Intriguing properties of neural networks
经典论文、对抗样本领域的开山之作
发布时间:2014
论文链接: https://arxiv.org/pdf/1312.6199.pdf
作者:Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, Rob Fergus
写在前面:该文章已经发表10年了,该领域的发展十分迅速,本文中的一些观点可能并不准确
核心观点
深度神经网络是高度表达性 (highly expressive models) 的模型。由于其复杂和多层次的结构,深度神经网络能够捕捉到数据中极其微妙和复杂的模式。然而,这种复杂性同时也意味着网络内部的决策过程很难被人类理解,对人们来说有些违反直觉 (counter-intuitive)。
在这篇论文中,作者介绍了两个十分有趣的属性:
- 通过不同的单元分析方法,高层单元本身 (individual high level units) 与它们的随机线性组合 (random linear combinations of high level units) 在功能上看起来并无差别。这表明在神经网络的高层中,包含语义信息的是空间,而不是单个单元。
- 深度神经网络学习的输入输出映射在很大程度上是相当不连续的。通过施加几乎察觉不到的扰动,就可以使网络错误地分类一个图像,这种扰动是通过最大化网络的预测误差找到的。此外,这些扰动的具体性质不是学习的随机产物:相同的扰动可以导致另一个网络(该网络在数据集的不同子集上训练)错误分类相同的输入。
对观点1的解释
- 高层单元与随机线性组合之间无区别:"高层单元"指网络中较靠近输出层的那些单元。这意味着,如果取一些高层的单元,不论是单独考虑还是将它们通过某种线性方式组合起来,从分析这些单元的角度来看,无法区分出它们之间的差别。这个观察挑战了我们通常认为的“特定单元负责特定高级特征”的理解。
- 语义信息的空间:由于单个单元和它们的组合在功能上没有区别,这表明高层次的语义信息并不是储存在单个神经元中,而是分布在整个空间中。这里的“空间”指的是由这些高层单元构成的多维空间,意味着信息是以某种分布的形式存在的,而不是局限于某个单个单元。
- 对深度学习的理解:神经网络处理信息和提取特征的方式可能比我们之前理解的要复杂得多。而不是单个单元对应单一的、明确的特征,更多的是整个单元集合以一种分布的方式共同表达了高级的语义信息。
在深度神经网络的高层中,重要的不是单个的单元,而是单元们形成的整体空间。这个空间以一种我们还不完全理解的方式,包含了输入数据的抽象和高级的语义信息。
对观点2的解释
- 输入输出映射的不连续性:深度神经网络将输入数据(如图像)映射到输出(如分类标签)的过程并不是平滑连续的。这意味着,即使是非常微小的改变也可能导致输出结果的巨大变化。例如,一个图像被正确分类为“猫”,但当这个图像被稍微修改后,即使这种修改几乎肉眼不可见,网络可能会错误地将其分类为“狗”。
- 扰动的发现和影响:这些细微的扰动是通过优化 (optimization) 找到的,目的是最大化网络的预测误差。这表明可以系统地生成这样的扰动,也表明深度神经网络在其决策边界周围可能存在着“盲区”,即那些对扰动高度敏感的区域。
- 扰动的非随机性和普遍性:这些导致误分类的扰动并不是随机产生的,也不是特定于某个网络的。相同的或类似的扰动可以导致在不同数据集上训练的其他网络也产生错误的分类结果。这意味着这种脆弱性是深度学习模型普遍存在的问题,而不仅仅是个别模型的特定缺陷。
在安全性方面,攻击者可能利用这一点生成扰动,以误导模型做出错误的决策;在鲁棒性方面,推动了对神经网络鲁棒性研究,即如何设计出能够抵抗这类细微扰动影响的模型。
背景知识
泛化
- 局部泛化 (local generalization):
- 模型在训练数据点附近的输入空间进行有效预测的能力
- 基于假设:输入空间中相互靠近的点(在某个小的邻域内)应当具有相似的输出
- 局部泛化反映了模型对于轻微扰动(如噪声)的鲁棒性,即这些小变动不会导致模型预测结果的显著改变
- 非局部泛化 (non-local generalization):
- 模型在输入空间中远离训练数据点的区域做出准确预测的能力
- 这涉及到对输入空间的更广泛区域的泛化,包括那些与训练样本在特征空间中相差较远的点
- 非局部泛化需要模型在没有直接数据支持的情况下推断输出,这通常依赖于模型对数据的高层次抽象和理解。例如,一个模型可能已经学习到“猫”的高级特征,如形状和纹理,因此即使是在训练数据中从未出现过的猫的新图片,模型也能正确分类。
总的来说,局部泛化关注点是模型对训练数据的微小变化的响应,而非局部泛化关注的是模型对于新的、可能在训练数据中没有直接例子的情况的处理能力。
特征提取 (feature extraction)
在传统的计算机视觉系统中,颜色直方图 (histogram of colors) 和量化的局部导数 (quantized local derivatives) 是常见的特征.
