一.GEMM算法概述
1.1不采用数据预取
首先,我们明确GEMM中的具体参数,取bm=128,bn=128,bk=8,rm=8,rn=8。当这几个参数选定后直观地感受一下这几个参数意义,假定给了三个矩阵,A,B,C,其维度都是2048*2048。要求解C=A*B。那么我们需要开启(2048/128)*(2048/128)=256个block,每个block里面有(128/8)*(128/8)=256个线程,每个线程需要负责计算C矩阵中8*8=64个元素的结果,每个block负责256*64=16384个元素的结果。
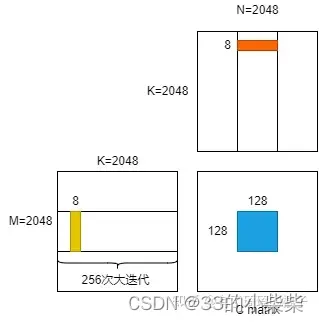
明确了上面的参数之后,我们来仔细地观察其中一个block的计算逻辑。对于这个block而言,bk=8,需要进行2048/8=256次迭代,我们先把这个迭代成为大迭代,每一次大迭代都需要把A里面128*8=1024个元素和B里面8*128=1024个元素先放到shared memory中。然后这个block中的256个线程把结果计算出来。计算完之后,再进入下一次大迭代。不断重复该过程,直至这个block负责的16384个元素的结果被求解出。大迭代示意图如下:
随后再具体看看每一次大迭代中,block中的线程的计算逻辑。在进行一个大迭代时,shared memory中有128*8=1024个A矩阵元素和8*128=1024个B矩阵元素。随后,每个线程需要进行8次迭代,我们把这个迭代称为小迭代。bk=8,所以有8次小迭代。每一次小迭代中,每个线程需要从shared memory中拿到A矩阵的一小列和B矩阵的一小行,即8个A元素和8个B的元素。线程将这8+8=16个元素放置在寄存器中。每个线程需要负责8*8=64个元素的计算,一共会产生64条FFMA指令。小迭代示意图如下:

以上就是不采用数据预取的GEMM算法计算逻辑。总的来说,对于一个block而言,有256个大迭代,每个大迭代中又有8个小迭代,这是后续内容的基础。
1.2 采用数据预取
差异体现在两方面,第一个是开启的shared memory和寄存器数量,第二个是需要提前将一些数据放置到shared memory和寄存器中。
为了实现数据预取,需要开启两倍的shared memory和寄存器。也可以将原来的shared memory切分成两块,也就是将bm*bk和bk*bn的矩阵一分为二。以A中的小矩阵而言,变成了两个bm*bk/2。然后大迭代次数由原来的256变成了512,称为数据预取或者双缓冲。在一个block中,原来在shared memory中需要存储的数据是bm*bk+bk*bn。现在变成了bm*bk*2+bk*bn*2。在一个thread中,为了存储A和B的数据,原来需要使用rm+rn个寄存器,现在需要使用2*(rm+rn)个寄存器。为了方便介绍,用read SM和write SM代表用来读写的两块共享内存,并用read REG和write REG来表示用来读写的两块寄存器。
把共享内存和寄存器说明白后,我们看具体的计算逻辑。在执行256次大迭代之前,我们需要提前将第0次大迭代的数据存到write SM中,并且将第0次小迭代的数据存到write REG中。在完成这一个预取过程后,我们再来仔细地看看第0个大迭代。需要注意的是,上一轮大迭代的write SM就是这一轮迭代的read SM。上一轮小迭代的write REG就是这一轮的read REG。所以在进行第0个大迭代时,上面的write SM就变成了read SM。我们首先需要将下一轮大迭代的数据存到write SM中。由于从global memory中取数的时钟周期非常多。所以在等待数据取回的同时,对read SM中的数据进行计算。也就是我们在等待的同时,需要开启8次小迭代来进行计算。而小迭代中也存在着读写分离,在对read REG进行计算之前,需要先执行write REG的操作,通过这种方式来掩盖访存的latency。整体逻辑如下:
for k in 256 big_loop:
prefecth next loop data to write_SM
// compute in read_SM
for iter in 8 small_loop:
prefecth next loop data to write_REG
compute in read_REG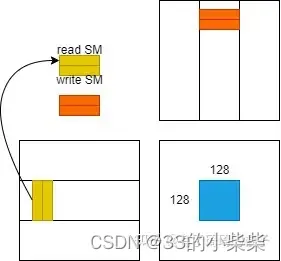
采用数据预取的GEMM计算流程。核心思想:提前将下一轮迭代所需要的数据取出然后放置到更近的存储中,然后通过pipline的形式来减少访存的latency。
二.GEMM代码解析
由于将数据从global memory中搬运到shared memory中还经过了寄存器,所以对prefetch过程进行了细化。
2.1参数说明
BLOCK_SIZE_M、BLOCK_SIZE_K、BLOCK_SIZE_N分别代表上下文的bm、bk、bn。中间两个参数,THREAD_SIZE_Y、THREAD_SIZE_X代表rm、rn。最后的参数ENABLE_DOUBLE_BUFFER代表是否采用双缓冲,即是否采用数据预取 ,即开启双缓冲的情况。
