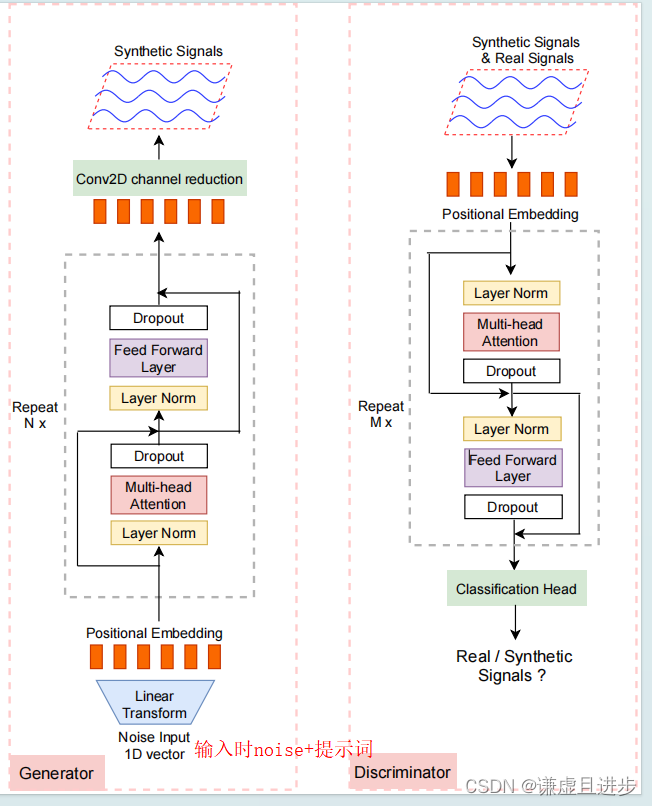
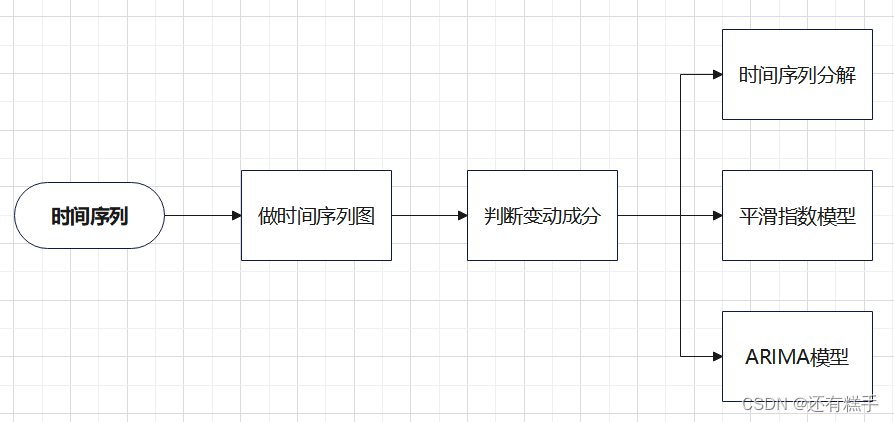
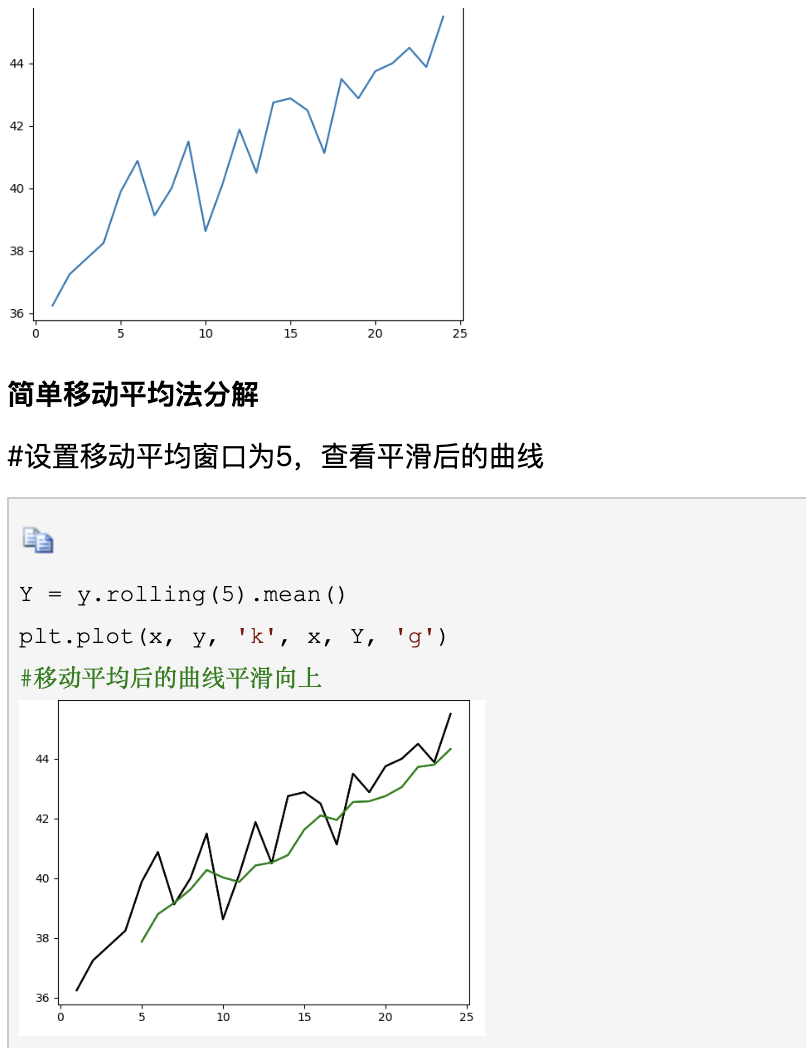
需要的同学私信联系,推荐关注上面图片右下角的订阅号平台 自取下载。
随着时间序列问题的复杂度逐渐提高,研究者们开始关注非线性和多变量问题。近年来,时间序列领域涌现出众多基于深度学习的先进框架,如Transformer、GNN、TCN、BERT等,这些模型借助注意力机制等创新技术,能够更加高效地捕捉复杂序列数据中的依赖关系。基于时间序列领域的标准权威数据集,以及众多实际应用场景,这些模型已经展现出了卓越的性能和成果。因此本文整理了一份超完整的时间序列论文标准数据集,共包含5大类时间序列研究方向,21+论文标准数据集,助力时间序列领域的研究与创新。来吧,涨涨知识~
1. 长期时间序列预测数据集
2. 短期时间序列预测数据集
3. 时间序列异常检测数据集
4. 时间序列分类数据集
5. 时间序列填补数据集
01
—
长期时间序列预测数据集
1.1 electricity
【数据简介】包含321个客户的用电量数据。
【数据情况】数据集没有丢失的值,每1H的数值以kW为单位,数据时间段为2016/07/01 2:00—2019/07/02 1:00,共26304条数据。所有时间标签都以葡萄牙小时为单位。所有天都有24点数据(24*4)。每年3月的时间变化日(23个小时),凌晨1点到凌晨2点之间的值对所有点都为零。每年10月的时间变化日(25个小时),凌晨1点到2点之间的值合计两个小时的消耗量。
【字段说明】数据集使用.csv格式保存,包含322个数据字段,具体如下:
date:整小时的时间戳,
0:用户id=0
1:用户id=1
......
319:用户id=319
OT:最后用户id
每日的用电量有一定的周期性和季节性,图中只画出前10个用户的electricity曲线。
