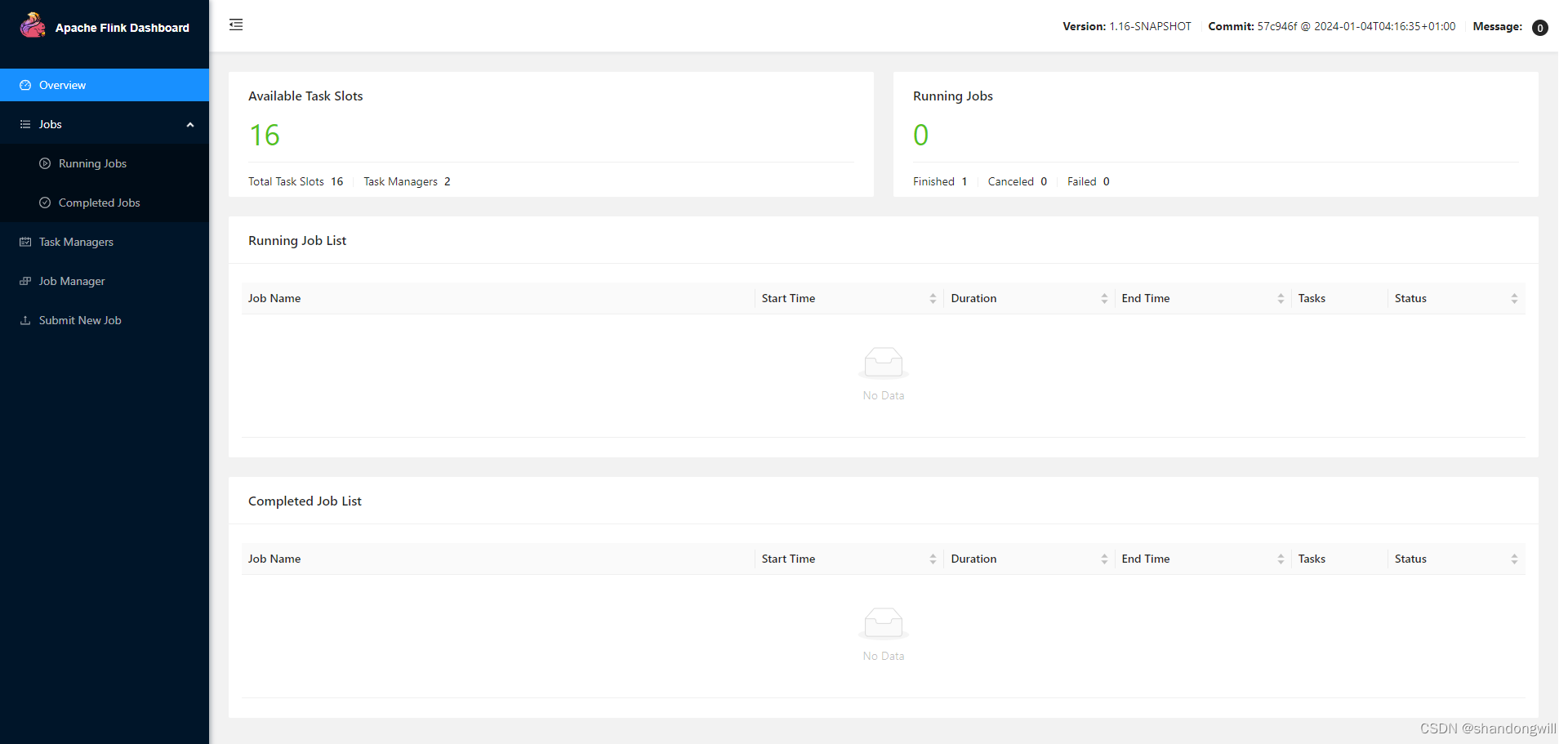
我们了解了flink的一个集群的一个基础架构,包括里面核心的一些组件,比如说job manager,task manager等一些组件的一些主要的一些组成。本节课程开始我们学习flink的一个集群部署模式。首先我们来看一下flink集群部署模式究竟应该有哪一些种类。我们根据两种条件将flink集群部署模是分成三种类型。两种条件究竟是哪两种条件?第一个就是整个根据集群的一个生命周期和它的一个资源隔离不同,我们整个集群的生命周期的话是在我们对定的这样的一个不同的这样的一个模式里面的话,它生命周期有一定的区别。比如说通过session的这种集群模式的话,它其实是共享我们的job manager和task manager,所有提交的job都是在一个runtime里面去执行。Job的销毁以及job的提交,它是不影响我整个集群的一个它的一个启停。
对于另外一种的话叫做poor job的模式。Poor job的这种模式的话,它是独享照manager和task manager。它会为每一个job单独去启动对应的这样的一个集群的一个run time。它的一个启停作业的一个drop的一个启停,它和我们的一个job manager以及task manager的一个生命周期是相绑定的。也就是说job的如果执行完毕了之后,整个的一个集群也是跟着相应的去进行一个停止。
另外一个的话,我们会根据我们的一个main方法,是否执行在客户端,还是执行在我们的一个集群的管理节点,也就是job manage里面。这个过程其实就是我们在1.1版本里面提出的一个新的一个特性,叫做application model。Application的may方法如果运行在我们的一个cluster上面的话,它就是一种application model的一个模式。也就刚才我们在其实上节课里面已经提到了,我们在客户端里面要进行一些比如说job gravy的一些生成,以及may方法的一些执行。这个过程的话,我们在新的版本里面,通过application model就可以把它放在我们的一个cluster上面去执行。这个时候的话,我们每一个application它其实对应的是一个wrong time。而我们的一个每个application里面的话是可以包含多个drop的。
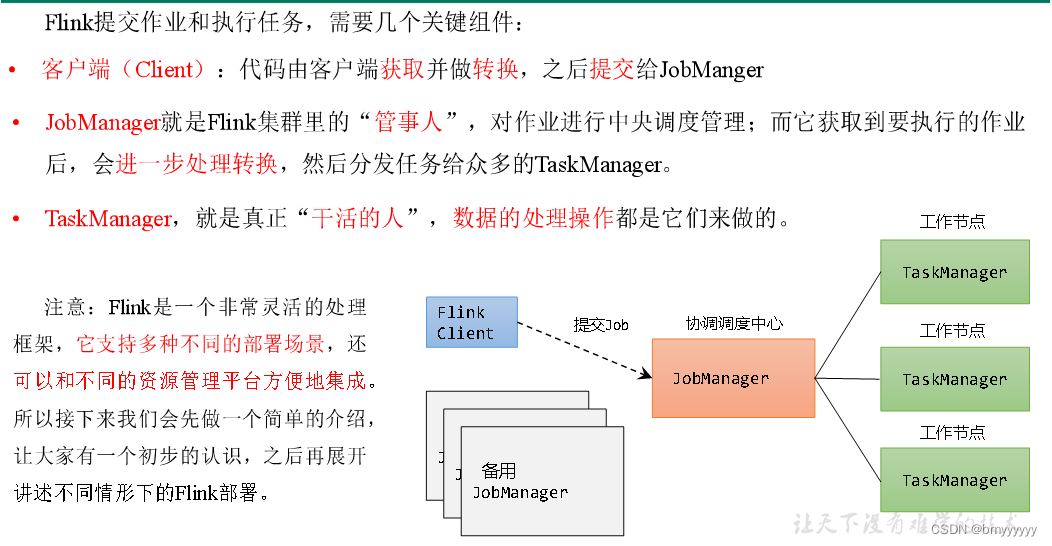
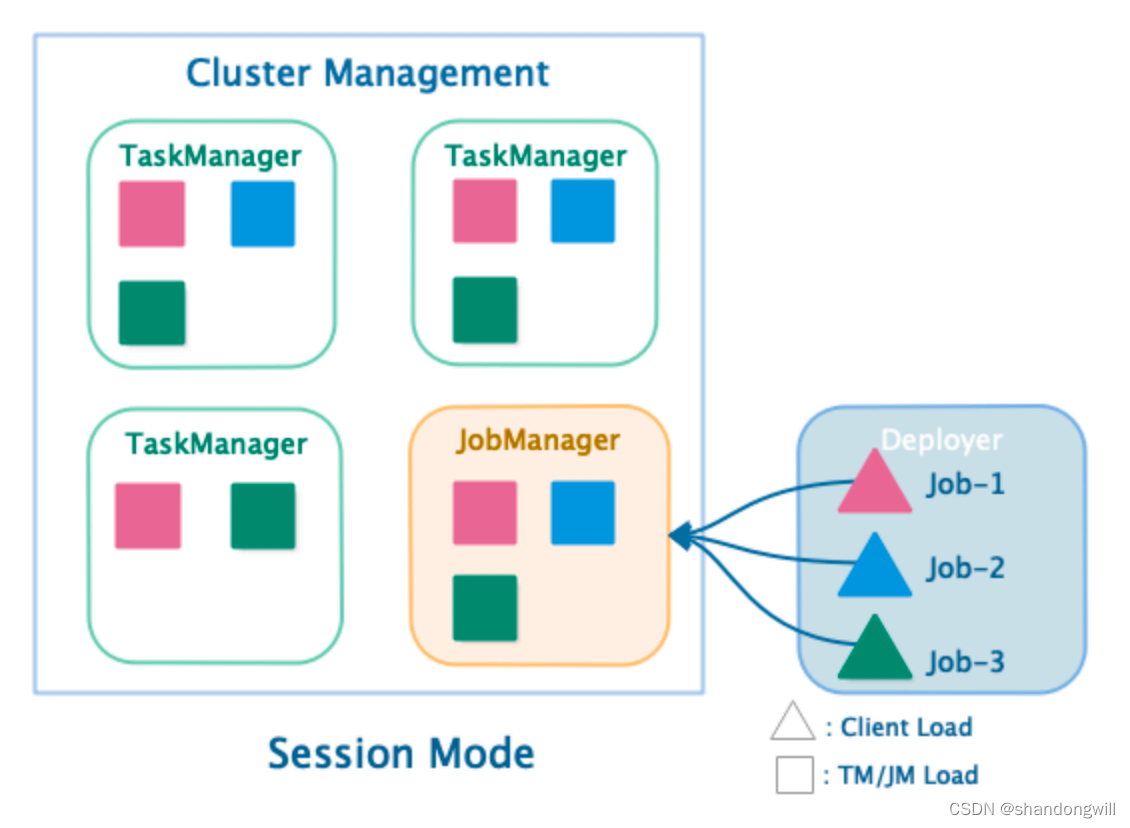