template <
const int BLOCK_SIZE_M, // height of block of C that each thread block calculate
const int BLOCK_SIZE_K, // width of block of A that each thread block load into shared memory
const int BLOCK_SIZE_N, // width of block of C that each thread block calculate
const int THREAD_SIZE_Y, // height of block of C that each thread calculate
const int THREAD_SIZE_X, // width of block of C that each thread calculate
const bool ENABLE_DOUBLE_BUFFER // whether enable double buffering or not
> 接下来是线程类的参数。整个计算流程需要开启256个block,这256个block按照二维形态排布。而一个block中开启了256个线程,这256个线程按照二维形态排布。bx代表横向的block坐标,by代表竖向的block坐标。而tx代表横向的线程坐标,ty代表竖向的线程坐标。这是CUDA的基础内容。THREAD_X_PER_BLOCK代表在一个block中由多少个横向的线程,在这里等于16。THREAD_Y_PER_BLOCK代表在一个block中有多少个横向的线程,在这里等于16。THREAD_NUM_PER_BLOCK代表在一个block中有多少个线程,在这里的呢关于256。tid代表当前线程在这256线程中的id号。
// Block index
int bx = blockIdx.x;
int by = blockIdx.y;
// Thread index
int tx = threadIdx.x;
int ty = threadIdx.y;
// the threads number in Block of X,Y
const int THREAD_X_PER_BLOCK = BLOCK_SIZE_N / THREAD_SIZE_X;
const int THREAD_Y_PER_BLOCK = BLOCK_SIZE_M / THREAD_SIZE_Y;
const int THREAD_NUM_PER_BLOCK = THREAD_X_PER_BLOCK * THREAD_Y_PER_BLOCK;
// thread id in cur Block
const int tid = ty * THREAD_X_PER_BLOCK + tx;随后说明开启的shared memory和register数量。As代表为了存储A矩阵中的数据所需要开启的shared memory。在一轮迭代中需要使用bm*bk的数据,为了加快后续的访存,所以需要进行一次转置。并且为了预取,开了两倍的大小,一半用来读数据,一般用来写数据。所以一共需要2*BLOCK_SIZE_K*BLOCK_SIZE_M的空间。Bs同理,但是载入数据并不需要转置。accum用来临时存储C的计算结果。frag_a用来加载As中的rm个数据,为了预取也就开启了双倍空间。frag_b同理。ldg_num_a,为了将global memory的数据块搬运到shared memory中,需要先经过寄存器。也就是说,这个搬运过程其实是global memory->register->shared memory。所以为了临时存储A的数据,需要开启一定量的寄存器。在第一次迭代中,我们总共需要搬运BLOCK_SIZE_M*BLOCK_SIZE_K个float数据,然后一个block中有THREAD_NUM_PER_BLOCK个线程,采用float4进行取数,即一个线程一次取4个数。则一共需要BLOCK_SIZE_M*BLOCK_SIZE_K/(THREAD_NUM_PER_BLOCK*4)次搬运就能把所有的数搬运到寄存器上。这个搬运次数用ldg_num_a表示。为了存储BLOCK_SIZE_M*BLOCK_SIZE_K的数据块,每个线程需要额外开启ldg_a_reg个寄存器进行存储。
// shared memory
__shared__ float As[2][BLOCK_SIZE_K][BLOCK_SIZE_M];
__shared__ float Bs[2][BLOCK_SIZE_K][BLOCK_SIZE_N];
// registers for C
float accum[THREAD_SIZE_Y][THREAD_SIZE_X] = {0};
// registers for A and B
float frag_a[2][THREAD_SIZE_Y];
float frag_b[2][THREAD_SIZE_X];