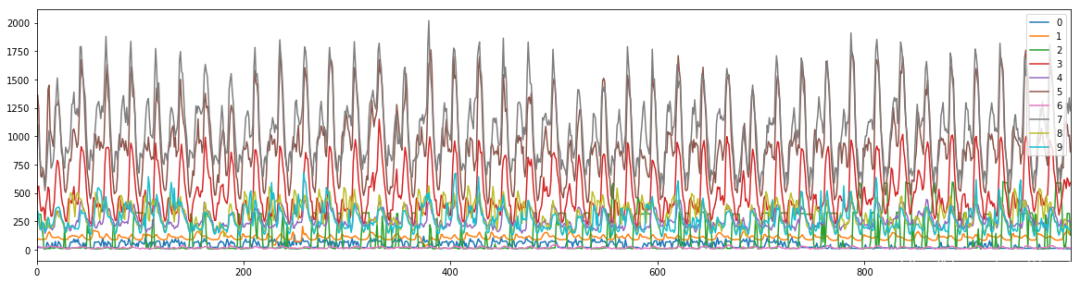
1.2 ETT-small
【数据背景】电力分配问题是电网根据顺序变化的需求管理电力分配到不同用户区域。但要预测特定用户区域的未来需求是困难的,因为它随工作日、假日、季节、天气、温度等的不同因素变化而变化。现有预测方法不能适用于长期真实世界数据的高精度长期预测,并且任何错误的预测都可能产生严重的后果。因此当前没有一种有效的方法来预测未来的用电量,管理人员就不得不根据经验值做出决策,而经验值的阈值通常远高于实际需求。值得注意的是,变压器的油温可以有效反映电力变压器的工况。为了解决这个问题,相关研究团队建立了一个平台并收集了2年的数据,可以用它来预测电力变压器的油温并研究电力变压器极限负载能力。
【数据情况】所有的数据都经过了预处理,这些数据的时间跨度为2016年7月到2018年7月。数据集含有2个电力变压器(来自2个站点)的数据,每个数据点每分钟记录一次(用m标记),它们分别来自中国同一个省的两个不同地区,分别名为ETT-small-m1和ETT-small-m2。每个数据集包含2年*365天*24小时*4=70080个数据点。此外,还提供一个小时级别粒度的数据集变体使用(用h标记),即ETT-small-h1和ETT-small-h2。
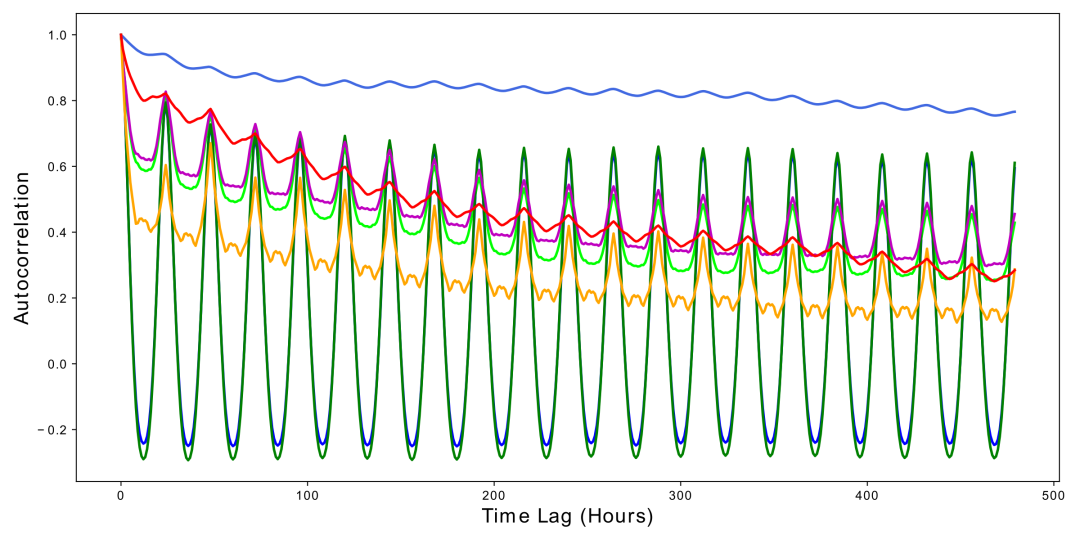
【字段说明】数据集使用.csv格式保存,共包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载值,其中第一行是数据头,包括了"HUFL"、"HULL"、"MUFL"、"MULL"、"LUFL"、"LULL"和"OT",每一列的详细意义如下:

1.3 exchange_rate
【数据简介】收集了1990年至2016年8个国家的每日汇率数据。