- 颜色直方图:颜色直方图是图像中颜色分布的图形表示。它统计了每种颜色在图像中出现的频率。由于颜色是视觉信息的直观属性,所以颜色直方图提供了一种简单的方式来描述和分析图像的颜色组成。这使得比较不同图像的颜色分布变得直观,且不依赖于图像的大小或者颜色在图像中的具体位置。
- 量化的局部导数:局部导数,如图像的边缘,是通过检测像素强度的变化来识别的。量化意味着这些导数值被简化为有限的几个级别。这些局部导数可以表示图像中物体的边界和纹理信息,是图像分析的基本工具。
这些特征容易理解,因为它们是从人类的视觉经验中抽象出来的基础视觉属性。颜色和边缘是人类用来理解世界的基本视觉线索,所以这些特征可以与我们对图像内容的直观理解直接相连。在机器学习模型中使用这些特征可以帮助系统在一定程度上模仿人类的视觉识别过程。
Kernel methods
Kernel methods 是一类算法,在机器学习和统计学中被广泛用于模式识别、分类和回归问题。这些方法的核心思想是通过一个函数(即“核函数”)将输入数据映射到一个高维特征空间,在这个高维空间中,数据点可能更容易被线性分割或分类。Kernel方法的一个关键特性是,它们能够处理非线性关系而无需显式地定义高维映射,这是通过核技巧(kernel trick)实现的。
Kernel技巧利用核函数来计算输入数据点之间的相似度,核函数对应于高维特征空间中的内积。这允许算法在原始输入空间中间接计算出高维特征空间中的关系,而不需要进行实际的映射,从而避免了直接在高维空间中计算的高昂计算成本。
最著名的kernel方法之一是支持向量机(SVM),它使用核函数来找到最佳的决策边界,或者说超平面,该超平面可以将数据分割成不同的类别。
当文中提到“对于深度神经网络,许多核方法所依赖的平滑性假设不成立”时,它可能是在指出与传统的核方法(这些方法假设通过合适的核函数可以在高维空间实现平滑的决策边界)相比,深度神经网络在学习数据表示时表现出不同的特性。这暗示了深度网络可能能够学习出更复杂的模式或决策边界,这些模式或边界在核方法的传统框架下可能无法捕捉。
盒约束优化问题 (box-constrained optimization problem)
在解决盒约束优化问题时,通常会使用一些特定的算法,如梯度投影法(projected gradient method)、有界限制的BFGS(L-BFGS-B)等,这些算法能够在搜索最优解的同时保持所有变量在约束的范围内。
框架与数据集
本论文在几个不同的网络和三个数据集上进行了大量的实验:
- MNIST dataset
- “FC”(Fully Connected):由一个或多个隐藏层和一个Softmax分类器组成的简单全连接网络
- “AE”(Autoencoder):在自动编码器上训练的分类器
- ImageNet dataset
- AlexNet网络:具体可参见论文:“Imagenet classification with deep convolutional neural networks”
- 来自 Youtube 的10M图像样本
- “QuocNet”:具有10亿可学习参数的无监督训练网络
对于MNIST实验,我们使用了带有权重衰减 λ λ λ 的正则化。此外,在一些实验中,我们将MNIST训练数据集分成两个互不相交的数据集 P 1 P_1 P1 和 P 2 P_2 P2,每个数据集包含30000个训练样本。
