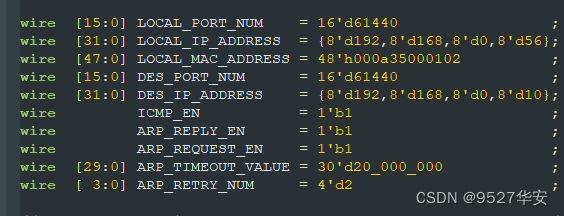
IP地址、端口号的修改
UDP协议栈留出了IP地址、端口号的修改端口供用户自由修改,位置如下:
PHY芯片–>以太网网口输出方案
PHY芯片网络输出架构以Tri Mode Ethernet MAC为核心,以PHY芯片为载体,优点是FPGA逻辑设计较为简单,缺点是硬件设计较为复杂,硬件成本会相应提高;本设计采用RTL8211E芯片,工作于延时模式,RGMII接口;关于该方案的以太网输出详细设计文档,请参考我之前的博客,博客链接如下:
直接点击前往
Tri Mode Ethernet MAC
Tri Mode Ethernet MAC主要是为了适配PHY芯片,因为后者的输入接口是GMII,而Tri Mode Ethernet MAC的输入接口是AXIS,输出接口是GMII,Tri Mode Ethernet MAC配置如下:
提供Tri Mode Ethernet MAC使用教程和移植教程,如下:

1G/2.5G Ethernet PCS/PMA or SGMII–>以太网光口输出方案
1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC网络输出架构不需要外接PHY芯片,网络数据直接通过SFP光口输出,优点是硬件设计较为简单,硬件成本会相应较低,缺点是FPGA逻辑设计较为复杂;关于该方案的以太网输出详细设计文档,请参考我之前的博客,博客链接如下:
直接点击前往
该方案需要一个SFP转网口(电口)接网线输出到PC端,可以到某宝购买该类电口,30多块钱,如下:

1G/2.5G Ethernet PCS/PMA or SGMII 简介
1G/2.5G Ethernet PCS/PMA or SGMII实现了类似于网络PHY芯片的功能,其功能框图如下:
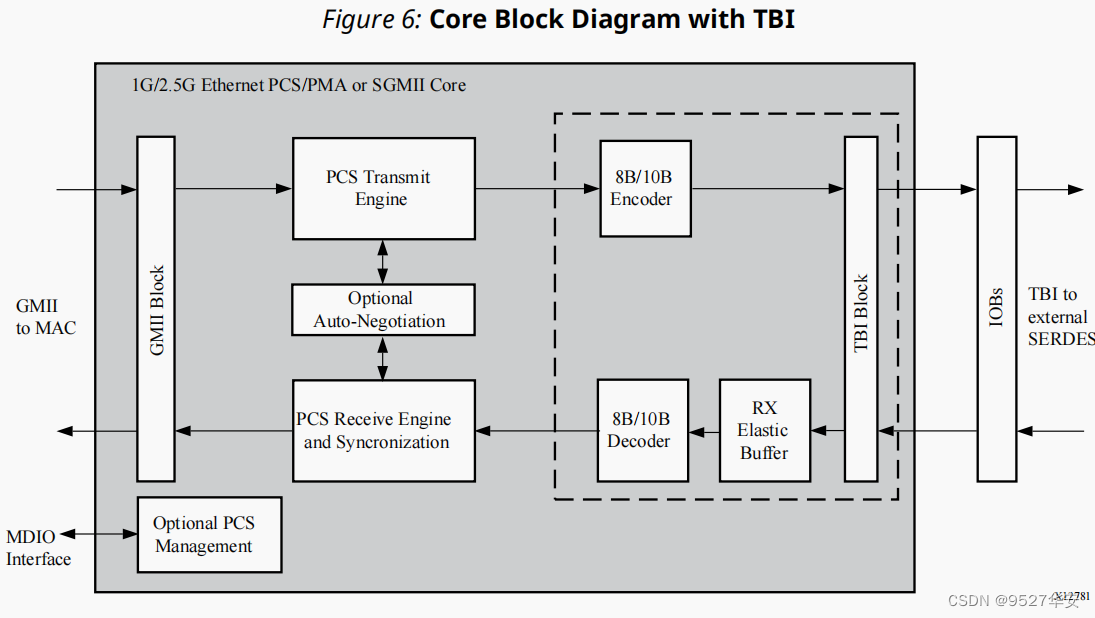
接收端:
数据首先经过GT资源解串,将串行数据解为并行数据;然后经过弹性Buffer做数据缓冲处理,主要是为了去频偏,使板与板之间的数据稳定,然后进行8b/10b解码,恢复正常数据;然后经过PCS接收同步器,对数据进行跨时钟处理,同步到GMII时序下;最后将数据放入GMII总线下输出;
发送端:
发送端则简单得多,输入时序为GMII;然后进入PCS发送引擎;然后对数据进行8b/10b编码;最后放入GT串化后输出;
1G/2.5G Ethernet PCS/PMA or SGMII 配置
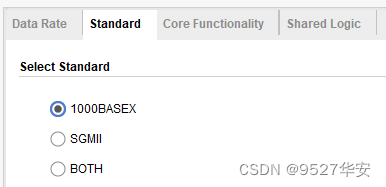
1G/2.5G Ethernet PCS/PMA or SGMII配置为1G,其与MAC的接口为GMII,配置如下:
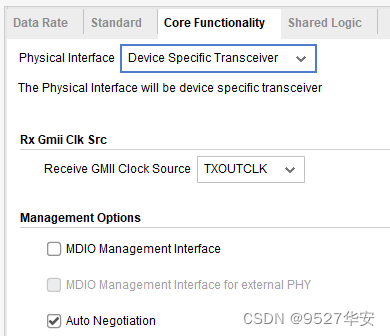
1G/2.5G Ethernet PCS/PMA or SGMII可运行于1G和2.5G线速率,对GT时钟有严格研究,按照官方数据手册,运行1G线速率时,GT差分时钟必须为125M,运行2.5G线速率时,GT差分时钟必须为312.5M,如下:

Tri Mode Ethernet MAC
Tri Mode Ethernet MAC主要是为了适配1G/2.5G Ethernet PCS/PMA or SGMII,因为后者的输入接口是GMII,而Tri Mode Ethernet MAC的输入接口是AXIS,输出接口是GMII,Tri Mode Ethernet MAC配置如下:
AXI 1G/2.5G Ethernet Subsystem–>以太网光口输出方案