【数据情况】数据集没有丢失值,每1D的数值颗粒度,数据时间段为1990/01/01 00:00—2010/10/10 00:00,共7588条数据,包含澳大利亚、英国、加拿大、瑞士、中国、日本、新西兰和新加坡等8个国家的每日汇率值。
【字段说明】数据集使用.csv格式保存,包含9个数据字段,具体如下:
date:1D颗粒度的时间戳
0:澳大利亚汇率
1:英国汇率
2:加拿大汇率
3:瑞士汇率
4:中国汇率
5:日本汇率
6:新西兰汇率
OT:新加坡汇率
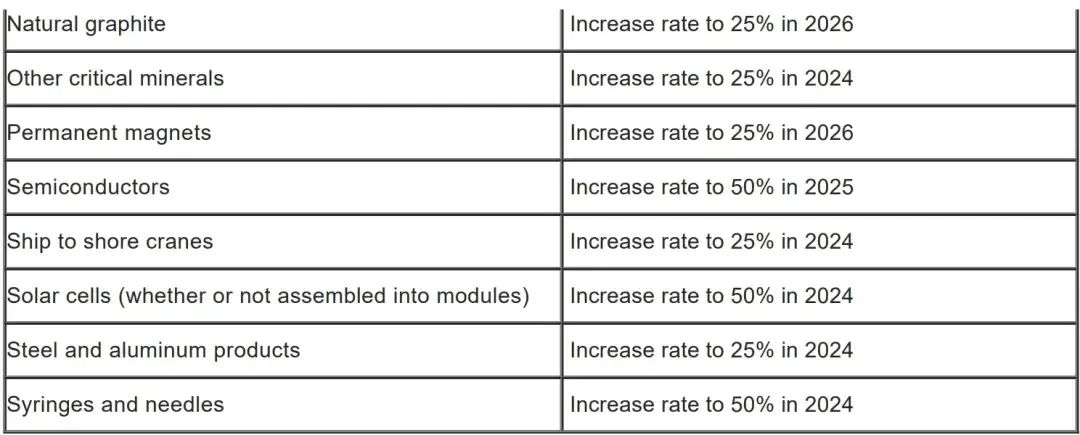
1.4 illness
【数据简介】美国疾病控制和预防中心每周流感统计数据。
【数据情况】数据集没有丢失值,每周的数值颗粒度,数据时间段为2022/01/01 00:00—2020/06/30 00:00,共966条数据,包括2002年至 2021年美国疾病控制和预防中心每周数据,数值描述了患有流感疾病的患者与患者数量的比率。
【字段说明】数据集使用.csv格式保存,包含322个数据字段,具体如下:
date:1周颗粒度的时间戳
WEIGHTED ILI:加权比率
UNWEIGHTED ILI:非加权比率
AGE 0-4:0-4岁患者数量
AGE 5-24:5-24岁患者数量
ILITOTAL:患有流感疾病的患者总数
NUM. OF PROVIDERS:提供人数
OT:患者数量
1.5 traffic
【数据简介】旧金山高速公路传感器记录的交通统计数据。
【数据情况】数据集没有丢失值,每1H的数值颗粒度,数据时间段为2016/07/01 02:00—2018/07/02 01:00,共17544条数据,包含 2015 年至 2016 年旧金山高速公路传感器记录的每小时数据,数值描述了不同传感器测量的道路占用率(介于0和1之间)。
【字段说明】数据集使用.csv格式保存,包含863列数据字段,具体如下:
date:1H颗粒度的时间戳
0:道路id=0
1:道路id=1
......
