目录
一、环境描述
系统环境描述:本教程基于CentOS 8.0版本虚拟机
Hadoop ha 集群环境说明:
机器节点信息:

Spark 集群环境说明:
机器节点信息:

注意: Spark Standalone 模式本身不依赖Hadoop,只是这里我需要使用hdfs,而且集群高可用模式也需要使用到Zookeeper,所以这里我会启动Zookeeper和hdfs,不需要启动Yarn 调度层了,可以不启动Yarn。
二、部署Spark 节点
2.1 下载资源包
Spark 包下载地址:
Index of /dist/spark/spark-3.3.4 (apache.org)
注意:需要和Hadoop体系的版本要保持一致,我这里的Hadoop是3.3.4版本,所以,我的Spark 版本也需要是3.3.4版本。
2.2 解压
tar -zxvf spark-3.3.4-bin-hadoop3.tgz
2.3 配置
可以参考官网,自己跟着官网自己学着部署,官网是最官方的,最正确的方式,官网参考地址:
Spark 独立模式 - Spark 3.3.4 文档 (apache.org)

2.3.1 配置环境变量
# 进入配置文件
vim /etc/profile
# 添加SPARK_HOME环境变量
export SPARK_HOME=/usr/local/spark-3.3.4-bin-hadoop3
2.3.2 修改workers配置文件
#重命名文件
mv workers.template workers
# 进入文件编辑
vim workers
# 添加worker节点
node3
node4

2.3.3 修改spark.env.sh文件
# 进入config目录
cd spark-3.3.4-bin-hadoop3/conf
# 重命名配置文件
mv spark-env.sh.template spark-env.sh
# 修改配置信息
vim spark-env.sh
export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.4/etc/hadoop
export SPARK_MASTER_HOST=master # 因为我这里部署的是HA模式,所以在master节点,这里配置的是master,在node1节点,这里就是node1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8080
export SPARK_WORKER_CORES=4
export SPARK_WORKER_MEMORY=4g
2.3.4 修改spark-defaults.conf
# 进入config目录
cd spark-3.3.4-bin-hadoop3/conf
# 重命名配置文件
mv spark-defaults.conf.template spark-defaults.conf
# 修改配置信息
vim spark-defaults.conf
spark.deploy.recoveryMode ZOOKEEPER
spark.deploy.zookeeper.url node2:2181,node3:2181,node4:2181
spark.deploy.zookeeper.dir /spark
# 开启spark的日期记录功能
spark.eventLog.enabled true
#创建spark日志路径,待会儿要创建
spark.eventLog.dir hdfs://mycluster/spark-logs
spark.history.fs.logDirectory hdfs://mycluster/spark-logs
spark.yarn.jars hdfs://mycluster/work/spark_lib/jars/*
2.4 分发
将配置好的spark-3.3.4-bin-hadoop3 分发到其他服务器
# 分发spark 包
scp -r /usr/local/spark-3.3.4-bin-hadoop3/ node1:/usr/local/
scp -r /usr/local/spark-3.3.4-bin-hadoop3/ node3:/usr/local/
scp -r /usr/local/spark-3.3.4-bin-hadoop3/ node4:/usr/local/
# 分发环境变量文件(记得到各自的服务器执行 source /etc/profile 使配置生效)
scp -r /etc/profile node1:/etc/profile
scp -r /etc/profile node3:/etc/profile
scp -r /etc/profile node4:/etc/profile
2.5 启动服务
2.5.1 启动zookeeper
# 启动zookeeper (需要分别启动)
zkServer.sh start
2.5.2 启动hdfs
start-dfs.sh start

2.5.3 启动spark
# 进入spark命令目录
/usr/local/spark-3.3.4-bin-hadoop3/sbin
# 启动服务
./start-all.sh
# 启动node1的master
./start-master.sh

接着验证一下,启动的服务是不是按照我们配置的那样:
检验下master节点,看下是否有Master进程:

发现有了,那证明主节点启动起来了
接着验证下node3、node4,看下是否有Worker进程:
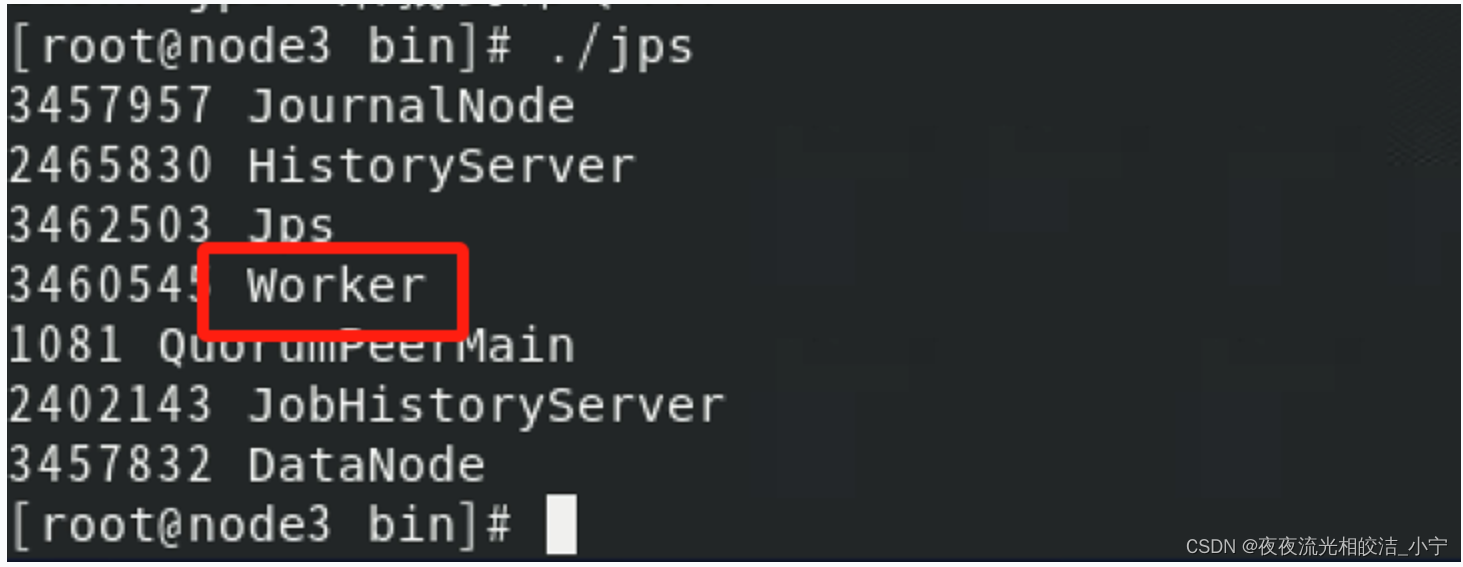

我们从上图中发现,node3,node4节点,分别有Worker进程了,说明集群部署成功了。
最后检查下node1节点,是不是有Master进程:

Ok,我们现在发现已经启动了两个Master进程了,一个在master节点,一个在node1节点。
我们可以通过Spark UI页面看下信息,访问http://master:8080

接着访问http://node1:8080

我们发现,node1节点的状态是standby状态
到此,我们Spark Stanalone模式HA就算部署成功了
2.6 测试
2.6.1 测试HA主备切换
为了验证主备切换的情况,我们可以把活跃(ALIVE)的主节点kill掉,观察之前备用(StandBy)的节点是否会做切换,升级为主节点:
# 查看master进程编号
jps
# kill -9 pid

kill掉了master节点的Master进程,看下是否切换到node1的Master中

从上图中可以看到,Master进程切换到了node1,状态为ALIVE状态,证明HA起到了作用,验证完成。
2.6.2 测试Spark调度和计算功能
# 提交jar包到集群
bin/spark-submit --master spark://master:7077,node1:7077 --class org.apache.spark.examples.SparkPi /usr/local/spark-3.3.4-bin-hadoop3/examples/jars/spark-examples_2.12-3.3.4.jar 100000




从以上图片中我们可以看到,提交的任务进入到了Spark 集群调度中,且已经在运行了,整个部署到此结束。
今天基于Spark3.3.4版本,实现Standalone 模式高可用集群部署的相关内容就分享到这里,可以关注Spark专栏《Spark》,后续不定期分享相关技术文章。如果帮助到大家,欢迎大家点赞+关注+收藏,有疑问也欢迎大家评论留言!