Units of: φ ( x ) φ(x) φ(x)
传统计算机视觉通常依赖于特征提取 (feature extraction),通常来说,一个简单的特征很容易理解,就比如:颜色直方图和量化的局部导数,这也使得人们可以将特征空间中的各个坐标与输入域中的有意义的变化联系起来。
在深度神经网络中,类似的推理也被应用于尝试解释计算机视觉问题。在这些工作中,研究者们将隐藏单元的激活解释为有意义的特征,并寻找能够最大化这个单个隐藏单元激活值的输入图像。简单地说,他们试图找到哪些输入图像会引发神经网络中某个特定单元的最强激活反应,这样的激活被认为是捕捉到了某个重要特征,可以表示如下:
x ′ = arg max x ∈ I ⟨ ϕ ( x ) , e i ⟩ x'=\underset{x \in \mathcal{I}}{\text{arg max}} \langle \phi(x), e_i \rangle x′=x∈Iarg max⟨ϕ(x),ei⟩
x ′ x' x′ 表示满足(或接近)最大可达值(attainable value)的图像视觉检查
e i e_i ei 表示第 i i i 个隐藏单元相关联的自然基向量
I \mathcal{I} I 表示保留集,是从数据分布中选取的,但网络没有在其上训练的图像集合
arg max x f ( x ) \text{arg max}_x f(x) arg maxxf(x) 表示函数 f ( x ) f(x) f(x) 取最大值时对应的自变量 x x x 的值,在这个具体公式中表示,寻找集合 I \mathcal{I} I 中的一个元素 x x x,使得内积 ⟨ ϕ ( x ) , e i ⟩ \langle \phi(x), e_i \rangle ⟨ϕ(x),ei⟩最大。换句话说,它找的是哪一个 x x x 与向量 e i e_i ei 有最大的“匹配度”或“相关性”。在深度学习的应用中,这通常意味着找到使某个特定神经网络层的激活最大化的输入 x x x。
3. 神经网络中的盲点(寻找对抗样本)
单位级别的检查 (unit-level inspection) 几乎没什么作用,而全局的、网络级别的检查方法在解释模型做出分类决策上可能会是有用的。就比如,用于识别输入中能使得给定输入实例进行正确分类的那部分(换言之,可以使用经过训练的模型进行弱监督定位),这种全局分析使我们更好地理解训练后的网络所代表的从输入到输出的映射。
通常来说,神经网络的输出层单元是其输入的一个高度非线性函数。当它使用交叉熵损失训练时(使用Softmax激活函数),它代表了给定输入(以及到目前为止呈现的训练集)标签的条件分布。有人认为,输入与神经网络输出单元之间的深层非线性层堆叠是模型编码输入空间上的非局部泛化先验的一种方式。换句话说,输出单元能够给输入空间中那些没有训练示例在其附近的区域分配极小的概率。例如,从不同视角看相同对象,虽然这些视角在像素空间中距离相对较远,但它们既共享标签也共享原始输入的统计结构。
具体解释如下:
- 损失函数衡量的是模型预测的概率分布与真实标签的概率分布之间的差异。在理想情况下,模型预测的概率分布应该与真实的分布完全一致,这时交叉熵损失会是最低的。所以,可以说对于分类问题,使用交叉熵损失,相当于用神经网络来计算输入图像对应类别的条件分布。