860:道路id=860
OT:最后道路id
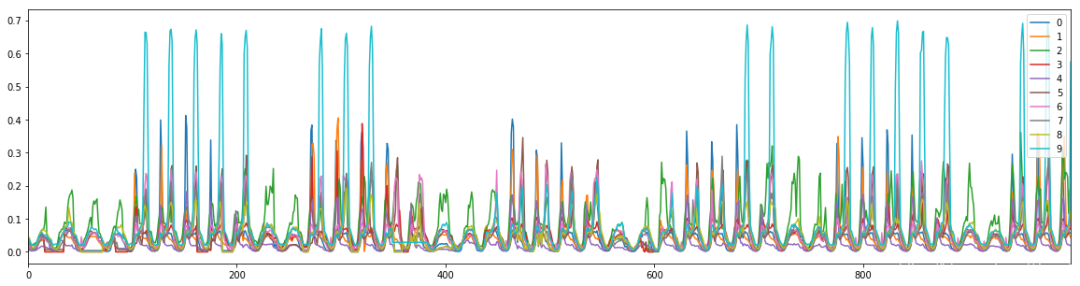
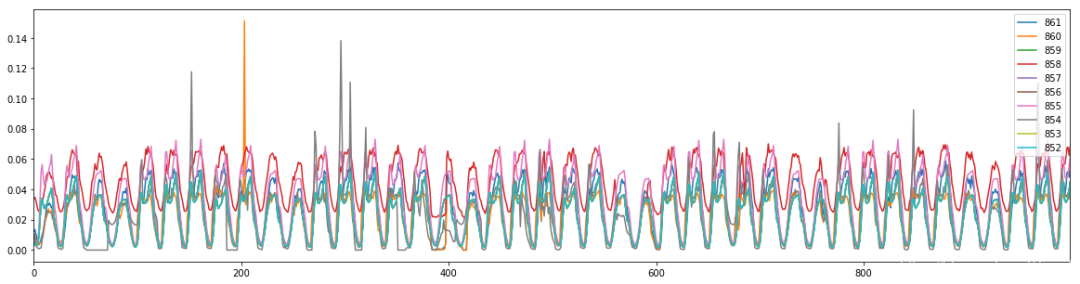
1.6 weather
【数据简介】Jena Climate时间序列数据集中基于多变量的历史气象数据,对气温变化的趋势进行预测
【数据情况】数据集没有丢失值,每10min的数值颗粒度,数据时间段为2020/01/01 00:10—2021/01/01 00:00,共52696条数据,包括2020年至 2021年Weather Station, Max Planck Institute for Biogeochemistry in Jena, Germany的天气要素数据,包括温度、压力、湿度等14个特征指标,每10分钟记录一次。
【字段说明】数据集使用.csv格式保存,主要包含以下16个数据字段:
date:10min颗粒度的时间戳
p(mbar):大气压力
T (degC):摄氏温度
Tpot (K):开尔文温度
Tdew (degC):露点温度,露点是衡量空气中水分绝对量的指标
rh (%):相对湿度
VPmax (mbar):饱和蒸汽压
VPact (mbar):蒸汽压力
VPdef (mbar):饱和水汽压差
sh (g/kg):比湿度
H2OC (mmol/mol):水蒸气浓度
rho (g/m ** 3):大气密度
wv (m/s):风速
max. wv (m/s):最大风速
wd (deg):风向
rain (mm):降雨量
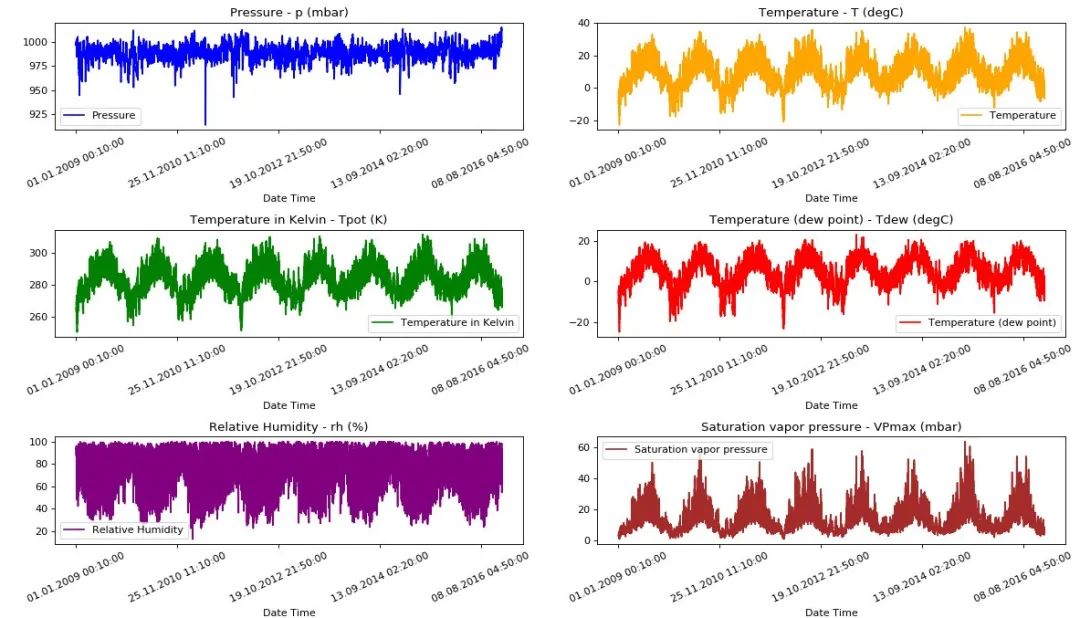
02
—
短期时间序列预测数据集
2.1 M4 Dataset
【数据简介】第四届Makridakis预测竞赛的多个时间序列集合
【数据情况】M4数据集是时间序列常用的一个数据集,该数据集由年度、季度、月度和其他(每周、每日和每小时)数据的时间序列组成,并分为训练和测试集。M4数据集的特点包括:
规模庞大,包含来自不同来源的多种类型的时间序列数据;
数据覆盖了广泛的领域,包括经济、金融、商业、社会、环境等;
数据质量良好,经过仔细清理和验证;
M4 数据集已被广泛用于时间序列预测研究。它为研究人员提供了一个宝贵的资源,可以用于开发和评估新的预测方法。
【数据目录】数据集使用.csv格式保存,主要包含以下16个数据文件:
M4-info.csv:数据集信息,包含各个子数据集对应的M4id-对象ID、category-数据领域、Frequency—数据频率、Horizon—数据长度、SP—数据颗粒度和StartingDate—数据起始时间
hourly-train.csv:小时颗粒度训练集
hourly-test.csv:小时颗粒度测试集
Daily-train.csv:日颗粒度训练集
Daily-test.csv:日颗粒度测试集
Weekly-train.csv:周颗粒度训练集
Weekly-test.csv:周颗粒度测试集
Monthly-train.csv:月度训练集
Monthly-test.csv:月度测试集
Quarterly-train.csv:季度训练集
Quarterly-test.csv:季度测试集
Yearly-train.csv:年度训练集
submission-Naive2.csv:结果示例
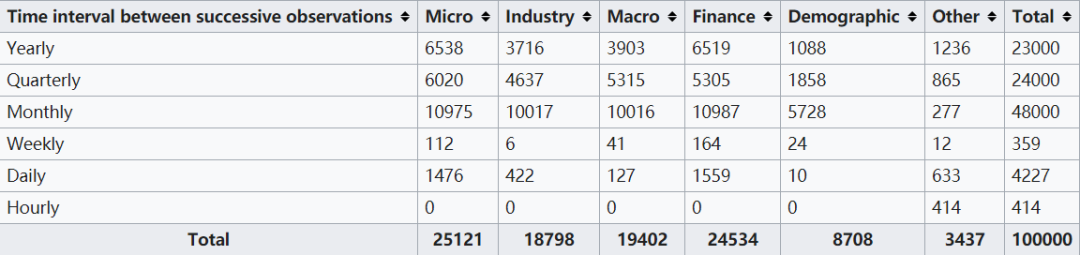
03
—
时间序列异常检测数据集
3.1 PSM
【数据简介】服务器节点时序异常数据
【数据情况】数据集没有丢失的值,共包含132481条数据。PSM数据集是从eBay公司的多个应用程序服务器节点内部收集的,有13周的训练数据和8周的测试数据。
【数据目录】数据集使用.csv格式保存,主要包含以下3个数据文件:
train.csv:训练集
train_label.csv:训练集标签
test.csv:测试集
【字段说明】包含以下24个数据字段:
timestamp:时间戳
feature_0:特征1
feature_1:特征2
......
feature_24:特征25
label:标签,0表示无异常,1表示有异常(仅训练集)
3.2 SMAP
【数据简介】NASA航天器系统遥测异常数据
