系列文章目录
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part1 案例复现
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part2 自有数据集构建
【时间序列篇】基于LSTM的序列分类-Pytorch实现 part3 化为己用
在一个人体姿态估计的任务中,需要用深度学习模型来进行序列分类。
时间花费最多的是在数据集的处理上。
这一节主要内容就是对数据集的处理。
文章目录
前言
类似于part1的工作,这部分对数据集进行了分析处理
一、任务问题和数据采集
1 任务问题
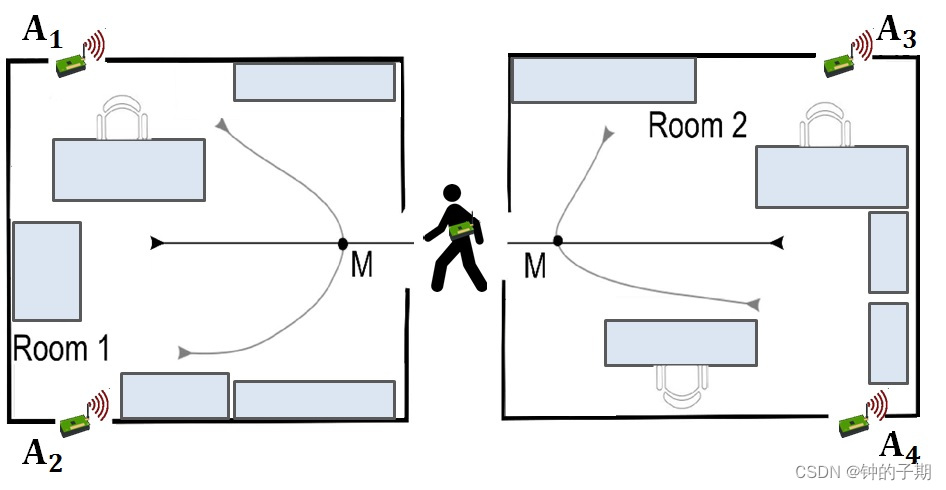
人体姿态估计:
在人体左右腿放置加速度传感器,分别采集横滚角和俯仰角。传感器生成高频数据,对不同状态下采集的数据进行分类,可以识别人体姿态。
2 原始数据采集
采集6类动作姿态,每种动作记录10次过程量。
蹲姿到站立(右蹲) ------ 1
蹲姿到站立(左蹲)----- 2
行进 ----------------------- 3
原地踏步 ----------------- 4
站立到蹲姿(右蹲) ------ 5
站立到蹲姿(左蹲) ------ 6
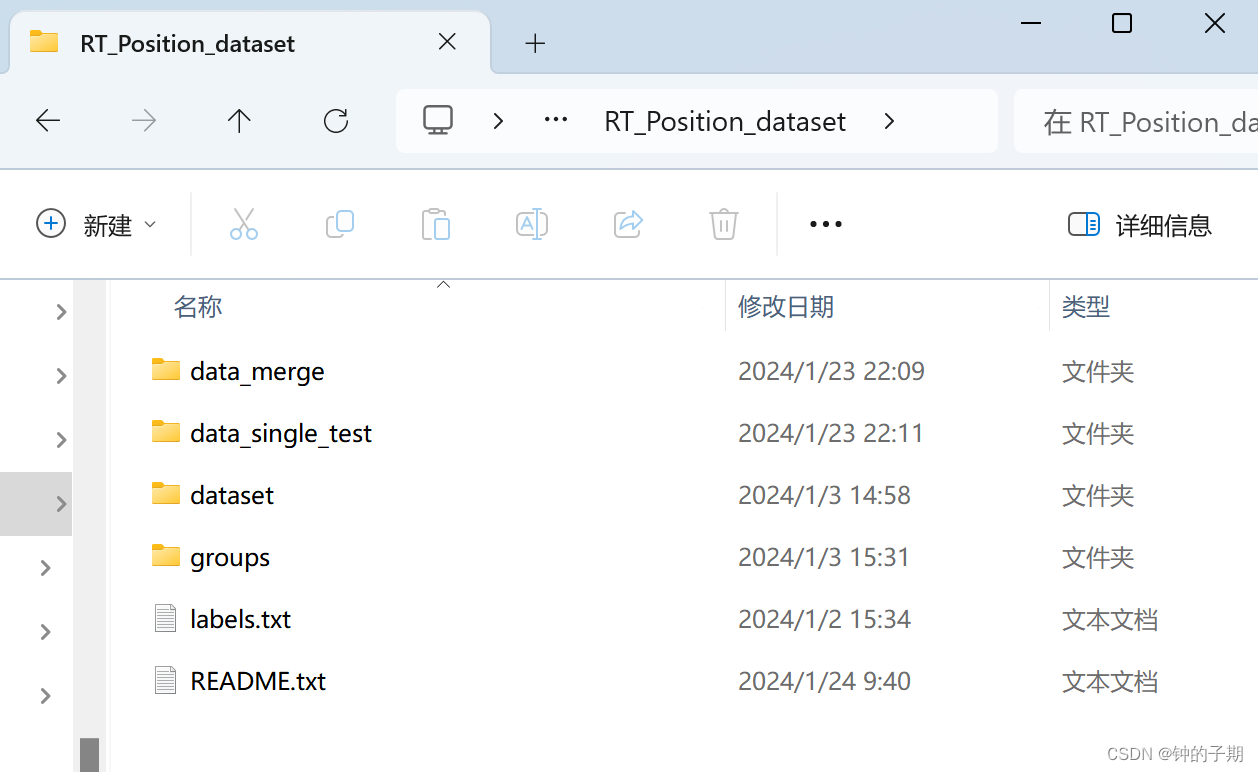
data_merge 文件夹下存放采集到的原始数据。
data_merge_1.xlsx
data_merge_2.xlsx
data_merge_3.xlsx
data_merge_4.xlsx
data_merge_5.xlsx
data_merge_6.xlsx
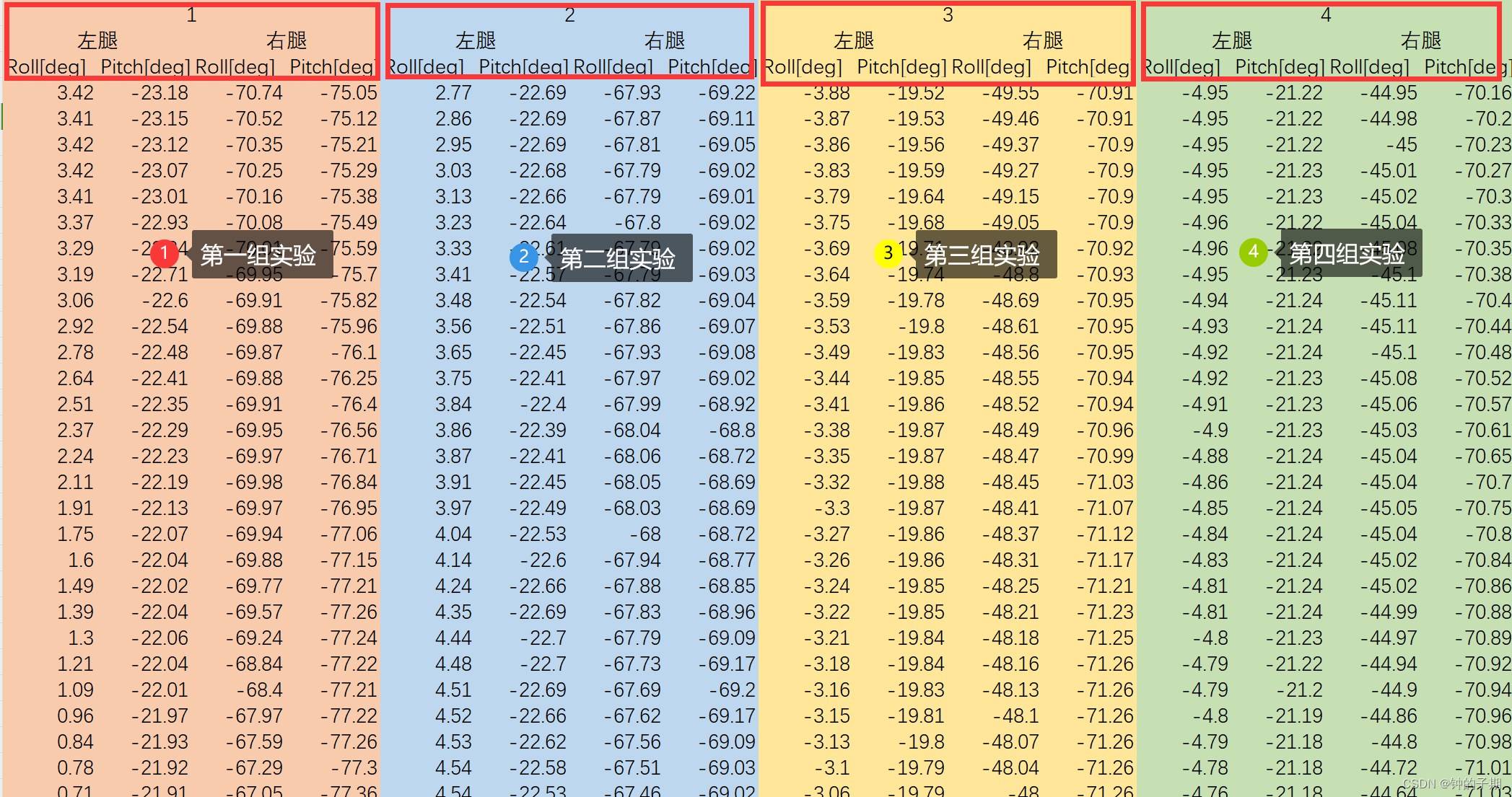
每一个 xlsx 文件对应一类动作姿态,保存有10组实验数据。
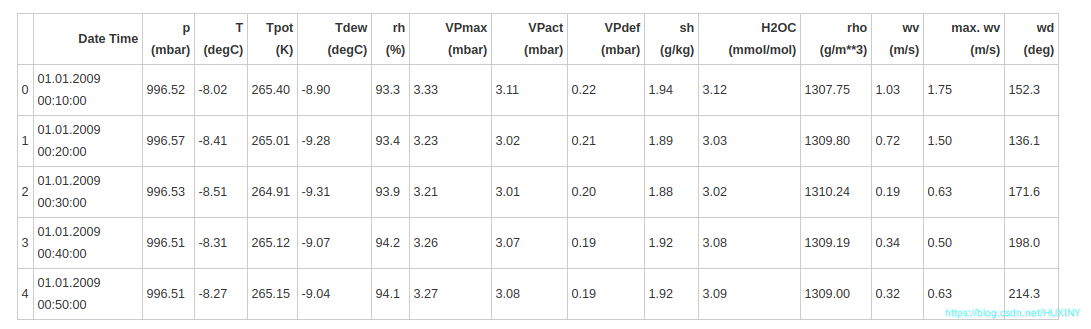
以 data_merge_1.xlsx 文件内容为例:
二、数据处理和生成样本
1 data_merge2single.py
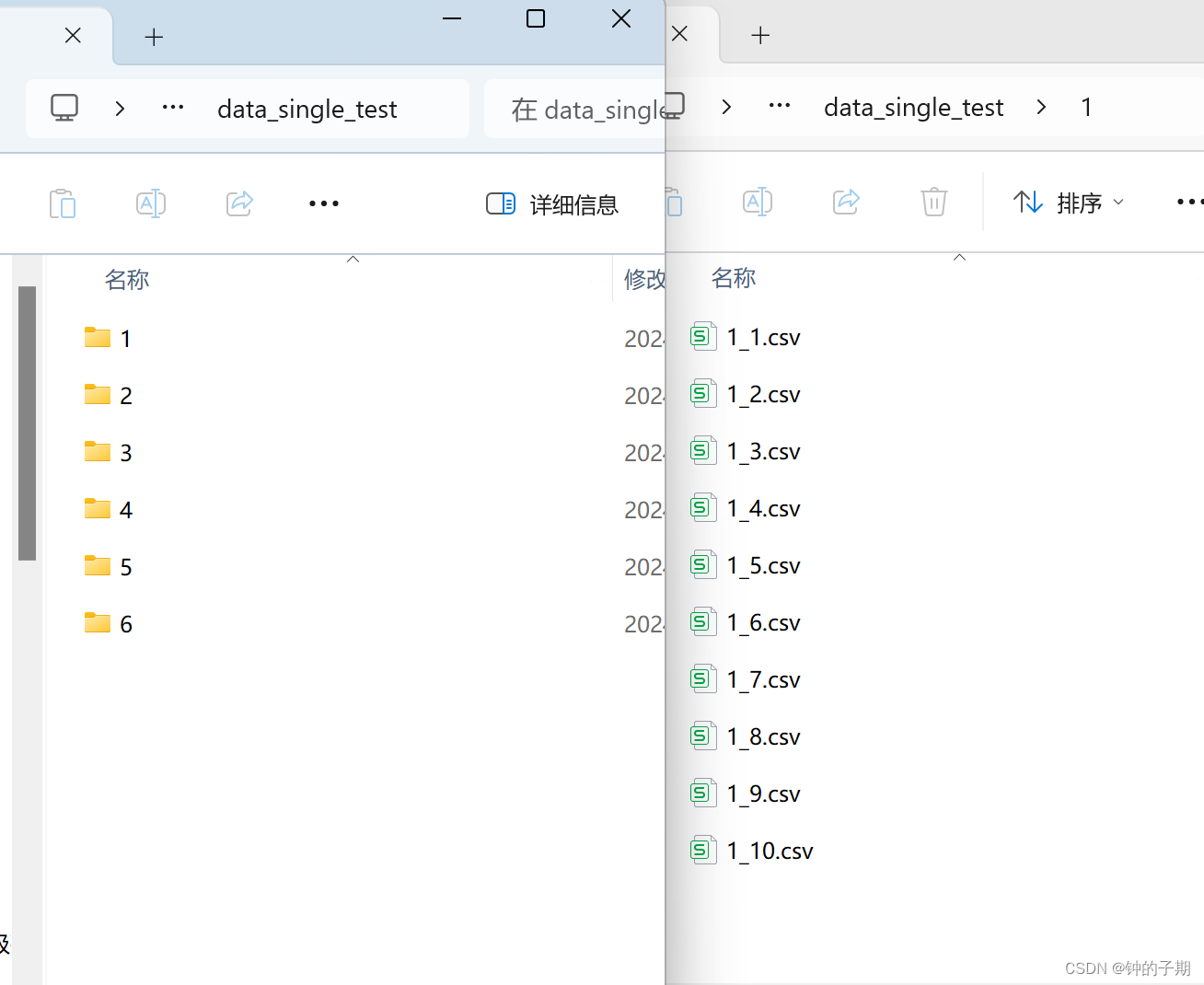
将每类动作姿态的data_merge_x.xlsx文件分解,每一组实验单独保存在一个文件中。
"""
@file name:data_merge2single.py
@desc: 得到每次实验的单独数据
"""
import os
import pandas as pd
'''
/****************************************************/