- 非局部泛化先验 (non-local generalization prior) 的概念指的是神经网络能够对那些在训练数据中没有直接出现过的输入进行有效泛化的能力。这意味着,即使某个输入(或输入的某个区域)在训练集中没有直接的对应样本,网络仍然能够基于它对整个输入空间的学习,对这个新的、未见过的输入做出合理的预测。输入与神经网络输出单元之间的深层非线性层堆叠也有人理解为神经网络在对输入空间的非局部泛化先验进行编码。
- 输出单元能够给输入空间中那些没有训练示例在其附近的区域分配极小但并非为0的概率 non-significant (and, presumably, non-epsilon) probabilities. 尽管这些输入数据在特征上可能与某些类别有关联,但根据模型通过训练学到的信息,它认为这些数据属于那个类别的可能性不高。这是模型尝试对看到的和未看到的数据进行泛化和推理的一种表现,即使面对它在训练数据中没有直接遇到的新情况,也能做出合理的预测。
- 深度学习模型尤其是卷积神经网络在图像识别和分类中具有泛化能力。模型通过训练,能够识别与训练样本在像素层面大相径庭的输入,例如,能处理同一对象从未在训练集中出现过的不同视角的图像。这归功于模型学习到的对象的一般性特征和统计结构,如形状、纹理和颜色分布,而不仅仅是依赖特定的像素排列。即使是从新的、未见过的视角观察到的对象,这些从不同角度拍摄的图像虽然在像素级别上看似不同,但因为它们代表同一对象,所以共享相同的分类标签和统计结构,使得网络能够将它们正确分类。这也展示了深度学习模型对输入数据的深层次理解能力,它能够识别和归纳超越像素相似性的图像背后的抽象特征和模式。
上述论证中隐含着这样一个论点:在非常接近训练示例的情况下,局部泛化按照预期那样正常工作。在这种假设下,如果给定一个很小的半径 ε > 0 \varepsilon>0 ε>0 和输入样本 x x x ,对于满足 r + x r+x r+x, ∣ ∣ r ∣ ∣ < ε ||r||<\varepsilon ∣∣r∣∣<ε ( r r r 表示微小变化) 的输入样本依然有机会被正确的分类。这种平滑先验通常对计算机视觉问题是有效的,即给图像细微扰动通常不会改变它本来的类别。但是对于深层神经网络,这篇文章的得到的结果是上述的平滑假设并不成立。并且可以通过简单的优化过程找到对抗样本(对正确分类的输入图像进行不明显的微小扰动),让神经网络不能再正确分类。
- 当提到局部泛化工作“如预期”的时候,它指的是在模型训练的数据点的非常近的范围内,模型能够保持其预测的连贯性和准确性。而非局部泛化则是挑战模型在远离训练数据点的范围内仍能保持有效预测能力的问题。
对于深度神经网络而言,我们发现许多核方法 (kernel methods) 所依赖的平滑性假设并不成立。具体来说,我们展示了通过使用一个简单的优化过程,我们能够找到对抗样本,这些是通过对正确分类的输入图像进行微小的、几乎察觉不到的扰动得到的,从而使得它不再被正确分类。
从某种意义上讲,我们描述的是一种通过优化以高效方式遍历神经网络所代表的流形 (traverse the manifold),并在输入空间中找到对抗样本 (adversarial examples) 的方法。