AXI 1G/2.5G Ethernet Subsystem网络输出架构不需要外接PHY芯片,网络数据直接通过SFP光口输出,优点是硬件设计较为简单,硬件成本会相应较低,缺点是FPGA逻辑设计较为复杂;关于该方案的以太网输出详细设计文档,请参考我之前的博客,博客链接如下:
直接点击前往
该方案需要一个SFP转网口(电口)接网线输出到PC端,可以到某宝购买该类电口,30多块钱,如下:
AXI 1G/2.5G Ethernet Subsystem 简介
AXI 1G/2.5G Ethernet Subsystem的权威官方手册为《pg138-axi-ethernet》,请自行下载阅读,该IP是Xilinx官方将1G/2.5G Ethernet PCS/PMA or SGMII和Tri Mode Ethernet MAC封装在一起组成的全新IP,目的是简化FPGA实现以太网物理层的设计难度,直接调用这一个IP即可使用,该IP展开后如下:
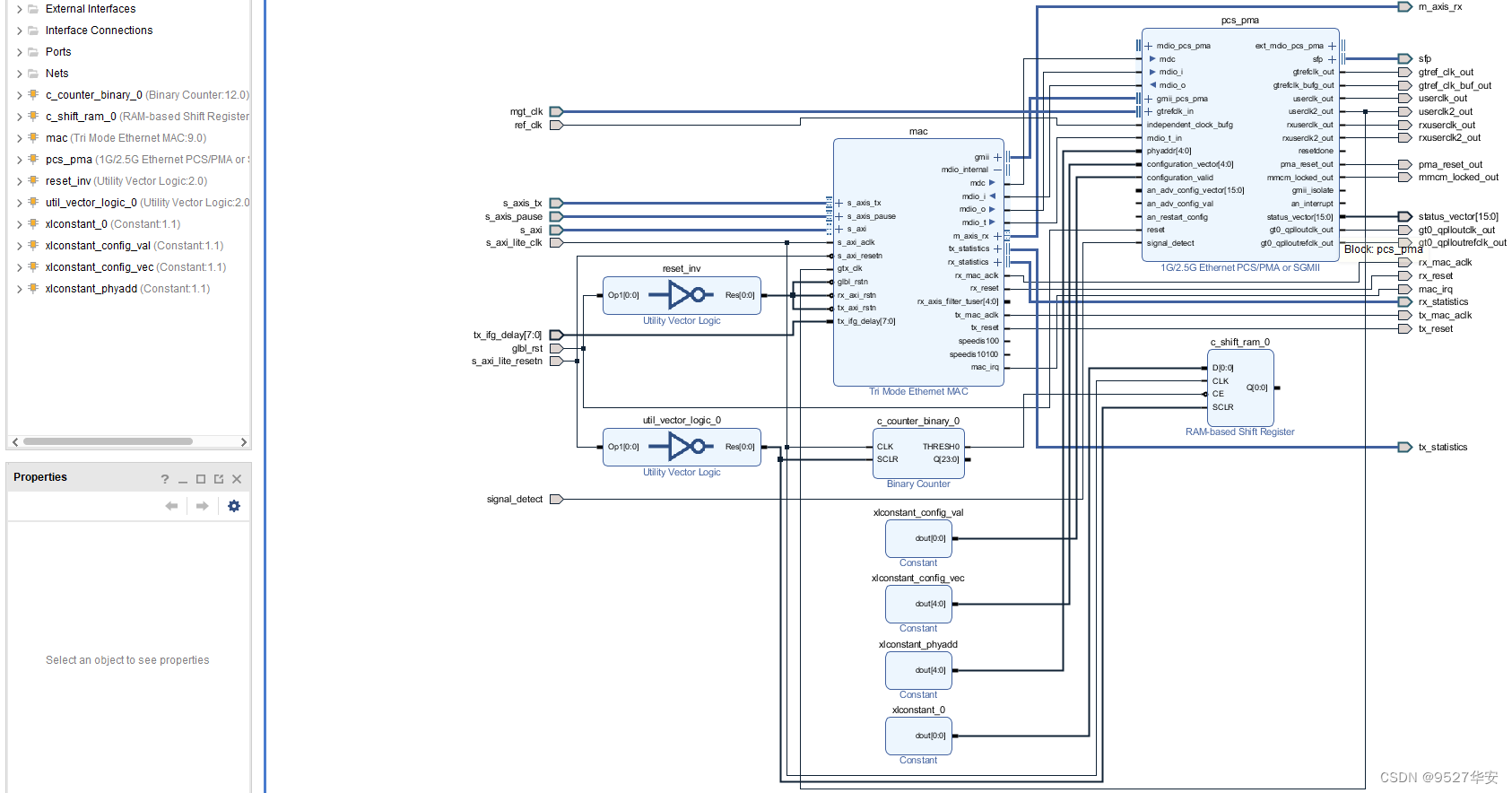
接收端:
数据首先经过1G/2.5G Ethernet PCS/PMA or SGMII解串,将串行数据解为并行数据;然后经过弹性Buffer做数据缓冲处理,主要是为了去频偏,使板与板之间的数据稳定,然后进行8b/10b解码,恢复正常数据;然后经过PCS接收同步器,对数据进行跨时钟处理,同步到GMII时序下然后输出给Tri Mode Ethernet MAC进行数据合适转换,最后以AXI4-Stream输出;
发送端:
发送端则简单得多,用户侧UDP MAC数据首先给到Tri Mode Ethernet MAC进行数据合适转换,以GMII数据输出给1G/2.5G Ethernet PCS/PMA or SGMII,后者进行以太网物理层处理,以差分信号输出;