我们首先来看一下session的一个集群的一个运行模式。30N的集群运行模式其实我们刚才已经介绍。它的job manager和task manager其实是共享一套这样的一个集群的一个runtime的。对于我的一个客户端这边去提交不同的一个top。比如说top 1、top 2、top 3。通过客户端的这种方式去提交我们对应的这样的一个同一个这样的一个job manager里面去接收对应不同的这样的一个job。在我们的一个主管理节点,也就是说我们的master节点的话,它会去管理不同的这样的一个drop,然后再去进行协调的一个操作。然后在不同的这样的一个task manager里面去启动对应的这样的一个task的一些执行的一些slot的一些资源。
整个下来的话,它其实是一种session的一种绘画的这种集群模式。共享我们的一个drop manager。然后通过不同的客户端去提交到同一个job manager,同一个这样的一个集群的master节点。然后在我们的task manager里面去进行相应的一个执行的一个过程。这个时候的话,其实可以发现对于我的一个客户端来讲的话,他首先需要去执行相应的一些生成相应的一些drop gravy的对象,以及把对应的这样的一些价包,以及自己的一些包要传递到我们的一个master的一个节点上面去。然后才能在我们的job manager里面去进行一个调度和生成。
我们总结一下,对于我们三省集群里面的话,它其实另一个比较核心的一点就是我这个job manager的一个生命周期的话。它其实不是受我的一个job的一个影响。不管你在上面去提交多少个job,这个job manager他其实始终是处于一个运行的一个过程。运行的一个阶段,除非你把整个的这样的一个集群停止掉,它才会停止我们对应的这样的一个job manager。
另外一个的话,我们来去对比我们的这样的一个session集群的一个模式的一个优点。三省模式的优点的话,它其实可以达到一个集群的一个资源的一个充分共享的一个作用。提升我们整个集群的一个资源利用率。当我作业执行完成了之后,我无需去把我的这样的一个job manager去停掉。另外这个的话,对于我的一个job manager执行过程中的话,它其实也本身也会消耗相应的这样的一个计算资源。我们无需去为每一个job都要去生成一套新的一套集群。所以说这样的模式的话,像相对去对资源利用率的一个提升上面有非常大的一个帮助。
另外一个的话,对于我用户去提交不同的这样的一个作业来讲的话。它在flink session的一个集群里面进行一个管理和运维,相对来说比较简单一点。如果是不借助于这样的一个session的一种模式的话,将对应的每一个job去依托于我们的一个class manager进行管理的话,我们整个的一个运维的一个过程和它的一个成本会有相对比较高的一个提升。