- “traverse the manifold”(遍历流形)是指在神经网络所代表的数据空间(或称为“流形”)内进行搜索或探索的过程。这里的“流形”是数学上的一个概念,用来描述在局部呈现出欧几里得空间特性的空间。在深度学习中,神经网络可以被看作是在高维数据空间中定义了一个复杂的流形,该流形通过网络的层次结构将输入数据映射到输出结果。因此,“遍历流形”具体指的是通过优化方法在这个高维空间内移动,以寻找那些能够改变网络输出的特定输入值,即寻找到能够使神经网络输出错误结果的对抗样本
对抗样本代表了流形中这个高维空间的特定区域,这些区域的存在可能会导致模型的预测错误,但这些区域出现的概率很低,使得通过随机采样来发现这些区域变得非常困难。已经有许多计算机视觉模型在训练过程中采用输入变形(比如旋转、缩放、剪切图像),以提高模型的鲁棒性和收敛速度。这些变形从统计上来看对于给定示例是低效的:它们高度相关,并且在整个模型训练过程中都来自同一个分布。
然而,尽管这些输入变形能增加数据的多样性,但从统计学的角度来看,它们是低效的。原因是这些变形高度相关,而且整个训练过程中,这些变形产生的数据都来自于同一个分布。这意味着,尽管数据通过变形在表面上看起来不同,但从根本上讲,它们带给模型学习的信息是有限的,因为这些变化是可预测的,且在整个训练过程中没有本质的变化。如果在训练过程中一直重复使用相同的变形方法,模型可能会过于适应这些特定的变形而不是学会从根本上理解图像的内容。
我们提出了一种方案,利用模型及其在训练数据周围局部空间建模方面的不足,使这一过程自适应。这种方法能够识别出模型在理解训练数据特别是数据的局部细节方面存在的问题或不足。利用这种识别出来的信息,该方法能够自动调整训练过程,使其更加针对性地解决这些问题,从而提高模型的性能。
我们的方案与硬负采样(hard-negative mining)有密切的联系,因为它们在想法上是接近的:在计算机视觉中,“硬负例”指的是那些模型错判为负例(即非目标类)的正例样本,或者说,它们是模型预测错误的案例,但按理应该被正确分类的。这些样本对于模型来说是“难题”,因为模型很难准确地将它们分类到正确的类别中。即,被模型错误地判断为低概率(即模型认为它们属于某一类的可能性很低)的示例,但实际上,这些示例应该被判断为高概率(即应该很容易被识别为某一类)。通过识别这些模型当前处理不好的示例,并在训练集中对它们给予更多的重视(例如,通过增加它们的权重或更频繁地将它们纳入训练批次中),可以促使模型更加关注于改进其在这些特定情况下的表现。正如所述的那样,本工作提出的优化问题也以一种类似于硬负采样的方式被使用。
4.1 正式描述
f : R m → { 1 , … , k } f:\mathbb{R}^m \rightarrow \{1, \ldots, k\} f:Rm→{1,…,k}为分类器,接收一个 m m m 维的图像像素值向量作为输入,将其映射到一个离散的标签集 1... k {1 ... k} 1...k 中, k k k 为类别数。
给定图片 x ∈ R m x \in \mathbb{R}^m x∈Rm 以及目标标签 l ∈ { 1 , … , k } l \in \{1, \ldots, k\} l∈{1,…,k},我们想解决如下的盒约束优化问题 (box-constrained optimization problem):
Minimize ∣ ∣ r ∣ ∣ 2 subject to: 1. f ( x + r ) = l 2. x + r ∈ [ 0 , 1 ] m \text{Minimize $||r||_2$ subject to:} \\ 1.f(x+r) = l \\ 2.x+r \in [0,1]^m Minimize ∣∣r∣∣2 subject to:1.f(x+r)=l2.x+r∈[0,1]m