AXI 1G/2.5G Ethernet Subsystem 配置
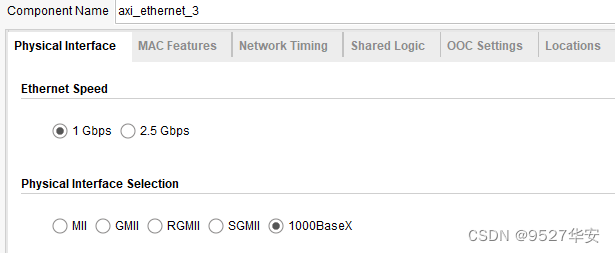
AXI 1G/2.5G Ethernet Subsystem配置为1G,如下:
AXI 1G/2.5G Ethernet Subsystem可运行于1G和2.5G线速率,对GT时钟有严格研究,按照官方数据手册,运行1G线速率时,GT差分时钟必须为125M,运行2.5G线速率时,GT差分时钟必须为312.5M,如下:
QT上位机和源码
PC端接收网络视频,并运行QT上位机接收显示视频;我们提供和UDP通信协议相匹配的QT抓图显示上位机及其源代码,目录如下:


我们的QT目前仅支持1280x720分辨率的视频抓图显示,但同时预留了1080P接口,对QT开发感兴趣的朋友可以尝试修改代码以适应1080P,因为QT在这里只是验证工具,不是本工程的重点,所以不再过多赘述;
工程源码架构
本博客提供3套工程源码,以工程源码1为例,vivado Block Design设计如下,其他工程与之类似,Block Design设计为图像缓存架构的部分:
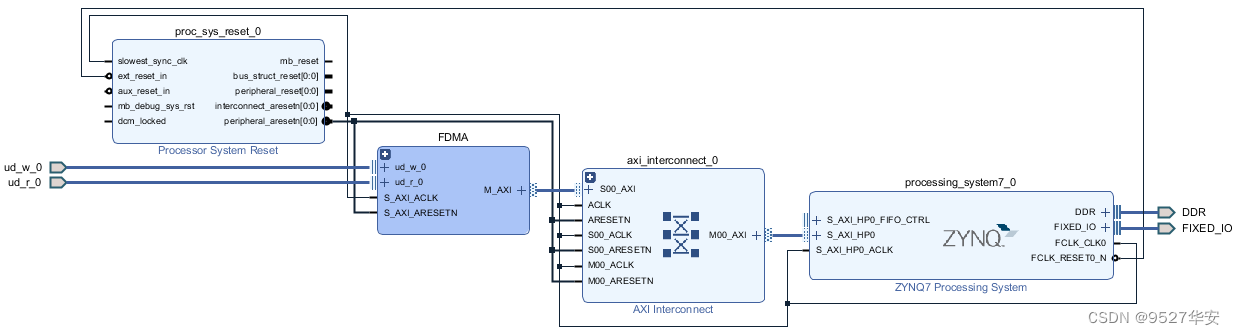
以工程源码1为例,使工程源码架构如下,其他工程与之类似:

FDMA图像缓存架构虽然不需要SDK配置,但FDMA的AXI4接口时钟由Zynq提供,所以需要运行SDK程序才能启动Zynq,从而为PL端逻辑提供时钟;由于不需要SDK配置,所以SDK软件代码就变得极度简单,只需运行一个“Hello World”即可,如下:
4、工程源码1详解–>PHY芯片以太网输出方案
开发板FPGA型号:Xilinx-Zynq7100–xc7z100ffg900-2;