// registers load global memory
const int ldg_num_a = BLOCK_SIZE_M * BLOCK_SIZE_K / (THREAD_NUM_PER_BLOCK * 4);
const int ldg_num_b = BLOCK_SIZE_K * BLOCK_SIZE_N / (THREAD_NUM_PER_BLOCK * 4);
float ldg_a_reg[4*ldg_num_a];
float ldg_b_reg[4*ldg_num_b];
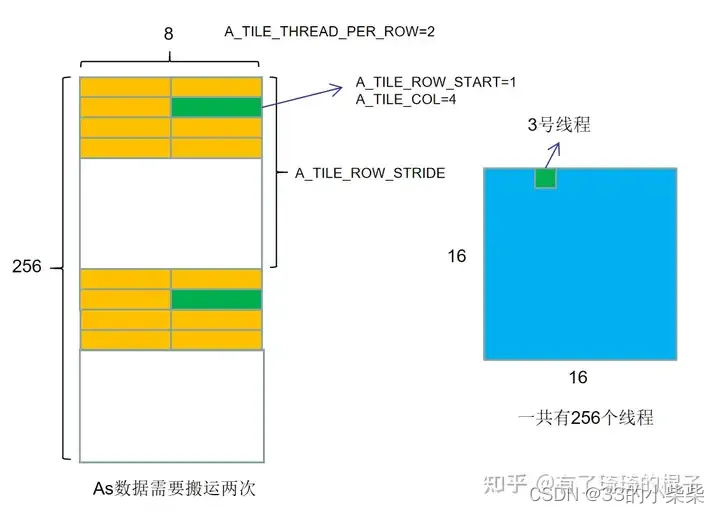
最后需要说明的参数是在global->shared memory阶段用到。我们开启了256个线程,在一次大迭代中需要将128*8个元素搬运到shared memory中。我们用下面的参数说明了这个搬运的逻辑。A_TILE_THREAD_PER_ROW代表把搬运一行数据需要使用多少个线程,为了搬运A的一行,需要使用两个线程。A_TILE_ROW_START代表在这个维度为bm*bk的数据块中,当前线程需要搬运的数据的竖向坐标,而A_TILE_COL代表需要搬运的数据的横向坐标。对3号线程而言,由于它要搬运(1,1)号数据块中的4个元素。所以A_TILE_ROW_START是1,A_TILE_COL是4。A_TILE_ROW_STRIDE代表在进行多次搬运时需要跨越的行。假设As是一块256*8的数据块,256个线程进行搬运,一次搬运4个数,所以要搬运两次。对于3号线程而言,分别搬运下图中的绿色数据块。
// threads number in one row
const int A_TILE_THREAD_PER_ROW = BLOCK_SIZE_K / 4;
const int B_TILE_THREAD_PER_ROW = BLOCK_SIZE_N / 4;
// row number and col number that needs to be loaded by this thread
const int A_TILE_ROW_START = tid / A_TILE_THREAD_PER_ROW;
const int B_TILE_ROW_START = tid / B_TILE_THREAD_PER_ROW;
const int A_TILE_COL = tid % A_TILE_THREAD_PER_ROW * 4;
const int B_TILE_COL = tid % B_TILE_THREAD_PER_ROW * 4;
// row stride that thread uses to load multiple rows of a tile
const int A_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / A_TILE_THREAD_PER_ROW;
const int B_TILE_ROW_STRIDE = THREAD_NUM_PER_BLOCK / B_TILE_THREAD_PER_ROW;2.2大迭代前预取数据
进入具体代码逻辑。用float4读取的过程中使用了两个宏,定义如下
// cal offset from row col and ld , in row-major matrix, ld is the width of the matrix
#define OFFSET(row, col, ld) ((row) * (ld) + (col))
// transfer float4
#define FETCH_FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])迭代前预取数据分为两个部分,第一个部分是将第一个大迭代的数据从global预取到shared memory中。第二个部分是将shared memory上的数据预取到寄存器中。先来看看第一个部分。这里分别是将第一个大迭代中需要的A、B数据预取到shared memory中。对于A矩阵而言,这个for循环代表着block中的线程需要搬运多少次才能将global中的数据放到shared memory中。由于A需要先进行一次转置,所以先将数据放置在寄存器中。数据按行取,然后按列存。对于B矩阵而言,数据不用转置,直接按行取,按列存。当然,这个过程中间也要经过寄存器。
// load A from global memory to shared memory
#pragma unroll
for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) {
int ldg_index = i / A_TILE_ROW_STRIDE * 4;
FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET(
A_TILE_ROW_START + i, // row
A_TILE_COL, // col
K )]);