存在约束:
- 找到一个扰动向量 r r r,使得扰动后的图像 x + r x + r x+r 被分类器 f f f 识别为目标标签 l l l
- x + r ∈ [ 0 , 1 ] m x+r \in [0,1]^m x+r∈[0,1]m:扰动后的图像像素值在合理范围
D ( x , l ) D(x,l) D(x,l) 用来寻找距离原始图像 x x x 最近的、被分类器 f f f 错误分类的图像。最小值 r r r 可能并不唯一,我们用 x + r x+r x+r 表示通过 D ( x , l ) D(x,l) D(x,l) 任意选择的一个最小值。很明显, D ( x , f ( x ) ) = f ( x ) D(x,f(x))=f(x) D(x,f(x))=f(x),因此当 f ( x ) ≠ l f(x)≠l f(x)=l 时,这个任务才是有意义的。
通常,$ D(x,l) $ 的精确计算是一个困难问题,因此我们使用盒约束L-BFGS (box-constrained L-BFGS) 对其进行近似。我们通过进行线性搜索来找到最小值 c > 0 c>0 c>0,对于该最小值,以下问题的极小值 r r r 满足 f ( x + r ) = l f(x+r)=l f(x+r)=l
Minimize c ∣ r ∣ + loss f ( x + r , l ) subject to x + r ∈ [ 0 , 1 ] m \text{Minimize } c|r| + \text{loss}_f(x + r, l) \quad \text{subject to } x + r \in [0, 1]^m Minimize c∣r∣+lossf(x+r,l)subject to x+r∈[0,1]m
在凸损失 (convex losses) 的情况下,这种惩罚函数方法 (penalty function method) 将给出精确解,但是神经网络通常是非凸的,因此在这种情况下我们会得到一个近似值。
实验结果
我们的最小失真 (minimum distortion) 函数 D D D 具有以下有趣特性,我们将在本节中通过非正式证据和定量实验加以说明:
- 在上述提及的神经网络中,对于每个样本,我们总是设法生成非常接近的,视觉上难以区分的,并且被原始网络错误分类的对抗样本,如下图所示(注:2024.4 链接已失效)

- 跨模型泛化能力:在 A 模型上产生的对抗样本,有很大一部分在 B 模型(和 A 模型结构相同,超参数不同)上也有效
- 跨数据集泛化能力:在 D1数据集训练得到的模型上产生的对抗样本,在 D2 数据集训练得到的模型上也有效,D1 和D2 属于不同的子集
上述结果表明,对抗样本在某种程度上是普遍的,而不仅仅是过度拟合特定模型或特定选择训练集的结果。并且,将对抗样本用于训练可能会提高结果模型的通用性。我们的初步实验也为MNIST提供了积极的证据来支持这一假设:我们通过保留一组对抗样本作为随机子集,成功地训练了测试误差低于1.2%的两层100-100-10非卷积神经网络,通过维护了一个动态对抗样本池,在每次训练迭代中,一部分对抗样本会被新生成的对抗样本替换。
我们使用了权重衰减 (weight decay),但没有使用 (dropout)。作为比较,仅通过权重衰减进行正则化,该规格的识别误差为1.6%,但通过使用精心设计的 Dropout 可将其降低至1.3%左右。一个很关键的细节是在训练过程中,针对每一层的输出生成对抗样本并用这些样本来训练该层以上的所有层。该网络以交替的方式进行训练,除了原始训练集之外,还分别维护和更新每一层的对抗样本库。根据观察,高层的对抗样本似乎比输入层或较低层的对抗样本有用得多。在未来的工作中,我们计划系统地比较这些影响。
出于空间考虑,我们只介绍我们执行的MNIST实验的代表性子集(参见下表)的结果。此处显示的结果与各种非卷积模型的结果一致。 对于MNIST,我们尚无卷积模型的结果,但我们与 AlexNet 进行的首次定性实验让我们有理由相信卷积网络的行为也可能相似。我们的每个模型都经过L-BFGS训练直至收敛。前三个模型是具有不同权重衰减参数 λ λ λ 的线性分类器,将二次权重衰减 l o s s d e c a y = λ ∑ w i 2 / k loss_{decay}=\lambda \sum w_i^2/k lossdecay=λ∑wi2/k ( k k k 是一层中单元的数量)填加至总损失中。
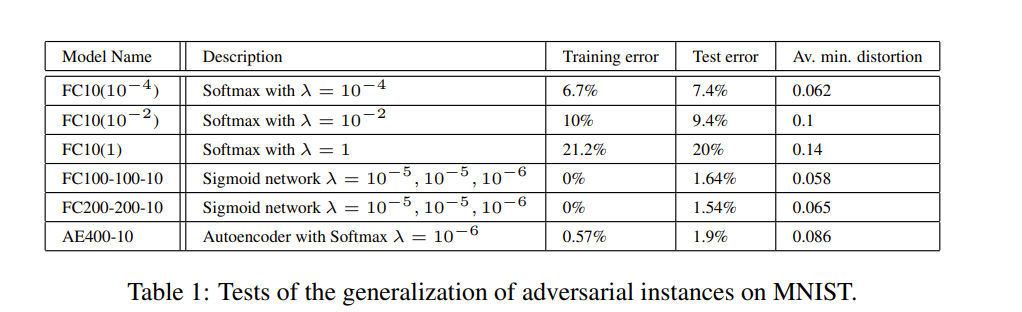
具体来看该表格,左侧是具体的模型,前三个是没有隐藏层的简单 softmax 分类器 FC10( λ λ λ ) , 其中 FC10(1) 表示以 λ = 1 λ = 1 λ=1 这种极端情况进行训练,来测试是否仍然可以产生对抗样本。另外两个模型是具有两个隐藏层和一个分类器的简单 sigmoidal 神经网络。最后一个模型AE400-10 是由具有Sigmoid型激活的单层稀疏自动编码器 (sparse autoencoder) 和带有 Softmax 分类器的400个节点组成的。该网络已经过训练获得了非常高质量的第一层过滤器并且没有对该层进行微调。
最后一列测量在训练集上达到 0% 精度所需的最小平均像素级别失真 (the minimum average pixel level distortion),也就是100%分类失败,这个失真是通过 ∑ ( x i ′ − x i ) 2 n \sqrt{\frac{\sum(x_i'-x_i)^2}{n}} n∑(xi′−xi)2来衡量的,其中 n 是图像像素的数目,像素值缩放到 [ 0 , 1 ] [0,1] [0,1] 范围内。
跨模型的泛化能力
在我们的第一个实验中,我们为给定的网络生成了一组的对抗样本,并为每个其他网络提供这些实例来测量误分类实例的比例。结果如下,最后两行用给定量的高斯噪声所引起的失真误差作为参考。除了一个模型以外的所有模型,即使标准差为0.1的噪声也大于我们对抗性噪声的标准差。图7展示了该实验中使用的两个网络生成的对抗样本的可视化。总的来说,即使对于使用不同超参数训练的模型,对抗样本也有所影响。尽管基于自动编码器的版本似乎可以对抗敌手,但也不能完全避免。
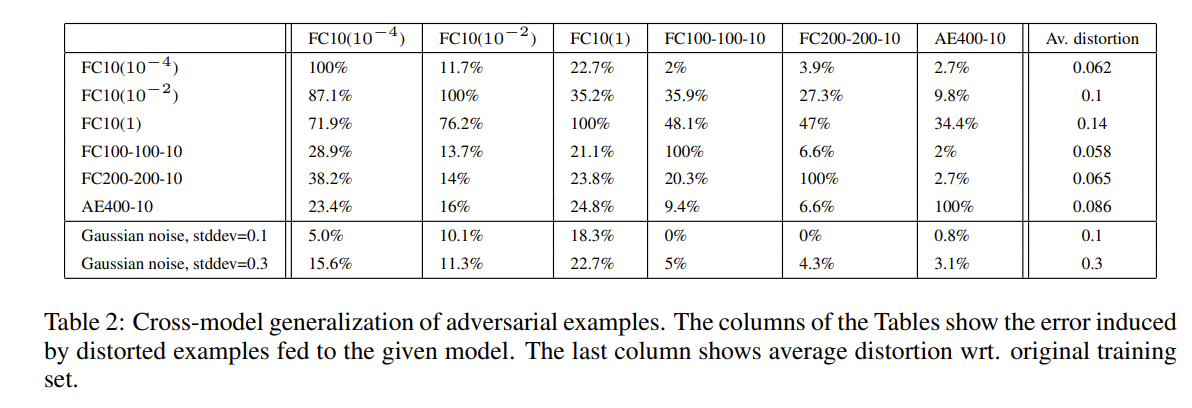

接下来研究有关数据集的问题,生成对抗样本的难度是否仅取决于训练集的特定选择吗,而且以上部分的使用都是在相同的数据集进行训练的,那么对抗样本的效果可以推广到在完全不同的训练集上训练的模型吗?
跨数据集泛化能力
为了研究交叉训练集的泛化,我们将60000个MNIST训练图像划分为30000个每组的 P 1 P_1 P1 和 P 2 P_2 P2 两个部分,并训练了三个具有 Sigmod 激活函数的非卷积网络:在 P 1 P_1 P1 上训练 FC100-100-10 和 FC123-456-10,在 P 2 P_2 P2 上训练 FC100-100-10。在 P 1 P_1 P1 上训练两个网络的原因是要研究同时更改超参数和训练集的累积效应。FC100-100-10 和 FC100-100-10’ 共享相同的超参数:它们都是100-100-10网络,而FC123-456-10 具有不同数量的隐藏单元。表3总结了有关这些模型的基本参数。
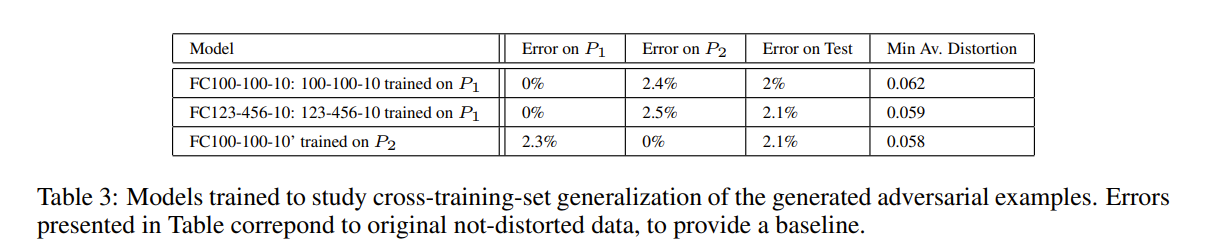
在为测试集生成具有100%错误率且失真最小的对抗样本之后,我们将这些示例提供给每个模型。
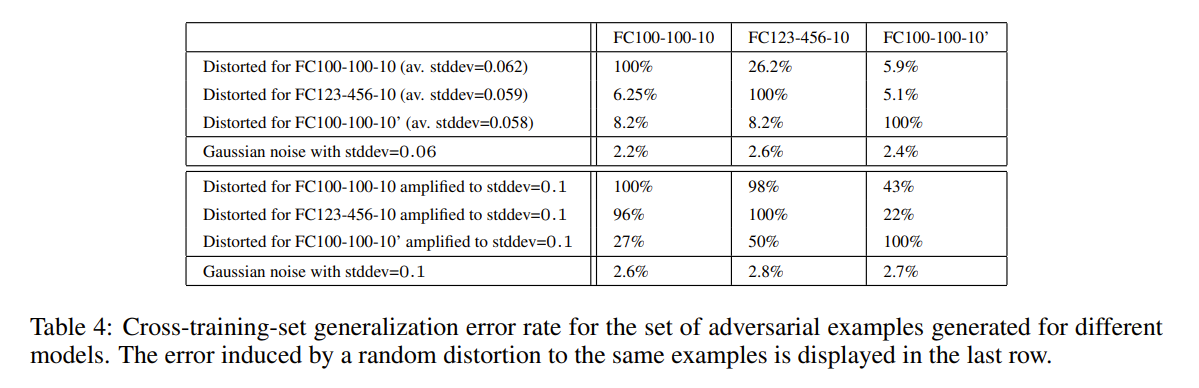
在最后的实验中,我们衡量失真的效应为 x + 0.1 x ′ − x ∣ ∣ x ′ − x ∣ ∣ 2 x+0.1\frac{x'-x}{||x'-x||_2} x+0.1∣∣x′−x∣∣2x′−x 而不是 x ′ x' x′。这将失真平均提高了40%,stddev 从0.06扩大到 0.1。我们可以得出结论:即使在不相交的训练集上训练的模型,对抗样本依旧也所影响,尽管其有效性大大降低。
神经网络稳定性的频谱分析
本部分涉及许多数学公式证明,一个专门讲解这部分的证明过程的视频链接如下:https://www.youtube.com/watch?v=df_NZyGeVXg
讨论
文章证明了深度神经网络在个体单元的语义含义以及在不连续性方面都表现出了一些违反直觉的属性。对抗负例 (adversarial negatives) 的存在似乎与网络达到高泛化性能的能力相矛盾。也确实是这样,虽然这些样例确实不太容易与常规样例区分,但如果神经网络真的泛化很好,怎么会被这些对抗样本所混淆呢?一个可能的解释是,对抗负例集的出现具有极低的概率,因此在测试集中从未(或很少)被观察到,但它却是稠密的(类似于有理数的分布),因此几乎在每一个测试案例的附近都能找到对抗负例。然而,我们对其出现的频率还缺乏深入理解,因此这个问题应该在未来的研究中得到关注。



![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]DETR](https://img-blog.csdnimg.cn/direct/e8df1ed8695749d1b661ff6ad6833838.png)
![[<span style='color:red;'>论文</span><span style='color:red;'>阅读</span>]BEVFusion](https://img-blog.csdnimg.cn/direct/65697d2df3dc47d2a67baf3c2e53c330.png)