开发环境:Vivado2019.1;
输入:3G-SDI相机或HDMI转SDI盒子,分辨率1920x1080@60Hz;
输出:RJ45网口,分辨率1280x720@60Hz;
图像缩放方案:自研纯Verilog图像缩放;
图像缩放实例:1920x1080缩放到1280x720;
图像缓存方案:自研FDMA方案;
图像缓存介质:PS端DDR3;
以太网输出方案:PHY芯片以太网输出;
PHY芯片:RTL8211E,延时模式,RGMII接口;
PC端接收方案:QT上位机;
工程作用:此工程目的是让读者掌握Zynq系列FPGA实现SDI转网口的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
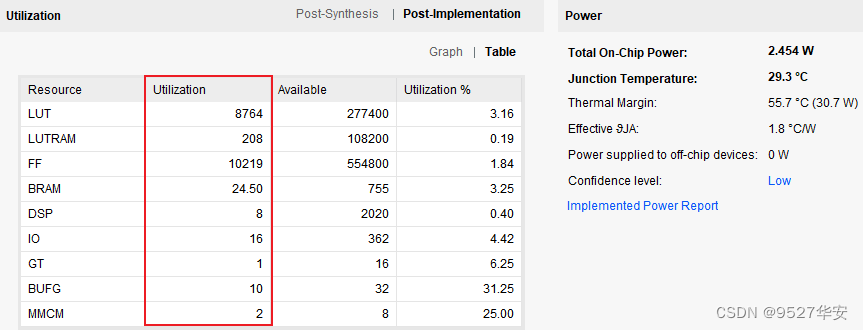
工程的资源消耗和功耗如下:
5、工程源码2详解–>1G/2.5G Ethernet PCS/PMA or SGMII以太网输出方案
开发板FPGA型号:Xilinx-Zynq7100–xc7z100ffg900-2;
开发环境:Vivado2019.1;
输入:3G-SDI相机或HDMI转SDI盒子,分辨率1920x1080@60Hz;
输出:SFP光口,分辨率1280x720@60Hz;
图像缩放方案:自研纯Verilog图像缩放;
图像缩放实例:1920x1080缩放到1280x720;
图像缓存方案:自研FDMA方案;
图像缓存介质:PS端DDR3;
以太网输出方案:1G/2.5G Ethernet PCS/PMA or SGMII+Tri Mode Ethernet MAC以太网输出;
PC端接收方案:QT上位机;