As[0][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index];
As[0][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1];
As[0][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2];
As[0][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3];
}
// load B from global memory to shared memory
#pragma unroll
for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) {
FETCH_FLOAT4(Bs[0][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(B[OFFSET(
B_TILE_ROW_START + i, // row
B_TILE_COL, // col
N )]);
}
__syncthreads();第二个部分。将shared memory中的数据存到寄存器中。一共需要取THREAD_SIZE_Y个数,每次取4个数
// load A from shared memory to register
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) {
FETCH_FLOAT4(frag_a[0][thread_y]) = FETCH_FLOAT4(As[0][0][THREAD_SIZE_Y * ty + thread_y]);
}
// load B from shared memory to register
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) {
FETCH_FLOAT4(frag_b[0][thread_x]) = FETCH_FLOAT4(Bs[0][0][THREAD_SIZE_X * tx + thread_x]);
}2.3大迭代逻辑
完成上一步后,进入大迭代,按照前面参数,我们需要进行256个大迭代。先忽略这个迭代里面的具体代码,看看这个框架,如下所示。首先要说的是write_stage_idx这个参数。之前定义了__shared__float As[2][BLOCK_SIZE_K][BLOCK_SIZE_M]。为了读写分离,给As开了两块空间。如果write_stage_idx=1,就对As[1]空间进行写操作,对As[0]空间进行读操作。因为我们之前将数据预取到了As[0]这个空间里,所以在第一个大迭代时,对As[0]进行读操作,对As[1]进行写操作,所以write_stage_idx=1。再来看看tile_idx这个参数,这个代表大迭代时,在A矩阵的列号。每一次大迭代要读取BLOCK_SIZE_K列,直到完成大迭代,即tile_idx=K为止。再看看循环里面的load_stage_idx,这个和write_stage_idx对应,两者保持二进制位相反即可。
2.4大迭代详细解释
具体说明大迭代。如果还有下一个迭代,则将下一个迭代的数据块,搬运到寄存器上,这里面的for循环代表可能需要多次搬运。
//大迭代逻辑
int write_stage_idx = 1;//对As[1]空间进行写,对As[0]进行读
int tile_idx = 0;//大迭代时,A矩阵的列号
do{
tile_idx += BLOCK_SIZE_K;
// load next tile from global mem
if(tile_idx< K){
#pragma unroll
//可能有多少次搬运
for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) {
int ldg_index = i / A_TILE_ROW_STRIDE * 4;
FETCH_FLOAT4(ldg_a_reg[ldg_index]) = FETCH_FLOAT4(A[OFFSET(
A_TILE_ROW_START + i, // row
A_TILE_COL + tile_idx, // col
K )]);
}
#pragma unroll
for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) {
int ldg_index = i / B_TILE_ROW_STRIDE * 4;
FETCH_FLOAT4(ldg_b_reg[ldg_index]) = FETCH_FLOAT4(B[OFFSET(
tile_idx + B_TILE_ROW_START + i, // row
B_TILE_COL, // col
N )]);
}
}随后进入小迭代的计算逻辑中,load_stage_idx参数代表需要从As的哪个空间进行读数。然后是BLOCK_SIZE_K-1次小迭代。按照前面的参数配置,即需要在这里完成7次小迭代。由于在小迭代中也采用了双缓冲的方式,需要将下一轮小迭代的数据提前写入到寄存器中,这个过程需要对shared memory访存,会稍微慢点。与此同时,线程需要计算更新THREAD_SIZE_X * THREAD_SIZE_Y=8*8=64个C矩阵元素的结果。
//进入小迭代的计算逻辑
int load_stage_idx = write_stage_idx ^ 1;//代表要从As的哪个空间进行读数
#pragma unroll
for(int j=0; j<BLOCK_SIZE_K-1; ++j){//BLOCK_SIZE_k-1次小迭代
// load next tile from shared mem to register
// load A from shared memory to register
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) {
FETCH_FLOAT4(frag_a[(j+1)%2][thread_y]) = FETCH_FLOAT4(As[load_stage_idx][j+1][THREAD_SIZE_Y * ty + thread_y]);
}
// load B from shared memory to register
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) {
FETCH_FLOAT4(frag_b[(j+1)%2][thread_x]) = FETCH_FLOAT4(Bs[load_stage_idx][j+1][THREAD_SIZE_X * tx + thread_x]);
}
// compute C THREAD_SIZE_X x THREAD_SIZE_Y
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) {
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) {
accum[thread_y][thread_x] += frag_a[j%2][thread_y] * frag_b[j%2][thread_x];
}
}
}而后需要将存储在临时寄存器的数据搬运到shared memroy中。由于A矩阵需要经过一次转置,所以和B矩阵不一样。
// 存储在寄存器的数据搬运到shared memroy中
if(tile_idx < K){
#pragma unroll
for ( int i = 0 ; i < BLOCK_SIZE_M ; i += A_TILE_ROW_STRIDE) {
int ldg_index = i / A_TILE_ROW_STRIDE * 4;
As[write_stage_idx][A_TILE_COL][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index];
As[write_stage_idx][A_TILE_COL+1][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+1];
As[write_stage_idx][A_TILE_COL+2][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+2];
As[write_stage_idx][A_TILE_COL+3][A_TILE_ROW_START + i]=ldg_a_reg[ldg_index+3];
}
// load B from global memory to shared memory
#pragma unroll
for ( int i = 0 ; i < BLOCK_SIZE_K; i += B_TILE_ROW_STRIDE) {
int ldg_index = i / B_TILE_ROW_STRIDE * 4;
FETCH_FLOAT4(Bs[write_stage_idx][B_TILE_ROW_START + i][B_TILE_COL]) = FETCH_FLOAT4(ldg_b_reg[ldg_index]);
}
// use double buffer, only need one sync
__syncthreads();
// switch
write_stage_idx ^= 1;
}
最后完成寄存器的预取,并将最后一个小迭代完成。
// load first tile from shared mem to register of next iter
// load A from shared memory to register
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; thread_y += 4) {
FETCH_FLOAT4(frag_a[0][thread_y]) = FETCH_FLOAT4(As[load_stage_idx^1][0][THREAD_SIZE_Y * ty + thread_y]);
}
// load B from shared memory to register
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x += 4) {
FETCH_FLOAT4(frag_b[0][thread_x]) = FETCH_FLOAT4(Bs[load_stage_idx^1][0][THREAD_SIZE_X * tx + thread_x]);
}
//compute last tile mma THREAD_SIZE_X x THREAD_SIZE_Y
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) {
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; ++thread_x) {
accum[thread_y][thread_x] += frag_a[1][thread_y] * frag_b[1][thread_x];
}
}
}while(tile_idx< K);
2.5计算结果返回
此时,最后的计算结果已经被存储在了accum寄存器中,需要将其写回到global memory中。
// store back to C
#pragma unroll
for (int thread_y = 0; thread_y < THREAD_SIZE_Y; ++thread_y) {
#pragma unroll
for (int thread_x = 0; thread_x < THREAD_SIZE_X; thread_x+=4) {
FETCH_FLOAT4(C[OFFSET(
BLOCK_SIZE_M * by + ty * THREAD_SIZE_Y + thread_y,
BLOCK_SIZE_N * bx + tx * THREAD_SIZE_X + thread_x,
N)]) = FETCH_FLOAT4(accum[thread_y][thread_x]);
}
}
}三.实验
1.在不采用任何汇编的情况下,手写CUDA代码会比cublas差多少?
2.bm、bn、bk、rm、rn等相关参数对GEMM的性能表现有多大影响
针对第一个问题,固定了bm bn bk rm rn的取值为64 8 64 8 8,在V100上测试了不同维度的矩阵(设M=N=K),并且对比了cublas,性能结果图。横坐标是矩阵维度,纵坐标是GFLOPS。在大维度矩阵下,手写的gemm大概平均14TFLOPS,性能表现达到cublas的91%。V100的单精度峰值性能是15.7TFLOPS,在完全不使用汇编,并且有着较好的代码可读性的同时,手写的gemm达到90%的单精度峰值效率。性能优化中最重要的是并行算法和优化策略。

针对问题二。测试不同参数下GEMM性能表现。M=N=K=4096。前5列对应的是参数设置,第6列是V100的GFLOPS,第7列是和cublas的比较。
| bm | bk | bn | rm | rn | MyGEMM | MyGEMM/cublas |
| 64 | 16 | 64 | 4 | 4 | 13036.2 | 86.0% |
| 64 | 32 | 64 | 4 | 4 | 11738.8 | 77.5% |
| 64 | 4 | 64 | 8 | 8 | 13065.6 | 86.2% |
| 64 | 8 | 64 | 8 | 8 | 13463.9 | 88.9% |
| 64 | 16 | 64 | 8 | 8 | 12682.8 | 83.7% |
| 64 | 32 | 64 | 8 | 8 | 8517.43 | 56.2% |
| 128 | 16 | 128 | 8 | 8 | 13506.8 | 89.1% |
| 128 | 8 | 128 | 8 | 8 | 14167.1 | 93.5% |

![[<span style='color:red;'>CUDA</span> 学习笔记] <span style='color:red;'>矩阵</span>转置<span style='color:red;'>算子</span><span style='color:red;'>优化</span>](https://img-blog.csdnimg.cn/direct/3fc4a02bf86b40e99d4828a6507d33db.png)

![[<span style='color:red;'>CUDA</span> 学习笔记] Reduce <span style='color:red;'>算子</span><span style='color:red;'>优化</span>](https://img-blog.csdnimg.cn/direct/42f16cd8d6d14be8bc8ffa3f1b9e5ff7.png)