路径指定
/****************************************************/
'''
# ----------------------------------------------------#
# 数据路径
# ----------------------------------------------------#
ROOT_path = "DATA/RT_Position_dataset"
merge_path = os.path.join(ROOT_path, "data_merge")
path_list = os.listdir(merge_path)
# print(path_list)
# ['data_merge_1.xlsx', 'data_merge_2.xlsx', 'data_merge_3.xlsx', 'data_merge_4.xlsx', 'data_merge_5.xlsx', 'data_merge_6.xlsx', '~$data_merge_1.xlsx']
single_path = os.path.join(ROOT_path, "data_single_test")
if not os.path.exists(single_path):
os.mkdir(single_path)
# ----------------------------------------------------#
# 对每个文件进行读取
# ----------------------------------------------------#
for i in range(0, len(path_list)): # 遍历 data_merge_x.xlsx 文件
file_path = os.path.join(merge_path, path_list[i])
save_path = os.path.join(single_path, str(i + 1))
if not os.path.exists(save_path):
os.makedirs(save_path)
print("----------------------------------------------------")
print(file_path)
# 使用pandas读取Excel文件
df = pd.read_excel(file_path)
# 计算总列数
total_columns = df.shape[1]
index = 0
# 每四列分割并保存(在实验中,分别采集左右腿的俯仰角和横滚角,特征数目为4)
for start_col in range(0, total_columns, 4):
index += 1
# 确定每个文件的列范围
end_col = min(start_col + 4, total_columns)
# 提取四列数据
sub_df = df.iloc[:, start_col:end_col]
# 保存到新的xlsx文件
sub_df.to_csv(f'{
save_path}/{
str(i + 1)}_{
index}.csv', index=False)
data_singe_test 文件夹下存放每组实验的单独数据。
2 data_plot.py
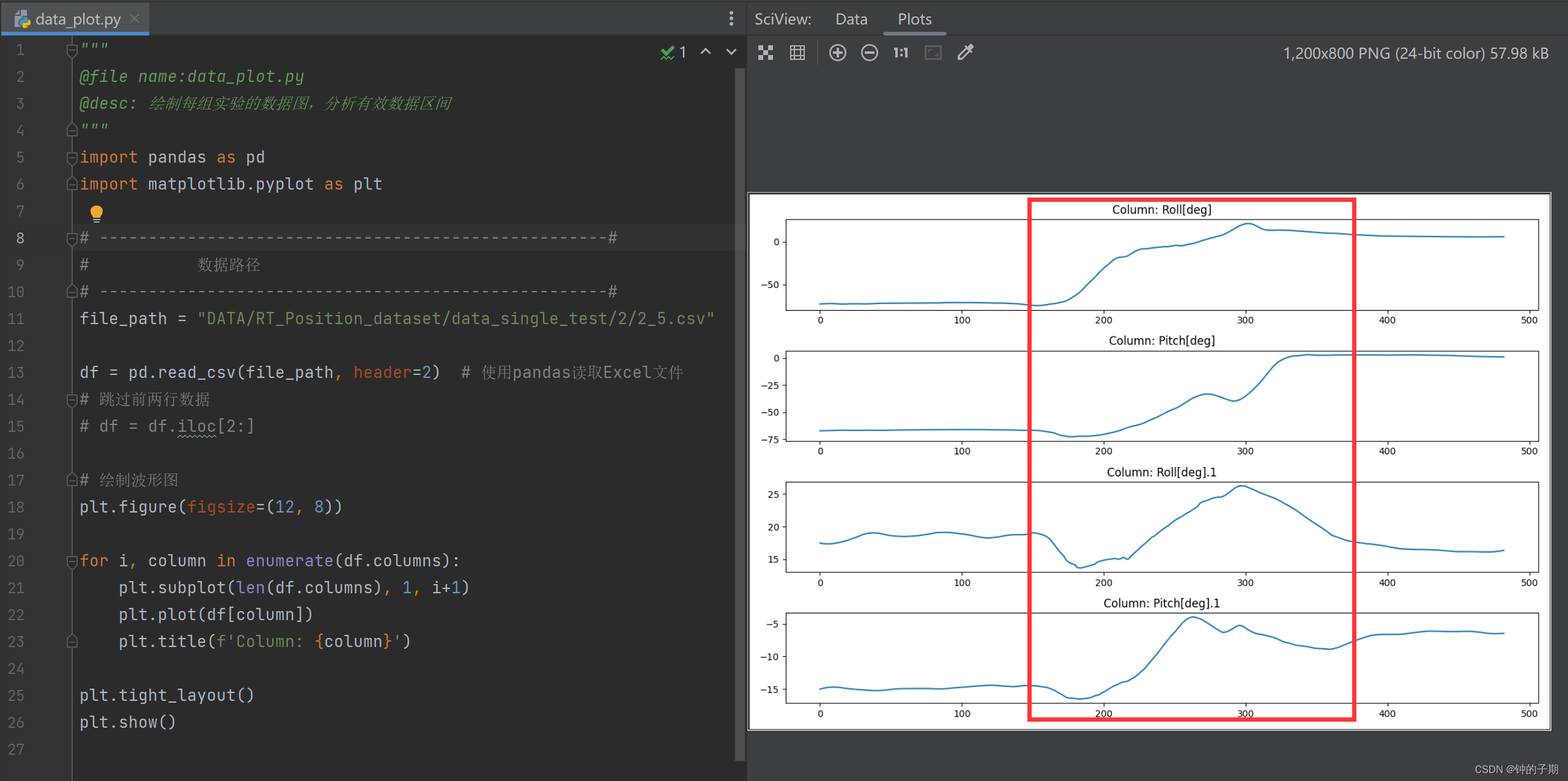
分析每个类别下的每一组实验,不是所有数据都有用,得到有效数据区间
"""
@file name:data_plot.py
@desc: 绘制每组实验的数据图,分析有效数据区间
"""
import pandas as pd
import matplotlib.pyplot as plt
# ----------------------------------------------------#
# 数据路径
# ----------------------------------------------------#
file_path = "DATA/RT_Position_dataset/data_single_test/2/2_5.csv"
df = pd.read_csv(file_path, header=2) # 使用pandas读取Excel文件
# 跳过前两行数据
# df = df.iloc[2:]
# 绘制波形图
plt.figure(figsize=(12, 8))
for i, column in enumerate(df.columns):
plt.subplot(len(df.columns), 1, i+1)
plt.plot(df[column])
plt.title(f'Column: {
column}')
plt.tight_layout()
plt.show()
后续的工作就是从每组实验的有效数据区间中生成样本。
log = {
'1': [[130, 300], [100, 250], [160, 310], [130, 300], [120, 280],
[200, 370], [120, 270], [100, 270], [100, 290], [160, 320]],
'2': [[100, 250], [290, 400], [200, 360], [180, 320], [180, 310],
[150, 290], [160, 300], [140, 270], [120, 270], [100, 260]],
'3': [[100, 400], [100, 370], [100, 450], [100, 450], [100, 450],
[150, 450], [130, 450], [100, 400], [150, 420], [150, 400]],
'4': [[100, 420], [100, 420], [200, 420], [200, 420], [200, 420],
[200, 420], [200, 420], [150, 400], [100, 400], [200, 400]],
'5': [[100, 300], [170, 300], [100, 300], [100, 250], [250, 400],
[100, 270], [150, 300], [100, 280], [120, 270], [130, 270]],
'6': [[120, 300], [150, 250], [100, 300], [50, 300], [100, 240],
[170, 310], [50, 250], [80, 280], [80, 280], [100, 300]],
} # 记录每组实验的有效数据区间
3 data_split.py
针对每一组实验的有效区间,提取并生成样本
"""
@file name:data_split.py
@desc: 分割并生成样本
"""
import os
import pandas as pd
log = {
'1': [[130, 300], [100, 250], [160, 310], [130, 300], [120, 280],
[200, 370], [120, 270], [100, 270], [100, 290], [160, 320]],
'2': [[100, 250], [290, 400], [200, 360], [180, 320], [180, 310],
[150, 290], [160, 300], [140, 270], [120, 270], [100, 260]],
'3': [[100, 400], [100, 370], [100, 450], [100, 450], [100, 450],
[150, 450], [130, 450], [100, 400], [150, 420], [150, 400]],
'4': [[100, 420], [100, 420], [200, 420], [200, 420], [200, 420],
[200, 420], [200, 420], [150, 400], [100, 400], [200, 400]],
'5': [[100, 300], [170, 300], [100, 300], [100, 250], [250, 400],
[100, 270], [150, 300], [100, 280], [120, 270], [130, 270]],
'6': [[120, 300], [150, 250], [100, 300], [50, 300], [100, 240],
[170, 310], [50, 250], [80, 280], [80, 280], [100, 300]],
}
'''
/****************************************************/
路径指定
/****************************************************/
'''
ROOT_path = "DATA/RT_Position_dataset"
# ----------------------------------------------------#
# 单次实验数据路径
# ----------------------------------------------------#
single_test_path = os.path.join(ROOT_path, "data_single_test")
# 样本保存路径
save_path = os.path.join(ROOT_path, "dataset")
if not os.path.exists(save_path):
os.mkdir(save_path)
# ----------------------------------------------------#
# 设置数据样本长度len_seq(设置每个文件的行数)
# ----------------------------------------------------#
rows_per_file = 16
'''
/****************************************************/
导出数据样本
/****************************************************/
'''
index = 0
# 使用os.listdir()列出文件夹中的所有内容(包括子文件夹和文件)
contents = os.listdir(single_test_path) # ['1', '2', '3', '4', '5', '6']
# 使用列表推导式过滤出所有子文件夹
folders = [content for content in contents if os.path.isdir(os.path.join(single_test_path, content))]
# 遍历文件夹中的所有子文件夹
for folder in folders: # ['1', '2', '3', '4', '5', '6']
folder_path = os.path.join(single_test_path, folder)
# print(folder_path)
# 遍历子文件夹中的所有文件
for csv_file in os.listdir(folder_path):
part = csv_file.split('_')[1].split('.')[0] # part = 1,2,3,4,5,6,7,8,9,10
file_path = os.path.join(folder_path, csv_file)
# ----------------------------------------------------------------
# 使用pandas读取Excel文件
df = pd.read_csv(file_path, header=2)
# 读取每次实验有效数据序列索引
[start, end] = log[folder][int(part) - 1]
# 选择每次实验中的有效数据
df_selected = df.iloc[start:end]
# 有效数据的总行数
total_rows = len(df_selected)
# ----------------------------------------------------#
# 核心的参数调整
# ----------------------------------------------------#
number_of_files = 200 # 每次实验的有效数据中,可以生成样本数的上限
window_size = rows_per_file # 滑动窗口的大小
step_size = 3 # 滑动窗口的步长
for file_number in range(number_of_files):
# 计算滑动窗口的起始和结束索引
start_index = file_number * step_size
end_index = start_index + window_size
# 防止结束索引超出数据范围
if end_index > total_rows:
break
# 提取数据
df_subset = df_selected.iloc[start_index:end_index]
index += 1
# 保存到新的csv文件
df_subset.to_csv(f'{
save_path}/Movement4_{
index}.csv', index=False)
print(f"{
folder}输出的文件索引截止到{
index}")
从所有实验数据中,生成样本并保存到 dataset 文件夹下。
这里的超参数设置:
- rows_per_file = 16 样本数据的长度是16,size是[16,4]
- number_of_files = 200 每次实验的有效数据中,可以生成样本数的上限
- step_size = 3 滑动窗口的步长,步长过长数据无法充分利用,过小容易过拟合
1~500索引文件对应类别1,以此类推。共生成3730个样本。

三、制作标签文件和数据集划分文件
上述步骤已生成样本,仿照 part1 文章中提及的数据集,制作 target 文件和 DatasetGroup 文件
本节手动制作两个csv文件。
1 target 文件
新建一个Movement4_target.csv文件,两列分别记录索引和对应类别。索引为1 ~ 3730,类别为1 ~ 6。
1 target 文件
新建一个Movement4_DatasetGroup.csv文件,两列分别记录索引和对应数据集。索引为1 ~ 3730,数据集组别为1 ~ 3。

将制作的 target 文件和 DatasetGroup 文件 保存到 groups 文件夹下。
四、总结
1 数据集示例
最终得到的数据集文件如下所示。
核心是 dataset 和 groups 文件夹。


























![[MRCTF2020]Ez_bypass1](https://img-blog.csdnimg.cn/direct/53eab380c09e4cc1945c71bd0d6a995d.png)


![[漏洞复现]Apache Struts2/S2-015 (CVE-2013-2135)](https://img-blog.csdnimg.cn/direct/92c515816b8a4b41839b92fd4fa134a0.png)