工程作用:此工程目的是让读者掌握Zynq系列FPGA实现SDI转网口的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
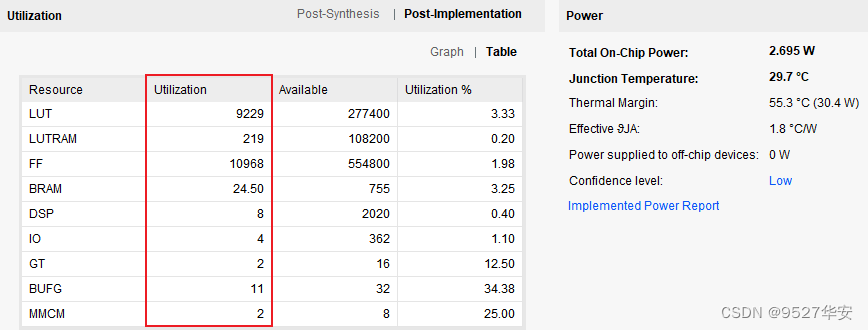
工程的资源消耗和功耗如下:
6、工程源码3详解–>AXI 1G/2.5G Ethernet Subsystem以太网输出方案
开发板FPGA型号:Xilinx-Zynq7100–xc7z100ffg900-2;
开发环境:Vivado2019.1;
输入:3G-SDI相机或HDMI转SDI盒子,分辨率1920x1080@60Hz;
输出:SFP光口,分辨率1280x720@60Hz;
图像缩放方案:自研纯Verilog图像缩放;
图像缩放实例:1920x1080缩放到1280x720;
图像缓存方案:自研FDMA方案;
图像缓存介质:PS端DDR3;
以太网输出方案:AXI 1G/2.5G Ethernet Subsystem以太网输出;
PC端接收方案:QT上位机;
工程作用:此工程目的是让读者掌握Zynq系列FPGA实现SDI转网口的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
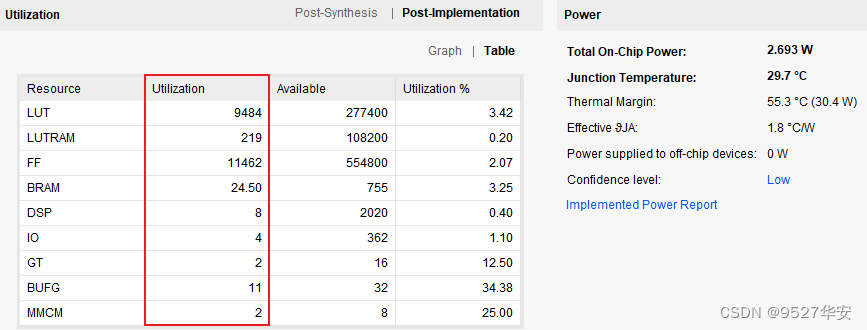
工程的资源消耗和功耗如下:
7、工程移植说明
vivado版本不一致处理
1:如果你的vivado版本与本工程vivado版本一致,则直接打开工程;
2:如果你的vivado版本低于本工程vivado版本,则需要打开工程后,点击文件–>另存为;但此方法并不保险,最保险的方法是将你的vivado版本升级到本工程vivado的版本或者更高版本;
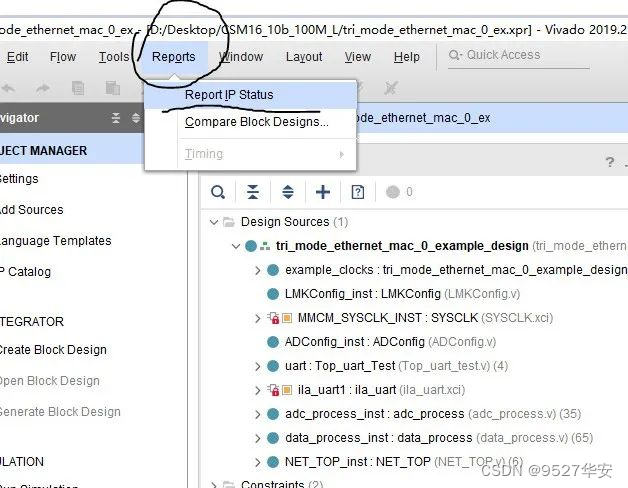