【数据情况】原始数据代表了真实的航天器遥测数据和来自土壤湿度主动-被动卫星(SMAP)和火星好奇号漫游者(MSL)的异常情况,所有数据都是关于时间的匿名数据,所有遥测值都是根据测试集中的最小值/最大值在(-1,1)之间预先缩放的。信道ID也被匿名化,但第一个字母表示信道的类型(P=功率,R=辐射等)。模型输入数据还包括一个热编码信息,关于特定航天器模块在给定时间窗口内发送或接收的命令。数据中不包括与命令的时间或性质相关的识别信息。数据集具有25个维度,其中训练集包含未标记的异常。
【数据目录】数据集使用.npy格式保存,主要包含以下3个数据文件:
SMAP_train.npy:训练集
SMAP_test.npy:测试集
SMAP_test_label.npy:测试集标签
3.3 SMD
【数据简介】服务器机组时序异常数据
【数据情况】SMD(服务器机组数据集)是一个新的为期5周的数据集,从一家大型互联网公司收集得到,该数据集包含3组实体。SMD由28台不同机器和38个传感器的5周数据组成,前5天仅包含正常数据,在最后5天间歇性注入异常数据。28台机器数据对应的28个子集应分别进行训练和测试。对于这些子集中的每一个子集,将其划分为两个长度相等的部分,用于训练和测试,并提供了一个点是否为异常的标签,以及每个异常的维度。
【数据目录】数据集使用.npy格式保存,主要包含以下3个数据文件:
SMD_train.npy:训练集
SMD_test.npy:测试集
SMD_test_label.npy:测试集标签,它表示一个点是否是异常。
3.4 SWaT
【数据简介】水处理传感器时序异常数据
【数据情况】数据时间段为2015/12/22 04:30—2015/12/28 09:59:59,在11天内从具有51个传感器的按比例缩小的水处理试验台收集的网络流量以及所有传感器数据。使用不同的攻击方法注入了41个异常,而在前7天里只生成了正常数据,最后4天内注入异常数据,已经对数据进行了异常/正常的标记。
在版本0中,当工厂排空储水箱30分钟时,开始记录数据。一般来说,在ICS环境中,这是正常操作之外的维护的一部分。由于这种排水,即使没有水流入/流出,LIT101数据的前30分钟也会发生变化。版本1是通过删除前30分钟的数据从版本0派生而来的。
【数据目录】数据集使用.csv和.xlsx格式保存,包含以下6个数据文件:
SWaT_Dataset_Attack_v0.xlsx:异常数据
SWaT_Dataset_Normal_v1.xlsx:正常数据
swat_raw.csv:版本0原始数据
swat_train.csv:版本0训练数据
swat2.csv:版本1原始数据
swat_train2.csv:版本1训练数据
04
—
时间序列分类数据集
4.1 EthanolConcentration
【数据简介】乙醇浓度光谱时序数据
【数据情况】EthanolConcentration是44个不同的真实威士忌瓶中的水和乙醇溶液的原始光谱数据集。乙醇的浓度分别为35%、38%、40%和45%。苏格兰威士忌的最低法定酒精含量为40%,许多威士忌都能保持这种酒精浓度。生产商必须确保其烈酒中的酒精浓度与标签上的报告紧密相关。
时序分类问题是确定任意瓶子中样品的酒精浓度。数据的排列使得每个实例由同一瓶和同一批溶液的三个重复读数组成。生产每种浓度(批次)的三种溶液,并对每个瓶+批次组合进行三次测量。每个读数都包括被拿起的瓶子,放置在光源和分光镜之间,以及保存的光谱。在1秒的积分时间内,在所使用的单个StellarNet BLACKComet SR光谱仪的最大波长范围(226nm至1101.5nm,采样频率为0.5nm)上记录光谱。
除了避免在瓶子上贴标签、压花和接缝外,没有特别尝试为每个单独的瓶子获得最干净的读数,也没有为每个重复读数精确复制通过瓶子的确切路径。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
EthanolConcentration_TRAIN.ts:训练集
EthanolConcentration_TEST.ts:测试集

4.2 FaceDetection
【数据简介】面部图像时序数据
【数据情况】数据来自2014年的Kaggle比赛。问题是基于独立于被摄体的MEG来确定被摄体是否已经被显示了面部图片或加扰图像。数据集仅为比赛中的训练数据,按患者分为10名训练受试者(受试者01至受试者10)和6名测试受试者。这些数据不能合理地随机重新采样。
每个患者大约有580-590次试验,提供5890次训练试验和3524名受试者。每次试验包括1.5秒的MEG记录(在刺激开始前0.5秒开始)和相关类别标签Face(类别1)或Scramble(类别0)。数据被下采样到250Hz,并在1Hz进行高通滤波,每个通道给出62个观测值。对于每个试验,记录306个时间序列,306个通道中的每个通道一个时间序列。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
FaceDetection_TRAIN.ts:训练集
FaceDetection_TEST.ts:测试集

4.3 Handwriting
【数据简介】手写UCR时序数据
【数据情况】数据来自受试者书写UCR创建的字母表中的26个字母时,从智能手表上获取的运动数据集。数据包含150个训练用例和850个测试用例,有6个维度分别为3个加速度计值和3个陀螺仪读数。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
Handwriting_TRAIN.ts:训练集
Handwriting_TEST.ts:测试集

4.4 Heartbeat
【数据简介】心音记录时序数据
【数据情况】数据来源于2016年PhysioNet/CinC挑战赛。心音记录来自世界各地的几个贡献者,在临床或非临床环境中收集,来自健康受试者和病理患者。心脏的声音记录是从身体的不同位置收集的。典型的四个位置是主动脉区、肺区、三尖瓣区和二尖瓣区,但可能是九个不同位置之一。声音分为两类:正常和异常。
正常记录来自健康受试者,异常记录来自确诊为心脏病的患者。这些患者患有多种疾病,但通常是心脏瓣膜缺陷和冠状动脉疾病患者。心脏瓣膜缺陷包括二尖瓣脱垂、二尖瓣反流、主动脉瓣狭窄和瓣膜手术。患者的所有记录通常被标记为异常。健康受试者和病理患者都包括儿童和成人。
每段录音都被缩短为5秒,然后创建每个实例的光谱图,窗口大小为0.061秒,重叠70%。该多变量数据集中的每个实例被布置为使得每个维度都是来自频谱图的频带。正常和异常两类分别为113级和296级。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
Heartbeat_TRAIN.ts:训练集
Heartbeat_TEST.ts:测试集

4.5 JapaneseVowels
【数据简介】UCI档案时序数据
【数据情况】数据来源于UCI。记录了9名讲日语的男性说元音“a”和“e”。将“12度线性预测分析”应用于原始记录,以获得具有12个维度的时间序列,最初的长度在7到29之间。在这个数据集中,实例被填充到最长的长度29。
分类任务是预测说话者。因此,每个实例都是一个转换的话语,12*29个值,附带一个类标签,[1…9]。给定的训练集由每个说话者的30个话语组成,但测试集基于时间和经验可用性的外部因素具有不同的分布,每个说话者有24到88个实例。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
JapaneseVowels_TRAIN.ts:训练集
JapaneseVowels_TEST.ts:测试集

4.6 PEMS-SF
【数据简介】旧金山湾区高速公路车道占用率数据
【数据情况】数据描述了旧金山湾区高速公路不同车道的占用率,介于0和1之间。测量时间为2008年1月1日至2009年3月30日,每10分钟采样一次。将该数据库中的每一天视为一个维度为963(在整个研究期间持续运行的传感器数量)、长度为6 x 24=144的单一时间序列。从数据集中删除了公共假日,以及两天的异常(2009年3月8日和2008年3月9日),其中所有传感器在凌晨2:00至3:00之间静音。
生成了440个时间序列的数据库。任务是将观察到的每一天分类为一周中正确的一天,从周一到周日,例如用{1,2,3,4,5,6,7}中的整数标记它。每个属性描述了在一天中的给定时间戳,由测量站记录的捕获器位置的占用率(在0和1之间)的测量。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
PEMS-SF_TRAIN.ts:训练集
PEMS-SF_TEST.ts:测试集

4.7 SelfRegulationSCP1
【数据简介】皮层慢电位时序数据
【数据情况】来自于图宾根大学提供的皮层慢电位的自我调节时序数据集。实验数据取自一名健康受试者,受试者被要求在电脑屏幕上上上下移动光标,同时测量他的皮层电位。在录音过程中,受试者收到了其缓慢皮层电位(Cz-Mastodes)的视觉反馈。皮层阳性导致光标在屏幕上向下移动。皮层负性导致光标向上移动。每次试验持续6秒。在每次试验过程中,任务都会在屏幕顶部或底部突出显示目标,以指示从第0.5秒到试验结束的消极或积极。视觉反馈从第2秒到第5.5秒。每次试验只有3.5秒的间隔时间用于训练和测试。256Hz的采样率和3.5s的记录长度导致每次试验每个通道896个样本。
数据由268个试验组成,在两个不同的日子记录并随机混合。总共268个试验中的168个来自第1天,其余100个试验来自第2天。每个实例有六个维度(上面的EEG通道),长度为896。类别标签是消极或积极的。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
SelfRegulationSCP1_TRAIN.ts:训练集
SelfRegulationSCP1_TEST.ts:测试集

4.8 SelfRegulationSCP2
【数据简介】皮层慢电位时序数据
【数据情况】来自于图宾根大学提供的皮层慢电位的自我调节时序数据集。数据取自一名人工呼吸的ALS患者,受试者被要求在电脑屏幕上上上下移动光标,同时测量他的皮层电位。在录音过程中,受试者接受了其慢速皮层电位(Cz-Mastodes)的听觉和视觉反馈。皮层阳性导致光标在屏幕上向下移动。皮层负性导致光标向上移动。每次试验持续8秒。在每次试验中,从每次试验的第0.5秒到第7.5秒,通过屏幕顶部(消极)或底部(积极)的高亮度目标来视觉和听觉呈现任务。此外,任务(向上或向下)在第0.5秒发出声音。视觉反馈是从秒2到秒6.5呈现的。每次试验只有4.5秒的间隔时间用于训练和测试。256Hz的采样率和4.5s的记录长度导致每次试验每个通道1152个样本。
测试数据是在训练数据(当天)之后记录的,180个试验属于0类或1类。请注意,尚不清楚此数据集中是否包含对分类任务有用的任何信息,当前最好的错误率为45.5%。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
SelfRegulationSCP2_TRAIN.ts:训练集
SelfRegulationSCP2_TEST.ts:测试集

4.9 SpokenArabicDigits
【数据简介】声音时序数据
【数据情况】数据集取自UCI存储库,来源于声音,来自8800个(10个数字x10个重复x88个说话者)时间序列的数据集。
13个频率倒谱系数(MFCC)取自年龄在18岁至40岁之间的44名男性和44名女性阿拉伯语母语者,代表10个阿拉伯语口语数字。数据库上的每一行表示13个MFCC系数,这些系数按递增顺序由空格分隔。13梅尔频率倒谱系数(MFCC)是利用以下条件计算的,采样率:11025 Hz,16位窗口应用:hamming滤波器。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
SpokenArabicDigits_TRAIN.ts:训练集
SpokenArabicDigits_TEST.ts:测试集

4.10 UWaveGestureLibrary
【数据简介】手势运动加速器时序数据
【数据情况】由加速度计生成的一组八个简单手势,时序数据由每个运动的X、Y、Z坐标组成,每个系列长度为315。
【数据目录】数据集使用.ts格式保存,包含以下2个数据文件:
UWaveGestureLibrary_TRAIN.ts:训练集
UWaveGestureLibrary_TEST.ts:测试集

05
—
时间序列填补数据集
5.1 electricity(同上)
【数据简介】包含321个客户的用电量数据。
【数据情况】数据集没有丢失的值,每1H的数值以kW为单位,数据时间段为2016/07/01 2:00—2019/07/02 1:00,共26304条数据。所有时间标签都以葡萄牙小时为单位。所有自然天都有24点数据(24*4)。每年3月的时间变化日(23个小时),凌晨1点到凌晨2点之间的值对所有点都为零。每年10月的时间变化日(25个小时),凌晨1点到2点之间的值合计两个小时的消耗量。
【字段说明】数据集使用.csv格式保存,包含322个数据字段,具体如下:
date:整小时的时间戳,
0:用户id=0
1:用户id=1
......
319:用户id=319
OT:最后用户id
每日的用电量有一定的周期性和季节性,图中只画出前10个用户的electricity曲线。
5.2 ETT-small(同上)
【数据背景】电力分配问题是电网根据顺序变化的需求管理电力分配到不同用户区域。但要预测特定用户区域的未来需求是困难的,因为它随工作日、假日、季节、天气、温度等的不同因素变化而变化。现有预测方法不能适用于长期真实世界数据的高精度长期预测,并且任何错误的预测都可能产生严重的后果。因此当前没有一种有效的方法来预测未来的用电量,管理人员就不得不根据经验值做出决策,而经验值的阈值通常远高于实际需求。值得注意的是,变压器的油温可以有效反映电力变压器的工况。为了解决这个问题,相关研究团队建立了一个平台并收集了2年的数据,可以用它来预测电力变压器的油温并研究电力变压器极限负载能力。
【数据情况】所有的数据都经过了预处理,这些数据的时间跨度为2016年7月到2018年7月。数据集含有2个电力变压器(来自2个站点)的数据,每个数据点每分钟记录一次(用m标记),它们分别来自中国同一个省的两个不同地区,分别名为ETT-small-m1和ETT-small-m2。每个数据集包含2年*365天*24小时*4=70080个数据点。此外,还提供一个小时级别粒度的数据集变体使用(用h标记),即ETT-small-h1和ETT-small-h2。
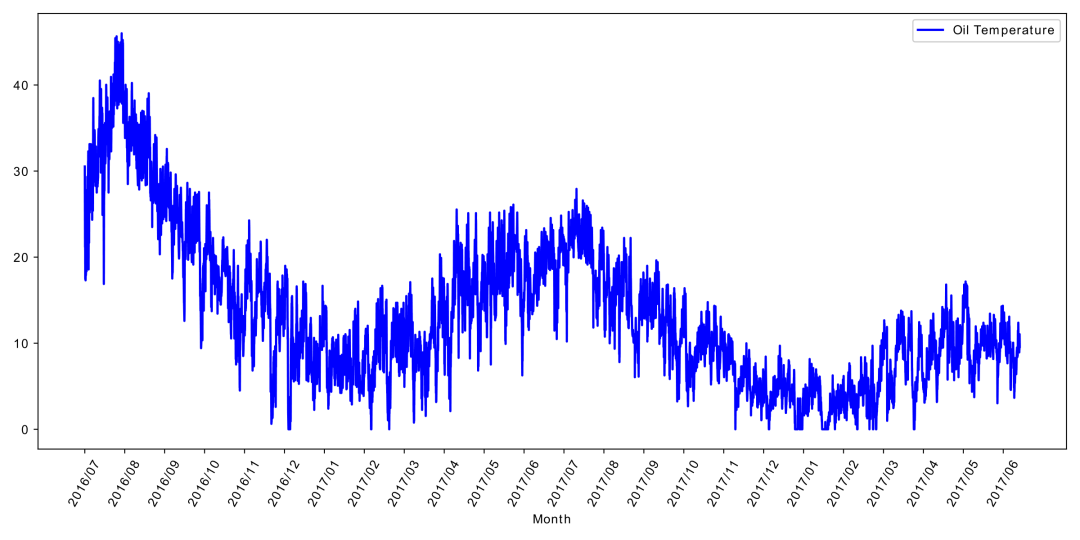
【字段说明】数据集使用.csv格式保存,共包含8维特征,包括数据点的记录日期、预测值“油温”以及6个不同类型的外部负载值,其中第一行是数据头,包括了"HUFL"、"HULL"、"MUFL"、"MULL"、"LUFL"、"LULL"和"OT",每一列的详细意义如下:
5.3 weather(同上)
【数据简介】Jena Climate时间序列数据集中基于多变量的历史气象数据,对气温变化的趋势进行预测
【数据情况】数据集没有丢失值,每10min的数值颗粒度,数据时间段为2020/01/01 00:10—2021/01/01 00:00,共52696条数据,包括2020年至 2021年Weather Station, Max Planck Institute for Biogeochemistry in Jena, Germany的天气要素数据,包括温度、压力、湿度等14个特征指标,每10分钟记录一次。
【字段说明】数据集使用.csv格式保存,主要包含以下16个数据字段:
date:10min颗粒度的时间戳
p(mbar):大气压力
T (degC):摄氏温度
Tpot (K):开尔文温度
Tdew (degC):露点温度,露点是衡量空气中水分绝对量的指标
rh (%):相对湿度
VPmax (mbar):饱和蒸汽压
VPact (mbar):蒸汽压力
VPdef (mbar):饱和水汽压差
sh (g/kg):比湿度
H2OC (mmol/mol):水蒸气浓度
rho (g/m ** 3):大气密度
wv (m/s):风速
max. wv (m/s):最大风速
wd (deg):风向
rain (mm):降雨量
06
—
结束语
以上就是时间序列论文标准数据集的所有内容了,更多数据集下载请关注文章顶部图片右下角平台即可获取。