另外一个三个模式它的一个运行的一个缺点是什么?第一个就是我们的一个集群的一个资源隔离相对较弱一点。对于我照不去提交,比如说我们如果top 1赵P2提交上来,集群的整个的一个资源用完了,那么job 3可能就是无法去提交到。即使我们外围的这样的一个集群的一个资源管理器,比如说ER或K8S还有额外的一些资源。但是这种情况下可能也会导致我的一个作业无法去执行的这样的一种情况。
另外一种的话就是刚才其实提到如果就是非negative部署的这种模式。Negative部署的话后面我们会有单独的章节进行讲解。它的一个特点就是我们的task manager是在我们启动的时候,它已经固定了。比如说我启动三个task manager,会在事先启动我对应的集群的时候,他已经把对应的这样的一个task manager启动起来,然后再去申请对应的slot资源。对于我这种情况的话,session模式的话,它这样的一个TM不易扩展的话,那我们的整个集群的一个计算资源的一个伸缩性就会相对来说比较弱一点。但是如果集群是negative这种模式的话,那么集群的一个资源的一个伸缩性的话,这一块的问题倒可以去解决。
另外一个的话其实就是叫做poor job的模式。Poor job的模式从名称上面其实就知道,就是我们每个job的话相当于说自己有一套自己的session的一个集群。也就是自己有一套这样的一个wrong time的一个集群。
每个job单独去共享我们的一个job manager。比如说提当一个drop上来了之后,它有单独的这样的一个job manager去启动,然后再去启动对应的task manager。Task manager的话也是跟我的每个job之间相互绑定,它也不会形成对应的共享的一个机制。比如说另外一个drop去提上来了之后,它也会去启动一个新的job manager,然后再去启动对应的task manager,在和job manager之间进行相互的一个通信和调度。同理其中第三个的话,我们还会启动第三个的task manager。整个下来的话,我们在一套集群资源管理器上面看到就会启动很多个这样的一个套job manager的一个管理节点,以及很多个这样的一个task manager节点。
这个里面的话,其实我们可以看得到,对于我提交的不同job申请的资源的会指定它的一个task manager里面的一些slot的一些数量。这个可以根据每个job的的不同申请的不同,它会选择启动不同的这样的一个task slot,这样的一个资源的一个卡槽。所以这个其实也是一个特点。
对于pull job的这种模式的话,它的一个另外一个比较大的一个特点就是我们的一个job的一个生成和提交的这个过程的话,它是跟整个top的一个生命周期是绑定的。我们比如说如果top 1执行完毕了之后,那么top 1对应的这样的一个job manager以及它的一个task manager的一些节点的话,全部都会进行一个释放和回收。然后当你再去提交一个,再再去启动对应的这样的一个资源,这个的过程的话,其实是我们的一个生命周期,会跟我们的一个job进行绑定。
对于poor job的这种部署模式,它的一个优势是什么?Job和job之间的话,资源大家其实可以看得到,其实是一个相互隔离的一个过程。对于我的一个每一个job之间,它其实都是独享对应的这样的一些计算资源。而像这样的话,资源可以进行相互这样的一个充分的一个隔离。另外一个的话是我们刚才也提到了这个task里面task manager slot一个资源的数量的话,可以根据我不同的job进行指定。
另外一个的话对于我们pull job模式的话,它也有自己的一些劣势。比如说我们那个资源浪费就会比较严重。对于我每提交一个job上来的话,它就会有对应的这样的一个集群的一个wrong time的一个生成。这种的话对于我job manager也会需要消耗相应的这样的一个计算资源。
另外一个的话,我们的一个job提交的方式的话,完全去提交到我们的class management上面去。可能在我们比如说在一二的队列里面的话,会有很多个job的一些对应的一些job manager的一些管理。对于这种管理的模式的话,可能会完全去依托于我们的一个cluster management进行一个管理。这种的话其实会带来一些管理上面的一些复杂度的一些提升。
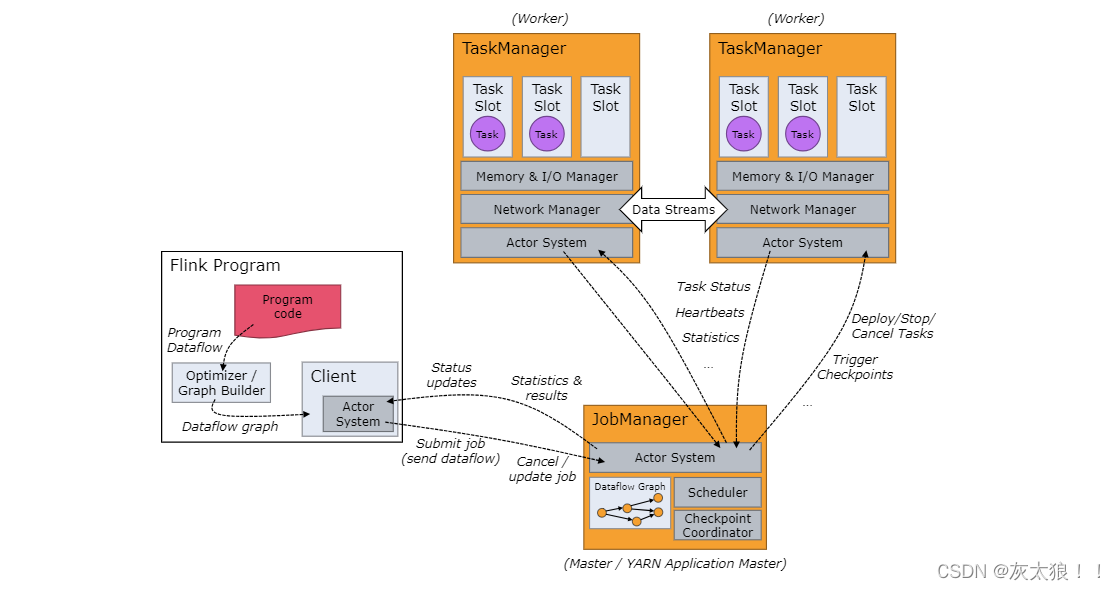
另外一种的话其实。是我们会发现在我们整个session和poor job类型的这样的一个集群部署的时候,它都会面临一个这样的一个问题。比如说我们都会有这样的一个模式,比如说我们用户要去提交一个自己的作业的话,它首先需要去下载对应的这样的一个application的一些dependency。比如说首先你必须得去下载相应的这样的一些依赖包括自己的一些本地的一些客户端的一些安装,以及我们的一个application的一些价包的一些上传,传递完毕了之后,下面一步的话是在我们客户端去执行相应的main方法,去生成对应的job graf的一个对象。这个过程的话,其实会相对来说比较消耗我们本地客户端的一些进程的一些资源,就是包括一些CPU的一些资源。
另外一个的话,我们会把对应的一些相应的一些用户的一些包,每次都要去通过summe的方式去提交到我们的一个集群上面去运行。如果这个用沪提交的这样的一个架包会非常大,比如说十几二十兆或几百兆的这样的一个包。每次如果进行这样的一个作业的一个提交的话,它就会占用我们这样的一个带宽。也就是说clients会跟我们这个照manager之间这样的一个网络上面会进行非常大的一个网络消耗,带宽的一个消耗。
另外一个的话,生成job graph的话,它其实本身也会消耗本机的一些CPU的一些资源。另外一个的话就是说当我如果是在通过同一个客户端去提交不同的这样的一个job到我们的集群上面运行的时候。这种任务多的情况下,它会势必会导致我的这样的一个客户端的压力会非常大。这样的话其实会造成我们的这样的一个运行的一个过程。它其实会有一个非常大的一个稳定性的一个不足。
另外一个的话,其实我们每次需要去提交这样的一个价包的话。其实如果是提交了多了的话,它其实我们每一次提交的这样的一个任务,它其实是一个blocking的。也就是说我们是一个阻塞的。它其实后面的这样的一个用户再去提交的话,它其实是一个需要进行相应的这样的一个排队等待的一个过程。对于我们如果是一种,比如说是一个流式的这样的一个流平台的这样类似于这样的一个项目的话。比如说不同的一些用户如果去提交对应的这样的一个作业的话,它就会造成了这样的一个大量的大面积的一个排队和等待的一个过程。
对于这种情况有没有一个更好的这种方式去解觉?我们其实社区里面就提出了一个方式,就是说为什么我们不能把这样的一个在客户端里面进行执行的一个过程去转嫁到我们的一个集群的一个job manager里面去执行。这样的话,我们可以去释放我们一个本地客户端的一个压力。最终在我们的一个客户端里面,只需要去简单的负责一个命令的一个提交,以及作业的一个命令的一个下发,然后同时在等待我们的一个job运行的一个结果。其实就可以这样的话就可以减轻我们整个client的一个压力。我们这个地方的话,其实就是讲到了另外一种新的在1.1版本提出来的一种另外一种集群的一个运行的一个模式,叫做application model。
刚才已经提到了,在我们客户端这边的话,只需要去负责相应的一些命令的一些提交即可。对应的这样的一些job的一些job graph的生成,以及架包的一些下载和上传。这些工作的话完全就交给我们整个集群进行一个操作。比如说对于drop py的一个生成的话,也是在我们job manager里面执行相应的一些魅方法。然后把妹方法里面去抽取对应的这样的一个drop graph的一个对象。对于我的这样的一个作业所依赖的一些价包的话,都可以通过类似于分布式的HDFS的这种分布式的这样的一种存储,直接去获取对应的这样的一个dependency的一些包。然后去拉到我们的这样的一个集集群里面去运行相应的这样的一个作业。
对于我招manager里面的话,首先会去到我们的HDFS去获取这些依赖的一些包。然后去把整个的一个作业进行一个生成job graph。然后到他的一个执行,然后到他的一个调度,都是在我们的这样的一个job manager的管理节点里面进行相应的这样的一个操做。
对于我们的客户端来讲的话,它其实并没有太大的这样的一些负载。客户端的负载的话,全部都转嫁到我们的这样的一个集群的job manager里面去。这样带来的一个好处是什么?第一个就是我用户这边的话,无需去每次事先需要把我的这样的一些依赖的一些价包去需要去传到我的运营的这样的一个集群。它可以去避免我们在客户端和我们的一个集群之间的这样的一个网络的一个带宽的上面进的一个大量的一个消耗。对于我的一个客户端来讲的话,它可以去有效去降低我的一个带宽消耗以及客户端的一个负载。
在我们这样的一个application model里面的话,它可以去实现一个application的级别的一个资源隔离。也就是说我们每次提交的话,它会再切分成一个这样的一个application的一个级别出来。Application的话,它里面可以去提交不同的一个drop。每个application的这样的一个过程的话,其实跟我们的一个poor job的一个集群的这样的一个运行模式是一样的。它也有自己的相应的启动对应的这样的一些task manager。另外一个application的话,可能也是去启动一个这样的一个runtime,一个集群。在我们的一个application里面的话,可以去提交多个这样的一个drop的一个资源。
另外一个的话,我们可以看到application model它其实也有相应的一些缺点。比如说这个功能太轻,可能还没有经过一些生产的一些验证。另外一个的话,他可能仅支持亚和carbonate这样两套class management的上面的一个提交。对于像R上面的话,可以通过HDFS上面直接去获取我们的一些依赖的一些包。但对于carbonate的话,我们需要去事先去构建相应的一个镜像。把对应的这样的一个user jar application jar去达到我们的一个镜像里面了之后,再去通过application model去进行一个运行。整个的话其实会有相应的这样的一个编译和镜像构建的一个过程。所以说这一块的话对于后面社区的一个不断的跟进的话,这一块的功能点的话会进行相应的一个优化和一些提升。
通过本节的学习的话,我们了解了flink的不同的集群的一个运行模式。比如说session or job以及application model。我们通过对比不同的这样的一个运行模式,了解每种运行模式的一个优点和一些它的一些缺点。下一节课程的话,我们会讲到flink能够去支持哪一些cluster management。也就是说我们的集群管理器上面去运行我们的flink的不同的这样的一个session或者说per job,以及我们的一个application model的一些这样的一些flink集群。
































![代码解读 | Hybrid Transformers for Music Source Separation[07]](https://img-blog.csdnimg.cn/direct/db7faaf7756b40c4b09a49349b75e485.png)