3:如果你的vivado版本高于本工程vivado版本,解决如下:
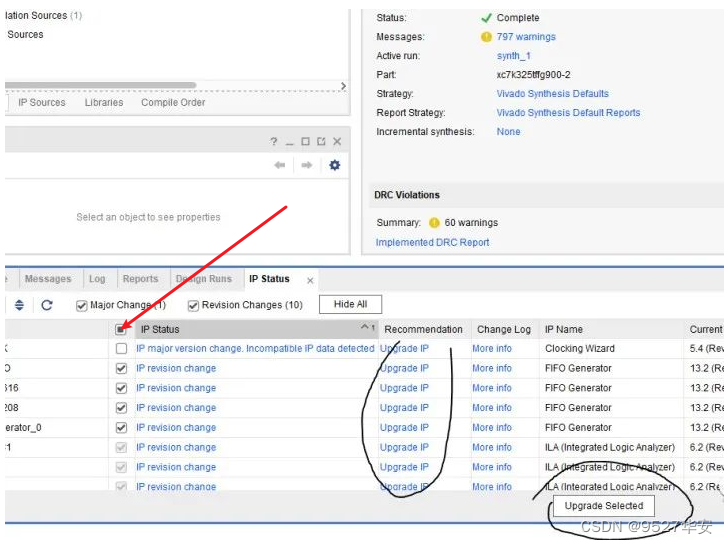
打开工程后会发现IP都被锁住了,如下:
此时需要升级IP,操作如下:
FPGA型号不一致处理
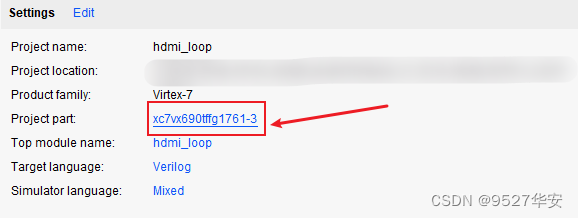
如果你的FPGA型号与我的不一致,则需要更改FPGA型号,操作如下:
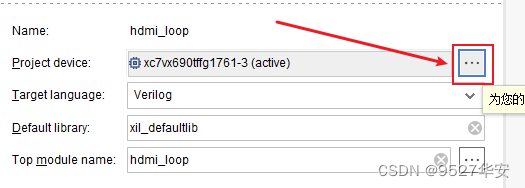
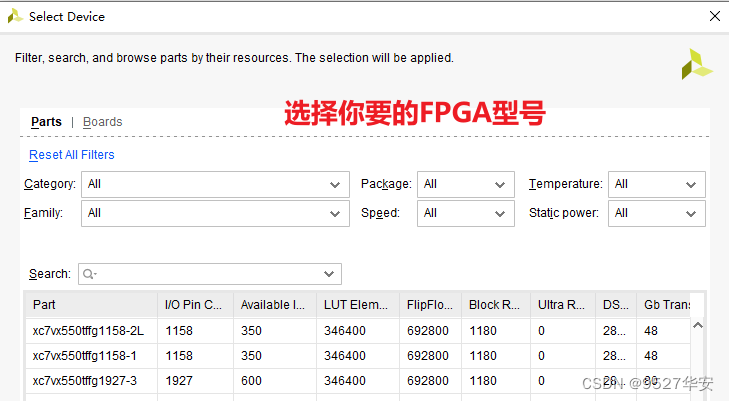
更改FPGA型号后还需要升级IP,升级IP的方法前面已经讲述了;
其他注意事项
1:由于每个板子的DDR不一定完全一样,所以MIG IP需要根据你自己的原理图进行配置,甚至可以直接删掉我这里原工程的MIG并重新添加IP,重新配置;
2:根据你自己的原理图修改引脚约束,在xdc文件中修改即可;
3:纯FPGA移植到Zynq需要在工程中添加zynq软核;
8、上板调试验证
准备工作
需要准备的器材如下:
FPGA开发板;
SDI摄像头或HDMI转SDI盒子;
SFP转网口模块(电口);
网线;
我的开发板了连接如下:

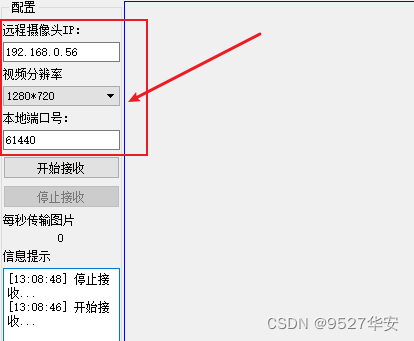
QT上位机配置如下:
输出视频演示
以工程1,3G-SDI输入图像缩放转网络输出为例,输出如下:
3G-SDI输入图像缩放转网络输出
9、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:私,或者文章末尾的V名片。
网盘资料如下:

此外,有很多朋友给本博主提了很多意见和建议,希望能丰富服务内容和选项,因为不同朋友的需求不一样,所以本博主还提供以下服务: